チュートリアル: Databricks ノートブックを使用した EDA 手法
Databricks ノートブックで Python を使用して探索的データ分析 (EDA) を実行し、データセットをロードしてクリーンアップし、その特性を探索し、傾向を視覚化して知見を生成します。
このチュートリアルで使用するノートブックでは、世界のエネルギーと排出量のデータを調べ、データの読み込み、クリーニング、探索の方法を示します。
サンプルノートブックを使用して作業を進めることも、独自のノートブックを最初から作成することもできます。
EDAとは?
探索的データ分析(EDA)は、データサイエンスプロセスの重要な最初のステップであり、データの分析と視覚化を行い、次のことを行います。
- その主な特徴を明らかにします。
- パターンと傾向を特定します。
- 異常を検出します。
- 変数間の関係を理解する。
EDAはデータセットに知見を提供し、さらなる統計分析やモデリングについて情報に基づいた意思決定を促進します。
Databricksノートブックを使用すると、データサイエンティストは使い慣れたツールを使用してEDAを実行できます。たとえば、このチュートリアルでは、次のような一般的な Python ライブラリを使用してデータを処理およびプロットします。
- Numpy :数値計算の基本ライブラリであり、配列、行列、およびこれらのデータ構造を操作するためのさまざまな数学関数のサポートを提供します。
- pandas : NumPyの上に構築された強力なデータ操作および分析ライブラリで、構造化データを効率的に処理するためのデータフレームなどのデータ構造を提供します。
- Plotly :データ分析とプレゼンテーションのための高品質でインタラクティブな視覚化の作成を可能にするインタラクティブなグラフ作成ライブラリ。
- Matplotlib :Pythonで静的、アニメーション、およびインタラクティブな視覚化を作成するための包括的なライブラリ。
Databricks には、テーブル内のデータのフィルタリングや検索、視覚化の拡大など、ノートブック出力内のデータを探索するのに役立つ組み込み機能も用意されています。Genie Code を使用して EDA のコードを作成することもできます。
始める前に
このチュートリアルを完了するには、次のものが必要です。
- 既存のコンピュート リソースを使用するか、新しいコンピュート リソースを作成するには、アクセス許可が必要です。 コンピュートを参照してください。
- [オプション] このチュートリアルでは、Genie Code を使用してコードを生成する方法について説明します。詳細については、 Genie Codeの使用」を参照してください。
データセットのダウンロードとCSVファイルのインポート
このチュートリアルでは、世界のエネルギーと排出量のデータを調べることで、EDA 手法を示します。 さらに詳しく知りたい方は、KaggleからEnergy Consumption Dataset by Our World in Data をダウンロードしてください。 このチュートリアルでは、 owid-energy-data.csv ファイルを使用します。
データセットを Databricks ワークスペースにインポートするには:
-
ワークスペースのサイドバーで、[ ワークスペース ] をクリックしてワークスペース ブラウザーに移動します。
-
CSV ファイル
