Databricks MLflow UI でトレースを表示する
キャプチャされたすべてのトレースは、 MLflowエクスペリメントに記録されます。 Databricks ワークスペースの MLflow UI からアクセスできます。
MLFLOW_TRACKING_URIがdatabricksに設定されている場合、トレースは Databricks ワークスペース内の管理された MLflow Tracking サービスによって保存され、提供されます。この作品はすぐに使えるバックエンドで、追加のホスティングは必要ありません。「Databricks にデプロイされたトレース エージェント」を参照してください。
-
エクスペリメントに移動する : トレースが記録されているエクスペリメントに移動します。 たとえば、
mlflow.set_experiment("/Shared/my-genai-app-traces")によって設定されたエクスペリメント)。 -
「トレース」タブを開きます 。「エクスペリメント」ビューで「 トレース」 タブをクリックすると、そのエクスペリメントに記録されたすべてのトレースのリストが表示されます。
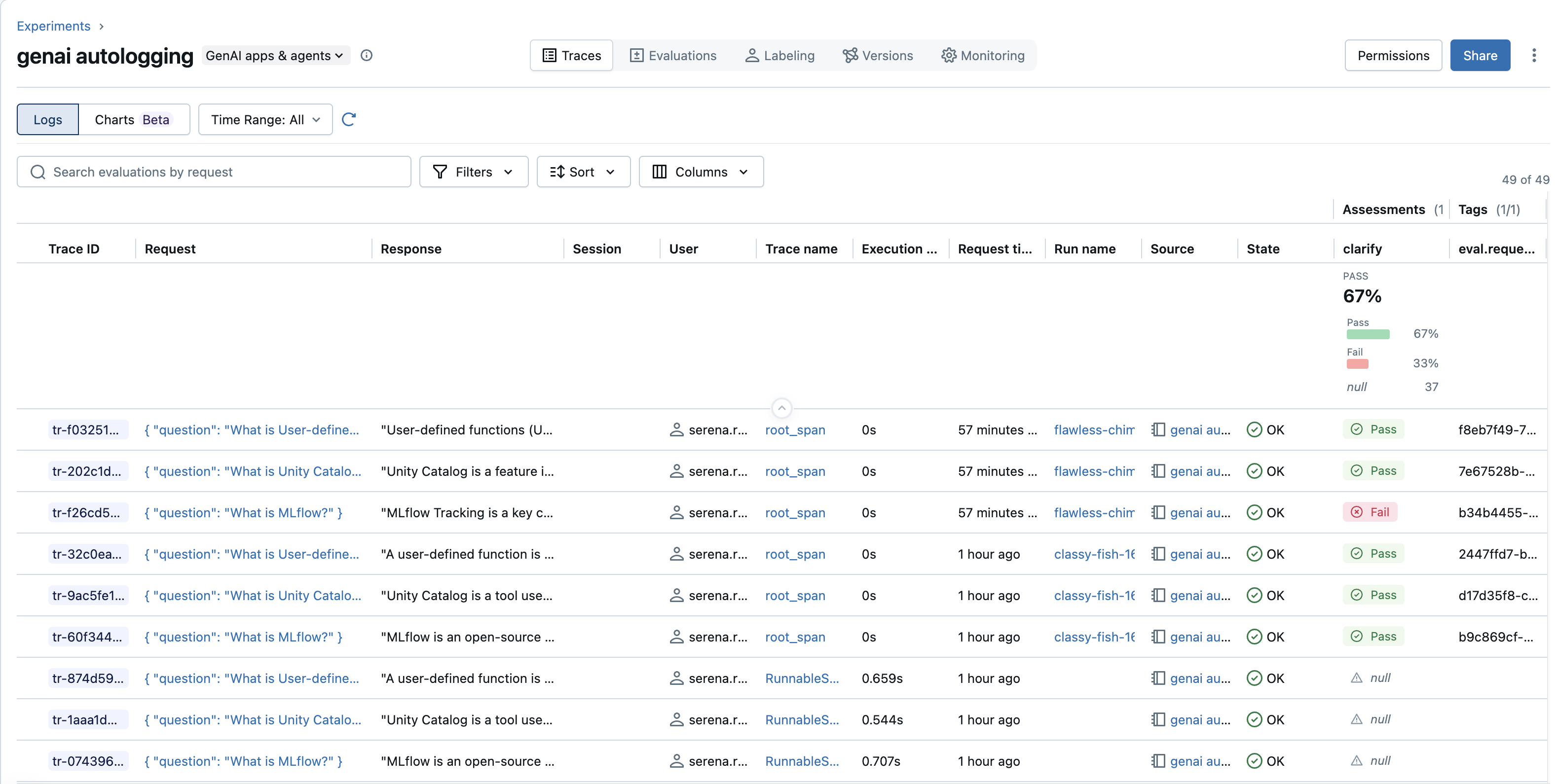
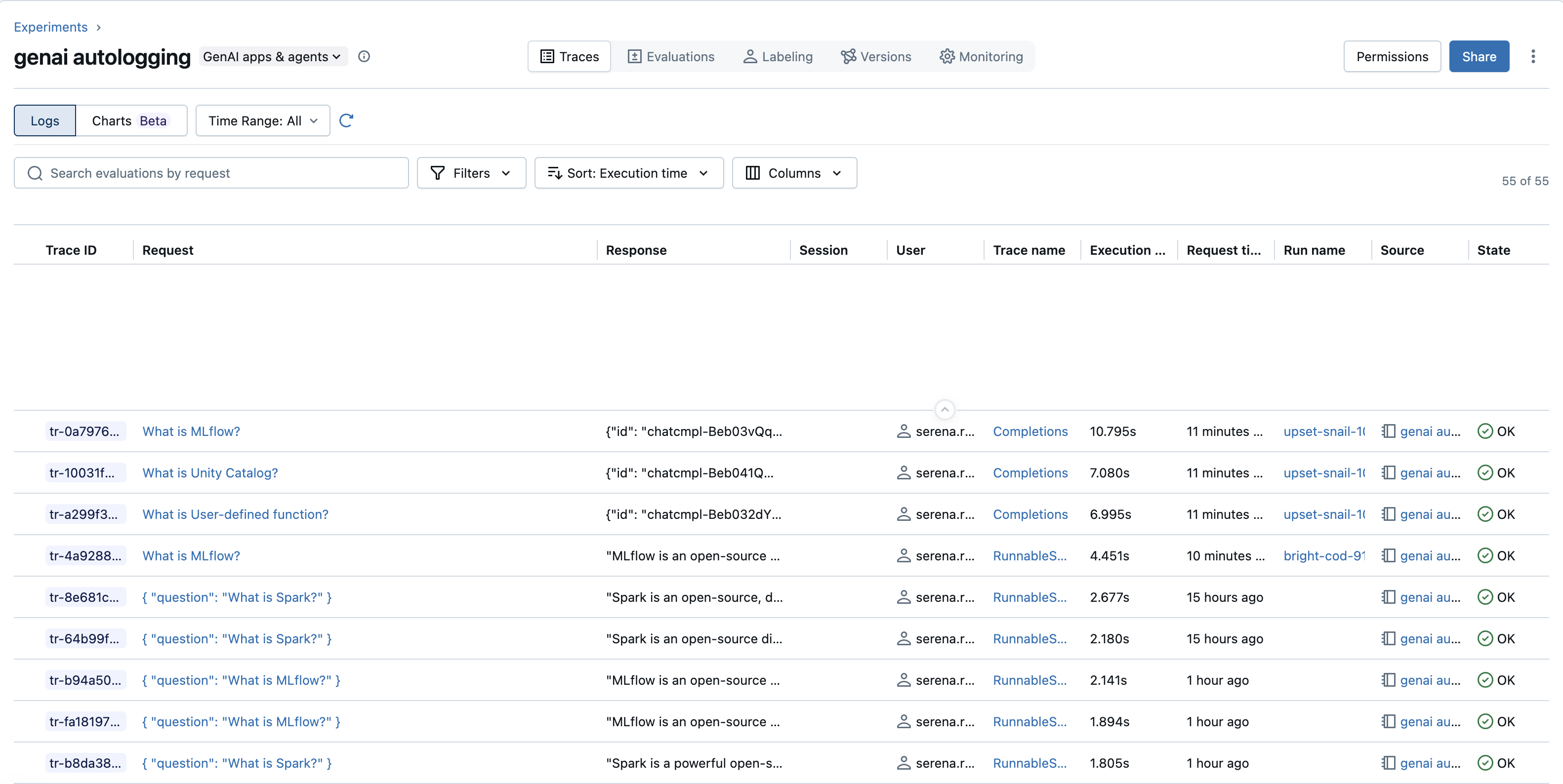
トレースリストを理解する
トレース リストには、通常次のような並べ替え可能な列を含むトレースの概要が表示されます。
- トレース ID : 各トレースの一意の識別子。
- リクエスト : トレースをトリガーした最初の入力のプレビュー。
- 応答 : トレースの最終出力のプレビュー。
- セッション : セッション識別子 (指定されている場合)。関連するトレースをグループ化します (例: 会話内)。
- ユーザー : 指定されている場合のユーザー識別子。
- 実行時間 : トレース完了までにかかる合計時間。
- リクエスト時間 : トレースが開始されたときのタイムスタンプ。
