コードベースのスコアラーの例
MLflow Evaluation for GenAI では、カスタム コード ベースのスコアラーを使用して、 AIエージェントまたはアプリケーションの柔軟な評価メトリックを定義できます。 この一連の例と付属の例ノートブックは、入力、出力、実装、およびエラー処理のさまざまなオプションを使用してコードベースのスコアラーを使用するための多くのパターンを示しています。
以下の画像は、 MLflow UI のメトリクスとしてのいくつかのカスタム スコアラーの出力を示しています。
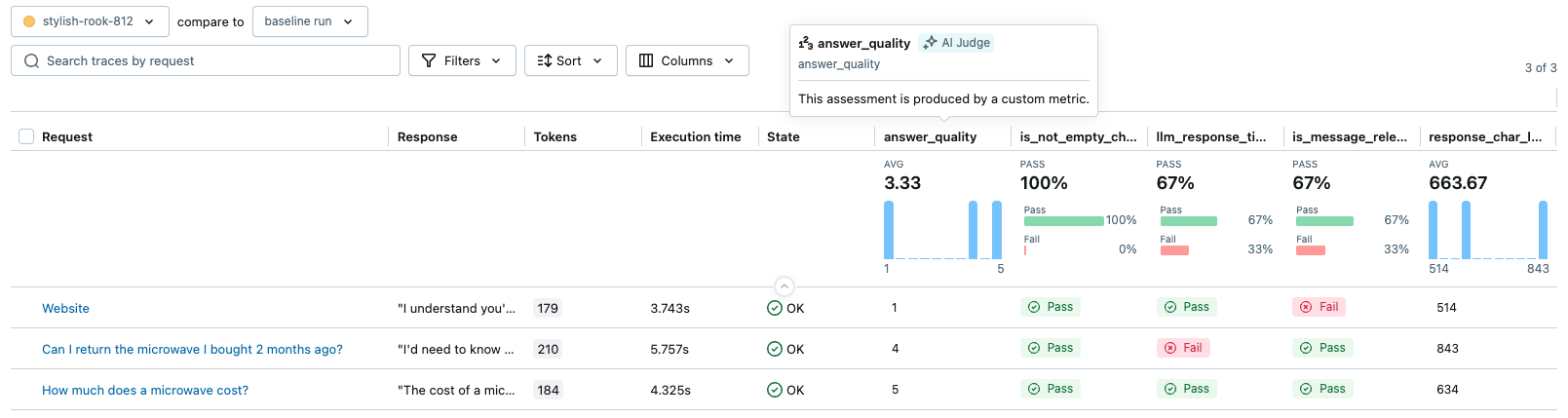
前提条件
- MLflow を更新する
- GenAIアプリを定義する
- いくつかのスコアラーの例で使用されるトレースを生成する
アップデート mlflow
最適な GenAI エクスペリエンスを実現するには、 mlflow[databricks]最新バージョンに更新し、以下のサンプル アプリは OpenAI クライアントを使用しているため、 openaiインストールしてください。
%pip install -q --upgrade "mlflow[databricks]>=3.1" "openai>=1.0.0"
dbutils.library.restartPython()
GenAIアプリを定義する
以下のいくつかの例では、質問に回答するための一般的なアシスタントである次の GenAI アプリを使用します。以下のコードでは、OpenAI クライアントを使用して、 Databricks がホストする LLMに接続します。
from databricks_openai import DatabricksOpenAI
import mlflow
# Create an OpenAI client that is connected to Databricks-hosted LLMs
client = DatabricksOpenAI()
# Select an LLM
model_name = "databricks-claude-sonnet-4"
mlflow.openai.autolog()
