OpenSharing の共有を作成します
このページでは、OpenSharingで共有を作成する方法を説明します。
共有は、Unity Catalogにおけるセキュリティ保護可能なオブジェクトであり、1つ以上の受信者と次のデータ資産を共有するために使用します。
- テーブルとテーブルパーティション
- ストリーミングテーブル
- マネージド Iceberg テーブル
- フォーリン Iceberg テーブル
- フォーリンスキーマとテーブル
- 行および列レベルでアクセスを制限する動的ビュー を含む ビュー
- マテリアライズドビュー
- ボリューム
- Python UDF
- ノートブック
- AIモデル
- Genieエージェント
スキーマ (データベース) 全体を共有すると、受信者は、共有した時点でスキーマ内のすべてのテーブル、ストリーミングテーブル、ビュー、マテリアライズドビュー、モデル、ボリュームにアクセスできるほか、今後スキーマに追加されたデータや AI アセットにもアクセスできます。
共有には、1つのUnity CatalogメタストアのデータとAIアセットのみを含めることができます。共有からデータとAIアセットをいつでも追加または削除できます。
共有を作成する前に、アカウントでOpenSharing を設定する(プロバイダー向け)ことを確認してください。
共有モデルの詳細については、共有、プロバイダー、および受信者を参照してください。
要件
完了したい各タスクについて、記載されている要件を満たしていることを確認してください。
データ資産を共有に追加する際は、Databricks は、共有所有者としてグループを使用することをお勧めします。
タスク | 要件 |
|---|---|
共有を作成する |
|
共有に次の項目を追加します:
|
|
スキーマ全体または外部スキーマを共有する |
|
共有にボリュームを追加する |
|
Python UDF を共有に追加する |
|
共有にモデルを追加する |
|
ノートブック ファイルを共有に追加する |
|
コンピュートの要件
- Databricks ノートブックを使用して共有を作成する場合、コンピュートリソースは Databricks Runtime 11.3 LTS 以降を使用し、標準または専用アクセスモード (以前の共有およびシングルユーザー) を備えている必要があります。
- SQLステートメントを使用して共有にスキーマを追加する場合 (またはスキーマを更新または削除する場合)、 Databricks Runtime 13.3 LTS以上を実行している SQL ウェアハウスまたはコンピュートを使用する必要があります。 カタログエクスプローラ を使用して同じことを実行する場合、コンピュートの要件はありません。
共有オブジェクトを作成する
共有オブジェクトを作成する前に、要件を満たしていることを確認してください。
共有を作成するには、カタログエクスプローラ、Databricks Unity Catalog CLI、または Databricks ノートブックまたは Databricks SQL クエリエディターで CREATE SHARE SQL コマンドを使用します。
- Catalog Explorer
- SQL
- CLI
-
Databricks ワークスペースで、
 カタログ をクリックします。
カタログ をクリックします。 -
カタログ ウィンドウの上部にある
 歯車アイコンをクリックし、 OpenSharing を選択します。
歯車アイコンをクリックし、 OpenSharing を選択します。または、右上隅の Share > OpenSharing をクリックします。
-
自分が共有 タブで、 データの共有 ボタンをクリックします。
-
共有の作成 ページで、共有の 名前 とオプションのコメントを入力します。
-
保存して続行 をクリックします。
データアセットの追加を続けることも、停止して後で戻ることもできます。
-
**データ資産の追加**タブで、共有するデータ資産を選択します。
詳細な手順、追加要件、および関連する制限事項については、以下を参照してください。
-
保存して続行 をクリックします。
-
ノートブックを追加 タブで、共有するノートブックを選択します。
詳細な手順については、「ノートブック ファイルを共有に追加」を参照してください。
-
保存して続行 をクリックします。
-
受信者の追加 タブで、共有する受信者を選択します。
詳細な手順については、OpenSharing データ共有へのアクセスを管理する (プロバイダー向け)を参照してください。
-
「**データを共有**」をクリックして、受信者とデータを共有します。
まだ受信者を作成していない場合は、 データを共有 をクリックし、受信者を作成してから、後でアクセス権を付与してください。
ノートブックまたは Databricks SQL クエリー エディターで次のコマンドを実行します。
CREATE SHARE [IF NOT EXISTS] <share-name>
[COMMENT "<comment>"];
共有にテーブル、ストリーミングテーブル、ボリューム、ビュー、マテリアライズドビュー、およびモデルを追加できるようになりました。
詳細な手順、追加要件、および関連する制限事項については、以下を参照してください。
Databricks CLI を使用して、次のコマンドを実行します。
databricks shares create <share-name>
--commentを使用してコメントを追加したり、--jsonを使用して共有にアセットを追加したりできます。詳細については、以降のセクションを参照してください。
共有にテーブル、ストリーミングテーブル、ボリューム、ビュー、マテリアライズドビュー、およびモデルを追加できるようになりました。
詳細な手順、追加要件、および関連する制限事項については、以下を参照してください。
共有にテーブルを追加する
共有にテーブルを追加する前に、要件を満たしていることを確認してください。
ワークスペース管理者であり、ワークスペース管理者グループからテーブルを含むスキーマおよびカタログに対する USE SCHEMA および USE CATALOG 権限を継承している場合、そのテーブルを共有に追加することはできません。まず、スキーマおよびカタログに対する USE SCHEMA および USE CATALOG 権限を自身に付与する必要があります。
テーブルのコメント、列のコメント、および主キー制約は、2024年7月25日以降にDatabricks-to-Databricks 共有を使用して受信者と共有される共有に含まれます。リリース日より前に受信者と共有された共有を通じてコメントと制約の共有を開始するには、受信者のアクセス権を取り消して再付与し、コメントと制約の共有をトリガーする必要があります。
共有にテーブルを追加するには、カタログエクスプローラ、Databricks Unity Catalog CLI、または Databricks ノートブックや Databricks SQL クエリ エディタで SQL コマンドを使用します。
- Catalog Explorer
- SQL
- CLI
-
Databricks ワークスペースで、
カタログ をクリックします。 -
カタログ ウィンドウの上部にある
歯車アイコンをクリックし、 OpenSharing を選択します。または、右上隅の Share > OpenSharing をクリックします。
-
「**自分が共有**」タブで、テーブルを追加する共有を見つけて、その名前をクリックします。行トラッキングが有効なテーブルを追加できます。受信者は行トラッキング列をクエリできます。
-
**アセットの管理 > アセットの編集**をクリックします。
-
アセットの編集 ページで、スキーマ全体 (データベース) または個々のテーブルを選択します。
-
テーブルを選択するには、まずカタログを選択し、次にそのテーブルを含むスキーマ、最後にテーブル自体を選択します。
ワークスペース検索を使用して、テーブルを名前、列名、またはコメントで検索できます。「ワークスペース オブジェクトの検索」を参照してください。
-
スキーマを選択するには、まずカタログを選択し、次にスキーマを選択します。
共有スキーマの詳細については、「 共有にスキーマを追加する」を参照してください。
-
-
履歴 : テーブル履歴を共有して、受信者がタイムトラベルクエリを実行したり、Spark 構造化ストリーミングでテーブルを読み取ったり、トランザクションを実行したりできるようにします。Databricks-to-Databricks 共有では、パフォーマンス向上のためにテーブルの Delta ログも共有されます。履歴共有によるテーブルの読み取りパフォーマンス向上を参照してください。履歴の共有には、Databricks Runtime 12.2 LTS 以降が必要です。
顧客がtable_changes() 関数を使用してテーブルのチェンジデータフィード (CDF) をクエリできるようにするには、共有する前にテーブルで CDF を有効にする必要があります WITH HISTORY。
-
(オプション)
 エイリアス 列または パーティション 列の下にある をクリックして、エイリアスまたはパーティションを追加します。スキーマ全体を選択した場合、エイリアスとパーティションは使用できません。スキーマ全体を選択した場合、テーブル履歴はデフォルトで含まれます。