- 実行名 : トレースが MLflow 実行に関連付けられている場合は、その名前がここに表示され、それらがリンクされます。
- ソース : トレースの起源。多くの場合、インストルメントされたライブラリまたはコンポーネントを示します (例:
openai、langchain、またはカスタム トレース名)。 - ステータス : トレースの現在のステータス (
OK、ERROR、IN_PROGRESSなど)。 - トレース名 : このトレースに割り当てられた特定の名前。多くの場合、ルート スパンの名です。
- 評価 : 評価タイプごとに個別の列 (例:
my_scorer、professional)。UI では、リストの上に、現在表示されているトレースの集計された評価メトリック (平均値や合格/不合格率など) を示す概要セクションが表示されることもよくあります。 - タグ : 個々のタグは列として表示できます (例:
persona、style)。 タグの概要カウントも表示されることがあります。
トレースの検索とフィルタリング
UI には、関連するトレースを検索してフォーカスするためのいくつかの方法が用意されています。
-
検索バー (多くの場合、「リクエストによる評価の検索」などのラベルが付いています): これにより、
Request(入力) フィールドの内容を検索して、トレースをすばやく見つけることができます。 -
フィルター ドロップダウン : より構造化されたフィルター処理を行うには、「フィルター」ドロップダウンを使用します。 これにより、通常、以下に基づいてクエリを構築できます。
- 属性 :
Requestコンテンツ、Session time、Execution time、Request timeなど。 - 評価 : 評価の存在または特定の値 (
my_scorerやprofessionalなど) でフィルターします。 State、Trace name、Session、User、Tagsなどのその他のフィールド (例:tags.persona = 'expert')。
