txtai のトレース
TXTAI は、セマンティック検索、 LLM オーケストレーション、言語モデルワークフローのためのオールインワンのエンベディングデータベースです。
MLflow Tracing は、txtaiの自動トレース機能を提供します。txtai の自動トレースは、mlflow.autolog 関数を呼び出すことで有効になり、MLflow は LLM の呼び出し、埋め込み、AI 検索のトレースをキャプチャし、アクティブな MLflow エクスペリメントに記録します。
前提 条件
txtai で MLflow Tracing を使用するには、 MLflowと txtai ライブラリ、 mlflow-txtai 拡張機能をインストールする必要があります。
- Development
- Production
開発環境の場合は、Databricks extras、 txtai、 mlflow-txtaiを含む完全な MLflow パッケージをインストールします。
pip install --upgrade "mlflow[databricks]>=3.1" txtai mlflow-txtai
フル mlflow[databricks] パッケージには、Databricks でのローカル開発と実験のためのすべての機能が含まれています。
本番運用デプロイメントの場合は、 mlflow-tracing、 txtai、 mlflow-txtaiをインストールします。
pip install --upgrade mlflow-tracing txtai mlflow-txtai
mlflow-tracingパッケージは、本番運用での使用に最適化されています。
MLflow 3 は、txtai で最適なトレース エクスペリエンスを実現することを強くお勧めします。
例を実行する前に、環境を構成する必要があります。
Databricks ノートブックの外部ユーザーの場合 : Databricks 環境変数を設定します。
export DATABRICKS_HOST="https://your-workspace.cloud.databricks.com"
export DATABRICKS_TOKEN="your-personal-access-token"
Databricks ノートブック内のユーザーの場合 : これらの資格情報は自動的に設定されます。
API キー : LLM プロバイダーの API キーが設定されていることを確認します。
export OPENAI_API_KEY="your-openai-api-key"
# Add other provider keys as needed if using txtai with different models
基本的な例
