はじめに: 生成AI向けMLflow Tracing (Databricksノートブック)
このクイックスタートは、開発環境として ノートブックを使用する場合に、生成AI アプリをMLflow Tracing Databricksと統合するのに役立ちます。ローカル IDE を使用している場合は、代わりに IDE クイックスタート を使用してください。
このチュートリアルを終了すると、次のことができるようになります。
- 生成AIアプリ用のMLflowエクスペリメントがリンクされたDatabricksノートブック
- MLflow Tracing で計測可能になったシンプルな 生成AI アプリケーション
- MLflowエクスペリメント内のそのアプリからのトレース
環境設定
-
Databricks ワークスペースに新しいノートブックを作成します。ノートブックには、GenAI アプリケーションのコンテナーである安全MLflowエクスペリメントがあります。 MLflowエクスペリメントの詳細については、 MLflow概念」セクションをご覧ください。
-
必要なパッケージをインストールします。
mlflow[databricks]: より多くの機能と改善を得るには、最新バージョンの MLflow を使用してください。openai: このチュートリアルでは、OpenAI API クライアントを使用して、Databricks でホストされるモデルを呼び出します。
%pip install -qq --upgrade "mlflow[databricks]>=3.1.0" openai
dbutils.library.restartPython()
ステップ 1: トレースを使用してアプリケーションを計測する
以下のコード スニペットは、LLM を使用して文テンプレートを完成させる単純な 生成AI アプリを定義します。
まず、 Databricks がホストする基盤モデルに接続するための OpenAI クライアントを作成します。
from databricks_openai import DatabricksOpenAI
# Create an OpenAI client that is connected to Databricks-hosted LLMs
client = DatabricksOpenAI()
model_name = "databricks-claude-sonnet-4"
あるいは、OpenAI SDK を使用して OpenAI がホストするモデルに接続することもできます。
import openai
# Ensure your OPENAI_API_KEY is set in your environment
# os.environ["OPENAI_API_KEY"] = "<YOUR_API_KEY>" # Uncomment and set if not globally configured
client = openai.OpenAI()
model_name = "gpt-4o-mini"
次に、アプリケーションを定義して実行します。トレースを使用してアプリをインストルメント化するには、次のコードを使用します。
mlflow.openai.autolog(): OpenAI SDK への呼び出しの詳細をキャプチャするための自動インストルメンテーション@mlflow.trace: Python関数を簡単にトレースできるデコレータ
import mlflow
import os