エイリアス 列または パーティション 列の下にある をクリックして、エイリアスまたはパーティションを追加します。スキーマ全体を選択した場合、エイリアスとパーティションは使用できません。スキーマ全体を選択した場合、テーブル履歴はデフォルトで含まれます。- エイリアス : テーブル名を読みやすくするための別名です。エイリアスは、受信者が参照し、クエリで使用する必要があるテーブル名です。エイリアスが指定されている場合、受信者は実際のテーブル名を使用できません。
- パーティション : テーブルの一部のみを共有します。たとえば、
(column = 'value').共有するテーブルパーティションの指定および受信者のプロパティを使用してパーティションのフィルタリングを行うを参照してください。
-
保存 をクリックします。
テーブルを追加するには、ノートブックまたは Databricks SQL クエリーエディターで次のコマンドを実行します。
ALTER SHARE <share-name> ADD TABLE <catalog-name>.<schema-name>.<table-name> [COMMENT "<comment>"]
[PARTITION(<clause>)] [AS <alias>]
[WITH HISTORY | WITHOUT HISTORY];
次を実行して、スキーマ全体を追加します。ADD SCHEMAコマンドを使用するには、SQLウェアハウスまたは13.3LTS 以降のDatabricks Runtimeを実行するコンピュートが必要です。共有スキーマの詳細については、「 共有にスキーマを追加する」を参照してください。
ALTER SHARE <share-name> ADD SCHEMA <catalog-name>.<schema-name>
[COMMENT "<comment>"];
以下のオプションがあります。スキーマ全体を選択した場合、PARTITION と AS <alias> は利用できません。
-
PARTITION(<clause>): テーブルの一部のみを共有する場合は、パーティションを指定できます。たとえば、(column = 'value')のように指定します。共有するテーブル パーティションの指定および受信者のプロパティを使用してパーティションのフィルター処理を行うをご覧ください。 -
AS <alias>:テーブル名をより読みやすくするための代替テーブル名、または エイリアス 。エイリアスは、受信者が参照し、クエリで使用する必要があるテーブル名です。エイリアスが指定されている場合、受信者は実際のテーブル名を使用できません。<schema-name>.<table-name>の形式を使用してください。 -
WITH HISTORYまたはWITHOUT HISTORY:WITH HISTORYが指定されている場合、テーブルを完全な履歴とともに共有し、受信者がタイムトラベルクエリー、ストリーミング読み取り、およびトランザクションを実行できるようにします。Databricks-to-Databricks共有の場合、履歴共有によってテーブルのDeltaログも共有され、パフォーマンスが向上します。テーブル共有のデフォルトの動作は、コンピュートがDatabricks Runtime 16.2以上を実行している場合はWITH HISTORY、それ以前のDatabricks Runtimeバージョンの場合はWITHOUT HISTORYです。スキーマ共有の場合、Databricks Runtimeのバージョンに関係なく、デフォルトはWITH HISTORYです。WITH HISTORYおよびWITHOUT HISTORYには、Databricks Runtime 12.2 LTS以上が必要です。履歴共有によるテーブル読み取りパフォーマンスの向上も参照してください。
タイムトラベルクエリやストリーミング読み取りを行うことに加えて、受信者がtable_changes()関数を使用してテーブルのチェンジデータフィード(CDF)をクエリできるようにするには、テーブルを共有する前に、テーブルでCDFを有効にする必要がありますWITH HISTORY。
ALTER SHAREオプションの詳細については、「ALTER SHARE」を参照してください。
テーブルを追加するには、Databricks CLI を使用して、次のコマンドを実行します。
databricks shares update <share-name> \
--json '{
"updates": [
{
"action": "ADD",
"data_object": {
"name": "<table-full-name>",
"data_object_type": "TABLE",
"shared_as": "<table-alias>"
}
}
]
}'
スキーマを追加するには、次の Databricks CLI コマンドを実行します。
databricks shares update <share-name> \
--json '{
"updates": [
{
"action": "ADD",
"data_object": {
"name": "<schema-full-name>",
"data_object_type": "SCHEMA"
}
}
]
}'
テーブルに限り、"data_object_type" を省略できます。
この例に記載されているオプションについては、SQLタブで手順をご覧ください。
追加のパラメーターについては、databricks shares update --help を実行するか、REST API リファレンスのPATCH /api/2.1/unity-catalog/shares/ を参照してください。
共有からテーブルを削除する方法については、共有の更新を参照してください。
クラウドトークンの適格性
Databricks は、クラウドトークン(一時的なパススコープのクラウド認証情報)を使用して、受信者に共有Deltaテーブルファイルへの直接の読み取りアクセスを付与します。Databricks-to-Open共有プロトコルでは、これは*ディレクトリベースアクセスモード*とも呼ばれます。ビュー、マテリアライズドビュー、フォーリンテーブル、ストリーミングテーブル、ボリューム、ノートブック、Python UDF、およびAIモデルはサポートされていません。どのテーブルが対象となるかは、共有プロトコルによって異なります。
Databricks-to-Databricks 共有 :次のすべての条件が当てはまる場合は、クラウド トークンが使用されます:
- テーブルは
WITH HISTORYで共有されています (最初からの完全な履歴)。 - テーブルはパーティションフィルターなしで共有されます。
Databricks-to-Open 共有:クラウド トークン(ディレクトリベースのアクセス モード)は、次のすべてが当てはまる場合に使用されます。
- 共有オブジェクトは、 マネージドまたは外部のDeltaテーブル です。
- テーブルは
WITH HISTORYで共有されています (最初からの完全な履歴)。 - テーブルはパーティションフィルターなしで共有されます。
- このテーブルは CCv2 テーブルではありません。
- テーブルはデフォルトストレージを使用していません。
Databricks-to-Databricks共有の場合、クラウドトークンは長期間有効なベアラー トークンなしでUnity Catalogメタストア間で直接交換され、直接ソーステーブルアクセスと同等のパフォーマンスが実現します。DatabricksとOpen間での共有の場合、OpenSharingサーバーは、リストおよびメタデータ応答に、テーブルのクラウドストレージの場所とaccessModes: ["url", "dir"]を含みます。Open recipients は、Generate Temporary Table Credentials エンドポイントを呼び出して資格情報を取得し、クラウド ストレージから直接読み取ることができます。
クラウド トークン アクセスを使用する場合、受信者は共有 Delta テーブルのルート ディレクトリにスコープ設定された資格情報を受け取ります。これにより、データファイルと Delta log の両方への読み取りアクセスが許可されます。Delta log には、各テーブルバージョンのコミット履歴、コミッターに関する情報、および vacuum されていない削除済みデータが含まれています。
共有するテーブルパーティションを指定
テーブルを共有に追加するときに、テーブルの一部のみを共有するには、パーティション仕様を指定してください。Catalog Explorer、Databricks Unity Catalog CLI、またはDatabricksノートブックもしくはDatabricks SQLクエリーエディターのSQLコマンドを使用して、共有にテーブルを追加または共有を更新する際に、パーティションを指定します。共有にテーブルを追加するおよび共有を更新するを参照してください。
例
次のSQLの例は、year、month、およびdateの列によってパーティション化された、inventoryテーブル内のデータの一部を共有します:
- 2021年のデータ。
- 2020年12月のデータ。
- 2019年12月25日のデータ。
ALTER SHARE share_name
