コードベースのスコアラーを開発する
MLflow Evaluation for GenAI では、カスタム コード ベースのスコアラーを使用して、 AIエージェントまたはアプリケーションの柔軟な評価メトリックを定義できます。
スコアラーを開発する際は、多くの場合、迅速に反復する必要があります。この開発者ワークフローを使用すると、毎回アプリ全体を再実行せずにスコアラーを更新できます。
- 評価データを定義する
- アプリからトレースを生成する
- 結果のトレースをクエリして保存する
- スコアラーを反復しながら、保存されたトレースを使用して評価します
サンプルノートブックには、このチュートリアルのすべてのコードが含まれています。
前提条件: MLflow を設定し、アプリケーションを定義する
最適な GenAI エクスペリエンスを実現するには、 mlflow[databricks]最新バージョンに更新し、以下のサンプル アプリは OpenAI クライアントを使用しているため、 openaiインストールしてください。
%pip install -q --upgrade "mlflow[databricks]>=3.1" "openai>=1.0.0"
dbutils.library.restartPython()
以下のmlflow.openai.autolog()呼び出しはMLflow Tracingを使用してアプリケーションを自動的にインストルメント化します。 記録されたトレースは、評価中にスコアラーへの入力になります。
import mlflow
mlflow.openai.autolog()
# If running outside of Databricks, set up MLflow tracking to Databricks.
# mlflow.set_tracking_uri("databricks")
# In Databricks notebooks, the experiment defaults to the notebook experiment.
# mlflow.set_experiment("/Shared/docs-demo")
databricks-openaiパッケージを使用して、Databricks がホストする LLM に接続する OpenAI クライアントを取得します。利用可能なプラットフォーム モデルからモデルを選択します。
from databricks_openai import DatabricksOpenAI
# Create an OpenAI client that is connected to Databricks-hosted LLMs
client = DatabricksOpenAI()
# Select an LLM
model_name = "databricks-claude-sonnet-4"
このチュートリアルでは、簡単な質問回答アシスタント アプリを作成します。
@mlflow.trace
def sample_app(messages: list[dict[str, str]]):
# 1. Prepare messages for the LLM
messages_for_llm = [
{"role": "system", "content": "You are a helpful assistant."},
*messages,
]
# 2. Call LLM to generate a response
response = client.chat.completions.create(
model= model_name,
messages=messages_for_llm,
)
return response.choices[0].message.content
sample_app([{"role": "user", "content": "What is the capital of France?"}])
ステップ 1: 評価データを定義する
以下の評価データは、LLM が回答する要求のリストです。このアプリの場合、リクエストは簡単な質問や複数のメッセージを含む会話になります。
eval_dataset = [
{
"inputs": {
"messages": [
{"role": "user", "content": "How much does a microwave cost?"},
]
},
},
{
"inputs": {
"messages": [
{
"role": "user",
"content": "Can I return the microwave I bought 2 months ago?",
},
]
},
},
{
"inputs": {
"messages": [
{
"role": "user",
"content": "I'm having trouble with my account. I can't log in.",
},
{
"role": "assistant",
"content": "I'm sorry to hear that you're having trouble with your account. Are you using our website or mobile app?",
},
{"role": "user", "content": "Website"},
]
},
},
]
ステップ 2: アプリからトレースを生成する
アプリからトレースを生成するには、 mlflow.genai.evaluate()を使用します。evaluate()には少なくとも 1 つのスコアラーが必要なので、この初期トレース生成用のプレースホルダー スコアラーを定義します。
from mlflow.genai.scorers import scorer
@scorer
def placeholder_metric() -> int:
# placeholder return value
return 1
プレースホルダー スコアラーを使用して評価を実行します。
eval_results = mlflow.genai.evaluate(
data=eval_dataset,
predict_fn=sample_app,
scorers=[placeholder_metric]
)
上記のコードを実行すると、評価データセットの行ごとに 1 つのトレースがエクスペリメントに作成されるはずです。 Databricksノートブックでは、セルの結果の一部としてトレースの視覚化も表示されます。 評価中にsample_appによって生成されたLLMの応答は、ノートブック Trace UI の [出力] フィールドとMLflowエクスペリメント UI の [応答] 列に表示されます。
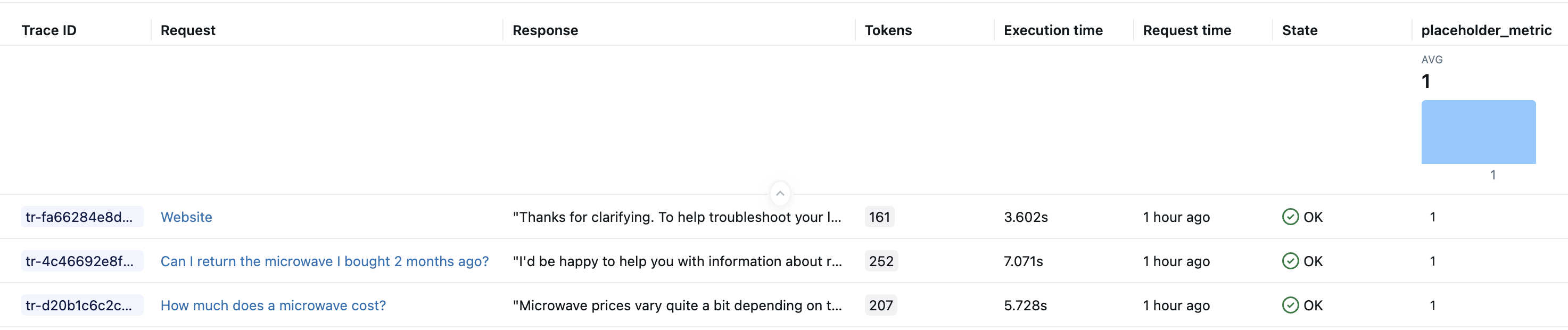
ステップ 3: 結果のトレースをクエリして保存する
生成されたトレースをローカル変数に保存します。mlflow.search_traces()関数は、トレースの Pandas DataFrame を返します。
generated_traces = mlflow.search_traces(run_id=eval_results.run_id)
generated_traces
ステップ 4: スコアラーを反復処理しながら、保存されたトレースを使用してevaluate()呼び出します
トレースの Pandas DataFrame を入力データセットとして直接evaluate()に渡します。これにより、アプリを再実行することなく、メトリクスを迅速に繰り返すことができます。 以下のコードは、事前計算されたgenerated_tracesに対して新しいスコアラーを実行します。
from mlflow.genai.scorers import scorer
@scorer
def response_length(outputs: str) -> int:
# Example metric.
# Implement your actual metric logic here.
return len(outputs)
# Note the lack of a predict_fn parameter.
mlflow.genai.evaluate(
data=generated_traces,
scorers=[response_length],
)
サンプルノートブック
次のノートブックにはこのページのすべてのコードが含まれています。
MLflow 評価のコードベーススコアラーの開発者ワークフロー
その他のリソース
- カスタムLLMスコアラー- コードベースのスコアラーよりも簡単に定義できる、 LLMを判断基準として使用するメトリクスを使用したセマンティック評価について学習します。
- 本番運用での実行スコアラー- 継続的なモニタリングのためにスコアラーをデプロイします。
- 評価データセットの構築- スコアラー用のテスト データを作成します。
- コードベースのスコアラーリファレンス- 署名、入力、出力、メトリクス命名、エラー処理、シークレットへのアクセスなど、
@scorerとScorerリファレンス。