スコアラーとLLMジャッジ
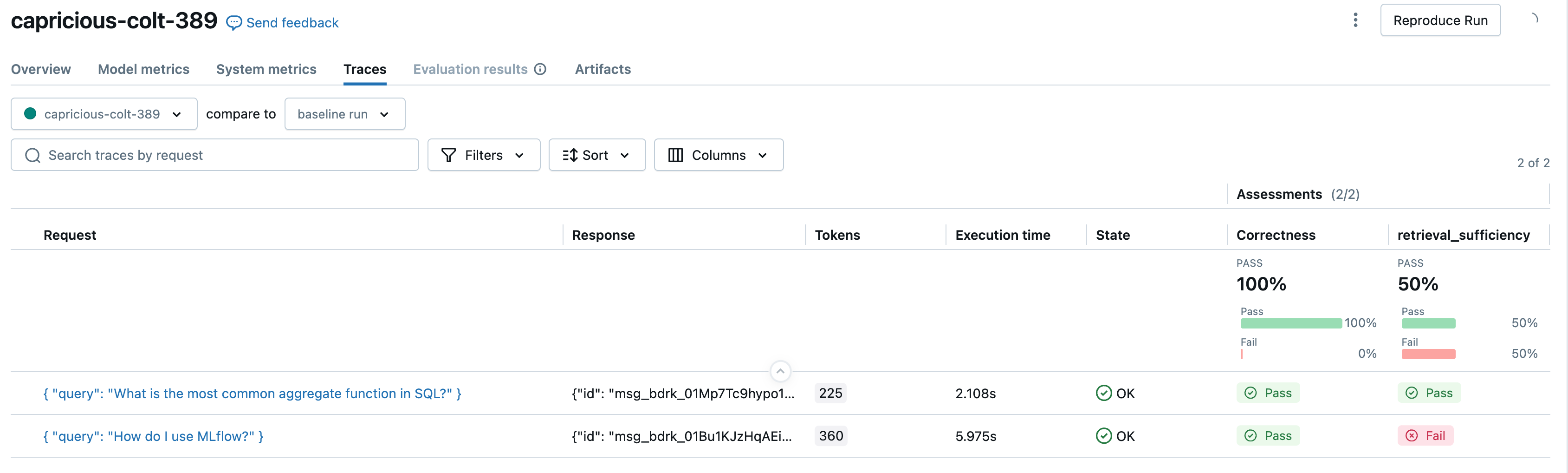
スコアラーは、MLflow GenAI 評価フレームワークの重要なコンポーネントです。モデル、エージェント、アプリケーションの評価基準を定義するための統一されたインターフェースを提供します。名前が示すように、スコアラーは評価基準に基づいてアプリケーションの性能を採点します。これは合格/不合格、真偽、数値、またはカテゴリ値になります。
開発での評価と本番運用でのモニタリングに同じスコアラーを使用して、アプリケーションのライフサイクル全体で評価の一貫性を保つことができます。
必要なカスタマイズと制御の量に応じて、適切なタイプのスコアラーを選択します。それぞれのアプローチは前のアプローチに基づいて構築され、複雑さと制御性がさらに高まります。
組み込みのジャッジを使って素早く評価を開始します。ニーズの変化に応じて、ドメイン固有の基準に合わせてカスタム LLM ジャッジを構築し、決定論的なビジネス ロジック用のカスタム コード ベースのスコアラーを作成します。
アプローチ | カスタマイズのレベル | ユースケース |
|---|---|---|
最小限(ガイドライン審査員にとっては中程度) |
組み込みジャッジには、応答がスタイルや事実ガイドラインなどのカスタム自然言語ルールに合格するか不合格になるかをチェックするガイドライン ジャッジ、組み込みジャッジも含まれます。 | |
フル | 詳細な評価基準とフィードバックの最適化を備えた、完全にカスタマイズされた LLM ジャッジを作成します。 数値スコア、カテゴリ、またはブール値を返すことができます。 | |
フル | 完全一致、形式の検証、パフォーマンス メトリックなどを評価する、プログラム的かつ決定論的なスコアラー。 | |
フル | オープンソース評価フレームワークから利用できる特殊なメトリクスが必要な場合。 |
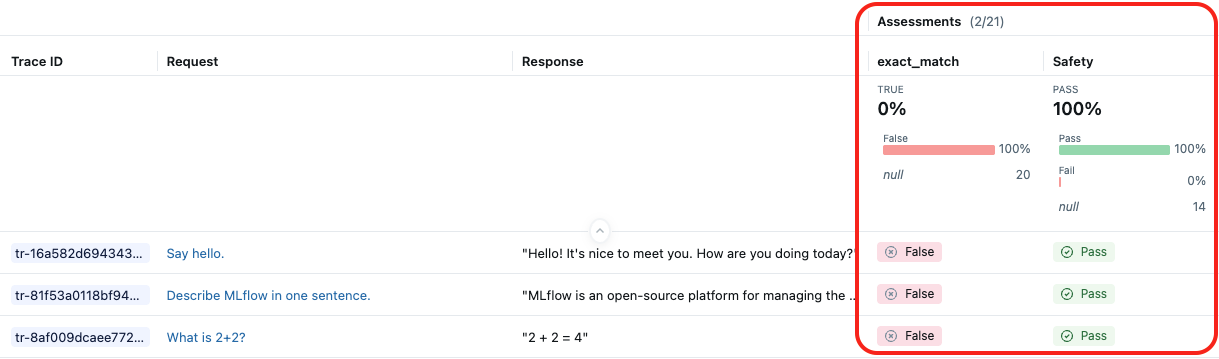
次のスクリーンショットは、組み込みの LLM ジャッジSafetyとカスタム スコアラーexact_matchの結果を示しています。
スコアラーの動作原理
スコアラーは、 evaluate()またはモニタリング サービスからトレースを受け取ります。 次に、次の操作を実行します。
traceを解析して、品質評価に使用される特定のフィールドとデータを抽出します。- 抽出されたフィールドとデータに基づいてスコアラーを実行し、品質評価を実行します。
- 品質評価を