# If running outside of Databricks, set up MLflow tracking to Databricks.
# mlflow.set_tracking_uri("databricks")
# In Databricks notebooks, the experiment defaults to the notebook experiment.
# mlflow.set_experiment("/Shared/docs-demo")
@mlflow.trace
def sample_app(messages: list[dict[str, str]]):
# 1. Prepare messages for the LLM
messages_for_llm = [
{"role": "system", "content": "You are a helpful assistant."},
*messages,
]
# 2. Call LLM to generate a response
response = client.chat.completions.create(
model= model_name,
messages=messages_for_llm,
)
return response.choices[0].message.content
sample_app([{"role": "user", "content": "What is the capital of France?"}])
トレースを生成する
以下のeval_datasetは、プレースホルダー スコアラーを使用してトレースを生成するためにmlflow.genai.evaluate()によって使用されます。
from mlflow.genai.scorers import scorer
eval_dataset = [
{
"inputs": {
"messages": [
{"role": "user", "content": "How much does a microwave cost?"},
]
},
},
{
"inputs": {
"messages": [
{
"role": "user",
"content": "Can I return the microwave I bought 2 months ago?",
},
]
},
},
{
"inputs": {
"messages": [
{
"role": "user",
"content": "I'm having trouble with my account. I can't log in.",
},
{
"role": "assistant",
"content": "I'm sorry to hear that you're having trouble with your account. Are you using our website or mobile app?",
},
{"role": "user", "content": "Website"},
]
},
},
]
@scorer
def placeholder_metric() -> int:
# placeholder return value
return 1
eval_results = mlflow.genai.evaluate(
data=eval_dataset,
predict_fn=sample_app,
scorers=[placeholder_metric]
)
generated_traces = mlflow.search_traces(run_id=eval_results.run_id)
generated_traces
上記のmlflow.search_traces()関数は、以下のいくつかの例で使用するために、トレースの Pandas DataFrame を返します。
例1: データにアクセスする Trace
完全なMLflow Trace オブジェクトにアクセスして、さまざまな詳細 (スパン、入力、出力、属性、タイミング) を使用して、きめ細かいメトリック計算を実行します。
このスコアラーは、トレースの合計実行時間が許容範囲内であるかどうかをチェックします。
import mlflow
from mlflow.genai.scorers import scorer
from mlflow.entities import Trace, Feedback, SpanType
@scorer
def llm_response_time_good(trace: Trace) -> Feedback:
# Search particular span type from the trace
llm_span = trace.search_spans(span_type=SpanType.CHAT_MODEL)[0]
response_time = (llm_span.end_time_ns - llm_span.start_time_ns) / 1e9 # convert to seconds
max_duration = 5.0
if response_time <= max_duration:
return Feedback(
value="yes",
rationale=f"LLM response time {response_time:.2f}s is within the {max_duration}s limit."
)
else:
return Feedback(
value="no",
rationale=f"LLM response time {response_time:.2f}s exceeds the {max_duration}s limit."
)
# Evaluate the scorer using the pre-generated traces from the prerequisite code block.
span_check_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[llm_response_time_good]
)
例2: 定義済みのLLMジャッジをラップする
MLflow の組み込み LLM ジャッジをラップするカスタム スコアラーを作成します。これを使用して、ジャッジのトレース データを前処理したり、フィードバックを後処理したりします。
この例では、 is_context_relevantジャッジをラップして、アシスタントの応答がユーザーのクエリに関連しているかどうかを評価する方法を示します。具体的には、 sample_appのinputsフィールドは{"messages": [{"role": ..., "content": ...}, ...]}のような辞書です。このスコアラーは、最後のユーザー メッセージの内容を抽出して関連性判定者に渡します。
import mlflow
from mlflow.entities import Trace, Feedback
from mlflow.genai.judges import is_context_relevant
from mlflow.genai.scorers import scorer
from typing import Any
@scorer
def is_message_relevant(inputs: dict[str, Any], outputs: str) -> Feedback:
last_user_message_content = None
if "messages" in inputs and isinstance(inputs["messages"], list):
for message in reversed(inputs["messages"]):
if message.get("role") == "user" and "content" in message:
last_user_message_content = message["content"]
break
if not last_user_message_content:
raise Exception("Could not extract the last user message from inputs to evaluate relevance.")
