トレースを使用してアプリをデバッグおよび分析する
MLflow Tracing 、アプリケーションの動作に関する深い知識を提供し、さまざまな環境間での完全なデバッグ エクスペリエンスを促進します。 完全な要求応答サイクル (入出力追跡) と実行フローをキャプチャすることで、アプリケーションのロジックと意思決定プロセスを視覚化して理解できます。
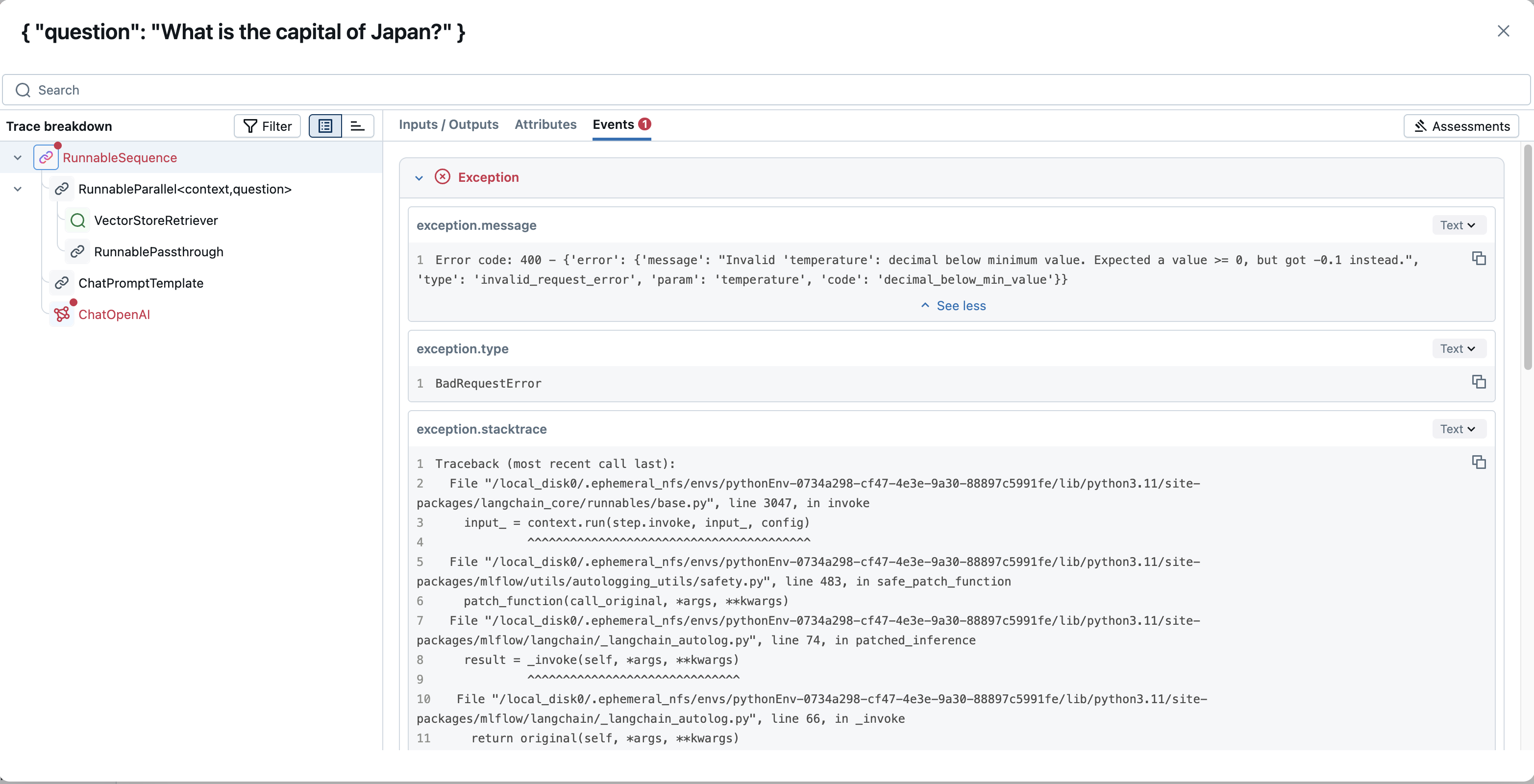
各中間ステップ(検索、ツール呼び出し、LLM のインタラクションなど)の入力、出力、メタデータ、および関連するユーザー フィードバックや品質評価の結果を調べることで、次のことが可能になります。
- 開発中 :生成AIライブラリの抽象化の下で何が起こっているかを詳細に可視化し、問題や予期しない動作が発生する場所を正確に特定するのに役立ちます。
- 本番運用中 : 夜間の問題を監視し、デバッグします。 トレースはエラーをキャプチャし、各ステップでのレイテンシなどの動作メトリクスを含めることができるため、迅速な診断に役立ちます。
MLflow Tracing 、開発と本番運用の間で統一されたエクスペリエンスを提供します。アプリケーションを一度インストルメント化すれば、トレースは両方の環境で一貫して機能します。 これにより、IDE、ノートブック、本番運用モニタリング ダッシュボードなど、好みの環境内でトレースをシームレスにナビゲートできるようになり、複数のツールを切り替えたり、大量のログを検索したりする手間が省けます。
パフォーマンスを監視し、コストを最適化する
GenAI アプリケーションのパフォーマンスとコストを理解し、最適化することが重要です。MLflow Tracing使用すると、アプリケーション実行の各ステップでのレイテンシー、コスト、リソース使用率などの主要な運用メトリクスをキャプチャして監視できます。
これにより、次のことが可能になります。
- 複雑なパイプライン内のパフォーマンスのボトルネックを追跡して特定します。
- リソースの使用率を監視して、効率的な操作を確保します。
- リソースまたはトークンが消費される場所を把握することで、コスト効率を最適化します。
- コードまたはモデルの相互作用におけるパフォーマンス改善の領域を特定します。
さらに、MLflow Tracing は、業界標準の可観測性仕様である OpenTelemetry と互換性があります。この互換性により、トレース データを既存の監視スタック内のさまざまなサービスにエクスポートできるようになります。詳細については、 OpenTelemetry エクスポートを参照してください。