Anthropicのトレース
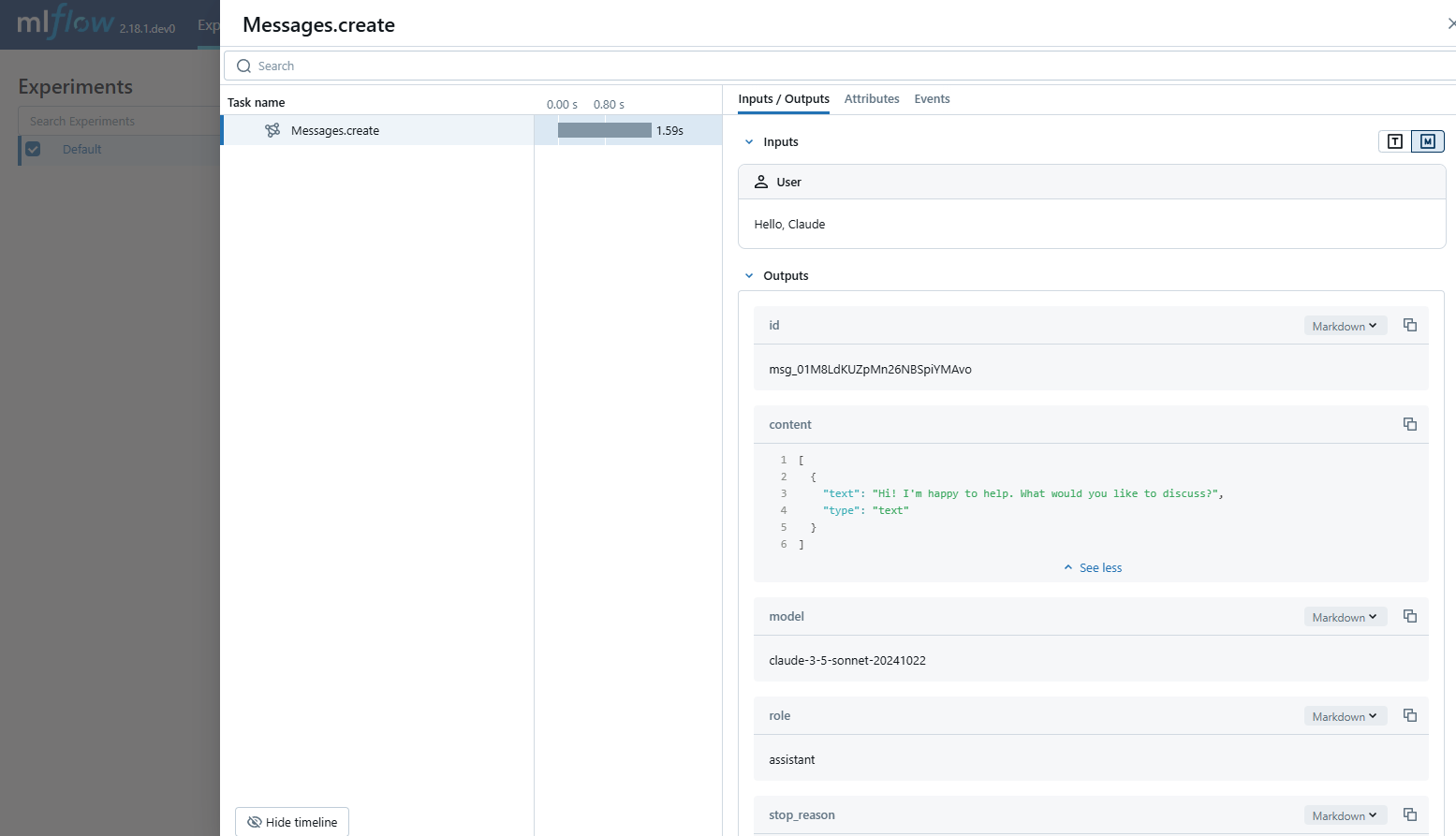
MLflow Tracing は、Anthropic LLM の自動トレース機能を提供します。自動トレースを有効にする
mlflow.anthropic.autolog関数を呼び出すことでAnthropicの場合、MLflowネストされたトレースをキャプチャし、Anthropic Python SDKの呼び出し時にアクティブなエクスペリメントMLflowに記録します。
import mlflow
mlflow.anthropic.autolog()
MLflow トレースでは、Anthropic 呼び出しに関する次の情報が自動的にキャプチャされます。
- プロンプトと完了応答
- 待ち時間
- モデル名
temperature、max_tokensなどの追加のメタデータ (指定されている場合)。- 応答で返された場合の関数呼び出し
- 例外が発生した場合
サーバレス コンピュート クラスターでは、自動ログは自動的に有効になりません。 この統合の自動トレースを有効にするには、明示的に mlflow.anthropic.autolog() を呼び出す必要があります。
現在、MLflow Anthropic 統合では、テキスト操作の同期呼び出しのトレースのみがサポートされています。非同期 APIs はトレースされず、マルチモーダル入力の完全な入力を記録することはできません。
前提 条件
AnthropicでMLflow Tracingを使用するには、MLflowと Anthropic SDKをインストールする必要があります。
- Development
- Production
開発環境の場合は、Databricks の追加機能と anthropicを含む完全な MLflow パッケージをインストールします。
pip install --upgrade "mlflow[databricks]>=3.1" anthropic
フル mlflow[databricks] パッケージには、Databricks でのローカル開発と実験のためのすべての機能が含まれています。
本番運用デプロイメントの場合は、 mlflow-tracing と anthropicをインストールします。
pip install --upgrade mlflow-tracing anthropic
mlflow-tracingパッケージは、本番運用での使用に最適化されています。
Anthropic で最適なトレース エクスペリエンスを得るには、MLflow 3 を強くお勧めします。