ADD TABLE inventory
PARTITION (year = "2021"),
(year = "2020", month = "Dec"),
(year = "2019", month = "Dec", date = "2019-12-25");
受信者プロパティを使用してパーティションフィルタリングを行う
データ受信者のプロパティに一致する、パラメーター化されたパーティション共有とも呼ばれるテーブルパーティションを共有できます。
デフォルトプロパティには次のものが含まれます。
databricks.accountIdデータ受信者が属するDatabricksアカウント (Databricks-to-Databricks共有のみ)。databricks.metastoreId: データ受信者が属する Unity Catalog メタストア (Databricks間共有のみ)。databricks.nameデータ受信者の名前。
受信者を作成または更新する際に、任意のカスタムプロパティを作成できます。
受信者プロパティでフィルタリングすることで、複数のDatabricksアカウント、ワークスペース、およびユーザー間で、同じ共有を使用して同じテーブルを共有しつつ、データ境界を維持できます。
たとえば、テーブルにDatabricksアカウントID列が含まれている場合、DatabricksアカウントIDによって定義されたテーブルパーティションを持つ単一の共有を作成できます。共有すると、OpenSharing は、各受信者に Databricks アカウントに関連付けられたデータのみを動的に提供します。
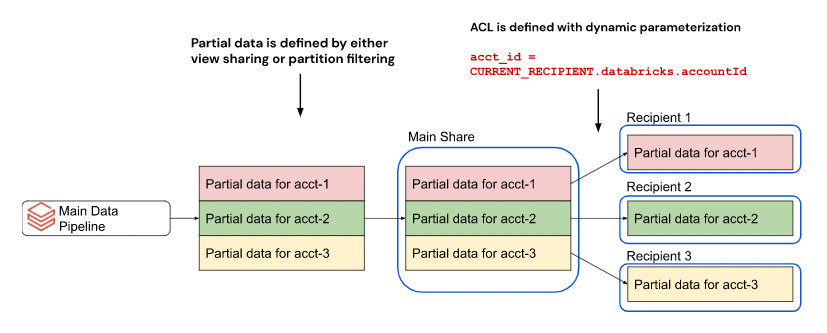
プロパティによって動的にパーティション分割する機能がなければ、受信者ごとに個別の共有を作成する必要があります。
共有を作成または更新する際に、受信者プロパティでフィルタリングするパーティションを指定するには、カタログエクスプローラまたは Databricks ノートブックまたは Databricks SQL クエリーエディターで CURRENT_RECIPIENT SQL 関数を利用できます。
受信者のプロパティは、Databricks Runtime 12.2以上で利用できます。
- Catalog Explorer
- SQL
-
Databricks ワークスペースで、
カタログ をクリックします。 -
カタログ ウィンドウの上部にある
歯車アイコンをクリックし、 OpenSharing を選択します。または、右上隅の Share > OpenSharing をクリックします。
-
自分が共有 タブで、更新する共有を見つけて、その名前をクリックします。
-
アセットの管理 > データ アセットの追加 をクリックします。
-
[テーブルの追加] ページで、テーブルが含まれるカタログとデータベースを選択し、そのテーブルを選択してください。
どのカタログとデータベースにテーブルが含まれているか不明な場合は、ワークスペース検索を使用して、名前、列名、またはコメントで検索できます。「ワークスペース オブジェクトの検索」を参照してください。
-
(オプション) パーティション 列の下の
をクリックして、パーティションを追加します。パーティションをテーブルに追加 ダイアログで、次の構文を使用してプロパティ・ベースのパーティション仕様を追加します。
(<column-name> = CURRENT_RECIPIENT().<property-key>)例えば
(country = CURRENT_RECIPIENT().country) -
保存 をクリックします。
ノートブックまたは Databricks SQL クエリー エディターで次のコマンドを実行します。
ALTER SHARE <share-name> ADD TABLE <catalog-name>.<schema-name>.<table-name>
PARTITION (<column-name> = CURRENT_RECIPIENT().<property-key>);
例えば
ALTER SHARE acme ADD TABLE acme.default.some_table
PARTITION (country = CURRENT_RECIPIENT().country);
削除ベクトルまたは列マッピングを含むテーブルを共有に追加します
プレビュー
この機能は パブリック プレビュー段階です。
削除ベクトルは、Delta テーブルで有効にできるストレージ最適化機能です。「Databricks の削除ベクトル」を参照してください。
Databricks では、Delta テーブルの列マッピングもサポートされています。 Delta Lake 列マッピングを使用した列の名前変更と削除を参照してください。
削除ベクトルまたは列マッピングを使用してテーブルを共有するには、履歴と共有する必要があります。 共有にテーブルを追加するを参照してください。
削除ベクトルまたは列マッピングが設定されたテーブルを共有すると、受信者は、SQLウェアハウス、Databricks Runtime 14.1以降で実行されているコンピュート、またはオープンソース delta-sharing-spark 3.1以降で実行されているコンピュートを使用して、そのテーブルをクエリできます。「削除ベクトルまたは列マッピングが有効なテーブルの読み取り」および「削除ベクトルまたは列マッピングが有効なテーブルの読み取り」を参照してください。
共有にスキーマを追加する
共有にスキーマを追加する前に、要件を満たしていることを確認してください。
共有にスキーマ全体を追加すると、共有の作成時にスキーマ内のすべてのデータアセットに受信者がアクセスできるようになります。また、時間の経過とともにスキーマに追加されるすべてのアセットにもアクセスできるようになります。これには、スキーマ内のすべてのテーブル、ビュー、およびボリュームが含まれます。この方法で共有されたテーブルには、常に完全な履歴が含まれます。
受信者とスキーマを共有する
共有にスキーマを追加するには、「共有にテーブルを追加する」の手順に従い、スキーマの追加方法を規定するコンテンツに注意してください。
SQLを使用してスキーマを追加、更新、または削除するには、 Databricks Runtime 13.3 LTS以上を実行している SQL ウェアハウスまたはクラスターが必要です。 カタログエクスプローラ を使用して同じことを実行する場合、コンピュートの要件はありません。
制限事項
-
サポートされていないデータアセットが含まれていても、スキーマを共有できます。これらのアセットはフィルタリングされ、受信者と共有されません。サポートされていないデータアセットは次のとおりです:
- パーティションフィルタリングを伴うリキッドクラスタリングを使用するテーブル
- V2 チェックポイント付き R2 テーブル
- 照合順序が有効になっているテーブル
- 行フィルターまたは列マスクを持つテーブル
SHALLOW CLONEtables- 共有テーブル内の外部キー制約
-
スキーマ全体を共有する場合、テーブルエイリアス、パーティション、およびボリュームエイリアスは使用できません。スキーマ内のアセットにエイリアスまたはパーティションを作成している場合、スキーマ全体を共有に追加すると、それらは削除されます。
-
スキーマ内のテーブルまたはボリュームに対して詳細オプションを指定したい場合は、SQLを使用してそのテーブルまたはボリュームを共有し、異なるスキーマ名でエイリアスを付ける必要があります。
-
スキーマレベルのエイリアシングはサポートされていません。異なるカタログの同じ名前のスキーマを同じ共有に追加することはできません。代わりに、エイリアススキーマ名で個々のテーブルを共有します。
ABACポリシーで保護されたテーブルとスキーマを共有に追加する
属性ベースのアクセス制御 (ABAC) は、Databricks全体で柔軟、スケーラブル、一元化されたアクセスコントロールを提供するデータガバナンスモデルです。
標準テーブルと同様に、ABACポリシーで保護されたテーブルやスキーマを共有できます。データアセットにABACポリシーを適用する方法については、行フィルターと列マスクのポリシーを作成および管理するを参照してください。
ただし、 特権ユーザー である必要があります。特権ユーザーとは、共有の所有者であり、データ資産に適用されるABACポリシーから除外されたユーザーです。このポリシーは、受信者のアクセスを管理しません。受信者は、共有資産への完全なアクセス権を持っています。ABAC の制限が適用されます。
共有にストリーミングテーブルを追加する
ストリーミングテーブルは、ストリーミングまたは増分データ処理に対する追加サポートを備えた通常のDeltaテーブルです。ストリーミングテーブルは、追加専用のデータソース向けに設計されており、入力を一度だけ処理します。スタンドアロンのストリーミングテーブルを使用するを参照してください。
共有にストリーミングテーブルを追加する前に、要件を満たしていることを確認してください。
追加要件
-
ストリーミングテーブルの共有が設定されているアカウントで、**ワークフロー、ノートブック、LakeFlow Pipelines向けのServerlessコンピュート**を有効にする必要があります。See Serverless コンピュートへの接続.