# Call the `relevance_to_query judge. It will return a Feedback object.
return is_context_relevant(
request=last_user_message_content,
context={"response": outputs},
)
# Evaluate the scorer using the pre-generated traces from the prerequisite code block.
custom_relevance_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[is_message_relevant]
)
例3: 使用 expectations
期待値はグラウンドトゥルース値またはラベルであり、多くの場合、オフライン評価で重要になります。mlflow.genai.evaluate()を実行する場合、次の 2 つの方法でdata引数に期待値を指定できます。
expectations列またはフィールド: たとえば、data引数が辞書のリストまたは Pandas DataFrame の場合、各行にはexpectationsキーを含めることができます。このキーに関連付けられた値は、カスタム スコアラーに直接渡されます。trace列またはフィールド: たとえば、data引数がmlflow.search_traces()によって返されたデータフレームである場合、トレースに関連付けられたExpectationデータを含むtraceフィールドが含まれます。
本番運用モニタリングでは、グラウンド トゥルースなしでライブ トラフィックを評価するため、通常は期待がありません。 オフラインとオンラインの両方の評価に同じスコアラーを使用する場合は、期待に適切に対応できるように設計してください。
この例では、定義済みのSafetyスコアラーとともにカスタム スコアラーを使用する方法も示します。
import mlflow
from mlflow.entities import Feedback
from mlflow.genai.scorers import scorer, Safety
from typing import Any, List, Optional, Union
expectations_eval_dataset_list = [
{
"inputs": {"messages": [{"role": "user", "content": "What is 2+2?"}]},
"expectations": {
"expected_response": "2+2 equals 4.",
"expected_keywords": ["4", "four", "equals"],
}
},
{
"inputs": {"messages": [{"role": "user", "content": "Describe MLflow in one sentence."}]},
"expectations": {
"expected_response": "MLflow is an open-source platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models.",
"expected_keywords": ["mlflow", "open-source", "platform", "machine learning"],
}
},
{
"inputs": {"messages": [{"role": "user", "content": "Say hello."}]},
"expectations": {
"expected_response": "Hello there!",
# No keywords needed for this one, but the field can be omitted or empty
}
}
]
例3.1: 期待される応答との完全一致
このスコアラーは、アシスタントの応答がexpectationsで提供されたexpected_responseと完全に一致するかどうかを確認します。
@scorer
def exact_match(outputs: str, expectations: dict[str, Any]) -> bool:
# Scorer can return primitive value like bool, int, float, str, etc.
return outputs == expectations["expected_response"]
exact_match_eval_results = mlflow.genai.evaluate(
data=expectations_eval_dataset_list,
predict_fn=sample_app, # sample_app is from the prerequisite section
scorers=[exact_match, Safety()] # You can include any number of scorers
)
例3.2: 期待値からのキーワードチェック
このスコアラーは、 expectationsのすべてのexpected_keywordsがアシスタントの応答に存在するかどうかを確認します。
@scorer
def keyword_presence_scorer(outputs: str, expectations: dict[str, Any]) -> Feedback:
expected_keywords = expectations.get("expected_keywords")
print(expected_keywords)
if expected_keywords is None:
return Feedback(value="yes", rationale="No keywords were expected in the response.")
missing_keywords = []
for keyword in expected_keywords:
if keyword.lower() not in outputs.lower():
missing_keywords.append(keyword)
if not missing_keywords:
return Feedback(value="yes", rationale="All expected keywords are present in the response.")
else:
return Feedback(value="no", rationale=f"Missing keywords: {', '.join(missing_keywords)}.")
keyword_presence_eval_results = mlflow.genai.evaluate(
data=expectations_eval_dataset_list,
predict_fn=sample_app, # sample_app is from the prerequisite section
scorers=[keyword_presence_scorer]
)
例4: 複数のフィードバックオブジェクトを返す
1 つのスコアラーはFeedbackオブジェクトのリストを返すことができるため、1 つのスコアラーで複数の品質ファセット (PII、感情、簡潔性など) を同時に評価できます。
各Feedbackオブジェクトには一意のnameが必要で、これが結果のメトリクス名になります。 メトリクス名の詳細を参照してください。
この例では、トレースごとに 2 つの異なるフィードバックを返すスコアラーを示します。
is_not_empty_check: 応答コンテンツが空でないかどうかを示すブール値。response_char_length: 応答の文字数を表す数値。
import mlflow
from mlflow.genai.scorers import scorer
from mlflow.entities import Feedback, Trace # Ensure Feedback and Trace are imported
from typing import Any, Optional
@scorer
def comprehensive_response_checker(outputs: str) -> list[Feedback]:
feedbacks = []
# 1. Check if the response is not empty
feedbacks.append(
Feedback(name="is_not_empty_check", value="yes" if outputs != "" else "no")
)
# 2. Calculate response character length
char_length = len(outputs)
feedbacks.append(Feedback(name="response_char_length", value=char_length))