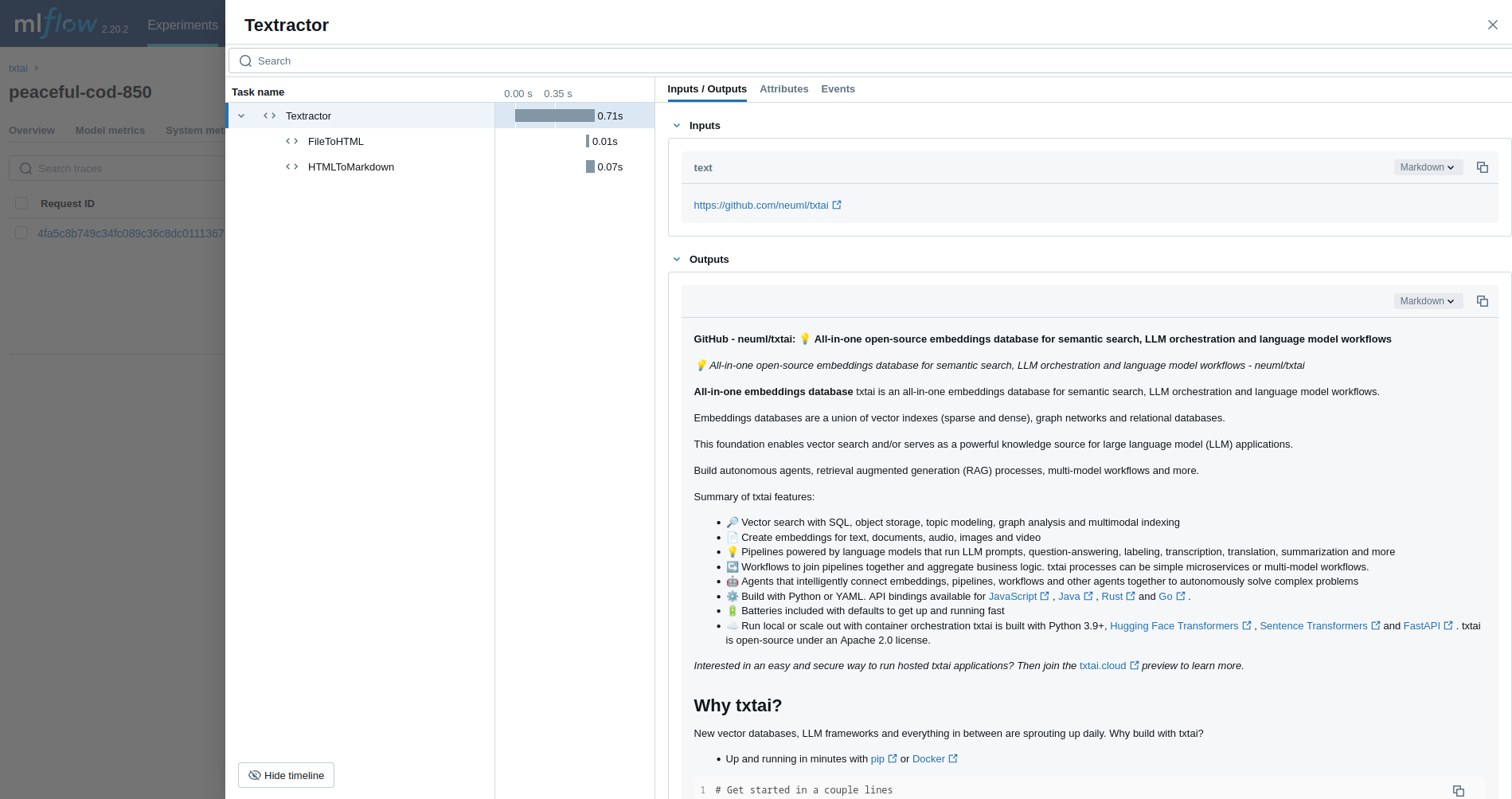
最初の例では、 Textractor パイプラインをトレースします。
サーバレス コンピュート クラスタでは、生成 AI トレースフレームワークの自動ログは自動的に有効になりません。 トレースする特定の統合に対して適切な mlflow.<library>.autolog() 関数を呼び出して、自動ログを明示的に有効にする必要があります。
import mlflow
from txtai.pipeline import Textractor
import os
# Ensure any necessary LLM provider API keys are set in your environment if Textractor uses one
# For example, if it internally uses OpenAI:
# os.environ["OPENAI_API_KEY"] = "your-openai-key"
# Enable MLflow auto-tracing for txtai
mlflow.txtai.autolog()
# Set up MLflow tracking to Databricks
mlflow.set_tracking_uri("databricks")
mlflow.set_experiment("/Shared/txtai-demo")
# Define and run a simple Textractor pipeline.
textractor = Textractor()
textractor("https://github.com/neuml/txtai")
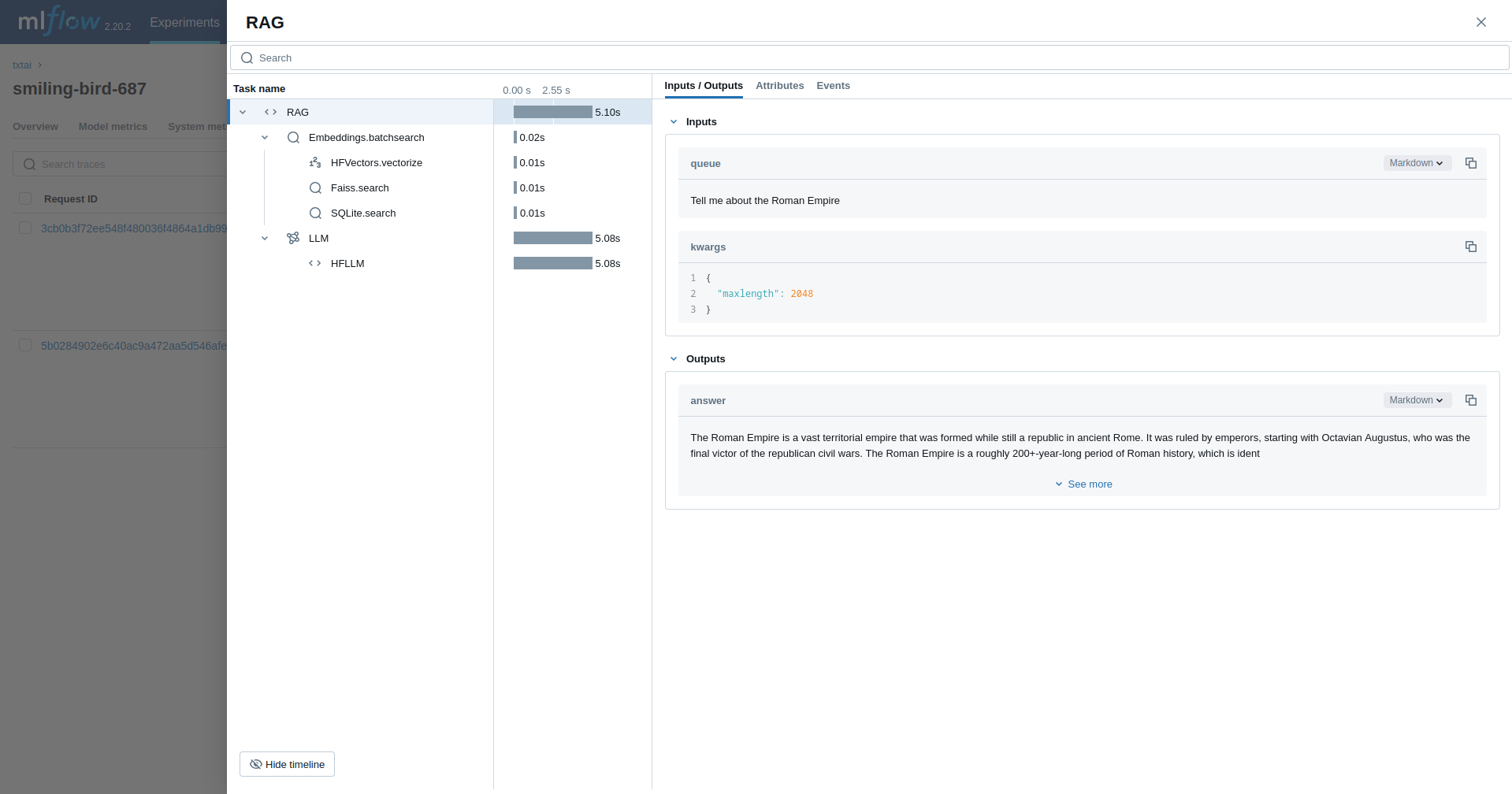
検索拡張生成(RAG)
次の例では、 RAG パイプラインをトレースします。
import mlflow
from txtai import Embeddings, RAG
import os
# Ensure your LLM provider API key (e.g., OPENAI_API_KEY for the Llama model via some services) is set
# os.environ["OPENAI_API_KEY"] = "your-key" # Or HUGGING_FACE_HUB_TOKEN, etc.
# Enable MLflow auto-tracing for txtai
mlflow.txtai.autolog()
