Ollamaのトレース
Ollama は、Llama 3.2、Gemma 2、Mistral、Code Llama などの大規模言語モデル (LLM) をデバイス上でローカルに実行できるようにするオープンソース プラットフォームです。
Ollama が提供するローカル LLM エンドポイントは OpenAI API と互換性があるため、OpenAI SDK を介してクエリを実行し、mlflow.openai.autolog()を使用して Ollama のトレースを有効にすることができます。Ollama を介した LLM のやり取りは、アクティブなエクスペリメント MLflow 記録されます。
Python
import mlflow
mlflow.openai.autolog()
注記
サーバレス コンピュート クラスタでは、生成 AI トレースフレームワークの自動ログは自動的に有効になりません。 トレースする特定の統合に対して適切な mlflow.<library>.autolog() 関数を呼び出して、自動ログを明示的に有効にする必要があります。
使用例
- 目的の LLM モデルで Ollama サーバーを実行します。
Bash
ollama run llama3.2:1b
- OpenAI SDK の自動トレースを有効にします。
import mlflow
# Enable auto-tracing for OpenAI
mlflow.openai.autolog()
# Set up MLflow tracking on Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/ollama-demo")
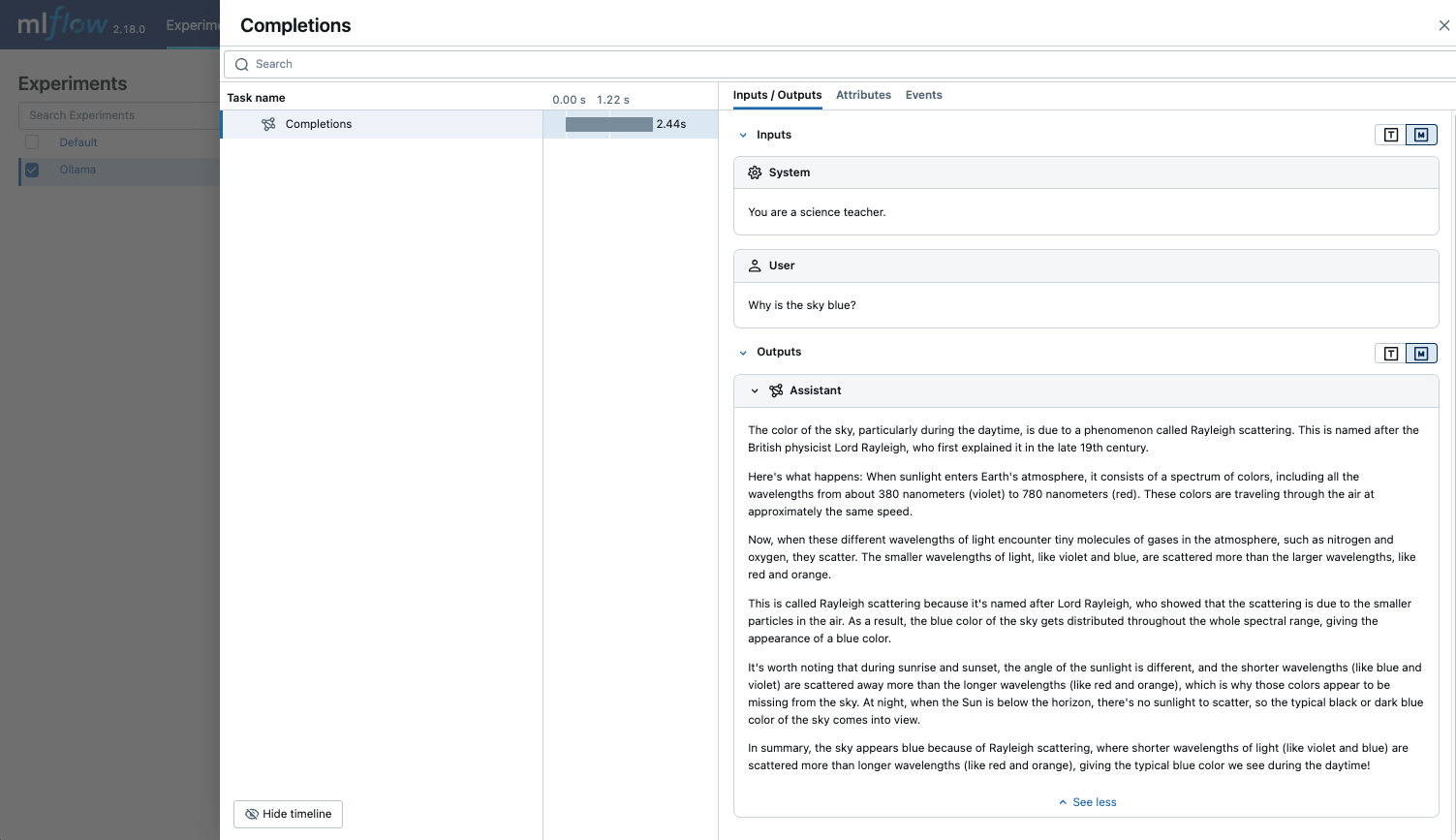
- LLM をクエリし、MLflow UI でトレースを確認します。
Python
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1", # The local Ollama REST endpoint
api_key="dummy", # Required to instantiate OpenAI client, it can be a random string
)
response = client.chat.completions.create(
model="llama3.2:1b",
messages=[
{"role": "system", "content": "You are a science teacher."},
{"role": "user", "content": "Why is the sky blue?"},
],
)
自動トレースを無効にする
Ollama の自動トレースは、 mlflow.openai.autolog(disable=True) または mlflow.autolog(disable=True)を呼び出すことで、グローバルに無効にできます。
その他のリソース
- トレースの概念を理解する - MLflow でトレース データをキャプチャして整理する方法を学習します
- アプリのデバッグと監視 - トレース UI を使用して、ローカルで実行される Ollama モデルを分析します
- アプリの品質を評価する - Ollama を利用したアプリケーションの品質評価を設定します