return feedbacks
# Evaluate the scorer using the pre-generated traces from the prerequisite code block.
multi_feedback_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[comprehensive_response_checker]
)
結果には、評価としてis_not_empty_checkとresponse_char_length 2 つの列が含まれます。
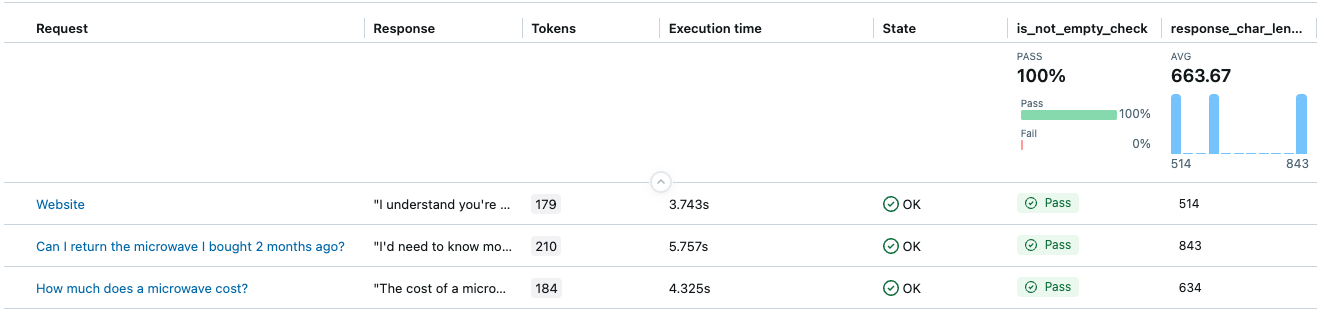
例5: ジャッジとして自分のLLMを使用する
スコアラー内にカスタム LLM または外部でホストされた LLM を統合します。スコアラーは、API 呼び出し、入出力フォーマットを処理し、LLM の応答からFeedback生成して、判定プロセスを完全に制御します。
また、 Feedbackオブジェクトのsourceフィールドを設定して、評価のソースが LLM ジャッジであることを示すこともできます。
import mlflow
import json
from mlflow.genai.scorers import scorer
from mlflow.entities import AssessmentSource, AssessmentSourceType, Feedback
from typing import Any, Optional
# Define the prompts for the Judge LLM.
judge_system_prompt = """
You are an impartial AI assistant responsible for evaluating the quality of a response generated by another AI model.
Your evaluation should be based on the original user query and the AI's response.
Provide a quality score as an integer from 1 to 5 (1=Poor, 2=Fair, 3=Good, 4=Very Good, 5=Excellent).
Also, provide a brief rationale for your score.
Your output MUST be a single valid JSON object with two keys: "score" (an integer) and "rationale" (a string).
Example:
{"score": 4, "rationale": "The response was mostly accurate and helpful, addressing the user's query directly."}
"""
judge_user_prompt = """
Please evaluate the AI's Response below based on the Original User Query.
Original User Query:
```{user_query}```
AI's Response:
```{llm_response_from_app}```
Provide your evaluation strictly as a JSON object with "score" and "rationale" keys.
