トレースの概念
トレースは、アプリケーションを介したリクエストの完全な実行フローをキャプチャする観測技術です。個別のイベントを記録する従来のログ記録とは異なり、トレースでは、システムがデータをどのように流すかを示す詳細なマップを作成し、その途中で行われたすべての操作を記録します。
GenAIアプリケーションは、LLM、リトリーバー、ツール、エージェントなど、複数のコンポーネントを組み合わせた複雑な多段階ワークフローを実行します。トレース機能を使うことで、実行フロー全体をキャプチャし、ワークフローのデバッグが可能になります。
トレース構造
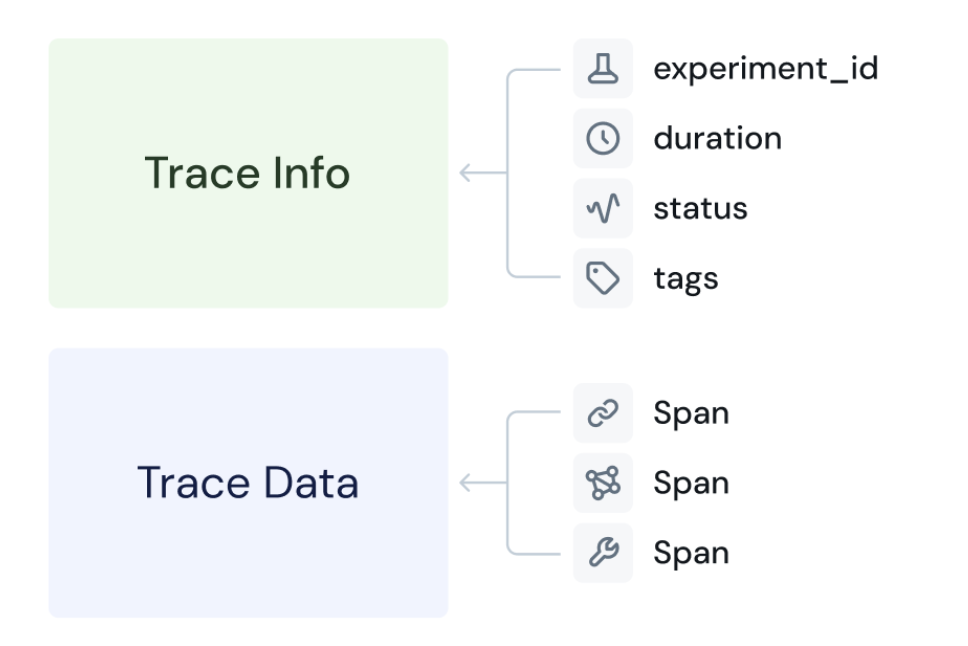
MLflowトレースは、次の 2 つの主要なオブジェクトで構成されます。
-
Trace.infoタイプTraceInfo: トレースの発生元、状態、および実行時間を記述するメタデータ。TraceInfoもタグを保持します。タグは、ユーザー、セッション、開発者が提供するキーと値のペアであり、トレースの検索やフィルタリングに使用できます。 -
Trace.dataタイプTraceData: 入力から出力までのアプリケーションのステップごとの実行をキャプチャするインストルメントされたSpanオブジェクトを含む実際のペイロード。
MLflowのトレース機能は、広く採用されている可観測性に関する業界標準であるOpenTelemetryの仕様と互換性があります。トレースは他のOpenTelemetry互換の観測ツールとの相互運用性を維持しつつ、MLflowはOpenTelemetryモデルをGenAI固有の構造と属性で拡張します。
トレース情報
TraceInfo 、全体的なトレースの軽量メタデータを提供します。主なフィールドには以下が含まれます。
フィールド | 説明 |
|---|---|
| トレースの一意の識別子 |
| トレースの保存場所:Unity Catalogのトレース保存場所(推奨)、MLflowエクスペリメント、またはDatabricks推論テーブル |
| トレースの開始時間(ミリ秒) |
| トレースステータス: |
| トレースの継続時間(ミリ秒) |
| 入力のJSONエンコードされたプレビュー(ルートスパン入力) |
| JSON エンコードされた出力のプレビュー (ルート スパン出力) |
| トレースのフィルタリングと検索のためのキーと値のペア |
トレースデータ
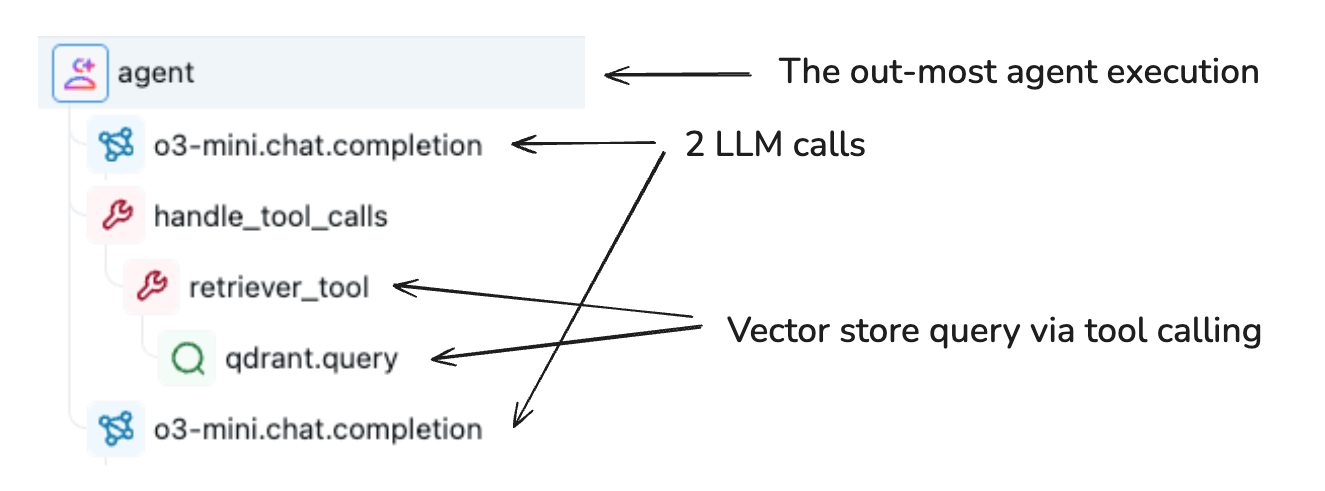
TraceDataオブジェクトは、実行の詳細が保存されるSpanオブジェクトのコンテナーです。各スパンは、次のような特定の操作に関する情報を取得します。
- リクエストとレスポンス
- レイテンシ測定
- LLMメッセージとツールの問題
- 取得した文書とコンテキスト
- メタデータと属性
スパンは親子の接続を通じて階層構造を形成し、アプリケーションの実行フローを表すツリーを作成します。
タグ
タグは、整理とフィルタリングのためにトレースに添付される変更可能なキーと値のペアです。MLflow は、一般的なユースケース向けに標準タグを定義します。