owid-energy-data.csvをワークスペースにドラッグ アンド ドロップします。これにより、インポート モーダルが開きます。ここにリストされている Target フォルダ に注意してください。これは、ワークスペース ブラウザーの現在のフォルダーに設定され、インポートされたファイルの宛先になります。
-
「インポート」 をクリックします。ファイルは、ワークスペースのターゲット フォルダーに表示されます。
-
ファイル パスは、後でファイルをノートブックに読み込むために必要です。 ワークスペース ブラウザーでファイルを見つけます。 ファイルパスをクリップボードにコピーするには、ファイル名を右クリックし、 URL/パスをコピー > フルパス を選択します。
新しいノートブックを作成する
ユーザーのホームフォルダーに新しいノートブックを作成するには、サイドバーの![]() 新規 をクリックし、メニューから ノートブック を選択します。
新規 をクリックし、メニューから ノートブック を選択します。
上部で、ノートブックの名前の横にある [Python ] をノートブックのデフォルト言語として選択します。
ノートブックの作成と管理の詳細については、「 ノートブックの管理」を参照してください。
この記事の各コード サンプルをノートブックの新しいセルに追加します。 または、提供されている サンプル ノートブック を使用して、チュートリアルに沿って進みます。
CSV ファイルの読み込み
新しいノートブックセルに、CSV ファイルを読み込みます。 これを行うには、 numpy と pandasをインポートします。 これらは Python データサイエンスや分析のためのライブラリとして有用です。
データセットから pandas データフレーム を作成すると、処理と視覚化が容易になります。 以下のファイルパスを、前にコピーしたパスに置き換えます。
import numpy as np
import pandas as pd # Data processing, CSV file I/O (e.g. pd.read_csv)
df=pd.read_csv('/Workspace/Users/demo@databricks.com/owid-energy-data.csv') # Replace the file path here with the workspace path you copied earlier
セルを実行します。 出力は、各列とその型のリストを含む pandas データフレームを返す必要があります。

データを理解する
データセットの基本を理解することは、データサイエンスプロジェクトにとって非常に重要です。 これには、手元にあるデータの構造、種類、および品質に精通することが含まれます。
Databricks ノートブックでは、 display(df) コマンドを使用してデータセットを表示できます。
データセットには 10,000 行を超えるため、このコマンドは切り捨てられたデータセットを返します。各列の左側には、列のデータ型が表示されます。詳細については、「 列の書式設定」を参照してください。
データ知見のための Pandas 活用
データセットを効果的に理解するには、次の Pandas コマンドを使用します。
-
df.shapeコマンドは データフレーム のディメンションを返し、行数と列数の概要をすばやく把握できます。
-
df.dtypesコマンドは、各列のデータ型を提供し、扱っているデータの種類を理解するのに役立ちます。また、結果テーブルの各列のデータ型も確認できます。
-