Feedbackとして返します。trace
ジャッジとしてのLLM
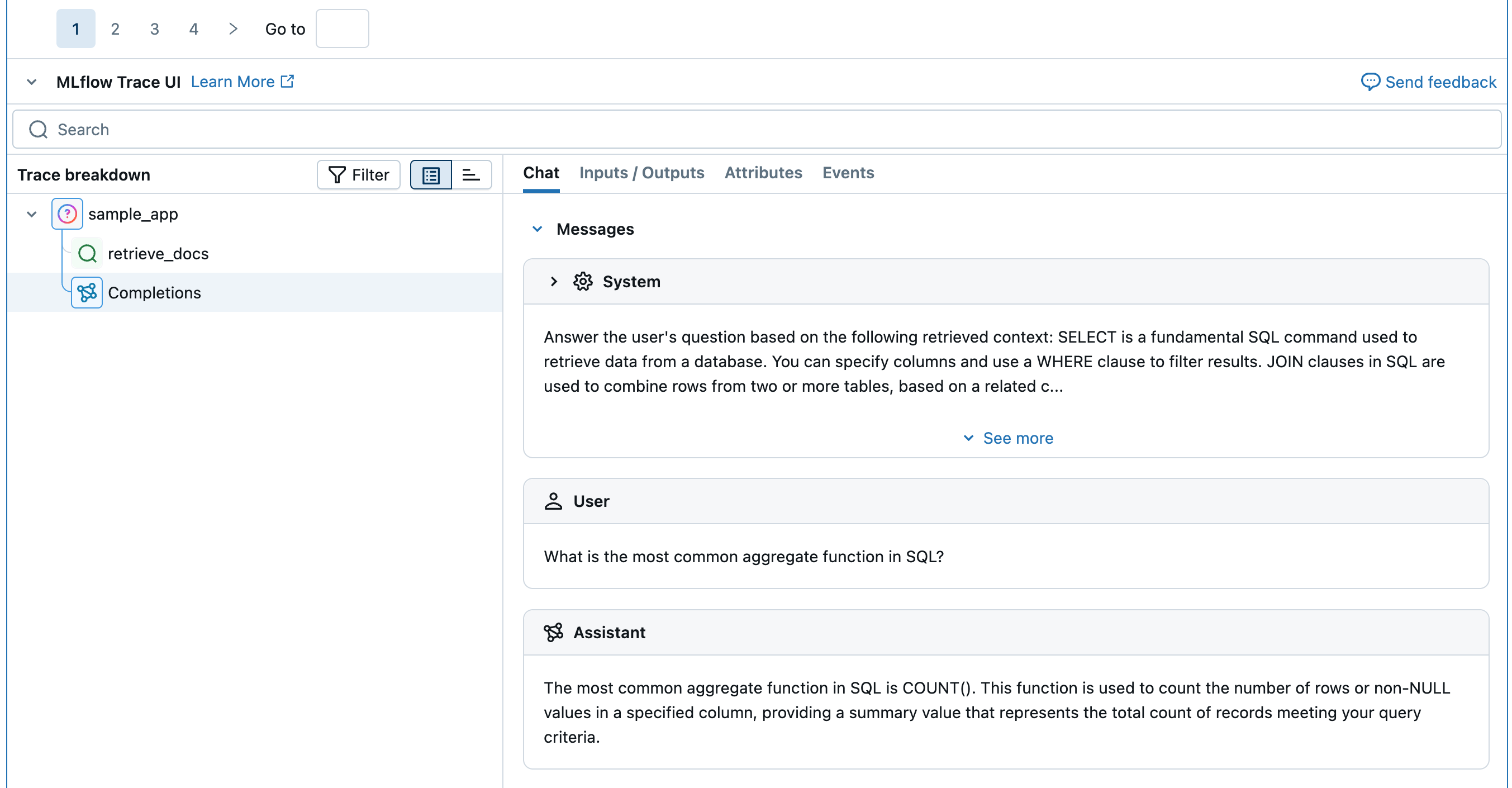
LLMジャッジは、品質評価に大規模言語モデルを使用する MLflow Scorerの一種です。
ジャッジを品質評価に特化した AI アシスタントと考えてください。アプリの入力、出力を評価し、実行トレース全体を調査して、定義した基準に基づいて評価を行うことができます。たとえば、ジャッジはgive me healthy food optionsとfood to keep me fitが類似したクエリであることを理解できます。
ジャッジは、LLM を使用して評価を行うスコアラーの一種です。これらをmlflow.genai.evaluate()で直接使用するか、カスタム スコアラーでラップして高度なスコアリング ロジックを実現します。
組み込みLLMジャッジ
MLflowは、関連性、安全性、根拠、正確性といった一般的な品質指標について、研究によって検証された組み込みの判定ツールを提供します。各裁判官の完全なリストと詳細なガイダンスについては、 「組み込みのLLM裁判官」を参照してください。
マルチターンジャッジ
会話型AIシステム向けに、MLflowは個々の発言ではなく会話全体を評価する組み込みの審査員も提供しています。複数ターン制審判員を参照してください。
カスタムLLMジャッジ
組み込みの審査員に加えて、カスタムプロンプトと指示を使用して独自の審査員を作成することもできます。
特定の評価タスクを定義する必要がある場合、成績やスコアをより細かく制御する必要がある場合(合格/不合格だけでなく)、またはエージェントが特定のユースケースに対して適切な判断を下し、操作を正しく実行したことを検証する必要がある場合は、カスタムLLMジャッジを使用してください。審査員の調整を使用してカスタムLLM審査員をトレーニングし、系統的なフィードバックを通じて人間の評価基準と一致させます。
カスタムジャッジを参照してください。
ジャッジをサポートするLLMを選択する
デフォルトでは、各ジャッジは 生成AIの品質評価を実行するために設計されたDatabricks ホスト LLMを使用します。ジャッジ定義内のmodel引数を使用してジャッジモデルを変更できます。モデルを<provider>:/<model-name>形式で指定します。例えば:
from mlflow.genai.scorers import Correctness
Correctness(model="databricks:/databricks-gpt-5-mini")