-
ワークスペースでワークスペースとカタログのバインディングが有効になっている場合は、そのワークスペースがストリーミングテーブルがあるカタログに対する読み取り/書き込みアクセス権を持っていることを確認してください。詳細については、ワークスペースとカタログのバインドを参照してください。
-
共有可能なストリーミングテーブルは、 Delta テーブルまたはその他の共有可能なストリーミングテーブルまたはビューで定義する必要があります。
-
ストリーミングテーブルを共有に追加するときは、Databricks Runtime LTS 13.3 以上のコンピュートあるいはSQLウェアハウスを使用する必要があります。
制限事項:
-
ストリーミングテーブルでは、行フィルターと列マスクを持つことはできません。
- ストリーミングテーブルのベーステーブルは、行フィルターと列マスクを持つことができます。
-
ストリーミングテーブルにはパーティションフィルターを含めることはできません。代わりに、ストリーミングテーブルの上にビューを作成します。
-
Databricks-to-Open 共有の受信者は、ストリーミングテーブルの現在のスナップショットのみを読み取ることができます。タイムトラベル、クエリ履歴、ストリーミング読み取り、および CDF は、オープン受信者にはサポートされていません。相手の方がCDFを必要とする場合は、CDFを有効にした通常のDeltaテーブルを共有してください。
-
受信者が基盤となるデータに直接アクセスできない場合、
LIMIT句と述語プッシュダウンはサポートされません。システムは、クエリフィルターに関係なく、すべてのクエリ結果を受信者に返す前に完全に具体化します。共有ビュー、マテリアライズドビュー、およびストリーミングテーブルの基になるデータに受信者は直接アクセスできますか?をご覧ください。 -
ストリーミングテーブルの一般的な制限も適用されます。ストリーミングテーブルの制限を参照してください。
ストリーミングテーブルを受信者と共有する
共有にストリーミングテーブルを追加するには:
- Catalog Explorer
- SQL
- CLI
-
Databricks ワークスペースで、
カタログ をクリックします。 -
カタログ ウィンドウの上部にある
歯車アイコンをクリックし、 OpenSharing を選択します。または、右上隅の Share > OpenSharing をクリックします。
-
「 自分が共有 」タブで、ストリーミングテーブルを追加する共有を見つけて、その名前をクリックします。
-
**アセットの管理 > アセットの編集**をクリックします。
-
アセットの編集 ページで、共有するストリーミングテーブルを検索または参照し、選択します。
-
(オプション) エイリアス 列で、
をクリックしてエイリアス、つまり代替のストリーミングテーブル名を指定し、ストリーミングテーブル名をより読みやすくします。エイリアスは、受信者が確認し、クエリで使用する必要がある名前です。エイリアスが指定されている場合、受信者は実際のストリーミングテーブル名を使用できません。 -
保存 をクリックします。
ノートブックまたはDatabricks SQLクエリーエディタで次のコマンドを実行します。
ALTER SHARE <share_name> ADD TABLE <st_name> [COMMENT <comment>] [AS <shared_st_name>];
以下のDatabricks CLIコマンドを実行してください。
databricks shares update <share-name> \
--json '{
“updates”: [
{
“action”: “ADD”,
“data_object”: {
“name”: “<st-full-name>",
“data_object_type”: “TABLE”,
“comment”: “<comment>”
}
}
]
}'
共有からストリーミングテーブルを削除する方法に関する情報については、共有の更新を参照してください。
共有にマネージド Iceberg テーブルを追加
プレビュー
この機能は パブリック プレビュー段階です。
Apache Icebergは、アナリティクスワークロード向けのオープンソースのテーブル形式です。Databricksでは、Unity Catalog内にIcebergテーブルを作成でき、これらはマネージドIcebergテーブルと呼ばれます。
管理対象Icebergテーブルを共有に追加する前に、要件を満たしていることを確認してください。Icebergテーブルおよびマネージド Iceberg テーブルの制限が適用されます。制限事項を参照してください。
Databricks は、マネージド Iceberg テーブルを外部の Iceberg クライアントに共有することをサポートしていません。
共有にマネージド Iceberg テーブルを追加するには:
- Catalog Explorer
- SQL
- CLI
-
Databricks ワークスペースで、
カタログ をクリックします。 -
カタログ ウィンドウの上部にある
歯車アイコンをクリックし、 OpenSharing を選択します。または、右上隅の Share > OpenSharing をクリックします。
-
自分が共有 タブで、マネージドIcebergテーブルを追加する共有を見つけて、その名前をクリックします。
-
[ アセットの管理 ] > [ アセットの編集 ] をクリックします。
-
**アセットの編集**ページで、共有したいマネージド Iceberg テーブルを検索または参照して選択します。
-
(オプション) Alias 列で、
をクリックして、別名、または別のマネージド Iceberg テーブル名を指定し、名前をより読みやすくします。エイリアスは、受信者が確認し、クエリで使用する必要がある名前です。エイリアスが指定されている場合、受信者は実際のマネージド Iceberg テーブル名を使用できません。 -
保存 をクリックします。
ノートブックまたはDatabricks SQLクエリーエディターで次のコマンドを実行します。必要に応じて、管理対象Icebergテーブルを別の名前で公開するには、<shared_iceberg_table_name>を指定します。
ALTER SHARE <share_name> ADD TABLE <managed_iceberg_name> [COMMENT <comment>] [AS <shared_iceberg_table_name>];
以下のDatabricks CLIコマンドを実行してください。
databricks shares update <share-name> \
--json '{
“updates”: [
{
“action”: “ADD”,
“data_object”: {
“name”: “<managed-iceberg-full-name>",
“data_object_type”: “TABLE”,
“comment”: “<comment>”
}
}
]
}'
共有にフォーリンスキーマまたはテーブルを追加します。
ベータ版
この機能はベータ版です。ワークスペース管理者は、 プレビュー ページからこの機能へのアクセスを制御できます。Databricksのプレビューを管理するを参照してください。
レイクハウスフェデレーションを使用すると、Databricks を使用して、外部データソースに対してクエリを実行できます。外部システムによってデータとメタデータが管理されている外部スキーマとテーブルを作成でき、Unity Catalogがこれらのテーブルをクエリするためのデータガバナンスを追加します。外部ソースへの接続について詳しくは、「外部データベースとカタログへの接続」を参照してください。
OpenSharingを使用すると、Databricksにデータをコピーしたり、複雑なネットワーク設定を行ったり、資格情報を転送したりすることなく、元の場所から外部データを安全に共有できるようになります。
共有に外部スキーマまたはテーブルを追加する前に、要件を満たしていることを確認してください。
追加要件
-
アカウントレベルのプレビューで**レイクハウスフェデレーション共有**を有効にする必要があります。「Databricks プレビューの管理」を参照してください。
-
フォーリンスキーマまたはフォーリンテーブル共有が設定されているアカウントでは、 Serverless compute for ワークフロー、ノートブック、およびLakeFlow Pipelines を有効にする必要があります。「Serverless コンピュートへの接続」を参照してください。
-
外部のスキーマとテーブルを共有する場合、データはプロバイダー側でクエリされ、一時的にマテリアライズされます。デフォルトでは、マテリアライズされたデータは、Databricks の デフォルト ストレージ を使用して隠されたスキーマに格納されます。デフォルト ストレージの要件を満たしていることを確認し、制限を遵守してください。