df.describe()コマンドは、平均、標準偏差、パーセンタイルなどの数値列の記述統計を生成し、パターンの識別、異常の検出、データの分布の理解に役立ちます。display()と併用すると、対話できる表形式で要約統計情報が表示されます。「 Databricks ノートブック出力テーブルを使用してデータを調べる」を参照してください。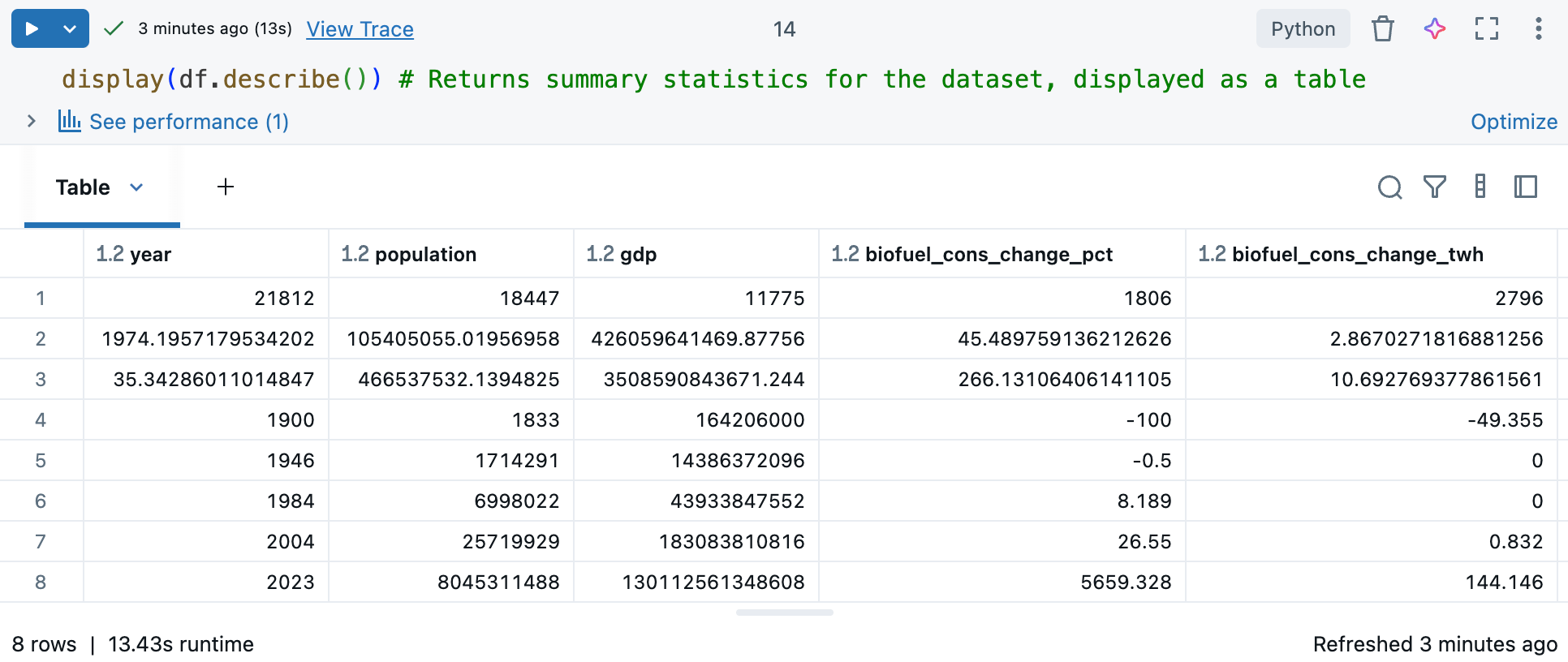
データプロファイリングの生成
Databricks Runtime 9.1 LTS 以降で利用可能です。
Databricks ノートブックには、組み込み データプロファイリング 機能が含まれています。 Databricksのdisplay関数でデータフレームを表示する場合、テーブル出力からデータプロファイリングを生成できます。
# Display the DataFrame, then click "+ > Data Profile" to generate a data profile
display(df)
出力の テーブル の横にある + > データプロファイリング をクリックします。これにより、データフレーム 内のデータのプロファイルを生成する新しいコマンドが実行されます。
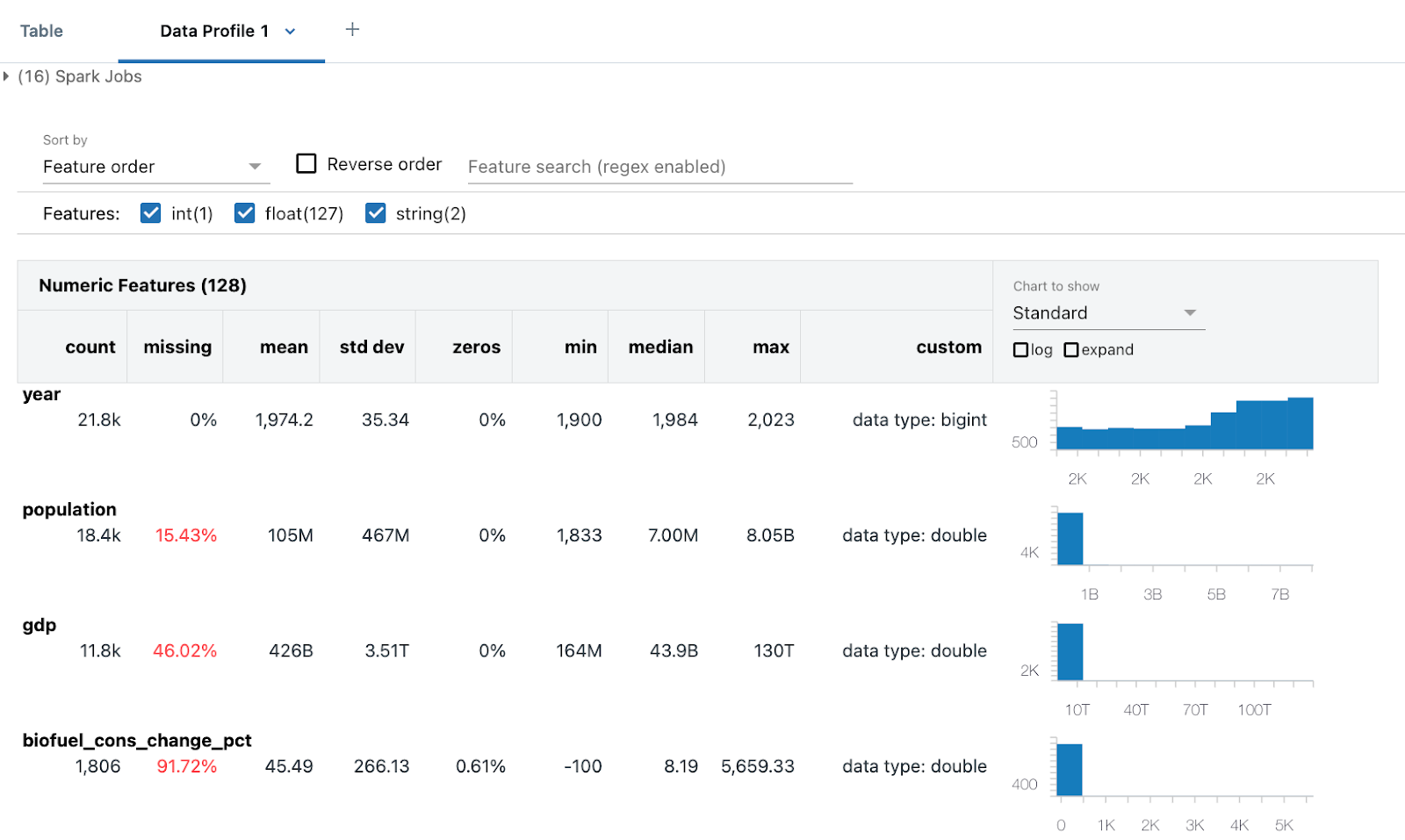
データプロファイリングには、数値、文字列、日付の列の要約統計と、各列の値分布のヒストグラムが含まれます。 また、プログラムによってデータプロファイリングを生成することもできます。 summarize コマンド (dbutils.data.summarize)を参照してください。
データのクリーニング
データのクリーニングは、データセットが正確で一貫性があり、意味のある分析の準備ができていることを確認するための EDA の重要なステップです。 このプロセスには、データを分析の準備ができていることを確認するための、次のようないくつかの重要なタスクが含まれます。
- 重複するデータを特定して削除します。
- 欠損値の処理 (特定の値への置き換えや、影響を受ける行の削除が含まれる場合があります)。
- 変換と変換によるデータ型の標準化 (文字列から 1 への変換など)
datetime一貫性を確保します。また、データを作業しやすい形式に変換することもできます。
このクリーニングフェーズは、データの品質と信頼性を向上させ、より正確で洞察に満ちた分析を可能にするため、不可欠です。
ヒント: Genie Codeを使用してデータクリーニングタスクを支援します
Genie Code を使用して、コードを生成できます。新しいコードセルを作成し、 生成 リンクをクリックするか、右上にあるGenie Codeアイコンを使用してGenie Codeを開きます。Genie Codeのクエリを入力してください。Genie Codeは、PythonまたはSQLコードを生成するか、テキストの説明を生成することができます。別の結果を得るには、 再生成 をクリックします。
たとえば、Genie Code を使用してデータをクリーンアップするには、次のプロンプトを試してください。
dfに重複する列または行が含まれているかどうかを確認します。複製を印刷します。 次に、重複を削除します。- 日付列はどのような形式ですか? に変更します
'YYYY-MM-DD'。 XXX列は使用しません。削除します。
Genie Code からコーディングのサポートを受けるを参照してください。
重複データの削除
データに重複する行または列がないかどうかを確認します。 その場合は、それらを削除します。
Genie Code を使用してコードを生成します。