# Set up MLflow tracking to Databricks if not already configured
# mlflow.set_tracking_uri("databricks")
# mlflow.set_experiment("/Shared/txtai-rag-demo")
wiki = Embeddings()
wiki.load(provider="huggingface-hub", container="neuml/txtai-wikipedia-slim")
# Define prompt template
template = """
Answer the following question using only the context below. Only include information
specifically discussed.
question: {question}
context: {context} """
# Create RAG pipeline
rag = RAG(
wiki,
"hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4",
system="You are a friendly assistant. You answer questions from users.",
template=template,
context=10,
)
rag("Tell me about the Roman Empire", maxlength=2048)
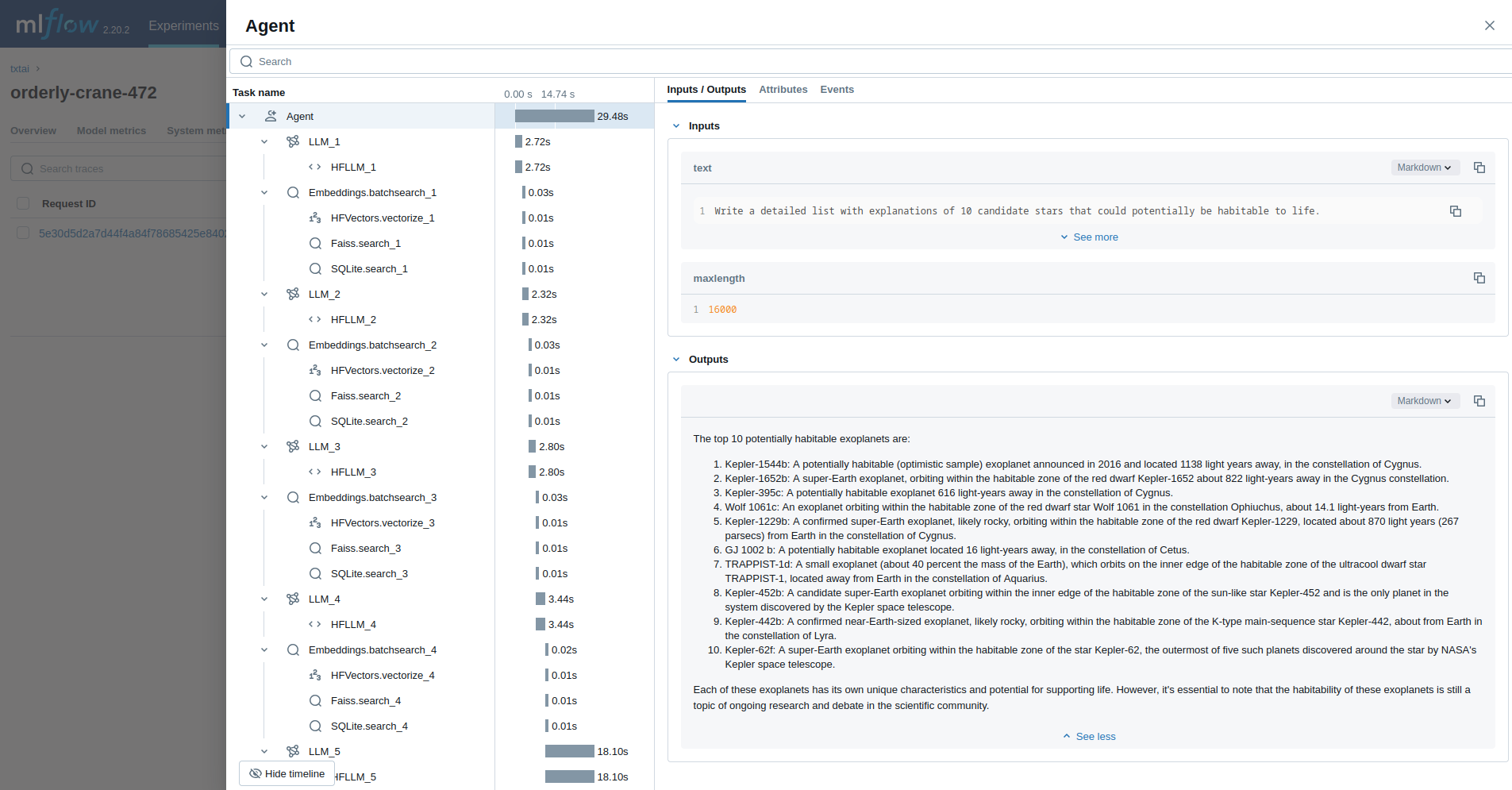
エージェント
最後の例では、天文学の問題を調査するために設計された txtai エージェント を実行します。
import mlflow
from txtai import Agent, Embeddings
import os
# Ensure your LLM provider API key (e.g., OPENAI_API_KEY for the Llama model via some services) is set
# os.environ["OPENAI_API_KEY"] = "your-key" # Or HUGGING_FACE_HUB_TOKEN, etc.
# Enable MLflow auto-tracing for txtai
mlflow.txtai.autolog()
# Set up MLflow tracking to Databricks if not already configured
# mlflow.set_tracking_uri("databricks")
# mlflow.set_experiment("/Shared/txtai-agent-demo")
def search(query):