"""
@scorer
def answer_quality(inputs: dict[str, Any], outputs: str) -> Feedback:
user_query = inputs["messages"][-1]["content"]
# Call the Judge LLM using the OpenAI SDK client.
judge_llm_response_obj = client.chat.completions.create(
model="databricks-claude-sonnet-4-5", # This example uses Databricks hosted Claude. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o-mini, etc.
messages=[
{"role": "system", "content": judge_system_prompt},
{"role": "user", "content": judge_user_prompt.format(user_query=user_query, llm_response_from_app=outputs)},
],
max_tokens=200, # Max tokens for the judge's rationale
temperature=0.0, # For more deterministic judging
)
judge_llm_output_text = judge_llm_response_obj.choices[0].message.content
# Parse the Judge LLM's JSON output.
judge_eval_json = json.loads(judge_llm_output_text)
parsed_score = int(judge_eval_json["score"])
parsed_rationale = judge_eval_json["rationale"]
return Feedback(
value=parsed_score,
rationale=parsed_rationale,
# Set the source of the assessment to indicate the LLM judge used to generate the feedback
source=AssessmentSource(
source_type=AssessmentSourceType.LLM_JUDGE,
source_id="claude-sonnet-4-5",
)
)
# Evaluate the scorer using the pre-generated traces from the prerequisite code block.
custom_llm_judge_eval_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[answer_quality]
)
UI でトレースを開き、「answer_quality」評価をクリックすると、根拠、タイムスタンプ、ジャッジモデル名などのジャッジのメタデータを確認できます。ジャッジの評価が正しくない場合は、 Editボタンをクリックしてスコアを上書きできます。
新しい評価は元のジャッジの評価に取って代わります。編集履歴は将来の参照用に保存されます。
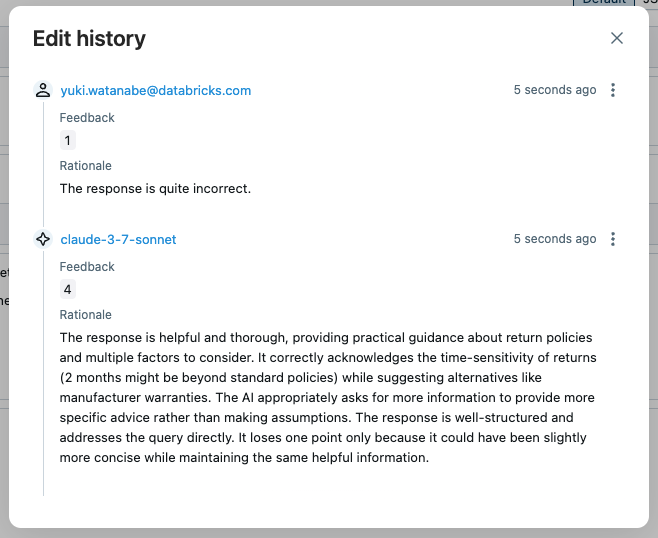
例6: クラスベースのスコアラー定義(オフライン評価のみ)
スコアラーに状態が必要な場合は、 @scorerデコレータベースの定義では不十分な可能性があります。代わりに、より複雑なスコアラーにはScorer基本クラスを使用します。Scorerクラスは Pydantic オブジェクトなので、追加のフィールドを定義して__call__メソッドで使用することができます。
クラスベースのScorerサブクラスは、 mlflow.genai.evaluate()を使用したオフライン評価でのみサポートされます。本番運用モニタリングには登録できません。 本番運用モニタリングでカスタム スコアラーを使用するには、 @scorerデコレータを使用します。
from mlflow.genai.scorers import Scorer
from mlflow.entities import Feedback
from typing import Optional
# Scorer class is a Pydantic object
class ResponseQualityScorer(Scorer):
# The `name` field is mandatory
name: str = "response_quality"
# Define additional fields
min_length: int = 50
required_sections: Optional[list[str]] = None
# Override the __call__ method to implement the scorer logic
def __call__(self, outputs: str) -> Feedback:
issues = []
# Check length
if len(outputs.split()) < self.min_length:
issues.append(f"Too short (minimum {self.min_length} words)")
# Check required sections
missing = [s for s in self.required_sections if s not in outputs]
if missing:
issues.append(f"Missing sections: {', '.join(missing)}")
if issues:
return Feedback(
value=False,
rationale="; ".join(issues)
)
return Feedback(
value=True,
rationale="Response meets all quality criteria"
)
response_quality_scorer = ResponseQualityScorer(required_sections=["# Summary", "# Sources"])