次のプロンプトを入力してみてください: 「df に重複する列または行が含まれているかどうかを確認します。」重複部分を印刷します。次に、重複したものを削除します。」Genie Code は、以下のサンプルのようなコードを生成する可能性があります。
# Check for duplicate rows
duplicate_rows = df.duplicated().sum()
# Check for duplicate columns
duplicate_columns = df.columns[df.columns.duplicated()].tolist()
# Print the duplicates
print("Duplicate rows count:", duplicate_rows)
print("Duplicate columns:", duplicate_columns)
# Drop duplicate rows
df = df.drop_duplicates()
# Drop duplicate columns
df = df.loc[:, ~df.columns.duplicated()]
この場合、データセットには重複するデータはありません。
null 値または欠損値を処理する
NaN 値または Null 値を処理する一般的な方法は、数学的な処理を容易にするために 0 に置き換えることです。
df = df.fillna(0) # Replace all NaN (Not a Number) values with 0
これにより、データフレーム 内の欠落しているデータが 0 に置き換えられ、欠落している値が問題を引き起こす可能性がある後続のデータ分析や処理手順に役立ちます。
日付の再フォーマット
日付は、多くの場合、データセットごとに異なる方法で書式設定されます。 日付形式、文字列、または整数の場合があります。
この分析では、 year 列を整数として扱います。 次のコードは、これを行う方法の 1 つです。
# Ensure the 'year' column is converted to the correct data type (integer for year)
df['year'] = pd.to_datetime(df['year'], format='%Y', errors='coerce').dt.year
# Confirm the changes
df.year.dtype
これにより、 year 列には整数の年の値のみが含まれ、無効なエントリは NaT (Not a Time) に変換されます。
Databricks ノートブック出力テーブルを使用してデータを調べる
Databricks には、出力テーブルを使用してデータを探索するのに役立つ組み込み機能が用意されています。
新しいセルで、 display(df) を使用してデータセットをテーブルとして表示します。
出力テーブルを使用すると、いくつかの方法でデータを探索できます。
特定の文字列または値をデータで検索する
表の右上にある検索アイコンをクリックし、検索キーワードを入力します。
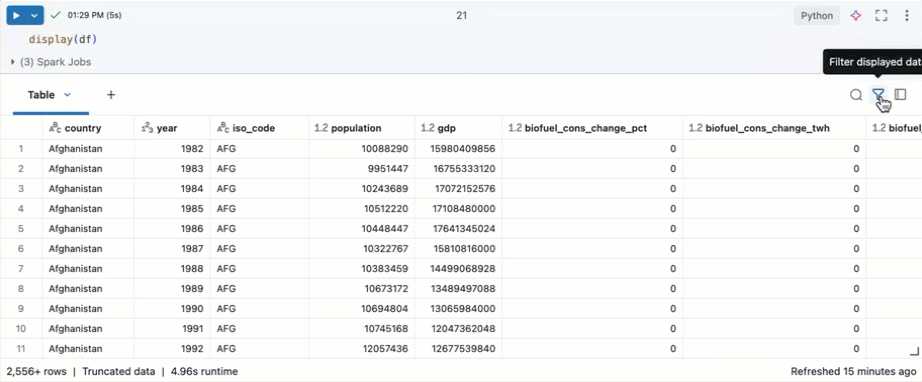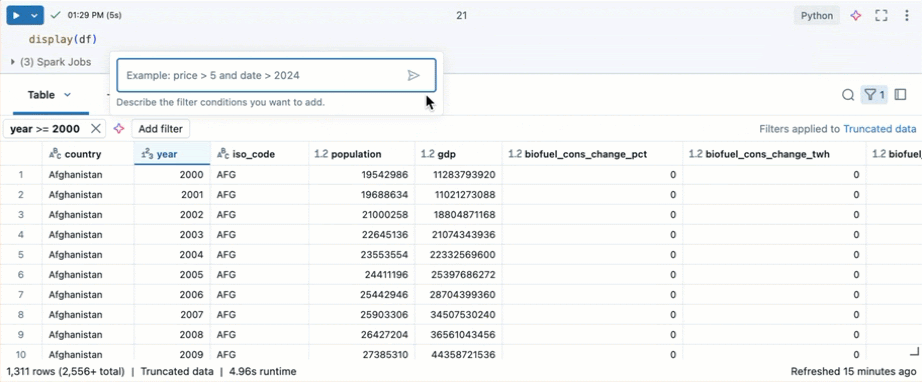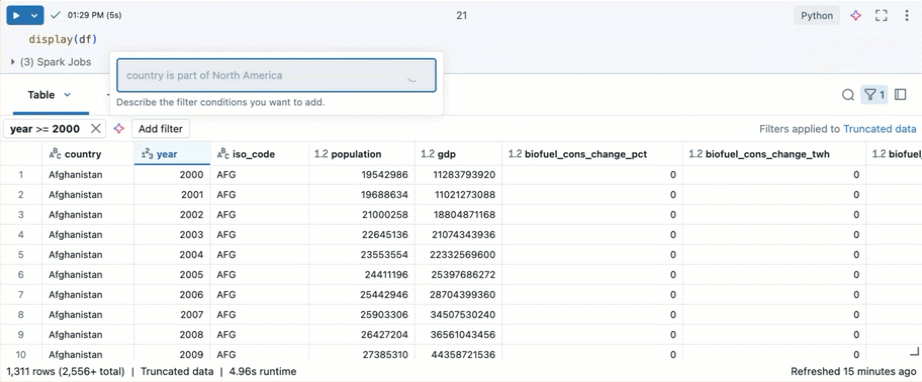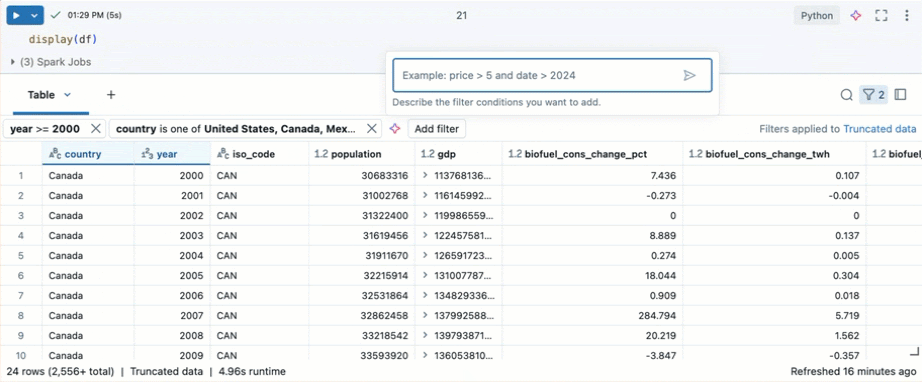
特定の条件でフィルタリングする
組み込みのテーブルフィルターを使用して、特定の条件で列をフィルタリングできます。 フィルターを作成するには、いくつかの方法があります。 結果のフィルタリングを参照してください。