# Enable auto-tracing for OpenAI
mlflow.openai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/tracing-quickstart")
# Use the trace decorator to capture the application's entry point
@mlflow.trace
def my_app(input: str):
# This call is automatically instrumented by `mlflow.openai.autolog()`
response = client.chat.completions.create(
model=model_name,
temperature=0.1,
max_tokens=200,
messages=[
{
"role": "system",
"content": "You are a helpful assistant.",
},
{
"role": "user",
"content": input,
},
]
)
return response.choices[0].message.content
result = my_app(input="What is MLflow?")
print(result)
アプリにトレースを追加する方法の詳細については、トレース インストルメンテーション ガイドと20以上のライブラリ連携を参照してください。
ステップ 2: MLflowでトレースを表示する
トレースはノートブックのセルの下に表示されます。
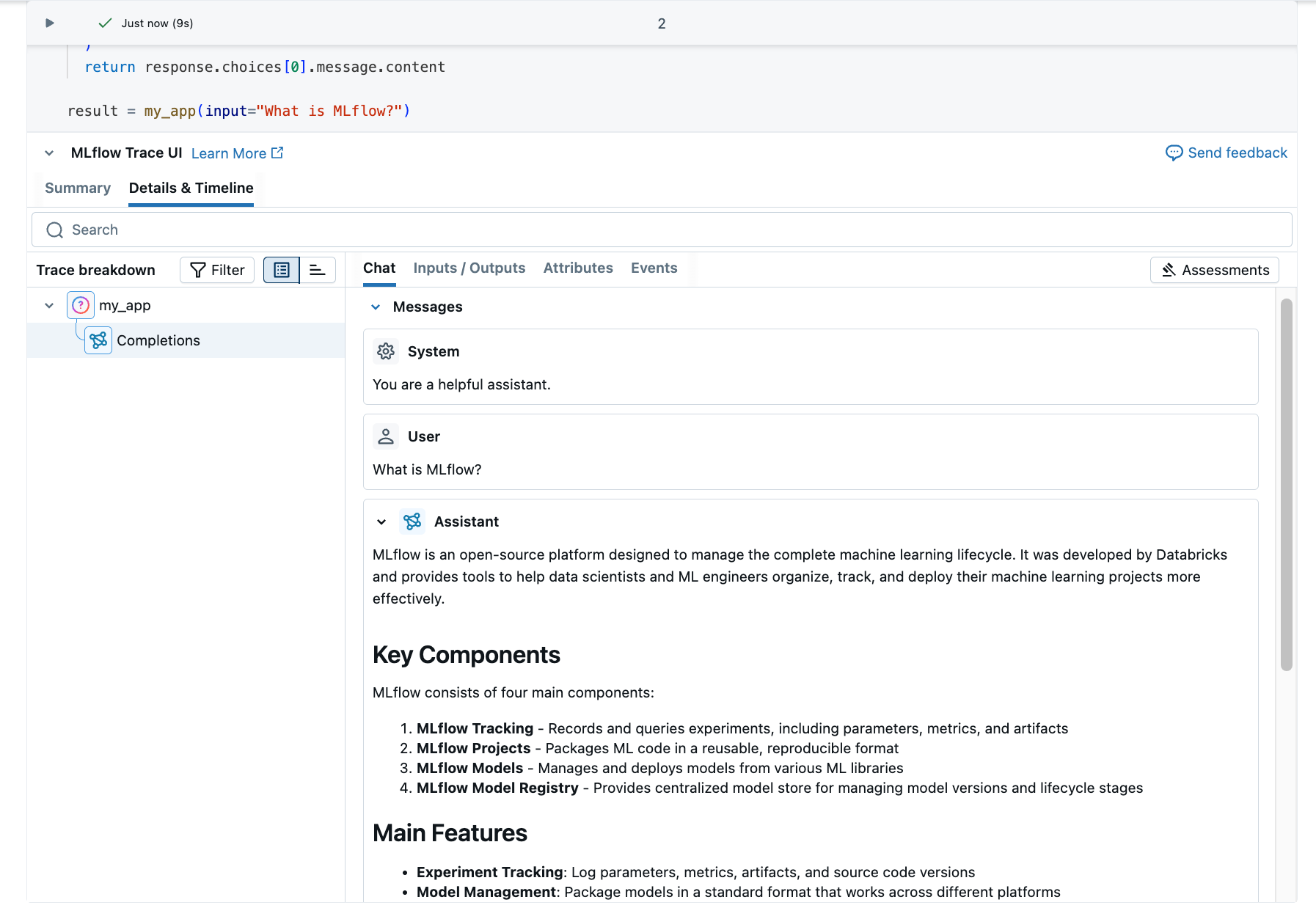
オプションとして、 MLflowエクスペリメントUIにアクセスしてトレースを表示することもできます。
- エクスペリメントアイコンをクリックします
 右側のサイドバーにあります。
右側のサイドバーにあります。 - エクスペリメントの実行の横にある新しいウィンドウアイコン
 をクリックします。
をクリックします。 - 生成されたトレースが [トレース] タブに表示されます。
- トレースをクリックして、その詳細を表示します。
トレースを理解する
作成したトレースは次のように表示されます。
-
ルートスパン :
my_app(...)関数への入力を表します- 子スパン : OpenAI完了リクエストを表す
-
属性 : モデル名、トークン数、タイミング情報などのメタデータが含まれます
-
入力 : モデルに送信されたメッセージ
-
出力 : モデルから受信した応答
この単純なトレースは、次のようなアプリケーションの動作に関する貴重な知見をすでに提供しています。
- 質問されたこと
- どのようなレスポンスが生成されたか
- リクエストにかかった時間
- 使用されたトークンの数 (コストに影響)
RAGシステムやマルチステップエージェントのようなより複雑なアプリケーションの場合、 MLflow Tracing は各コンポーネントとステップの内部動作を明らかにすることで、さらに多くの価値を提供します。
次のステップ
- MLflow Tracingガイド- MLflow Tracingについてさらに詳しく知りたい場合は、ここから始めてください。
- MLflow Tracing統合- 自動トレース統合を備えた 20 以上のライブラリ
- トレースの概念 - MLflow Tracingの基本を理解する