Geminiのトレース
MLflow Tracing は、Google Gemini の自動トレース機能を提供します。自動トレースを有効にする
mlflow.gemini.autolog 関数を呼び出すことで Gemini の場合、MLflow ネストされたトレースをキャプチャし、Gemini Python SDKの呼び出し時にアクティブなエクスペリメントMLflowに記録します。
Python
import mlflow
mlflow.gemini.autolog()
MLflow トレースは、Gemini 呼び出しに関する次の情報を自動的にキャプチャします。
- プロンプトと完了応答
- 待ち時間
- モデル名
temperature、max_tokensなどの追加のメタデータ (指定されている場合)。- 応答で返された場合の関数呼び出し
- 例外が発生した場合
注記
サーバレス コンピュート クラスターでは、自動ログは自動的に有効になりません。 この統合の自動トレースを有効にするには、明示的に mlflow.gemini.autolog() を呼び出す必要があります。
注記
現在、MLflow Gemini 統合では、テキスト操作の同期呼び出しのトレースのみがサポートされています。非同期 APIs はトレースされず、マルチモーダル入力では完全な入力が記録されない場合があります。
基本的な例
Python
import mlflow
import google.genai as genai
import os
# Turn on auto tracing for Gemini
mlflow.gemini.autolog()
# Set up MLflow tracking on Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/gemini-demo")
# Configure the SDK with your API key.
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# Use the generate_content method to generate responses to your prompts.
response = client.models.generate_content(
model="gemini-1.5-flash", contents="The opposite of hot is"
)
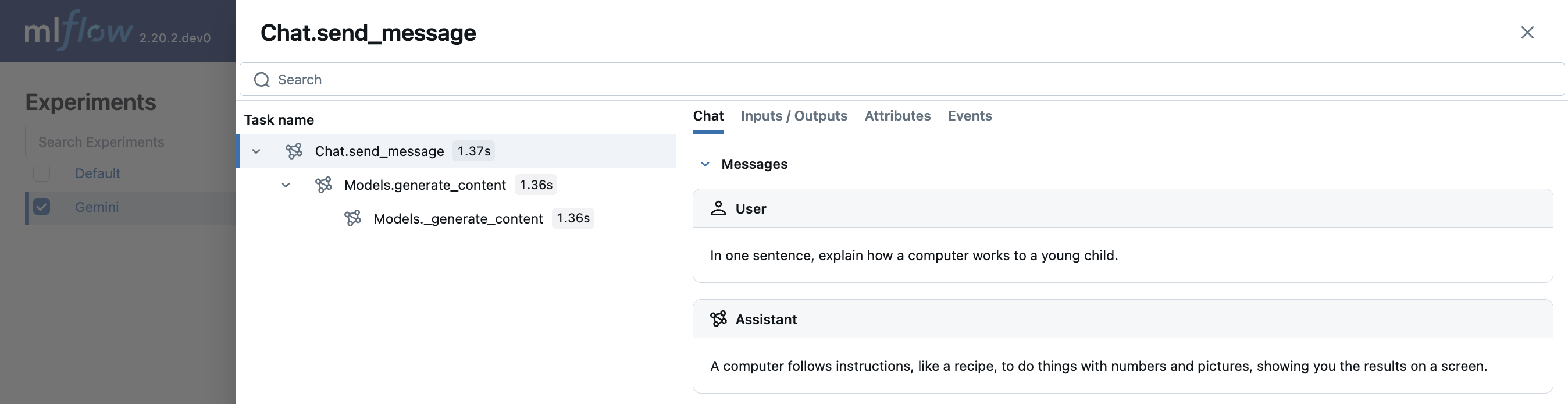
マルチターンチャットインタラクション
MLflow は、Gemini を使用したマルチターン会話のトレースをサポートしています。
import mlflow
mlflow.gemini.autolog()
chat = client.chats.create(model='gemini-1.5-flash')
response = chat.send_message("In one sentence, explain how a computer works to a young child.")
print(response.text)
response = chat.send_message("Okay, how about a more detailed explanation to a high schooler?")
print(response.text)
エンベディング
Gemini SDKにおけるMLflow Tracingでは、エンベディングAPI がサポートされています。
Python
result = client.models.embed_content(model="text-embedding-004", contents="Hello world")
自動トレースを無効にする
Gemini の自動トレースは、 mlflow.gemini.autolog(disable=True) または mlflow.autolog(disable=True)を呼び出すことでグローバルに無効にできます。
その他のリソース
- トレースの概念を理解する - MLflow でトレース データをキャプチャして整理する方法を学習します
- アプリのデバッグと監視 - Trace UI を使用して、Gemini アプリケーションの動作を分析します
- アプリの品質を評価する - Gemini 搭載アプリケーションの品質評価を設定します