Genie Code を使用してフィルターを作成します。 テーブルの右上隅にあるフィルター アイコンをクリックします。フィルター条件を入力します。Genie Code は自動的にフィルターを生成します。
データセットを使用した視覚化の作成
出力テーブルの上部にある + > Visualization をクリックして、ビジュアライゼーション エディターを開きます。
視覚化する視覚化の種類と列を選択します。エディタには、設定に基づくチャートのプレビューが表示されます。たとえば、次の図は、複数の折れ線グラフを追加して、さまざまな再生可能エネルギー ソースの消費量を経時的に表示する方法を示しています。
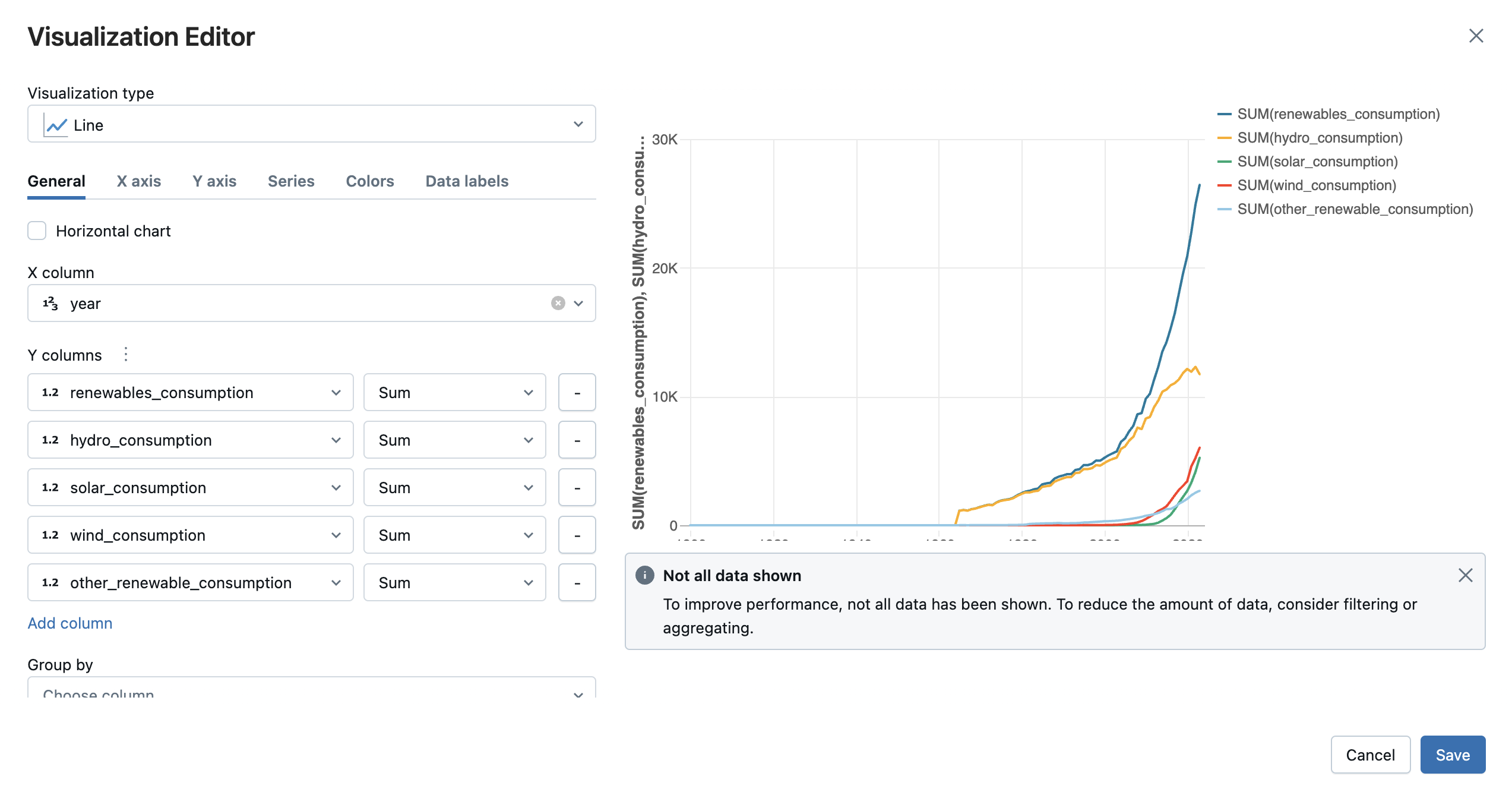
[ 保存 ] をクリックして、ビジュアライゼーションをセル出力のタブとして追加します。
新しいビジュアライゼーションの作成を参照してください。
Pythonライブラリを使用してデータを探索し、視覚化します
視覚化を使用したデータの探索は、EDA の基本的な側面です。 ビジュアライゼーションは、数値解析だけではすぐにはわからないデータ内のパターン、傾向、関係性を明らかにするのに役立ちます。 Plotly や Matplotlib などのライブラリを使用して、散布図、棒グラフ、折れ線グラフ、ヒストグラムなどの一般的な視覚化手法を使用します。これらのビジュアルツールを使用すると データサイエンティスト 異常を特定し、データ分布を理解し、変数間の相関を観察できます。 たとえば、散布図プロットは外れ値を強調表示でき、時系列プロットは傾向と季節性を明らかにすることができます。
- 一意の国の配列を作成する
- 排出量上位10カ国の排出量推移グラフ(2000年~2022年)
- 地域別の排出量のフィルタリングとグラフ化
- 再生可能エネルギーシェアの成長を計算してグラフ化する
- Scatter プロット: 再生可能エネルギーの影響を上位に表示
- 世界のエネルギー消費量の予測をモデル化
一意の国の配列を作成する
データセットに含まれる国を調べるには、一意の国の配列を作成します。 配列を作成すると、エンティティが countryとしてリストされます。
# Get the unique countries
unique_countries = df['country'].unique()
unique_countries
アウトプット:

知見:
country列には、世界、高所得国、アジア、米国など、常に直接比較できるわけではないさまざまなエンティティが含まれています。データを地域でフィルタリングする方が便利な場合があります。
排出量上位10カ国の排出量推移グラフ(2000年~2022年)
たとえば、2000 年代に温室効果ガスの排出量が最も多かった 10 か国に調査を集中させたいとします。確認する年と排出量の多い上位 10 か国のデータをフィルタリングし、plotly を使用して、時間の経過に伴う排出量を示す折れ線グラフを作成できます。
import plotly.express as px
# Filter data to include only years from 2000 to 2022
filtered_data = df[(df['year'] >= 2000) & (df['year'] <= 2022)]