以下の例を実行する前に、環境を構成する必要があります。
Databricks ノートブックの外部ユーザーの場合 : Databricks 環境変数を設定します。
export DATABRICKS_HOST="https://your-workspace.cloud.databricks.com"
export DATABRICKS_TOKEN="your-personal-access-token"
Databricks ノートブック内のユーザーの場合 : これらの資格情報は自動的に設定されます。
APIキー :Anthropic APIキーが正しく設定されていることを確認してください。本番運用で使用する場合は、環境変数の代わりにAI Gateway またはDatabricksシークレットを使用することをお勧めします。
export ANTHROPIC_API_KEY="your-anthropic-api-key"
サポートされている APIs
MLflow は、次の Anthropic APIsの自動トレースをサポートしています。
チャット完了 | 関数呼び出し | ストリーミング | 非同期 | 画像 | バッチ |
|---|---|---|---|---|---|
✅ | ✅ | ✅ (※1) |
(*1)非同期のサポートは MLflow 2.21.0 で追加されました。
追加のAPIのサポートをリクエストするには、GitHubで 機能リクエスト をオープンしてください。
基本的な例
import anthropic
import mlflow
import os
# Ensure your ANTHROPIC_API_KEY is set in your environment
# os.environ["ANTHROPIC_API_KEY"] = "your-anthropic-api-key" # Uncomment and set if not globally configured
# Enable auto-tracing for Anthropic
mlflow.anthropic.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/anthropic-tracing-demo")
# Configure your API key.
client = anthropic.Anthropic(api_key=os.environ["ANTHROPIC_API_KEY"])