- 属性 :
-
並べ替えドロップダウン : [並べ替え] ドロップダウンを使用して、
Request time、Execution timeなどのさまざまな列ごとにトレースを並べ替えます。 -
列ドロップダウン : 特定のタグや評価メトリクスなど、トレース リストに表示される列をカスタマイズします。

メタデータフィルター
MLflow UI (トレースタブ) では、アタッチされたメタデータを表示できます。
次の検索クエリを使用して、MLflow UI でトレースをフィルターします。
# Find all traces for a specific user
metadata.`mlflow.trace.user` = 'user-123'
# Find all traces in a session
metadata.`mlflow.trace.session` = 'session-abc-456'
# Find traces for a user within a specific session
metadata.`mlflow.trace.user` = 'user-123' AND metadata.`mlflow.trace.session` = 'session-abc-456'
# Find traces from production environment
metadata.`mlflow.source.type` = 'production'
# Find traces from a specific app version
metadata.app_version = '1.0.0'
個々のトレースを探索する
特定のトレースの詳細を確認するには、リストからその**リクエスト**または**トレース名**をクリックします。これにより、2つのメインタブがある詳細なトレースビューが開きます。
- 概要 :トレースの概要です。このタブには、ルートスパンの入力と出力、主要な中間スパン、およびトレース中に発生した例外が表示されます。 デフォルト 、 JSON 、および テーブル のトグルを使用して、タブの入力と出力の表示方法を変更します。
- 詳細とタイムライン :各スパンの詳細を含む完全な内訳です。次のセクションでは、このビューについて説明します。
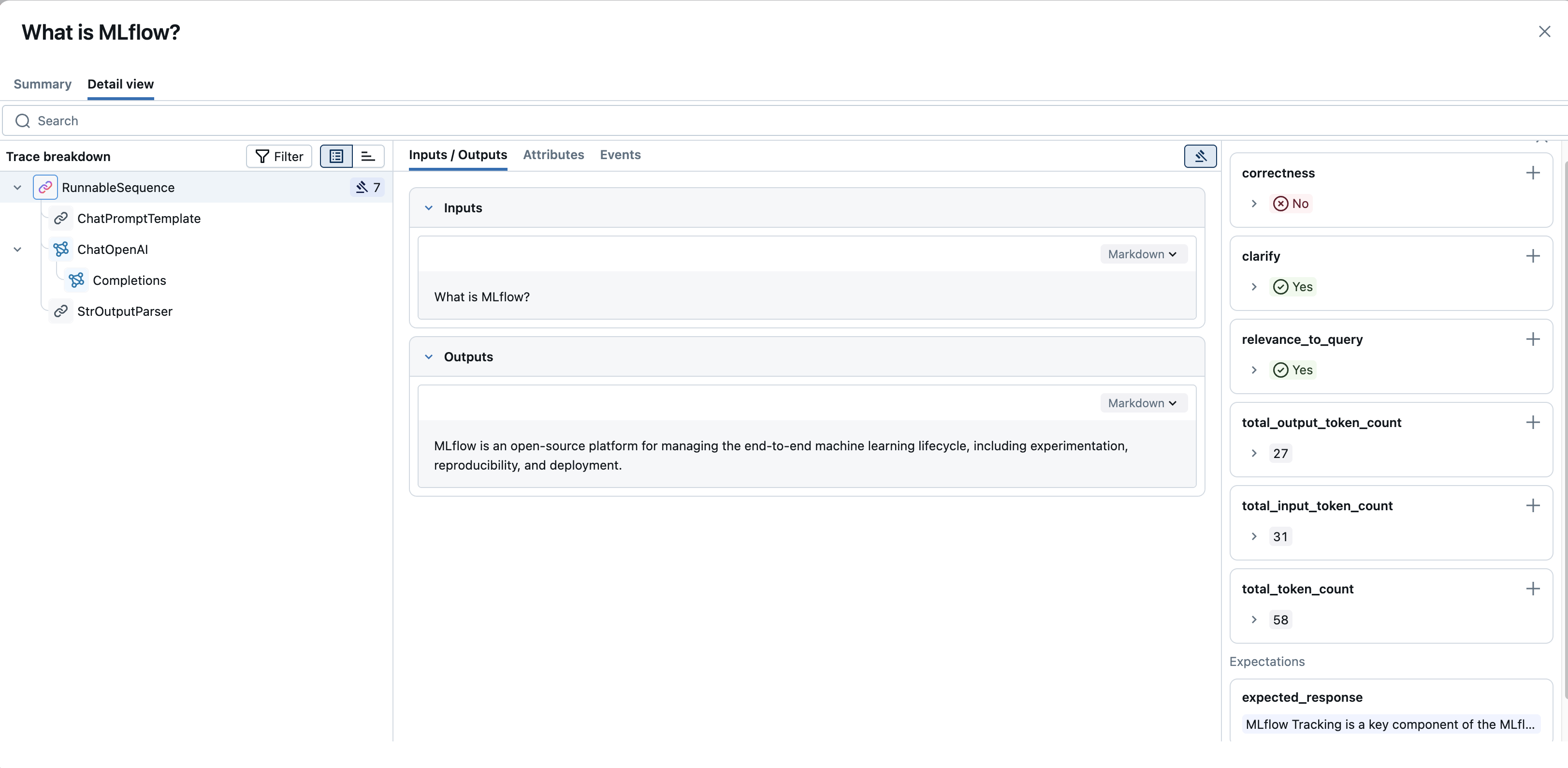
詳細とタイムライン タブには、いくつかの主要なパネルがあります:
-
トレースの内訳(左パネル) :
- このパネル (多くの場合、「トレースの内訳」というタイトル) には、 スパン階層が ツリー チャートまたはウォーターフォール チャートとして表示されます。トレース内のすべての操作 (スパン)、それらの親子関係、実行順序と期間が表示されます。
- この内訳から個々のスパンを選択し、その具体的な詳細を調べることができます。
-
スパンの詳細(中央パネル) :
-
トレースの内訳からスパンを選択すると、このパネルにその詳細情報が表示されます。通常は次のようなタブにまとめられています。
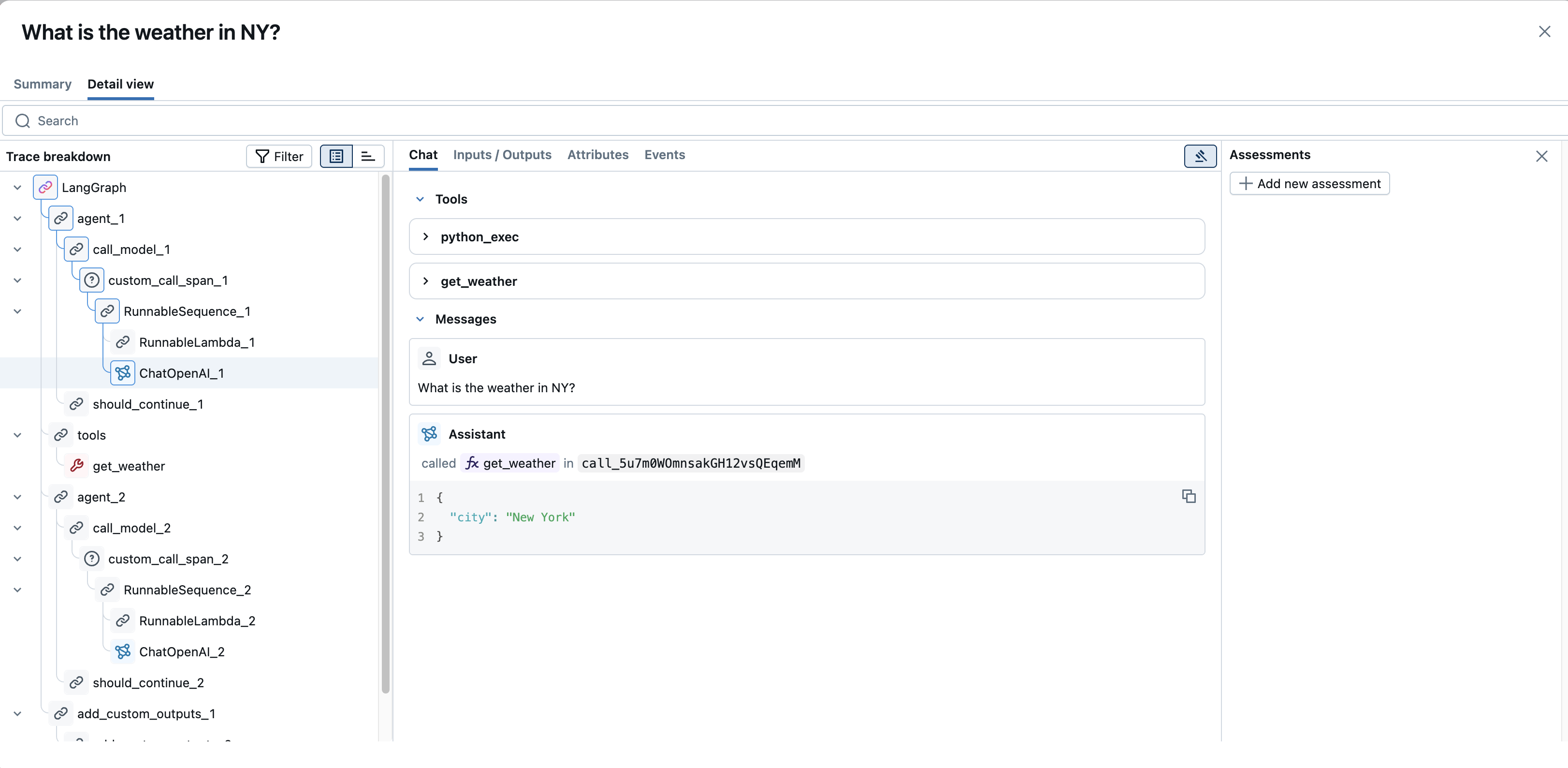
- チャット : チャットベースの LLM インタラクションの場合、このタブには会話フロー (ユーザー、アシスタント、ツール メッセージ) のレンダリングされたビューが表示されることがよくあります。
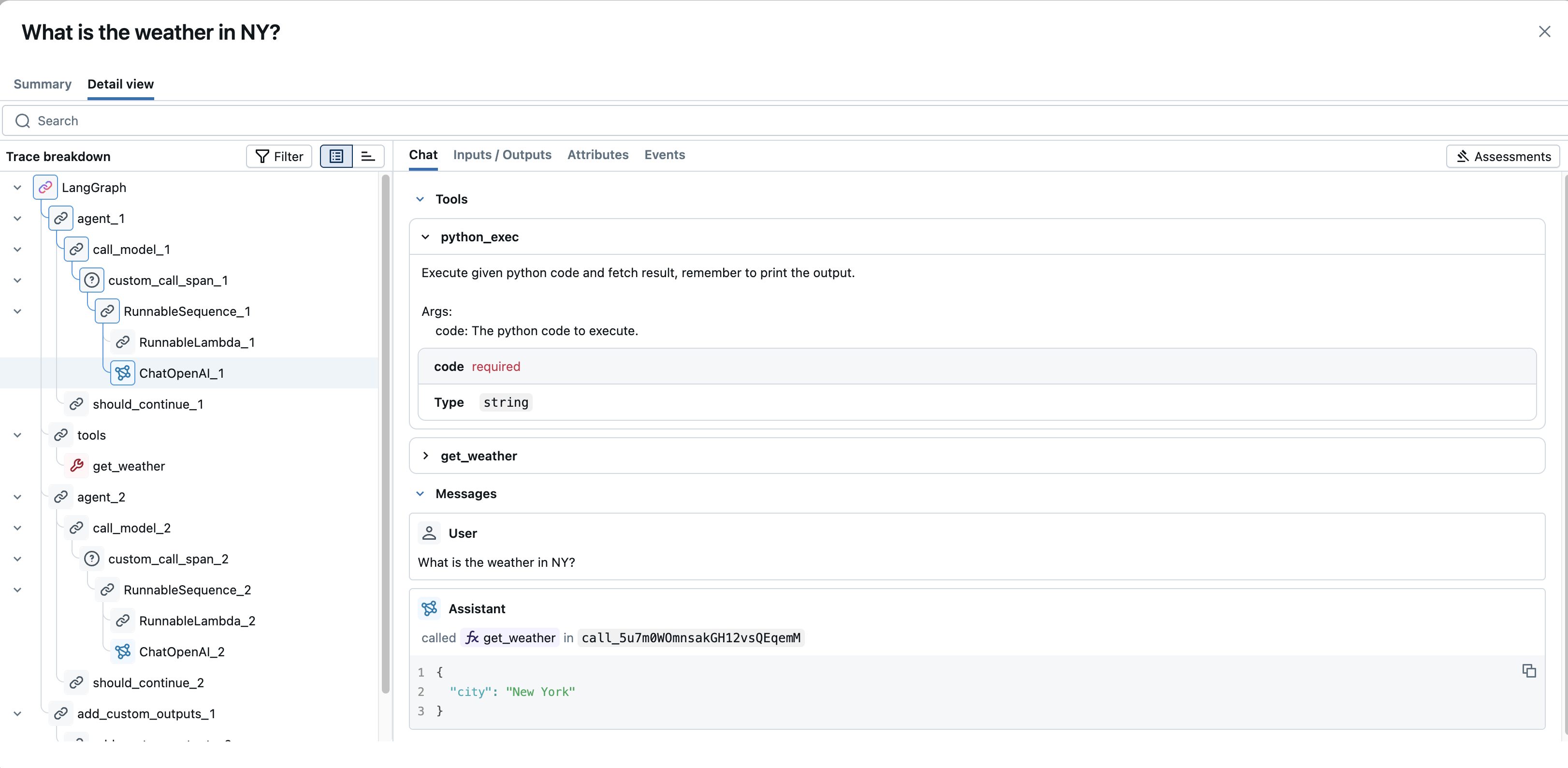
- 入力 / 出力 : 操作に渡された生の入力データと返された生の出力データを表示します。大きなコンテンツの場合は、「表示を増やす」/「表示を減らす」切り替えを使用して、ビューを展開または折りたたむことができます。
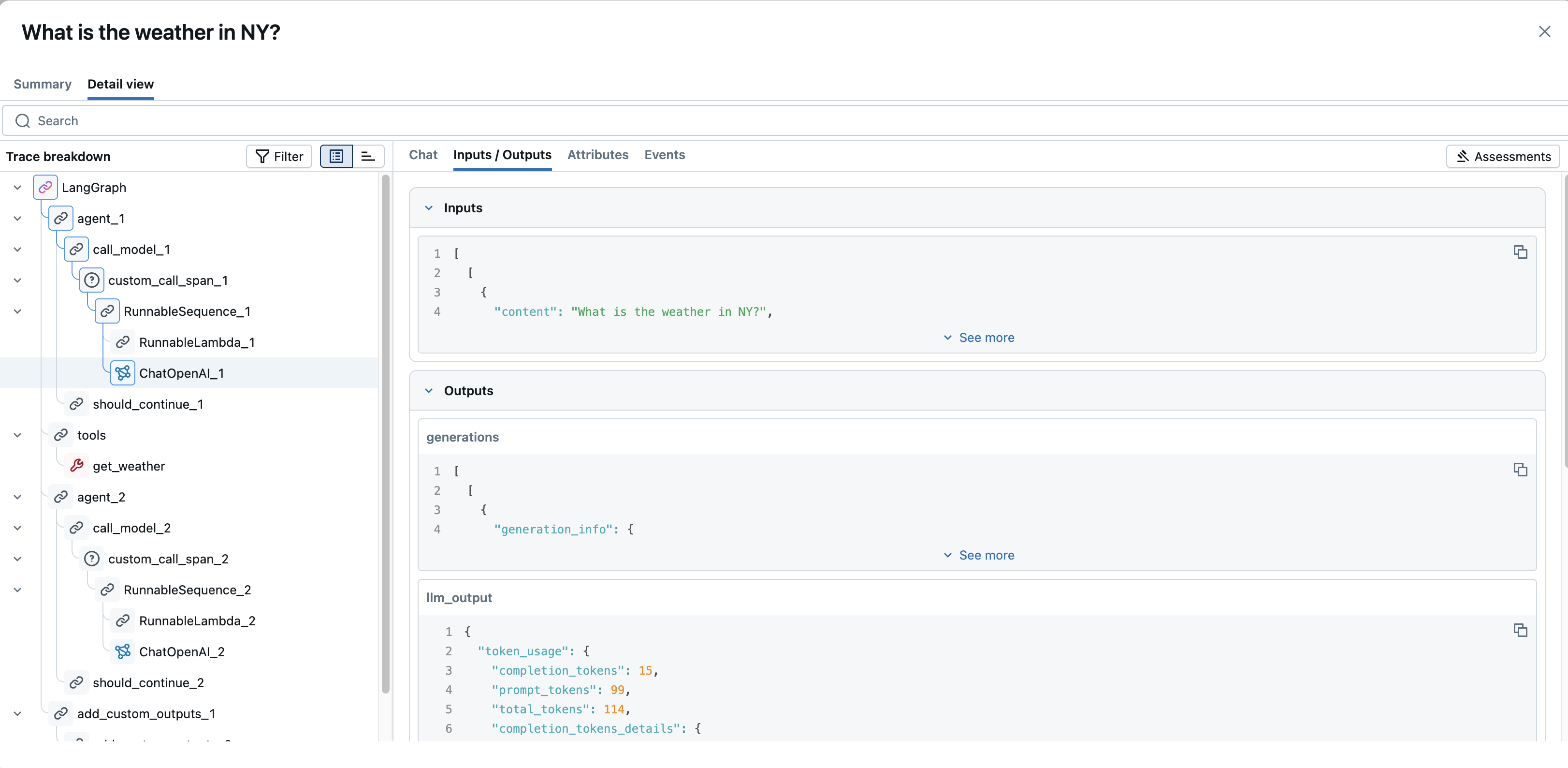
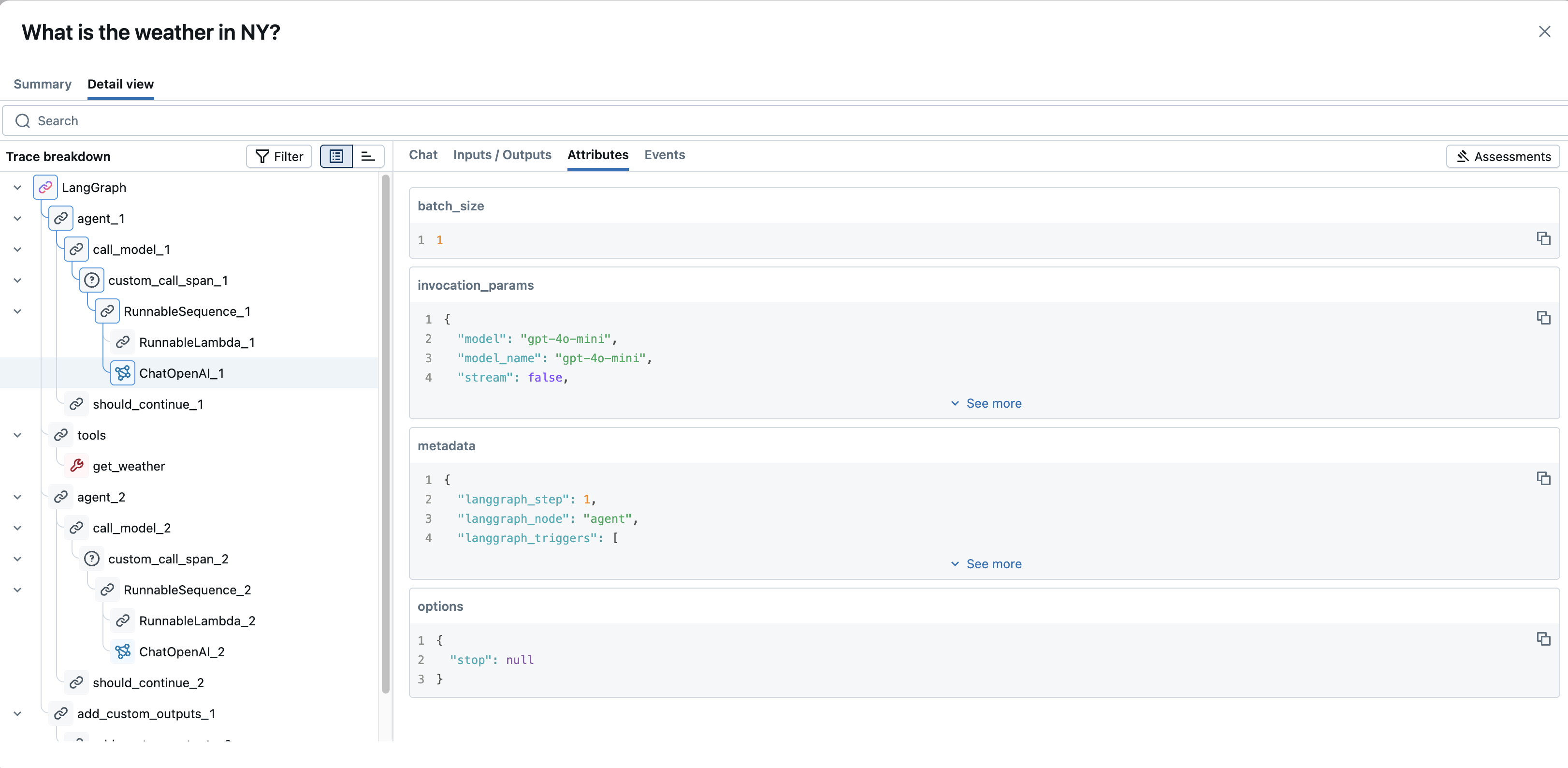