デフォルトストレージの地域別の可用性の詳細については、 「サーバレスの可用性」を参照してください。
Databricks デフォルトストレージの使用をオプトアウトし、一時的なマテリアライズに独自のストレージを使用するには、サポートケースをオープンしてください。
具体化するには大きすぎるフォーリンテーブルは共有できません。具体化が制限を超えると、クエリは失敗します。
- デフォルトストレージの使用を選択した場合は、アカウント レベルで**「OpenSharing for デフォルトストレージ – 拡張アクセス」**プレビューを有効にする必要があります。「Databricks プレビューの管理」を参照してください。
制限事項
- 共有されたフォーリンテーブルは、
LIMIT句または述語プッシュダウンをサポートしていません。システムは、クエリフィルターに関係なく、すべてのクエリ結果を受信者に返す前に完全に具体化します。
推奨される使用パターン
クエリ結果は各クエリに対してオンデマンドで生成されるため、フォーリンテーブルとスキーマの共有は、テーブルまたはマテリアライズドビューの共有と比較して、費用対効果が高くない可能性があります。Databricksでは、パフォーマンスを向上させるために次のことを推奨しています。
- 一般的なクエリ結果のサイズは10 GB未満に抑えてください。
- 頻繁なデータダンプの代わりに、アドホックな探索的クエリを使用します。
- クラウドトークン共有を使用する場合、コスト効率とパフォーマンス向上のため、フォーリンテーブル上に作成されたマテリアライズドビューを共有することを検討してください。
外部スキーマまたはテーブルを受信者と共有する
共有に外部スキーマまたはテーブルを追加するには、カタログエクスプローラ、Databricks Unity Catalog CLI、または Databricks ノートブックまたは Databricks SQL クエリエディターの SQL コマンドを使用します。
- Catalog Explorer
- SQL
- CLI
-
Databricks ワークスペースで、
カタログ をクリックします。 -
カタログ ウィンドウの上部にある
歯車アイコンをクリックし、 OpenSharing を選択します。または、右上隅の Share > OpenSharing をクリックします。
-
自分が共有 タブで、フォーリンテーブルまたはスキーマを追加する共有を見つけて、その名前をクリックします。
-
**アセットの管理 > アセットの編集**をクリックします。
-
アセットを編集 ページで、共有するフォーリンテーブルまたはスキーマを検索または参照して選択します。
-
(オプション) **エイリアス**列で、
をクリックしてエイリアス、つまり代替の外部スキーマ名またはテーブル名を指定し、外部スキーマ名またはテーブル名をより読みやすくします。エイリアスは、受信者が確認し、クエリで使用する必要がある名前です。エイリアスが指定されている場合、受信者は実際の外部スキーマ名またはテーブル名を使用できません。 -
保存 をクリックします。
ALTER SHARE <share-name>
ADD {TABLE | SCHEMA} {federated_catalog.federated_schema.federated_table | federated_catalog.federated_schema}
[COMMENT "<comment>"]
[AS <alias>];
次のオプションがあります。
AS <alias>:データアセット名をより読みやすくするための、代替名またはエイリアス。エイリアスは、受信者が参照し、クエリで使用する必要があるデータアセット名です。エイリアスが指定されている場合、受信者は実際の名前を使用できません。形式<catalog-name>.<schema-name>.<view-name>を使用します。COMMENT "<comment>": コメントは、カタログエクスプローラー UI および SQL ステートメントを使用してデータ資産の詳細を一覧表示および表示する際に表示されます。
ALTER SHAREオプションの詳細については、「ALTER SHARE」を参照してください。
databricks shares update <share-name> \
--json '{
“updates”: [
{
“action”: “ADD”,
“data_object”: {
“name”: “<federated-data-asset-full-name>",
“data_object_type”: “{TABLE | SCHEMA}”,
"shared_as": "<foreign-data-asset-alias>",
“comment”: “<comment>”
}
}
]
}'
フォーリンIcebergテーブルを共有に追加する
プレビュー
この機能は パブリック プレビュー段階です。
フォーリン Iceberg テーブルは、レイクハウスフェデレーション を使用してフォーリン Iceberg カタログからフェデレーションされたテーブルです。Databricks の Apache Iceberg テーブルの詳細については、Databricks の Apache Iceberg とは何ですか? を参照してください。
始める前に、一般的な要件と共有を作成するを満たしていることを確認してください。外部 Iceberg クライアントを使用して、受信者に外部の Iceberg テーブルを共有することもできます。詳細については、外部 Iceberg クライアントへの共有を有効にするを参照してください。
受信者が最新のデータを受け取ることを確認するには、定期的にフォーリンIcebergテーブルを更新してください。任意のSELECTクエリまたはREFRESH TABLEコマンドは、テーブルのメタデータを更新します。
Databricks では、Databricks 上のフォーリン Iceberg テーブルをリモートの Iceberg ソースと同期した状態に保つために、スケジュールされたジョブを設定することをおすすめします。更新のスケジュール設定の詳細については、クエリのスケジュール設定を参照してください。
追加要件
- 「 レイクハウスフェデレーション共有 」プレビューをアカウント レベルで有効にする必要があります。「Databricks プレビューの管理」を参照してください。
- Icebergクライアントを使用していないオープンな受信者と外部のIcebergテーブルを共有する場合は、デフォルトストレージを使用する必要があります。アカウント レベルで OpenSharing for デフォルトストレージ – 拡張アクセスの プレビューを有効にする必要があります。Databricksのプレビューを管理するを参照してください。
- Icebergクライアントを使用していないオープンな受信者と共有する場合、共有データは、お客様のコンピュートおよびストレージを使用して、最初にフィルター処理され、マテリアライズされます。追加費用が発生する可能性があります。詳細については、「オープン共有のコストを発生させ、確認する方法」をご覧ください。および受信者は共有ビュー、マテリアライズドビュー、ストリーミングテーブルの基になるデータに直接アクセスできますか?。
- 外部Icebergテーブルでは、Delta UniFormが有効になっている必要があります。UniForm が有効になっていない場合、テーブルを共有に追加することはできません。UniFormを使用してIcebergクライアントでDelta Lakeテーブルを読み取るを参照してください。
制限事項
- パーティションはサポートされていません。
- Icebergクライアントを使用していないオープンな受信者と共有する場合、
LIMIT句および述語プッシュダウンはサポートされていません。システムは、クエリーフィルターに関わらず、すべてのクエリー結果を受信者に返す前に完全にマテリアライズ化します。
共有にフォーリン Iceberg テーブルを追加する
フォーリンIcebergテーブルは、完全な履歴と共に自動的に共有されます。
共有にフォーリン Iceberg テーブルを追加するには:
- Catalog Explorer
- SQL
- CLI
-
Databricks ワークスペースで、
カタログ をクリックします。 -
カタログ ウィンドウの上部にある
歯車アイコンをクリックし、 OpenSharing を選択します。または、右上隅の Share > OpenSharing をクリックします。
-
「 自分が共有 」タブで、外部 Iceberg テーブルを追加する共有を見つけて、その名前をクリックします。
-
