Databricks の外部にデプロイされたエージェントのトレース
MLflow Tracing は、実行の詳細をキャプチャして Databricks ワークスペースに送信することで、Databricks 外部にデプロイされた本番運用 生成AI エージェントに包括的な可観測性を提供し、MLflow UI で実行の詳細を表示できます。
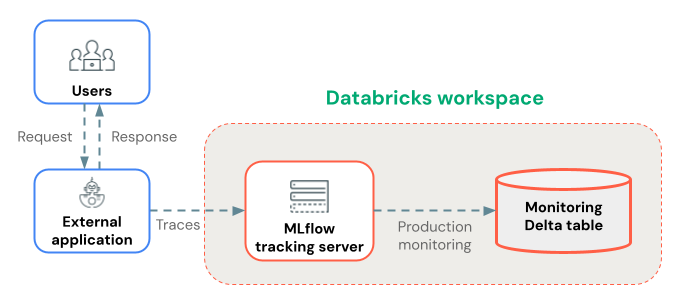
このページでは、Databricks の外部でトレースが有効なエージェントをデプロイする方法について説明します。エージェントがDatabricks Model Servingを使用してデプロイされている場合、カスタムエージェントを使用してデプロイ(推奨)を参照してください。
本番運用のワークロードの場合、Databricksは、これらのトレースを受信するエクスペリメントをUnity Catalogのトレースの場所にバインドすることを推奨します。そうすることで、トレースは無制限の保持期間、Unity Catalogのガバナンス、およびSQLクエリ機能を備えたDeltaテーブルに保存されます。DatabricksノートブックからUnity Catalogに裏付けられたエクスペリメントを作成し、以下の環境変数で名前またはIDで参照します。Unity CatalogにOpenTelemetryトレースを保存するを参照してください。
前提 条件
必要なパッケージをインストールします。次の表に、オプションを示します。
パッケージ | 推奨される使用例 | 利点 |
|---|---|---|
| 本番運用のデプロイメント | 無駄のない迅速な展開のための最小限の依存関係 大量のトレースに最適化されたパフォーマンス 本番運用 モニタリングのクライアント側トレースに着目 |
開発と実験 | 完全な MLflow 実験機能セット (UI、LLM-as-a-judge、開発ツールなど) すべての開発ツールとユーティリティが含まれています |
## Install mlflow-tracing for production deployment tracing
%pip install --upgrade "mlflow-tracing==3.1.0"
## Install mlflow for experimentation and development
%pip install --upgrade "mlflow[databricks]==3.1.0"
基本的なトレース設定
Databricks がトレースを収集できるように、Databricks ワークスペースに接続するようにアプリケーション デプロイを構成します。
次の環境変数を設定します。
# Required: Set the Databricks workspace host and authentication token
export DATABRICKS_HOST="https://your-workspace.cloud.databricks.com"
export DATABRICKS_TOKEN="your-databricks-token"
# Required: Set MLflow Tracking URI to "databricks" to log to Databricks
export MLFLOW_TRACKING_URI=databricks
# Required: Configure the experiment name for organizing traces (must be a workspace path)
export MLFLOW_EXPERIMENT_NAME="/Shared/production-genai-app"
デプロイの例
環境変数を設定したら、それをアプリケーションに渡します。タブをクリックすると、接続の詳細をさまざまなフレームワークに渡す方法が表示されます。
- Docker
- Kubernetes
Docker デプロイの場合は、コンテナー構成を介して環境変数を渡します。
# Dockerfile
FROM python:3.11-slim
# Install dependencies
COPY requirements.txt .
RUN pip install -r requirements.txt
# Copy application code
COPY . /app
WORKDIR /app
# Set default environment variables (can be overridden at runtime)
ENV DATABRICKS_HOST=""
ENV DATABRICKS_TOKEN=""
ENV MLFLOW_TRACKING_URI=databricks
ENV MLFLOW_EXPERIMENT_NAME="/Shared/production-genai-app"
CMD ["python", "app.py"]
環境変数を使用してコンテナを実行します。
docker run -d \
-e DATABRICKS_HOST="https://your-workspace.cloud.databricks.com" \
-e DATABRICKS_TOKEN="your-databricks-token" \
-e MLFLOW_TRACKING_URI=databricks \
-e MLFLOW_EXPERIMENT_NAME="/Shared/production-genai-app" \
-e APP_VERSION="1.0.0" \
your-app:latest
Kubernetes デプロイの場合は、ConfigMaps と Secrets を使用して環境変数を渡します。
# configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: databricks-config
data:
DATABRICKS_HOST: 'https://your-workspace.cloud.databricks.com'
MLFLOW_TRACKING_URI: databricks
MLFLOW_EXPERIMENT_NAME: '/Shared/production-genai-app'
---
# secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: databricks-secrets
type: Opaque
stringData:
DATABRICKS_TOKEN: 'your-databricks-token'
---
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: genai-app
spec:
template:
spec:
containers:
- name: app
image: your-app:latest
envFrom:
- configMapRef:
name: databricks-config
- secretRef:
name: databricks-secrets
env:
- name: APP_VERSION
value: '1.0.0'
トレース収集の検証
アプリをデプロイした後、トレースが適切に収集されていることを確認します。
import mlflow
from mlflow.client import MlflowClient
import os
# Ensure MLflow is configured for Databricks
mlflow.set_tracking_uri("databricks")
# Check connection to MLflow server
client = MlflowClient()
try:
# List recent experiments to verify connectivity
experiments = client.search_experiments()
print(f"Connected to MLflow. Found {len(experiments)} experiments.")
# Check if traces are being logged
traces = mlflow.search_traces(
experiment_names=[os.getenv("MLFLOW_EXPERIMENT_NAME", "/Shared/production-genai-app")],
max_results=5
)
print(f"Found {len(traces)} recent traces.")
except Exception as e:
print(f"Error connecting to MLflow: {e}")
print(f"Check your authentication and connectivity")
本番運用モニタリングでトレースを長期保存する
トレースがMLflowエクスペリメントに記録された後、本番運用モニタリング(ベータ版) を使用して、トレースをDeltaテーブルに長期保存できます。
トレース ストレージに対する本番運用モニタリングの利点:
- 耐久性のあるストレージ : MLflowエクスペリメント アーティファクトのライフサイクルを超えて長期保存するために、トレースをDeltaテーブルに保存します。
- トレース サイズの制限なし : 代替のストレージ方法とは異なり、本番運用モニタリングはあらゆるサイズのトレースを処理します。
- 自動品質評価 :本番運用トレース上の実行MLflowスコアラーにより、アプリケーションの品質を継続的に監視します。
- 高速同期 : トレースは約 15 分ごとに Delta テーブルに同期されます。
あるいは、 AI Gateway 対応の推論テーブルを使用してトレースを保存することもできます。ただし、トレース サイズと同期遅延の制限に注意してください。
その他のリソース
- Databricks MLflow UI でトレースを表示する- MLflow UI でトレースを表示します。
- 本番運用モニタリング- 長期保存のためにトレースをDeltaテーブルに保存し、スコアラーで自動的に評価します。
- トレースにコンテキストを追加 - デバッグと知見の改善のために、ユーザーまたはセッションID、カスタムタグ、ユーザーフィードバックを添付します。