ユースケース
ベータ版
6月15日より、LakebaseはGCPでベータとして利用可能です。サポートされているリージョンについては、「リージョンの可用性」を参照してください。
レイクハウスデータの提供
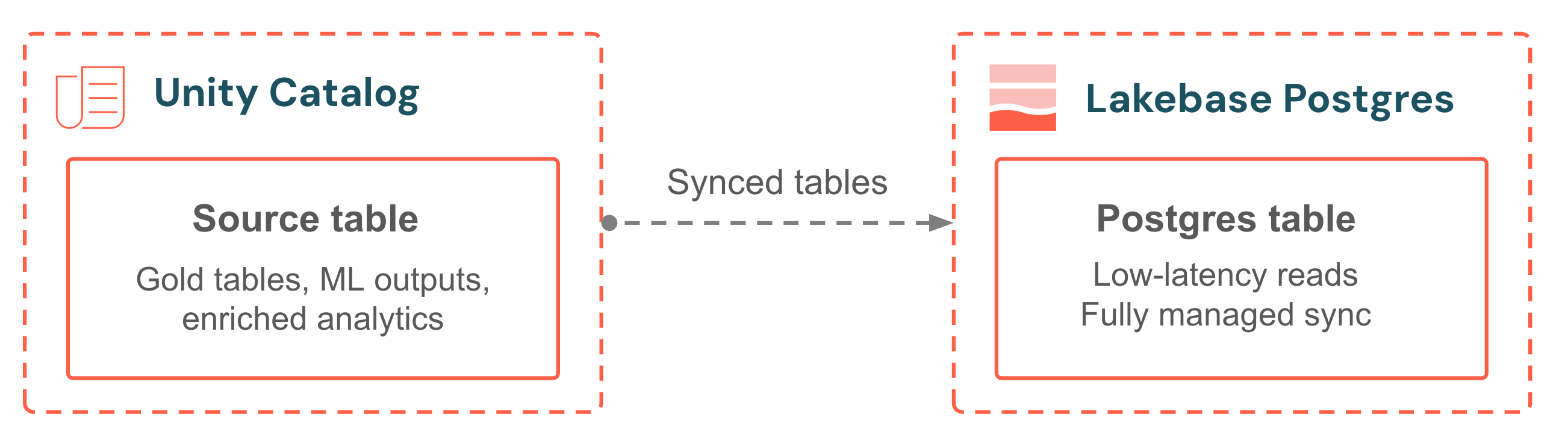
同期されたテーブルは、Unity CatalogのデータをLakebaseデータベースに取り込み、低遅延のトランザクション読み取りを実現します。ソース テーブルを選択し、同期モードを選択すると、パイプラインはフルマネージドになります。 同期スクリプトも、外部オーケストレーションも、監視対象のジョブもありません。連続モードでは、データソースから数秒以内の精度でデータを保持します。トリガーモードは、定期的な増分更新によって鮮度とコストのバランスを取ります。アプリケーションは常に、独自の運用データとともに最新のアナリティクスを提供します。
最初のステップ | 学習パス |
|---|---|
|
アプリケーションバックエンド
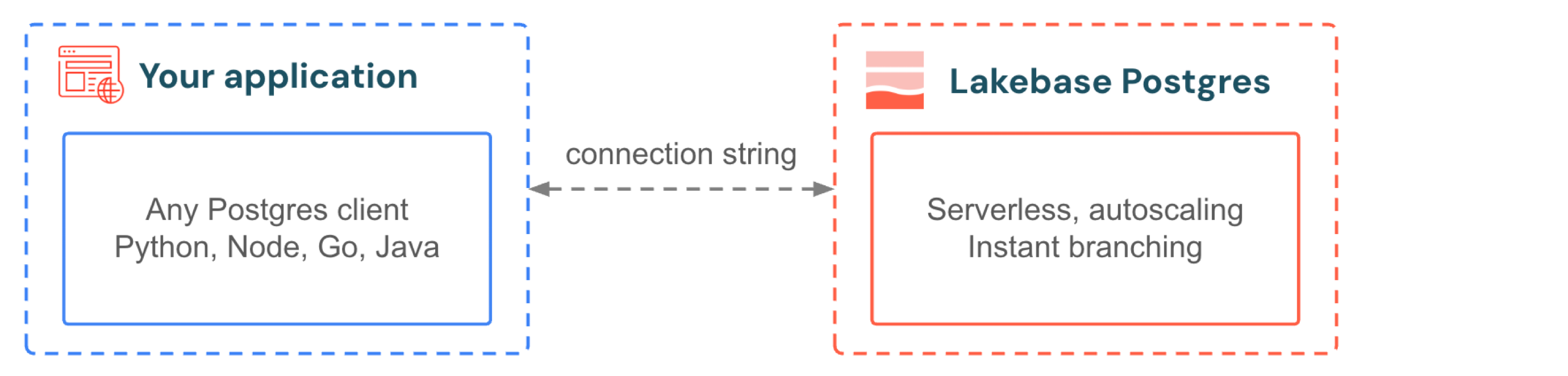
アプリケーションは、他のPostgresデータベースに接続するのと同じ方法でLakebaseに接続します。既に使い慣れているドライバーやフレームワークを使用してください。アプリのトラフィックが急増した場合、オートスケールは接続を切断せずにコンピュートを追加します。 