- 属性 : スパンに固有のキーと値のメタデータを表示します (例:
model名、LLM 呼び出しの場合はtemperature、リトリーバー スパンの場合はdoc_uri)。
-
イベント : エラーが発生したスパンの場合、このタブには通常、例外の詳細とスタック トレースが表示されます。ストリーミング スパンの場合、生成された個々のデータ チャンクが表示される場合があります。
-
一部の出力フィールドには、コンテンツが Markdown 形式の場合に生のビューとレンダリングされたビューを切り替えるための Markdown トグルが ある場合もあります。
-
-
評価(右パネル) :
- このパネルには 、トレース全体 または 現在選択されている範囲 に対して記録された評価 (ユーザー フィードバックまたは評価) が表示されます。
- 重要なのは、このパネルには多くの場合 「+ 新しい評価を追加」 ボタンが含まれており、トレースをレビューしながら UI から直接新しいフィードバックや評価スコアを記録できることです。これは、手動によるレビューやラベル付けのワークフローに非常に役立ちます。
トレースレベルの情報 : 個々のスパンの詳細に加えて、このビューでは全体的なトレース情報へのアクセスも提供します。 これには、トレース レベルのタグと、トレース全体について記録された評価 (特定のスパンが選択されていない場合やルート スパンが選択されていない場合は、評価パネルに表示されることが多い) が含まれます。これらは、直接的なユーザー フィードバックまたは体系的な評価から発生する可能性があります。
一般的なデバッグシナリオ
MLflow Tracing UI を使用して、一般的なデバッグと観測可能性のニーズに対応する方法を次に示します。
-
遅いトレース(レイテンシのボトルネック)を特定する :
- トレース リスト ビュー : 「並べ替え」ドロップダウンを使用して、トレースを「実行時間」の降順で並べ替えます。これにより、最も遅いトレースが一番上に表示されます。