# Evaluate the scorer using the pre-generated traces from the prerequisite code block.
class_based_scorer_results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[response_quality_scorer]
)
例7: スコアラーにおけるエラー処理
MLflow がスコアラーのエラーをどのように表示するか、および 2 つのエラー処理方法については、 「エラー処理」を参照してください。以下の例では、両方のアプローチを1つのスコアラーに組み合わせています。
import mlflow
from mlflow.genai.scorers import scorer
from mlflow.entities import Feedback, AssessmentError
@scorer
def resilient_scorer(outputs, trace=None):
try:
response = outputs.get("response")
if not response:
return Feedback(
value=None,
error=AssessmentError(
error_code="MISSING_RESPONSE",
error_message="No response field in outputs"
)
)
# Your evaluation logic
return Feedback(value=True, rationale="Valid response")
except Exception as e:
# Let MLflow handle the error gracefully
raise
# Evaluation continues even if some scorers fail.
results = mlflow.genai.evaluate(
data=generated_traces,
scorers=[resilient_scorer]
)
例8: スコアラーの命名規則
以下の例は、コードベースのスコアラーの命名規則を示しています。
from mlflow.genai.scorers import Scorer
from mlflow.entities import Feedback
from typing import Optional, Any, List
# Primitive value or single `Feedback` without a name: The scorer function name becomes the metric name.
@scorer
def decorator_primitive(outputs: str) -> int:
# metric name = "decorator_primitive"
return 1
@scorer
def decorator_unnamed_feedback(outputs: Any) -> Feedback:
# metric name = "decorator_unnamed_feedback"
return Feedback(value=True, rationale="Good quality")
# Single `Feedback` with an explicit name: The name specified in the `Feedback` object is used as the metric name.
@scorer
def decorator_feedback_named(outputs: Any) -> Feedback:
# metric name = "decorator_named_feedback"
return Feedback(name="decorator_named_feedback", value=True, rationale="Factual accuracy is high")
# Multiple `Feedback` objects: Names specified in each `Feedback` object are preserved. You must specify a unique name for each `Feedback`.
@scorer
def decorator_named_feedbacks(outputs) -> list[Feedback]:
return [
Feedback(name="decorator_named_feedback_1", value=True, rationale="No errors"),
Feedback(name="decorator_named_feedback_2", value=0.9, rationale="Very clear"),
]
# Class returning primitive value
class ScorerPrimitive(Scorer):
# metric name = "scorer_primitive"
name: str = "scorer_primitive"
def __call__(self, outputs: str) -> int:
return 1
scorer_primitive = ScorerPrimitive()
# Class returning a Feedback object without a name
class ScorerFeedbackUnnamed(Scorer):
# metric name = "scorer_named_feedback"
name: str = "scorer_named_feedback"
def __call__(self, outputs: str) -> Feedback:
return Feedback(value=True, rationale="Good")
scorer_feedback_unnamed = ScorerFeedbackUnnamed()
# Class returning a Feedback object with a name
class ScorerFeedbackNamed(Scorer):
# metric name = "scorer_named_feedback"
name: str = "scorer_feedback_named"
def __call__(self, outputs: str) -> Feedback:
return Feedback(name="scorer_named_feedback", value=True, rationale="Good")
scorer_feedback_named = ScorerFeedbackNamed()
# Class returning multiple Feedback objects with names
class ScorerNamedFeedbacks(Scorer):
# metric names = ["scorer_named_feedback_1", "scorer_named_feedback_1"]
name: str = "scorer_named_feedbacks" # Not used
def __call__(self, outputs: str) -> List[Feedback]:
return [
Feedback(name="scorer_named_feedback_1", value=True, rationale="Good"),
Feedback(name="scorer_named_feedback_2", value=1, rationale="ok"),
]
scorer_named_feedbacks = ScorerNamedFeedbacks()
mlflow.genai.evaluate(
data=generated_traces,
scorers=[
decorator_primitive,
decorator_unnamed_feedback,
