Databricksにデプロイされたエージェントのトレース
本番運用トレースが自動的にキャプチャされるように、DatabricksにAIアプリケーションをデプロイしてください。カスタムエージェント(推奨)またはカスタムCPU Model Servingを使用して、DatabricksにAIアプリケーションをデプロイできます。どのデプロイ方法を選択しても、Databricksはリアルタイムで表示できるよう、トレースをMLflowエクスペリメントにLogs。
Databricks の外部にデプロイされたアプリについては、 「Databricks の外部にデプロイされたトレース エージェント」を参照してください。
トレースの保存場所を選択してください
Databricks 、デプロイ中にmlflow.set_experiment(...)で設定したMLflowエクスペリメントにトレースを記録します。 トレースは MLflow UI でリアルタイムに表示できます。
永続的で、ガバナンスが適用され、クエリ可能なストレージとして、Databricks は、エクスペリメントを Unity Catalog のトレースロケーションにバインドし、トレースが Unity Catalog の Delta テーブルに格納されるようにすることをお勧めします。これは本番運用向けに推奨されるバックエンドです。Unity CatalogにOpenTelemetryトレースを格納するを参照してください。
Unity Catalogトレースロケーションを使用しない場合、トレースはアーティファクトとして保存され、カスタム保存場所を指定できます。例えば、artifact_locationがUnity Catalogボリュームに設定されたワークスペースエクスペリメントを作成した場合、トレースデータアクセスはUnity Catalogボリューム権限によって管理されます。
Unity Catalogボリュームに保存されているトレースデータを読み取るIDはすべて、MLflowエクスペリメントへのアクセスに加えて、そのボリュームに対するREAD VOLUME権限を持っている必要があります。これには、インタラクティブユーザーだけでなく、本番運用またはサービングワークロードで使用されるIDも含まれます。
カスタムエージェントでデプロイ (推奨)
カスタムエージェントを使用して GenAI アプリケーションをデプロイすると、MLflow Tracing は追加の設定なしで自動的に機能します。トレースはエージェントのMLflowエクスペリメントに保存されます。
トレースの保存場所を設定します。
- 本番運用 モニタリングを使用してトレースをDeltaテーブルに保存する場合は、ワークスペースで有効になっていることを確認してください。
- アプリの本番運用トレースを格納するためのMLflowエクスペリメントを作成します。
次に、Python ノートブックで、MLflow Tracing を使用してエージェントを計測可能にし、Custom Agents を使用してエージェントをデプロイします。
- Python 環境に
mlflow[databricks]の最新バージョンをインストールします。 mlflow.set_experiment(...)を使用してMLflowエクスペリメントに接続します。- MLflow
ResponsesAgentを使用してエージェント コードをラップします。エージェント コードで、自動または手動のインストルメンテーションを使用してMLflow Tracing有効にします。 - エージェントを MLflow モデルとしてログに記録し、Unity Catalogに登録します。
mlflowがモデルの Python 依存関係にあり、ノートブック環境で使用されているのと同じパッケージ バージョンであることを確認します。agents.deploy(...)を使用して、Unity Catalog モデル (エージェント) をモデルサービング エンドポイントにデプロイします。
Databricks Gitフォルダーに保存されているノートブックからエージェントをデプロイしている場合、 MLflow 3 リアルタイムトレースはデフォルトで機能しません。
リアルタイムトレースを有効にするには、 agents.deploy()を実行する前に、 mlflow.set_experiment()を使用してエクスペリメントをGitに関連付けられていないエクスペリメントに設定します。
このノートブックでは、上記の展開ステップを示します。
カスタムエージェント と MLflow Tracing ノートブック
カスタム CPU サービングを使用してデプロイする (代替)
カスタムエージェントを使用できない場合、代わりにカスタムCPU Model Servingを使用してエージェントをデプロイしてください。
まず、トレースの保存場所を設定します。
- 本番運用 モニタリングを使用してトレースをDeltaテーブルに保存する場合は、ワークスペースで有効になっていることを確認してください。
- アプリの本番運用トレースを格納するためのMLflowエクスペリメントを作成します。
次に、 Python ノートブックで、 MLflow Tracingを使用してエージェントを計測可能にし、モデルサービング UI または API を使用してエージェントをデプロイします。
- 自動または手動のトレース インストルメンテーションを使用して、エージェントを MLflow モデルとしてログに記録します。
- モデルを CPU サービスにデプロイします。
- MLflowエクスペリメントへの
CAN_EDITアクセスを持つサービスプリンシパルまたはパーソナル アクセストークン(PAT)を提供します。 - CPU サービング エンドポイント ページで、[エンドポイントの編集] に移動します。トレースするデプロイされたモデルごとに、次の環境変数を追加します。
ENABLE_MLFLOW_TRACING=trueMLFLOW_EXPERIMENT_ID=<ID of the experiment you created>- サービスプリンシパルをプロビジョニングする場合は、
DATABRICKS_CLIENT_IDとDATABRICKS_CLIENT_SECRETを設定します。 PAT をプロビジョニングした場合は、DATABRICKS_HOSTを設定し、DATABRICKS_TOKENを設定します。
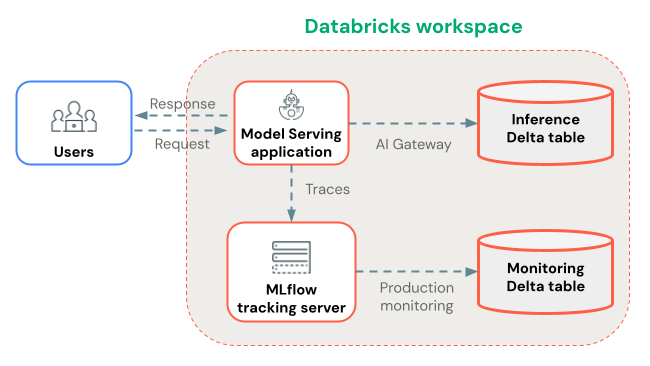
本番運用モニタリングでトレースを長期保存する
トレースがMLflowエクスペリメントに記録された後、オプションで本番運用モニタリング(ベータ版) を使用して、トレースをDeltaテーブルに長期保存できます。
トレース ストレージに対する本番運用モニタリングの利点:
- 耐久性のあるストレージ : MLflowエクスペリメント アーティファクトのライフサイクルを超えて長期保存するために、トレースをDeltaテーブルに保存します。
- トレース サイズの制限なし : 代替のストレージ方法とは異なり、本番運用モニタリングはあらゆるサイズのトレースを処理します。
- 自動品質評価 :本番運用トレース上の実行MLflowスコアラーにより、アプリケーションの品質を継続的に監視します。
- 高速同期 : トレースは約 15 分ごとに Delta テーブルに同期されます。
あるいは、 AI Gateway 対応の推論テーブルを使用してトレースを保存することもできます。ただし、トレース サイズと同期遅延の制限に注意してください。
その他のリソース
- Databricks MLflow UI でトレースを表示する- MLflow UI でトレースを表示します。
- 本番運用モニタリング- 長期保存のためにトレースをDeltaテーブルに保存し、スコアラーで自動的に評価します。
- トレースにコンテキストを追加- リクエスト追跡、ユーザー セッション、環境データのメタデータを添付します。