[ アセットの管理 ] > [ アセットの編集 ] をクリックします。
-
[アセットの編集] ページで、共有するフォーリンIceberg テーブルを検索または参照し、それを選択します。
-
(オプション) エイリアス 列で、
をクリックしてエイリアスを指定します。エイリアスは、受信者が見る名前であり、クエリで使用する必要がある名前です。 -
保存 をクリックします。
ノートブックまたはDatabricks SQLクエリーエディターで次のコマンドを実行します。必要に応じて、<shared_table_name> を指定して、フォーリン Iceberg テーブルを別の名前で公開します。
ALTER SHARE <share_name> ADD TABLE <foreign_iceberg_table_name> [COMMENT <comment>] [AS <shared_table_name>];
以下のDatabricks CLIコマンドを実行してください。
databricks shares update <share-name> \
--json '{
"updates": [
{
"action": "ADD",
"data_object": {
"name": "<foreign-iceberg-table-full-name>",
"data_object_type": "TABLE",
"comment": "<comment>"
}
}
]
}'
共有にビューを追加する
ビューは、1 つ以上のテーブルまたは他のビューから作成される読み取り専用オブジェクトです。 ビューは、Unity Catalog メタストア内の複数のスキーマとカタログに含まれるテーブルやその他のビューから作成できます。 ビューの作成と管理を参照してください。
ビューを共有する場合、データはクエリされ、一時的にマテリアライズされます。マテリアライズされたデータは、ビューの親スキーマまたはカタログのストレージロケーション、またはメタストアのルートロケーションに格納されます。
ビューを共有に追加する前に、要件を満たしていることを確認してください。
追加要件
-
ビュー共有が設定されているアカウントで、 ワークフロー、ノートブック、およびLakeflow PipelinesのServerless コンピュート を有効にする必要があります。Serverless コンピュートへの接続を参照してください。
-
共有可能なビューは、Delta テーブル、その他の共有可能なビュー、またはローカルのマテリアライズドビューとストリーミングテーブルで定義する必要があります。共有可能なビューは、フォーリンテーブルで定義できません。
-
ビューを共有に追加するときは、Databricks Runtime 13.3 LTS 以上のコンピュートまたはSQLウェアハウスを使用する必要があります。
-
ワークスペースでワークスペースとカタログのバインドが有効になっている場合は、ワークスペースにカタログへの読み取りおよび書き込みアクセス権があることを確認してください。詳細については、ワークスペースとカタログのバインドを参照してください。
-
ビューを共有する場合、受信者のコンピュートタイプとアカウントの関係によっては、データがプロバイダー側でクエリされ、一時的にマテリアライズされる可能性があります。マテリアライズドデータは、ビューの親スキーマまたはカタログのストレージロケーション、あるいはメタストアのルートロケーションに格納されます。マテリアライゼーションが行われるタイミングと費用負担の詳細については、受信者は、共有ビュー、マテリアライズドビュー、およびストリーミングテーブル内の基になるデータに直接アクセスできますか? を参照してください。および OpenSharing のコストはどのように発生し、確認できますか?
-
ストレージロケーションにファイアウォールやプライベートリンクなどのカスタムネットワーク設定がある場合、受信者がそのストレージロケーションに接続できるよう、許可リストに登録されていることを確認する必要があります。サーバレス コンピュートのファイアウォール規則の構成については、ファイアウォールを使用したワークスペースのネットワーク送信の制限 を参照してください。
制限事項
- 共有テーブルまたは共有ビューを参照するビューを共有することはできません。
- フォーリンテーブルを参照するビューは、フォーリン Iceberg テーブルを含め、共有することはできません。
- 受信者が基盤となるデータに直接アクセスできない場合、
LIMIT句と述語プッシュダウンはサポートされません。システムは、クエリフィルターに関係なく、すべてのクエリ結果を受信者に返す前に完全に具体化します。共有ビュー、マテリアライズドビュー、およびストリーミングテーブルの基になるデータに受信者は直接アクセスできますか?をご覧ください。
受信者とビューを共有する
このセクションでは、Catalog Explorer、Databricks CLI、またはDatabricksノートブックやDatabricks SQLクエリ エディターのSQLコマンドを使用して、共有にビューを追加する方法について説明します。Unity Catalog REST API を使用する場合は、REST API リファレンスの PATCH /api/2.1/unity-catalog/shares/ を参照してください。
- Catalog Explorer
- SQL
- CLI
-
Databricks ワークスペースで、
カタログ をクリックします。 -
カタログ ウィンドウの上部にある
歯車アイコンをクリックし、 OpenSharing を選択します。または、右上隅の Share > OpenSharing をクリックします。
-
自分が共有 タブで、ビューを追加する共有を見つけて、その名前をクリックします。
-
アセットの管理 > データ アセットの追加 をクリックします。
-
[ テーブルの追加 ] ページで、共有したいビューを検索または参照し、選択します。
-
(オプション)
エイリアス 列の下にある をクリックして、代替ビュー名、または エイリアス を指定し、ビュー名を読みやすくします。エイリアスは受信者が見る名前であり、クエリで使用する必要があります。エイリアスが指定されている場合、受信者は実際のビュー名を使用できません。 -
保存 をクリックします。
ノートブックまたは Databricks SQL クエリー エディターで次のコマンドを実行します。
ALTER SHARE <share-name> ADD VIEW <catalog-name>.<schema-name>.<view-name>
[COMMENT "<comment>"]
[AS <alias>];
次のオプションがあります。
AS <alias>: ビュー名をより読みやすくするための、代替ビュー名またはエイリアス。エイリアスとは、受信者が参照し、クエリで使用する必要があるビュー名です。エイリアスが指定されている場合、受信者は実際のビュー名を使用できません。形式<schema-name>.<view-name>を使用します。COMMENT "<comment>": コメントは、カタログエクスプローラーの UI と、SQL ステートメントを使用してビューの詳細をリストおよび表示するときに表示されます。
ALTER SHAREオプションの詳細については、「ALTER SHARE」を参照してください。
以下の Databricks CLI コマンドを実行します。
databricks shares update <share-name> \
--json '{
"updates": [
{
"action": "ADD",
"data_object": {
"name": "<view-full-name>",
"data_object_type": "VIEW",
"shared_as": "<view-alias>"
}
}
]
}'
"shared_as": "<view-alias>" オプションで、ビュー名をより読みやすくするための代替のビュー名、つまりエイリアスを提供します。エイリアスは、受信者が確認し、クエリで使用する必要があるビュー名です。エイリアスが指定されている場合、受信者は実際のビュー名を使用できません。形式 <schema-name>.<view-name> を使用します。
追加のパラメーターについては、databricks shares update --help を実行するか、REST API リファレンスのPATCH /api/2.1/unity-catalog/shares/ を参照してください。
共有からビューを削除する方法については、共有の更新を参照してください。
共有に動的ビューを追加して行と列をフィルター処理する
ダイナミックビューを使用して、テーブルデータへのきめ細やかなアクセス制御を構成できます。以下を含む:
- 列または行レベルのセキュリティ
- データマスキング.