LLMジャッジを支援するモデルに関する情報
- LLMジャッジは、Microsoftが運営するAzure OpenAIなどのサードパーティサービスを使用して生成AIアプリケーションを評価する場合があります。
- Azure OpenAIの場合、Databricksは不正行為モニタリングをオプトアウトしているため、プロンプトや応答はAzure OpenAIに保存されません。
- 地域間処理が無効になっている場合、LLM判定者はワークスペースのDatabricks Geoでコンテンツを処理します。対象となるGeo内モデルが利用できない場合、判定者は地域制限エラーを返します。When cross-Geo processing is enabled, LLM judges can process content in other Geos.
- パートナーを利用したAI機能を無効にすると、 LLMジャッジがパートナーを利用したモデルを呼び出すことができなくなります。 独自のモデルを提供することで、LLM ジャッジを引き続き使用できます。
- LLM ジャッジは、顧客が生成AIエージェント/アプリケーションを評価するのを支援することを目的としており、ジャッジ LLM アウトプットを LLMのトレーニング、改善、または微調整に使用すべきではありません。
正確さを判断する
Databricks は、以下の方法でジャッジの質を継続的に向上させています。
- 人間の専門家の判断に対する 研究の検証
- メトリクス追跡 : コーエンのカッパ、精度、F1 スコア
- 学術データと実世界のデータセットを用いた 多様なテスト
コードベースのスコアラー
カスタム コード ベースのスコアラーは、生成AI アプリケーションの品質を測定する方法を正確に定義するための究極の柔軟性を提供します。単純なヒューリスティック、高度なロジック、プログラムによる評価など、特定のビジネスユースケースに合わせてカスタマイズされた評価メトリックを定義できます。
次のシナリオではカスタム スコアラーを使用します。
- カスタムヒューリスティックまたはコードベースの評価メトリクスを定義します。
- アプリのトレースのデータが組み込みの LLM ジャッジにマッピングされる方法をカスタマイズします。
- 評価には、Databricks がホストする LLM ジャッジではなく、独自の LLM を使用します。
- カスタム LLM ジャッジによって提供される以上の柔軟性と制御が必要なその他のユースケース。
コードベースのスコアラーを参照してください。