トラフィックが停止すると、スケール・トゥ・ゼロ機能はデータベースを一時停止し、次のクエリが呼び出された際に数百ミリ秒以内に再アクティブ化します。ピーク時にプロビジョニングを行う必要はなく、アイドル状態に対して料金を支払う必要はありません。 開発においては、ブランチングによって、各開発者はデータシード、ストレージの重複、待ち時間なしに、本番運用データベースの独立したコピーを利用できるようになります。
最初のステップ | 学習パス |
|---|---|
|
|
AIエージェントとML
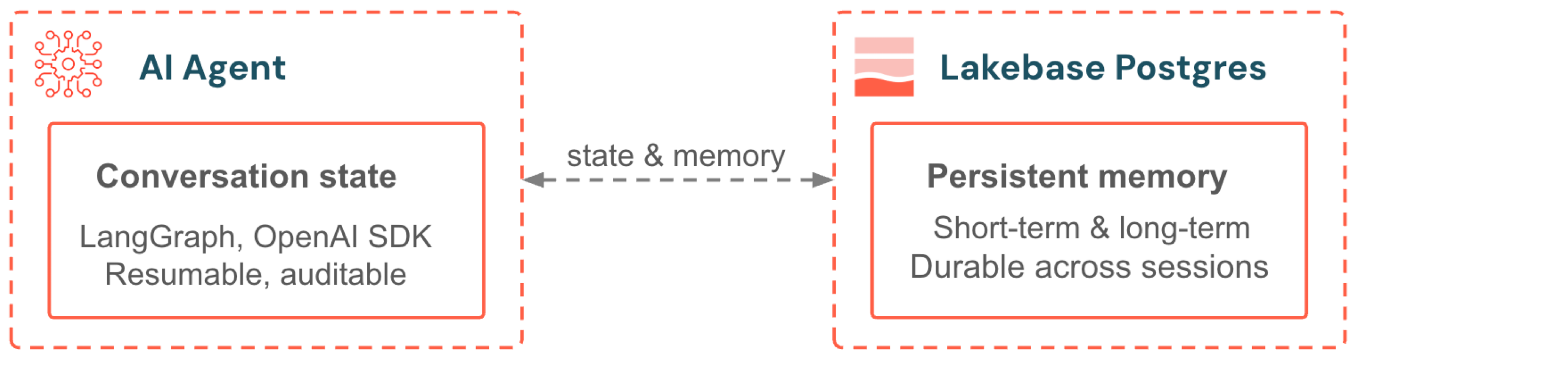
Lakebase は、AI エージェントのメモリとリアルタイムの Feature Serving のバックエンドとして機能します。LangGraph または OpenAI Agents SDK で構築されたエージェントは、Postgres に会話状態と長期メモリを格納します。Model Serving で提供されるモデルは、Lakebase Autoscaling を搭載したオンライン Feature Store を介して特徴量データにアクセスします。どちらも、自動スケーリング、スケールトゥゼロ、および Unity Catalog ガバナンスの恩恵を受けます。
最初のステップ | 学習パス |
|---|---|
|
|