- 詳細トレース ビュー : 低速トレースを開いたら、「トレースの内訳」パネルを調べます。スパンのウォーターフォール表示では、最も時間がかかった操作が視覚的に強調表示されるため、アプリケーションのフロー内でのレイテンシのボトルネックを正確に特定するのに役立ちます。
-
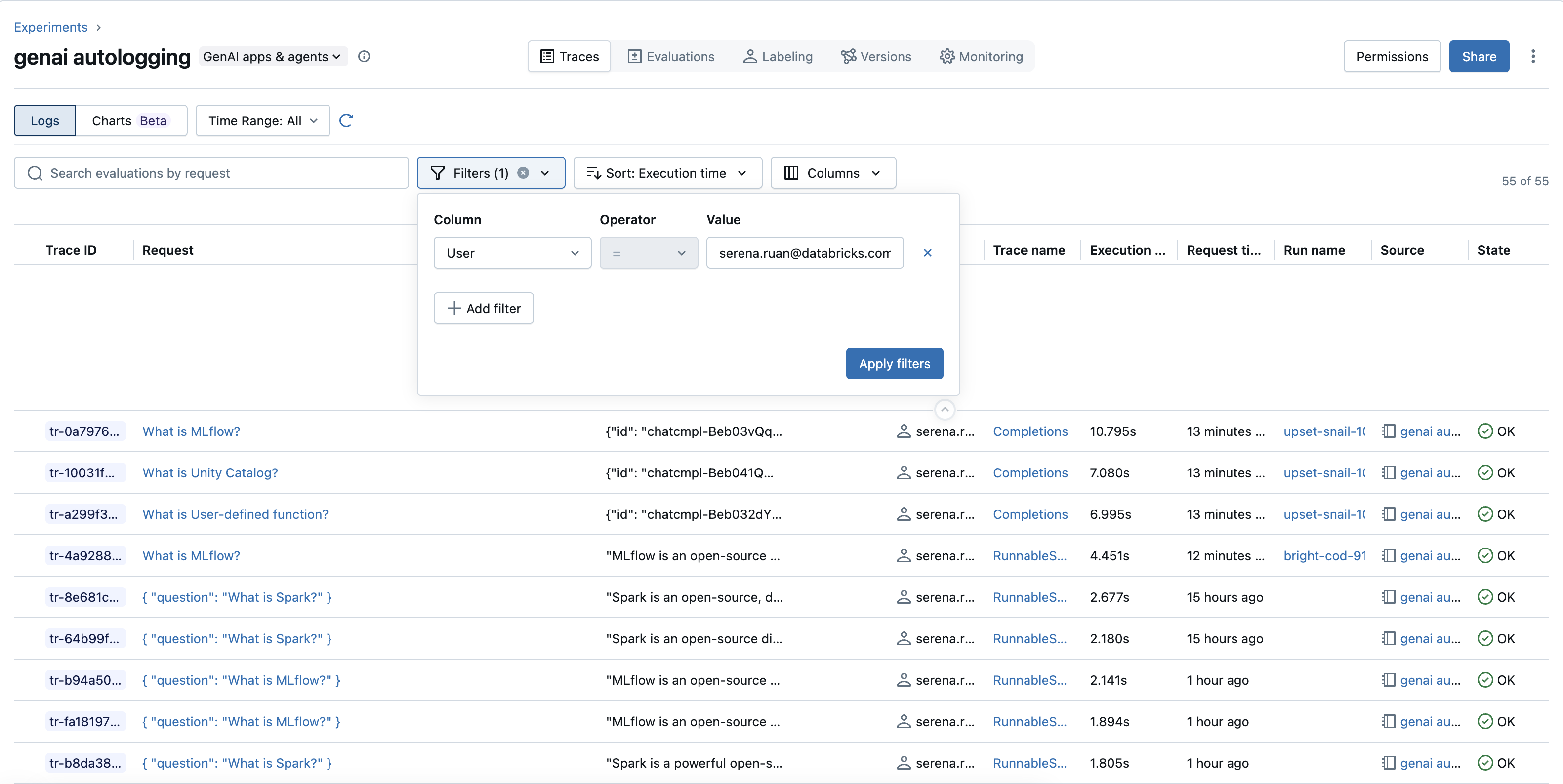
特定のユーザーからのトレースを見つける :
- フィルターを使用する :ユーザー情報を追跡していて、それがフィルター オプションとして使用できる場合 (例: 「属性」の下、または「フィルター」ドロップダウンの専用の「ユーザー」フィルター)、特定のユーザー ID を選択または入力できます。
- 検索とタグを使用する : あるいは、ユーザー ID がタグとして保存されている場合 (例:
mlflow.trace.user)、tags.mlflow.trace.user = 'user_example_123'のようなクエリで検索バーを使用します。
-
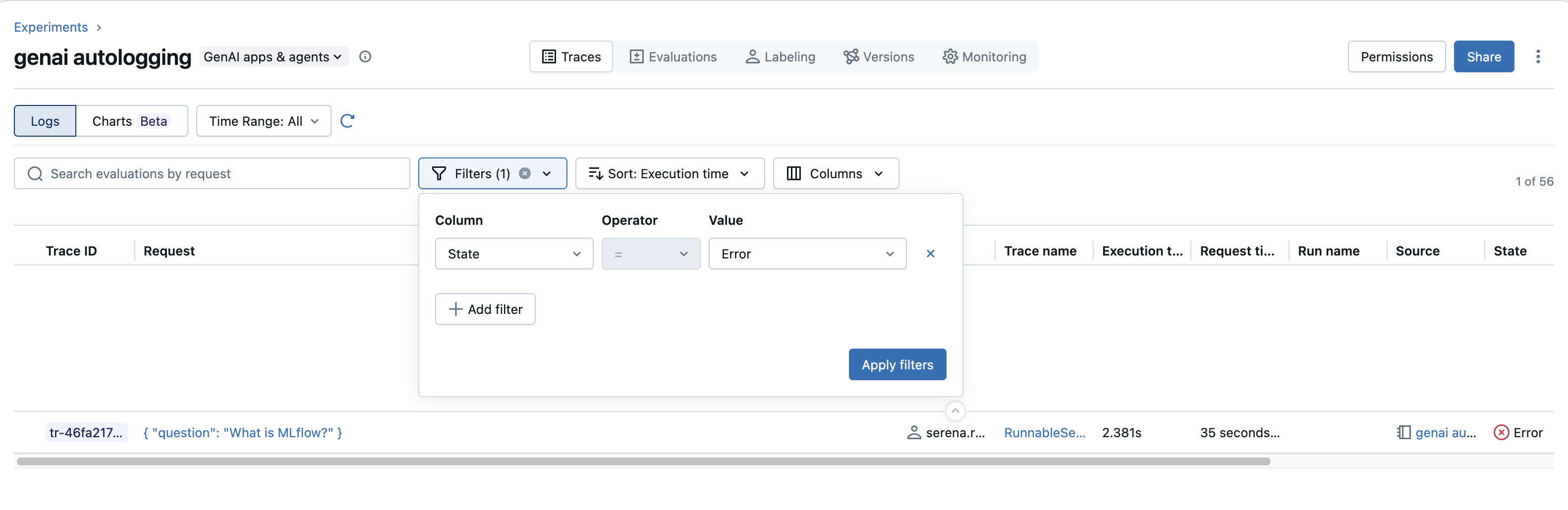
障害(エラー)のあるトレースを検索します 。
- フィルターの使用 : 「フィルター」ドロップダウンで、
State属性を選択し、ERRORを選択して失敗したトレースのみを表示します。 - 詳細トレース ビューの場合 : エラー トレースの場合は、「トレースの内訳」でエラーがマークされている範囲を選択します。失敗の根本原因を診断するために重要な例外メッセージとスタック トレースを表示するには、Span の詳細パネルの「イベント」タブに移動します。
- フィルターの使用 : 「フィルター」ドロップダウンで、
-
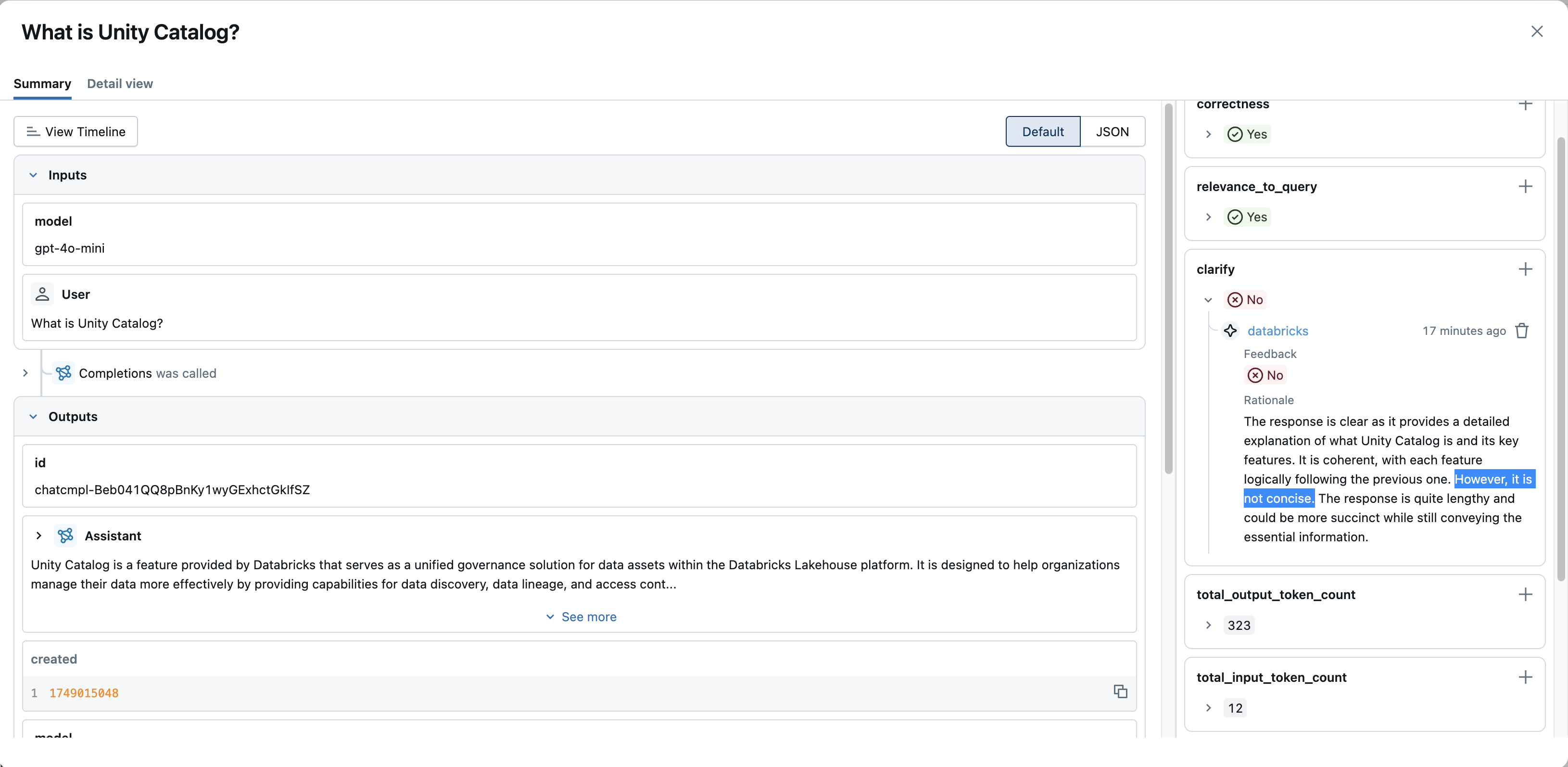
否定的なフィードバックや問題のあるトレースを特定します 。
- 評価フィルターの使用 :ユーザーからのフィードバックを収集している場合や、評価 (例: ブール値