# Use the create method to create new message.
message = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1024,
messages=[
{"role": "user", "content": "Hello, Claude"},
],
)
本番運用環境の場合は、ハードコードされた値や環境変数の代わりに、常にAI Gateway またはDatabricksシークレットを使用してください。
非同期
import anthropic
import mlflow
import os
# Ensure your ANTHROPIC_API_KEY is set in your environment
# os.environ["ANTHROPIC_API_KEY"] = "your-anthropic-api-key" # Uncomment and set if not globally configured
# Enable trace logging
mlflow.anthropic.autolog()
# Set up MLflow tracking to Databricks if not already configured
# mlflow.set_tracking_uri("databricks")
# mlflow.set_experiment("/Shared/anthropic-async-demo")
client = anthropic.AsyncAnthropic()
response = await client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1024,
messages=[
{"role": "user", "content": "Hello, Claude"},
],
)
高度な例: ツール呼び出しエージェント
MLflow Tracing は、 Anthropic モデルからのツール呼び出し応答を自動的にキャプチャします。 応答内の関数命令は、トレース UI で強調表示されます。さらに、 @mlflow.trace デコレータを使用してツール関数に注釈を付けて、ツール実行のスパンを作成できます。
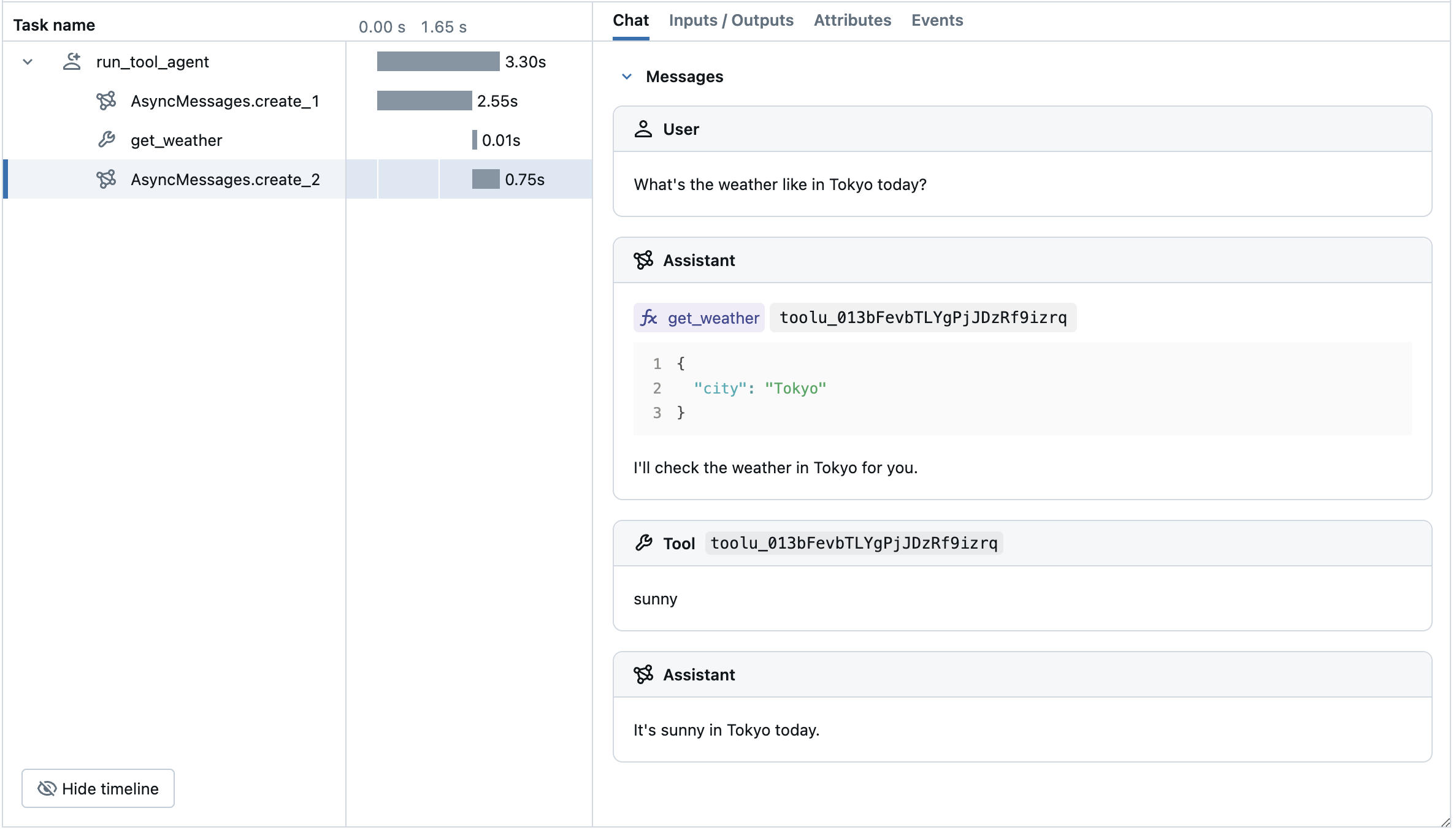
次の例では、Anthropicのツール呼び出しと MLflow Tracing for Anthropic を使用して、エージェントを呼び出す単純な関数を実装します。この例では、エージェントがブロックせずに並列呼び出しを処理できるように、非同期 Anthropic SDK をさらに使用します。
import json
import anthropic
import mlflow
import asyncio
from mlflow.entities import SpanType
import os
# Ensure your ANTHROPIC_API_KEY is set in your environment
# os.environ["ANTHROPIC_API_KEY"] = "your-anthropic-api-key" # Uncomment and set if not globally configured
# Set up MLflow tracking to Databricks if not already configured
# mlflow.set_tracking_uri("databricks")
# mlflow.set_experiment("/Shared/anthropic-tool-agent-demo")
# Assuming autolog is enabled globally or called earlier
# mlflow.anthropic.autolog()
client = anthropic.AsyncAnthropic()
model_name = "claude-3-5-sonnet-20241022"
# Define the tool function. Decorate it with `@mlflow.trace` to create a span for its execution.
@mlflow.trace(span_type=SpanType.TOOL)