"""
Searches a database of astronomy data.
Make sure to call this tool only with a string input, never use JSON.
Args:
query: concepts to search for using similarity search
Returns:
list of search results with for each match
"""
return embeddings.search(
"SELECT id, text, distance FROM txtai WHERE similar(:query)",
10,
parameters={"query": query},
)
embeddings = Embeddings()
embeddings.load(provider="huggingface-hub", container="neuml/txtai-astronomy")
agent = Agent(
tools=[search],
llm="hugging-quants/Meta-Llama-3.1-8B-Instruct-AWQ-INT4",
max_iterations=10,
)
researcher = """
{command}
Do the following.
- Search for results related to the topic.
- Analyze the results
- Continue querying until conclusive answers are found
- Write a Markdown report
"""
agent(
researcher.format(
command="""
Write a detailed list with explanations of 10 candidate stars that could potentially be habitable to life.
"""
),
maxlength=16000,
)
その他のリソース
MLflowでtxtaiを使用するその他の例とガイダンスについては、MLflow txtai拡張機能のドキュメントをご覧ください。
その他のリソース
- トレースの概念を理解する - MLflow が RAG およびエージェント ワークフローのトレース データをキャプチャして整理する方法を学習します
- アプリのデバッグと監視 - Trace UI を使用して、txtai アプリケーションの動作を分析します
- アプリの品質を評価する - セマンティック検索とRAGアプリケーションの品質評価を設定します