is_correctまたは数値relevance_score) につながる評価を実行している場合は、「フィルター」を使用すると、これらの評価名とその値でフィルター処理できることがあります (例:is_correct = falseまたはrelevance_score < 0.5のフィルター)。 - 評価を表示する : トレースを開き、「評価」パネル (詳細ビューの右側) または個々のスパンの評価を確認します。これにより、記録されたフィードバック、スコア、および根拠が表示され、応答が低品質とマークされた理由を理解するのに役立ちます。
- 評価フィルターの使用 :ユーザーからのフィードバックを収集している場合や、評価 (例: ブール値
これらの例は、MLflow Tracing によってキャプチャされた詳細情報と、UI の表示およびフィルタリング機能を組み合わせることで、問題を効率的にデバッグし、アプリケーションの動作を観察できる方法を示しています。
Databricksノートブックでのトレース
MLflow Tracing は、Databricks ノートブック内でシームレスなエクスペリエンスを提供し、開発および実験ワークフローの一部としてトレースを直接表示できるようにします。
MLflow Tracing Databricksノートブック統合は、 MLflow 2.20 以降で利用できます。
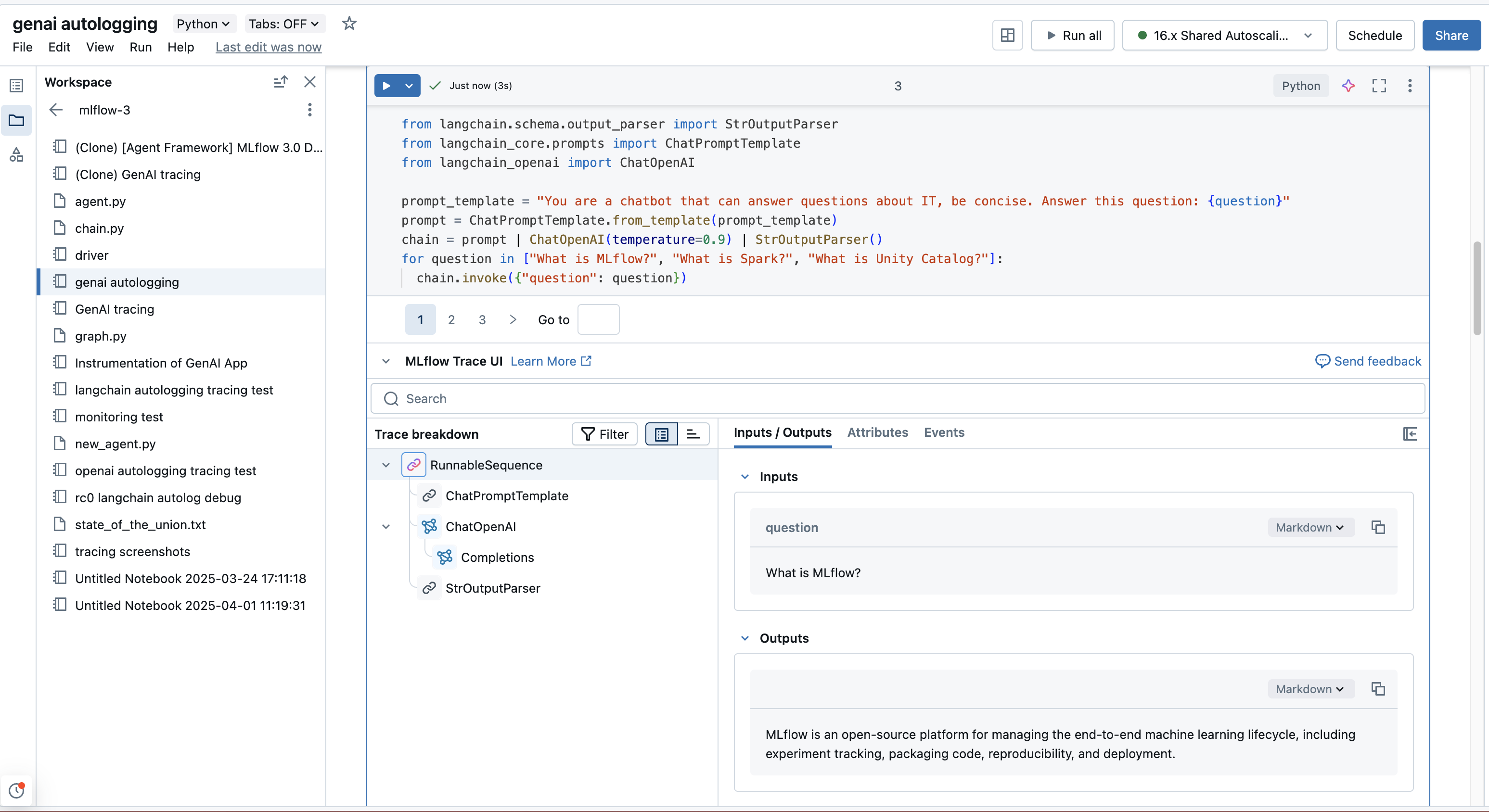
Databricksノートブックで作業しており、 MLflow Tracking URI が"databricks"に設定されている場合 (多くの場合、これはデフォルトであるか、 mlflow.set_tracking_uri("databricks")を使用して設定できます)、セルの出力にトレース UI を自動的に表示できます。
これは通常、次の場合に発生します。
- セルのコード実行によってトレースが生成されます (たとえば、