async def get_weather(city: str) -> str:
if city == "Tokyo":
return "sunny"
elif city == "Paris":
return "rainy"
return "unknown"
tools = [
{
"name": "get_weather",
"description": "Returns the weather condition of a given city.",
"input_schema": {
"type": "object",
"properties": {"city": {"type": "string"}},
"required": ["city"],
},
}
]
_tool_functions = {"get_weather": get_weather}
# Define a simple tool calling agent
@mlflow.trace(span_type=SpanType.AGENT)
async def run_tool_agent(question: str):
messages = [{"role": "user", "content": question}]
# Invoke the model with the given question and available tools
ai_msg = await client.messages.create(
model=model_name,
messages=messages,
tools=tools,
max_tokens=2048,
)
messages.append({"role": "assistant", "content": ai_msg.content})
# If the model requests tool call(s), invoke the function with the specified arguments
tool_calls = [c for c in ai_msg.content if c.type == "tool_use"]
for tool_call in tool_calls:
if tool_func := _tool_functions.get(tool_call.name):
tool_result = await tool_func(**tool_call.input)
else:
raise RuntimeError("An invalid tool is returned from the assistant!")
messages.append(
{
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": tool_call.id,
"content": tool_result,
}
],
}
)
# Send the tool results to the model and get a new response
response = await client.messages.create(
model=model_name,
messages=messages,
max_tokens=2048,
)
return response.content[-1].text
# Run the tool calling agent
cities = ["Tokyo", "Paris", "Sydney"]
questions = [f"What's the weather like in {city} today?" for city in cities]
answers = await asyncio.gather(*(run_tool_agent(q) for q in questions))
for city, answer in zip(cities, answers):
print(f"{city}: {answer}")
自動トレースを無効にする
Anthropic の自動トレースは、 mlflow.anthropic.autolog(disable=True) または mlflow.autolog(disable=True)を呼び出すことで、グローバルに無効にできます。