# Get the top 10 countries with the highest emissions in the filtered data
top_countries = filtered_data.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
# Filter the data for those top countries
top_countries_data = filtered_data[filtered_data['country'].isin(top_countries)]
# Plot emissions trends over time for these countries
fig = px.line(top_countries_data, x='year', y='greenhouse_gas_emissions', color='country',
title="Greenhouse Gas Emissions Trends for Top 10 Countries (2000 - 2022)")
fig.show()
アウトプット:
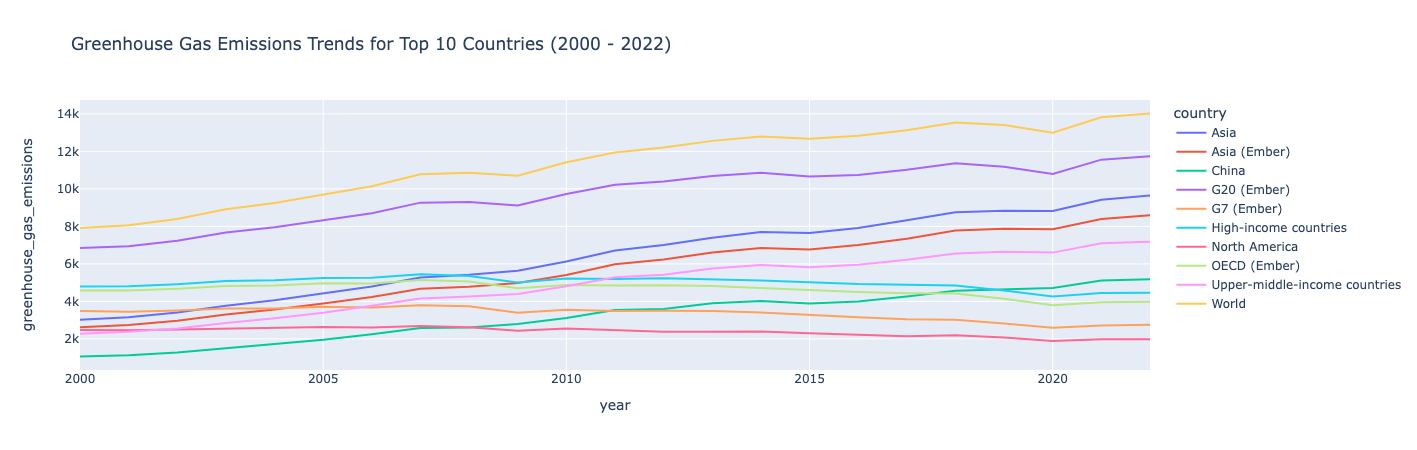
知見:
温室効果ガスの排出量は2000年から2022年にかけて増加傾向にありますが、排出量が比較的安定しており、その期間にわずかに減少した一部の国は例外です。
地域別の排出量のフィルタリングとグラフ化
地域ごとにデータを除外し、各地域の合計排出量を計算します。 次に、データを棒グラフとしてプロットします。
# Filter out regional entities
regions = ['Africa', 'Asia', 'Europe', 'North America', 'South America', 'Oceania']
# Calculate total emissions for each region
regional_emissions = df[df['country'].isin(regions)].groupby('country')['greenhouse_gas_emissions'].sum()
# Plot the comparison
fig = px.bar(regional_emissions, title="Greenhouse Gas Emissions by Region")
fig.show()
アウトプット:
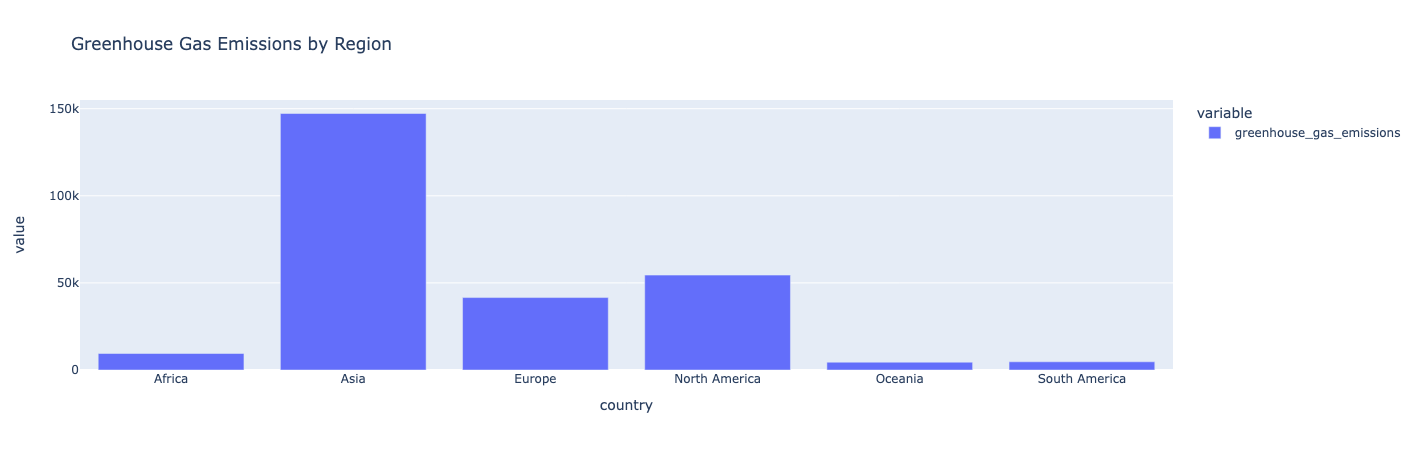
知見 :
アジアは温室効果ガスの排出量が最も多い国です。 オセアニア、南アメリカ、アフリカは、温室効果ガスの排出量が最も少ない地域です。
再生可能エネルギーシェアの成長を計算してグラフ化する
再生可能エネルギーの割合を、一次エネルギー消費量に対する再生可能エネルギー消費量の比率として計算する新しいフィーチャ/列を作成します。 次に、平均再生可能エネルギーシェアに基づいて国をランク付けします。 上位 10 か国について、再生可能エネルギーのシェアを時系列でプロットします。
# Calculate the renewable energy share and save it as a new column called "renewable_share"
df['renewable_share'] = df['renewables_consumption'] / df['primary_energy_consumption']