mlflow.trace.session: 関連するトレースをグループ化するためのセッション識別子mlflow.trace.user: ユーザーごとのインタラクションを追跡するためのユーザー識別子mlflow.source.name: トレースを生成したエントリポイントまたはスクリプトmlflow.source.git.commit: ソースコードの Git コミットハッシュ(該当する場合)mlflow.source.type: ソースタイプ (PROJECT、NOTEBOOKなど)
特定のニーズに合わせてカスタム タグを追加することもできます。詳細については、 「トレースにコンテキストを追加する」および「カスタム タグ/メタデータを添付する」を参照してください。
ストレージレイアウト
トレースは常にMLflowエクスペリメントに属しますが、トレースデータを物理的に保存するバックエンドはユーザーが選択します:
- Unity Catalog OTel Deltaテーブル (推奨) : スケールとガバナンスのため、エクスペリメントをUnity Catalogトレースロケーションに向けます。トレースは、OpenTelemetry形式のDeltaテーブルに保存され、エクスペリメントごとの制限はなく、Unity Catalogのアクセス許可によって管理され、SQLでクエリ可能です。Unity CatalogにOpenTelemetryトレースを保存するを参照してください。
- マネージド エクスペリメント バックエンド : Unity Catalogトレースの場所が構成されていない場合のdefault。
TraceInfoは、インデックス付き行としてリレーショナルデータベースに保存され、トレースの検索とフィルター処理のための高速なクエリーを可能にします。TraceData(スパン) は、スパンが大きいため、リレーショナルデータベースではなくアーティファクトストレージに保存されます。これにより、トレース量が増加してもクエリーは高速に保たれます。
アクティブなトレースと終了したトレース
アクティブトレースとは、MLflowが現在書き込んでいるトレースのことです。たとえば、 @mlflow.traceで装飾された関数が実行されている間などです。装飾された関数が終了すると、トレースは終了しますが、新しいデータで注釈を付けることは可能です。
アクティブなトレースまたは最近のトレースを操作するには、次の方法を使用します。
mlflow.get_active_trace_id(): 現在アクティブなトレースのIDを返します。mlflow.get_last_active_trace_id(): 最新の完了したトレースのIDを返します。
その他のリソース
- スパンの概念 - スパンと、スパンが個々の操作をどのようにキャプチャするかについて学びます。
- はじめに: MLflow Tracing for GenAI (Databricksノートブック) - ノートブックでトレースの実践的な経験を積みます。