decorator_feedback_named,
decorator_named_feedbacks,
scorer_primitive,
scorer_feedback_unnamed,
scorer_feedback_named,
scorer_named_feedbacks,
],
)
例9: 評価結果の連鎖
1 つのスコアラーがトレースのサブセットに問題を示している場合、 mlflow.search_traces()を使用して、そのトレースのサブセットを収集し、さらに反復することができます。以下の例では、一般的な「安全性」の障害を検出し、さらにカスタマイズされたスコアラーを使用して、障害が発生したトレースのサブセットを分析します (コンテンツ ポリシー ドキュメントを使用した評価の簡単な例)。あるいは、問題のあるトレースのサブセットを使用して AI アプリ自体を反復処理し、困難な入力に対するパフォーマンスを向上させることもできます。
from mlflow.genai.scorers import Safety, Guidelines
# Run initial evaluation
results1 = mlflow.genai.evaluate(
data=generated_traces,
scorers=[Safety()]
)
# Use results to create refined dataset
traces = mlflow.search_traces(run_id=results1.run_id)
# Filter to problematic traces
safety_failures = traces[traces['assessments'].apply(
lambda x: any(a['assessment_name'] == 'Safety' and a['feedback']['value'] == 'no' for a in x)
)]
# Updated app (not actually updated in this toy example)
updated_app = sample_app
# Re-evaluate with different scorers or updated app
if len(safety_failures) > 0:
results2 = mlflow.genai.evaluate(
data=safety_failures,
predict_fn=updated_app,
scorers=[
Guidelines(
name="content_policy",
guidelines="Response must follow our content policy"
)
]
)
例10: ガイドライン付きの条件付きロジック
ガイドラインのジャッジをカスタム コード ベースのスコアラーでラップして、ユーザー属性やその他のコンテキストに基づいて異なるガイドラインを適用できます。
from mlflow.genai.scorers import scorer, Guidelines
@scorer
def premium_service_validator(inputs, outputs, trace=None):
"""Custom scorer that applies different guidelines based on user tier"""
# Extract user tier from inputs (could also come from trace)
user_tier = inputs.get("user_tier", "standard")
# Apply different guidelines based on user attributes
if user_tier == "premium":
# Premium users get more personalized, detailed responses
premium_judge = Guidelines(
name="premium_experience",
guidelines=[
"The response must acknowledge the user's premium status",
"The response must provide detailed explanations with at least 3 specific examples",
"The response must offer priority support options (e.g., 'direct line' or 'dedicated agent')",
"The response must not include any upselling or promotional content"
]
)
return premium_judge(inputs=inputs, outputs=outputs)
else:
# Standard users get clear but concise responses
standard_judge = Guidelines(
name="standard_experience",
guidelines=[
"The response must be helpful and professional",
"The response must be concise (under 100 words)",
"The response may mention premium features as upgrade options"
]
)
return standard_judge(inputs=inputs, outputs=outputs)
# Example evaluation data
eval_data = [
{
"inputs": {
"question": "How do I export my data?",
"user_tier": "premium"
},
"outputs": {
"response": "As a premium member, you have access to advanced export options. You can export in 5 formats: CSV, Excel, JSON, XML, and PDF. Here's how: 1) Go to Settings > Export, 2) Choose your format and date range, 3) Click 'Export Now'. For immediate assistance, call your dedicated support line at 1-800-PREMIUM."
}
},
{
"inputs": {
"question": "How do I export my data?",
"user_tier": "standard"
},
"outputs": {
"response": "You can export your data as CSV from Settings > Export. Premium users can access additional formats like Excel and PDF."
}
}
]
# Run evaluation with the custom scorer
results = mlflow.genai.evaluate(
data=eval_data,
scorers=[premium_service_validator]
)
サンプルノートブック
次のノートブックにはこのページのすべてのコードが含まれています。
MLflow 評価ノートブックのコードベースのスコアラー
その他のリソース
- カスタムLLMスコアラー- コードベースのスコアラーよりも簡単に定義できる、 LLMを判断基準として使用するメトリクスを使用したセマンティック評価について学習します。
- 本番運用での実行スコアラー- 継続的なモニタリングのためにスコアラーをデプロイします。
- 評価データセットの構築- スコアラー用のテスト データを作成します。