@mlflow.traceで装飾された関数や自動インストルメント化されたライブラリ呼び出しを呼び出すことによって)。 - 明示的に
mlflow.search_traces()を呼び出すと、結果が表示されます。 mlflow.entities.Traceオブジェクト (例:mlflow.get_trace()から) は、セル内の最後の式であるか、display()に渡されます。
このノートブック ビューは、メインのMLflowエクスペリメント UI と同じ豊富なインタラクティブなトレース探索機能を提供し、コンテキストを切り替えることなく反復処理を高速化するのに役立ちます。
ノートブックのディスプレイを制御する
ノートブックのセルの出力でトレースの自動表示を有効または無効にするには、次を実行します: mlflow.tracing.disable_notebook_display()またはmlflow.tracing.enable_notebook_display()
制限事項
- トレースリストには最大1,000件のトレースが返されます。フィルターとトレース ID 検索は、エクスペリメント全体ではなく、このセットにのみ適用されるため、大規模なエクスペリメント内の古いトレースは表示されない可能性があります。 古い痕跡を見つけるには、その痕跡が含まれるように時間範囲を絞り込みます。
- Unity Catalogにないエクスペリメントは、100,000トレースに制限されています。スケーラブルで、ガバナンスが適用され、トレース制限のないストレージの場合、DatabricksはUnity Catalogにトレースを保存することをお勧めします。既存のエクスペリメントのトレースを移動するには、Unity Catalogのトレースに移行してください。
その他のリソース
- SDK 経由でトレースをクエリ- カスタム ワークフローのトレースをプログラムで検索および分析します
- 評価データセットの構築- 体系的な評価と品質改善のためにトレースをテストデータに選択して変換します