CURRENT_RECIPIENT()関数を使用する動的ビューを作成すると、受信者定義で指定したプロパティに基づいて受信者アクセスを制限できます。
このセクションでは、動的ビューを使用して、行レベルと列レベルの両方で、受信者によるテーブルデータへのアクセスを制限する例を示します。
要件
- 共有にビューを追加するための要件を満たしているか確認してください。
- Databricks Runtime バージョン :
CURRENT_RECIPIENT関数は Databricks Runtime 14.2 以降でサポートされています。
制限事項:
- ビュー共有のすべての制限が適用されます。
- プロバイダーが
CURRENT_RECIPIENT関数を使用するビューを共有している場合、共有コンテキストのために、プロバイダーはそのビューを直接クエリすることはできません。このような動的ビューをテストするには、プロバイダーは自分自身とビューを共有し、受信者としてそのビューをクエリする必要があります。 - プロバイダーは、動的ビューを参照するビューを作成できません。
受信者のプロパティを設定する
これらの例では、共有するテーブルには country という名前の列があり、一致する country プロパティを持つ受信者のみが特定の行または列を表示できます。
カタログエクスプローラー、またはDatabricksノートブックまたはSQLクエリエディターのSQLコマンドを使用して、受信者のプロパティを設定できます。
- Catalog Explorer
- SQL
-
Databricks ワークスペースで、
カタログ をクリックします。 -
カタログ ウィンドウの上部にある
歯車アイコンをクリックし、 OpenSharing を選択します。または、右上隅の Share > OpenSharing をクリックします。
-
[受信者] タブで、プロパティを追加する受信者を見つけて、その名前をクリックします。
-
ページ右下、**受信者のプロパティ**の下で、Databricks 受信者の場合は
 **databricks.metastoreID** の横にある、またはオープン受信者の場合は **databricks.name** の横にある 鉛筆アイコンをクリックします。
**databricks.metastoreID** の横にある、またはオープン受信者の場合は **databricks.name** の横にある 鉛筆アイコンをクリックします。 -
[受信者プロパティの編集] ダイアログで、列名をキーとして
country(この場合)、フィルタリングする値を値としてCA(例:) 指定します。 -
保存 をクリックします。
受信者にプロパティを設定するには、ALTER RECIPIENTを使用します。この例では、countryプロパティはCAに設定されています。
ALTER RECIPIENT recipient1 SET PROPERTIES ('country' = 'CA');
受信者向けの行レベルのアクセス許可を持つ動的ビューを作成
この例では、一致するcountryプロパティを持つ受信者のみが特定の行を表示できます。
CREATE VIEW my_catalog.default.view1 AS
SELECT * FROM my_catalog.default.my_table
WHERE country = CURRENT_RECIPIENT('country');
もう1つのオプションは、データプロバイダーがファクトテーブルフィールドを受信者プロパティにマッピングする個別のマッピングテーブルを維持することです。これにより、受信者プロパティとファクトテーブルフィールドを分離して、柔軟性を高めることができます。
受信者に対する列レベルのアクセス許可を持つ動的ビューを作成する
この例では、country プロパティに一致する受信者のみが特定の列を表示できます。その他は、返されたデータを REDACTED として表示します。
CREATE VIEW my_catalog.default.view2 AS
SELECT
CASE
WHEN CURRENT_RECIPIENT('country') = 'US' THEN pii
ELSE 'REDACTED'
END AS pii
FROM my_catalog.default.my_table;
動的ビューを受信者と共有する
動的ビューを受信者と共有するには、標準ビューの場合と同じ SQL コマンドまたは UI プロシージャを使用します。 共有にビューを追加するを参照してください。
共有にマテリアライズドビューを追加
ビューと同様に、マテリアライズドビューもクエリの結果であり、テーブルのようにアクセスできます。通常ビューとは異なり、マテリアライズドビューの結果は、マテリアライズドビューが最後に更新された時点のデータの状態を反映します。マテリアライズドビューの詳細については、「スタンドアロンのマテリアライズドビューを使用する」を参照してください。
共有にマテリアライズドビューを追加する前に、要件を満たしていることを確認してください。
追加要件
-
マテリアライズドビュー共有が設定されているアカウントで、 ワークフロー、ノートブック、および Lakeflow pipelines の Serverless コンピュート を有効にする必要があります。See Serverless コンピュートへの接続.
-
ワークスペースでワークスペース-カタログバインディングが有効になっている場合は、そのワークスペースがマテリアライズドビューを含むカタログへの読み取り/書き込みアクセス権を持っていることを確認してください。詳細については、ワークスペースとカタログのバインドを参照してください。
-
共有可能なマテリアライズドビューは、Delta テーブル、またはその他の共有可能なストリーミングテーブル、ビュー、またはマテリアライズドビューで定義する必要があります。
-
マテリアライズドビューを共有に追加するときは、Databricks Runtime 13.3 LTS 以上の SQLウェアハウスまたはコンピュートを使用する必要があります。
制限事項:
- マテリアライズドビューには行フィルターを設定できませんが、マテリアライズドビューのベース テーブルには行フィルターと列マスクを設定できます。
- マテリアライズドビューはパーティションフィルターを持つことはできません。代わりに、マテリアライズドビューの上にビューを作成します。
- Databricks-to-Open Sharing の受信者は、マテリアライズドビューの現在のスナップショットのみを読み取ることができます。ストリーミング読み取りはオープンな受信者向けにはサポートされていません。
- 受信者が基盤となるデータに直接アクセスできない場合、
LIMIT句と述語プッシュダウンはサポートされません。システムは、クエリフィルターに関係なく、すべてのクエリ結果を受信者に返す前に完全に具体化します。共有ビュー、マテリアライズドビュー、およびストリーミングテーブルの基になるデータに受信者は直接アクセスできますか?をご覧ください。 - 一般的な制限はマテリアライズドビューにも適用されます。「マテリアライズドビューの制限事項」を参照してください。
マテリアライズドビューを受信者と共有する
このセクションでは、DatabricksノートブックまたはDatabricks SQLクエリ エディターで、カタログエクスプローラ、Databricks CLI、またはSQLコマンドを使用して、マテリアライズドビューを共有に追加する方法について説明します。REST APIを使用したい場合は、REST APIリファレンスのPATCH /api/2.1/unity-catalog/shares/を参照してください。
- Catalog Explorer
- SQL
- CLI
-
Databricks ワークスペースで、
カタログ をクリックします。 -
カタログ ウィンドウの上部にある
歯車アイコンをクリックし、 OpenSharing を選択します。または、右上隅の Share > OpenSharing をクリックします。
-
「 自分が共有 」タブで、マテリアライズドビューを追加する共有を見つけて、その名前をクリックします。
-
**アセットの管理 > アセットの編集**をクリックします。
-
アセットの編集 ページで、共有したいマテリアライズドビューを検索または参照して選択します。
-
(オプション) エイリアス 列で、
をクリックして、マテリアライズドビュー名をよりわかりやすくするためのエイリアス、つまり代替のマテリアライズドビュー名を指定します。エイリアスは、受信者が見てクエリで使用する必要がある名前です。エイリアスが指定されている場合、受信者は実際のマテリアライズドビュー名を使用できません。 -
保存 をクリックします。
ノートブックまたはDatabricks SQLクエリーエディタで次のコマンドを実行します。
ALTER SHARE <share_name> ADD MATERIALIZED VIEW <mv_name> [COMMENT <comment>] [AS <shared_mv_name>];