# Rank countries by their average renewable energy share
renewable_ranking = df.groupby('country')['renewable_share'].mean().sort_values(ascending=False)
# Filter for countries leading in renewable energy share
leading_renewable_countries = renewable_ranking.head(10).index
leading_renewable_data = df[df['country'].isin(leading_renewable_countries)]
# filtered_data = df[(df['year'] >= 2000) & (df['year'] <= 2022)]
leading_renewable_data_filter=leading_renewable_data[(leading_renewable_data['year'] >= 2000) & (leading_renewable_data['year'] <= 2022)]
# Plot renewable share over time for top renewable countries
fig = px.line(leading_renewable_data_filter, x='year', y='renewable_share', color='country',
title="Renewable Energy Share Growth Over Time for Leading Countries")
fig.show()
アウトプット:
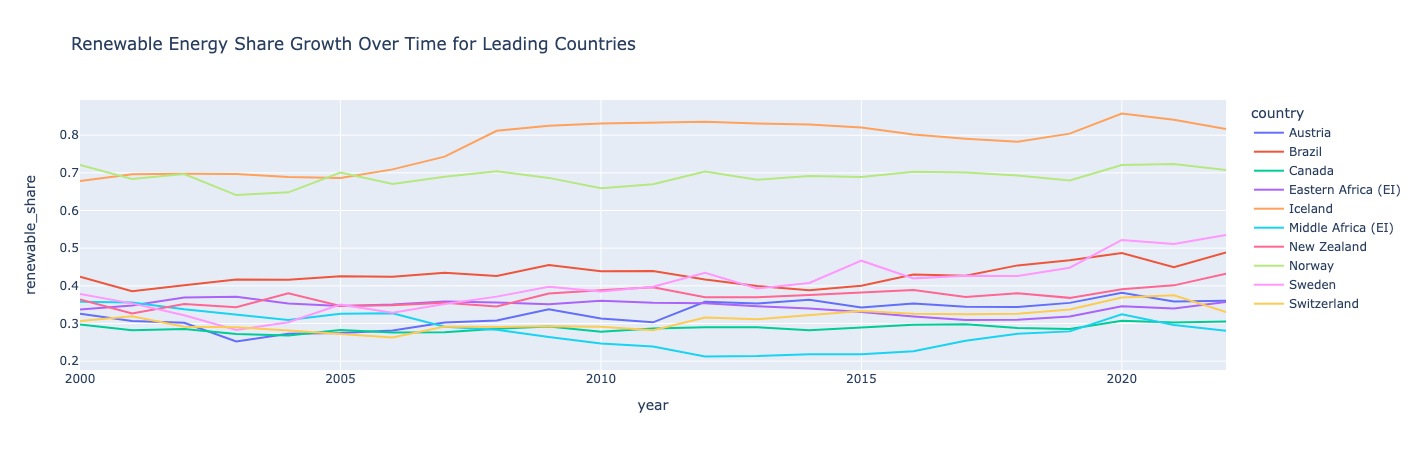
知見:
ノルウェーとアイスランドは再生可能エネルギーで世界をリードしており、消費量の半分以上が再生可能エネルギーによるものです。
アイスランドとスウェーデンは、再生可能エネルギーの割合が最も大きく伸びた国だった。全ての国で一時的な落ち込みと上昇が見られ、再生可能エネルギーのシェア拡大は必ずしも直線的ではないことが示された。中央アフリカは2010年代初頭に落ち込んだものの、2020年には回復した。
Scatter プロット: 再生可能エネルギーの影響を上位に表示
上位 10 社のエミッターのデータをフィルタリングし、散布図プロットを使用して、再生可能エネルギーの割合と温室効果ガス排出量の経時的な推移を調べます。
# Select top emitters and calculate renewable share vs. emissions
top_emitters = df.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
top_emitters_data = df[df['country'].isin(top_emitters)]
# Plot renewable share vs. greenhouse gas emissions over time
fig = px.scatter(top_emitters_data, x='renewable_share', y='greenhouse_gas_emissions',
color='country', title="Impact of Renewable Energy on Emissions for Top Emitters")
fig.show()
アウトプット:
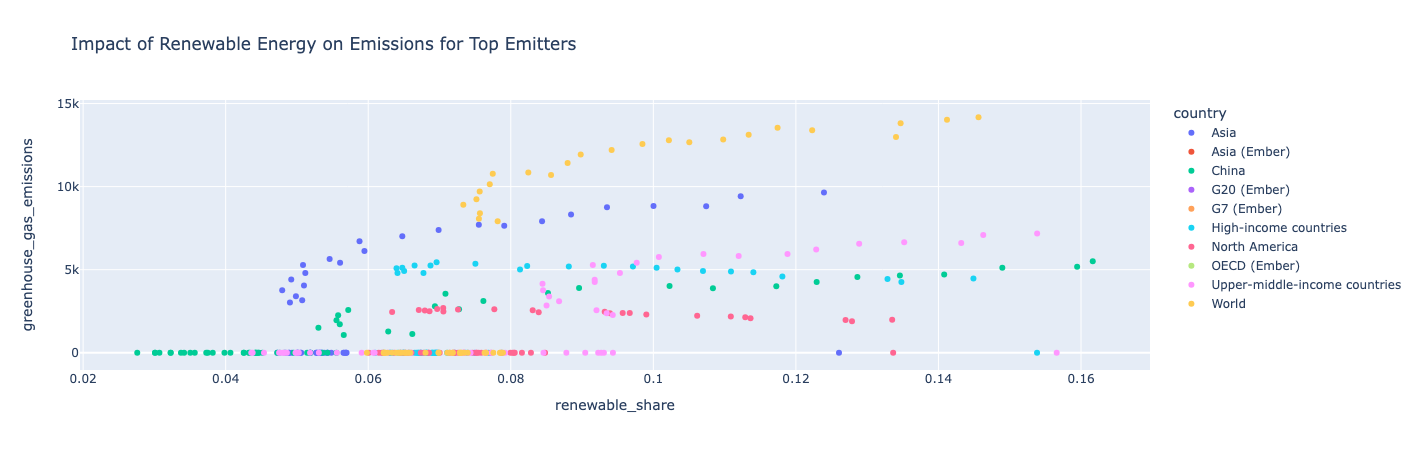
知見:
ある国が再生可能エネルギーをより多く使用すると、温室効果ガスの排出量も増えるため、総エネルギー消費量は再生可能エネルギー消費量よりも速く増加します。 北米は例外で、再生可能エネルギーの割合が増加し続けたため、温室効果ガスの排出量は年間を通じて比較的一定に保たれていました。
世界のエネルギー消費量の予測をモデル化
世界の一次エネルギー消費量を年ごとに集計し、自己回帰積分移動平均(ARIMA)モデルを構築して、今後数年間の世界の総エネルギー消費量を予測します。 Matplotlibを使用して、過去および予測されたエネルギー消費をプロットします。
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt
# Aggregate global primary energy consumption by year
global_energy = df[df['country'] == 'World'].groupby('year')['primary_energy_consumption'].sum()
# Build an ARIMA model for projection
model = ARIMA(global_energy, order=(1, 1, 1))
model_fit = model.fit()
forecast = model_fit.forecast(steps=10) # Projecting for 10 years
# Plot historical and forecasted energy consumption
plt.plot(global_energy, label='Historical')
plt.plot(range(global_energy.index[-1] + 1, global_energy.index[-1] + 11), forecast, label='Forecast')
plt.xlabel("Year")
plt.ylabel("Primary Energy Consumption")
plt.title("Projected Global Energy Consumption")
plt.legend()
plt.show()
アウトプット:
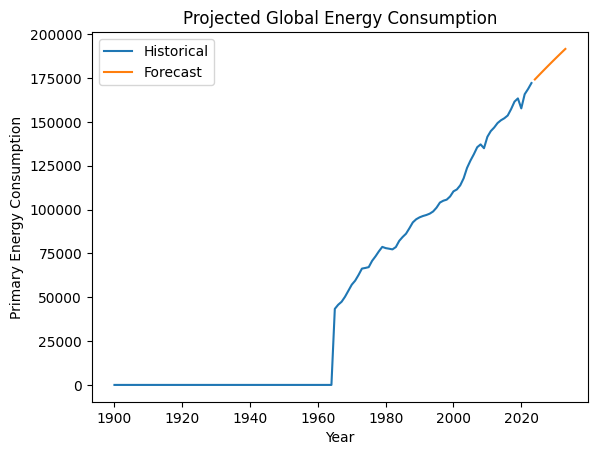
知見:
このモデルでは、世界のエネルギー消費量は増加し続けると予測されています。
ノートブックの例
次のノートブックを使用して、この記事の手順を実行します。 ノートブックを Databricks ワークスペースにインポートする手順については、「 ノートブックのインポート」を参照してください。
チュートリアル: 地球のエネルギーデータを使用した EDA
次のステップ
データセットに対して最初の探索的データ分析を実行したので、次の手順を試してください。
- その他の EDA 視覚化の例については、 サンプルノートブック の付録を参照してください。
- このチュートリアルの途中でエラーが発生した場合は、組み込みのデバッガーを使用してコードをステップ実行してみてください。 ノートブックのデバッグを参照してください。
- ノートブックをチームと共有 して、分析をチームが理解できるようにします。 付与するアクセス許可に応じて、分析をさらに進めるためのコードの開発を支援したり、さらに調査するためのコメントや提案を追加したりできます。
- 分析を確定したら、ノートブック ダッシュボードまたは主要なビジュアライゼーションを含む AI/BIダッシュボード を作成して、関係者と共有します。