databricks shares update <share-name> \
--json '{
“updates”: [
{
“action”: “ADD”,
“data_object”: {
“name”: “<mat-view-full-name>”,
“data_object_type”: “MATERIALIZED_VIEW”,
“comment”: “<comment>”
}
}
]
}'
共有からマテリアライズドビューを削除する方法については、共有の更新を参照してください。
共有にボリュームを追加する
ボリュームは、クラウド オブジェクト ストレージの場所にあるストレージの論理ボリュームを表す Unity Catalog オブジェクトです。 これらは主に、表形式以外のデータ資産に対するガバナンスを提供することを目的としています。 Unity Catalogボリュームとはを参照してください。
共有にボリュームを追加する前に、要件を満たしていることを確認してください。
追加要件
- ボリューム共有は、Databricks-to-Databricks 共有でのみサポートされています。
- ボリュームを共有に追加する際は、バージョン2023.50以降のSQLウェアハウス、またはDatabricks Runtime 14.1以降のコンピュートリソースを使用する必要があります。
- プロバイダー側のボリュームストレージにカスタムネットワーク構成(ファイアウォールやプライベートリンクなど)がある場合、プロバイダーは、受信者のデータプレーンアドレスが、ボリュームのストレージ場所に接続できるように適切に許可リストに登録されていることを確認する必要があります。受信者側で、Catalog Explorerはボリュームを正しく表示しない場合があります。
2024年7月25日以降にDatabricks-to-Databricks共有を使用して受信者と共有された共有には、ボリュームコメントが含まれます。リリース日より前に受信者と共有された共有を通じてコメントの共有を開始したい場合は、コメントの共有をトリガーするために受信者アクセスを取り消して再付与する必要があります。
受信者とボリュームを共有する
このセクションでは、カタログエクスプローラ、Databricks CLI、または Databricks ノートブックまたは SQL クエリ エディターの SQL コマンドを使用して、共有にボリュームを追加する方法について説明します。 Unity Catalog REST APIを使用したい場合は、REST APIリファレンスのPATCH /api/2.1/unity-catalog/shares/ を参照してください。
- Catalog Explorer
- SQL
- CLI
-
Databricks ワークスペースで、
カタログ をクリックします。 -
カタログ ウィンドウの上部にある
歯車アイコンをクリックし、 OpenSharing を選択します。または、右上隅の Share > OpenSharing をクリックします。
-
自分が共有 タブで、ボリュームを追加する共有を見つけて、その名前をクリックします。
-
**アセットの管理 > アセットの編集**をクリックします。
-
**資産の編集**ページで、共有するボリュームを検索または参照して選択します。
あるいは、ボリュームを含むスキーマ全体を選択できます。「共有にスキーマを追加する」を参照してください。
-
(オプション)
**エイリアス**列の下にある をクリックして、代替ボリューム名、つまり**エイリアス**を指定し、ボリューム名を読みやすくします。エイリアスは、スキーマ全体を選択した場合は使用できません。
エイリアスは、受信者が確認する名前であり、クエリで使用する必要があります。エイリアスが指定されている場合、受信者は実際のボリューム名を使用できません。
-
保存 をクリックします。
ノートブックまたは Databricks SQL クエリー エディターで次のコマンドを実行します。
ALTER SHARE <share-name> ADD VOLUME <catalog-name>.<schema-name>.<volume-name>
[COMMENT "<comment>"]
[AS <alias>];
次のオプションがあります。
AS <alias>:ボリューム名を読みやすくするための別のボリューム名、またはエイリアス。エイリアスは、受信者に表示され、クエリで使用する必要があるボリューム名です。エイリアスが指定されている場合、受信者は実際のボリューム名を使用できません。形式<schema-name>.<volume-name>を使用します。COMMENT "<comment>":コメントは、カタログエクスプローラーUIに表示され、SQLステートメントを使用してボリュームの詳細をリストおよび表示するときにも表示されます。
ALTER SHAREオプションの詳細については、「ALTER SHARE」を参照してください。
Databricks CLI 0.210以降を使用して、以下のコマンドを実行します。
databricks shares update <share-name> \
--json '{
"updates": [
{
"action": "ADD",
"data_object": {
"name": "<volume-full-name>",
"data_object_type": "VOLUME",
"string_shared_as": "<volume-alias>"
}
}
]
}'
"string_shared_as": "<volume-alias>" はオプションであり、ボリューム名をより読みやすくするために、代替のボリューム名(エイリアス)を提供します。エイリアスは、受信者に表示され、クエリで使用する必要があるボリューム名です。エイリアスが指定されている場合、受信者は実際のボリューム名を使用できません。形式 <schema-name>.<volume-name> を使用します。
追加のパラメーターについては、databricks shares update --help を実行するか、REST API リファレンスのPATCH /api/2.1/unity-catalog/shares/ を参照してください。
共有からのボリュームの削除に関する情報については、共有の更新を参照してください。
共有に Python UDF を追加する
ユーザー定義関数 (UDF) を使用すると、Databricks の組み込み機能を拡張するコードを再利用および共有できます。Python UDF を作成する方法については、ユーザー定義スカラー関数 - Python を参照してください。
Python UDF を共有に追加する前に、要件を満たしていることを確認してください。
追加の制限
- オープンな受信者とPython UDFを共有することはできません。
Python UDF を受信者と共有する
このセクションでは、カタログエクスプローラー、Databricks CLI、またはDatabricksノートブックまたはSQLクエリエディターのSQLコマンドを使用して、Python UDFを共有に追加する方法について説明します。Unity Catalog REST APIを使用したい場合は、REST APIリファレンスのPATCH /api/2.1/unity-catalog/shares/を参照してください。
- Catalog Explorer
- SQL
- CLI
-
Databricks ワークスペースで、
カタログ をクリックします。 -
カタログ ウィンドウの上部にある
歯車アイコンをクリックし、 OpenSharing を選択します。または、右上隅の Share > OpenSharing をクリックします。
-
**自分が共有** タブで、Python UDFを追加する共有を見つけて、その名前をクリックします。
-
**アセットの管理 > アセットの編集**をクリックします。
-
「**アセットの編集**」ページで、共有するPython UDFを検索または参照して選択します。
または、Python UDF を含むスキーマ全体を選択できます。「共有にスキーマを追加する」を参照してください。
-
(オプション)
エイリアス 列の下にある をクリックして、Python UDF 名を読みやすくするための別の Python UDF 名、または エイリアス を指定します。エイリアスは、スキーマ全体を選択した場合は使用できません。
エイリアスは、受信者が確認する名前であり、クエリで使用する必要があります。エイリアスが指定されている場合、受信者は実際のPython UDF名を使用できません。
-
保存 をクリックします。
ノートブックまたはDatabricks SQLクエリ エディターで、ADD MODELを使用する次のコマンドを実行します。
ALTER SHARE <share-name> ADD MODEL <catalog-name>.<schema-name>.<python-udf-name>
[AS <alias>];
次のオプションがあります。
AS <alias>:Python UDF名をより読みやすくするための、別のPython UDF名、またはエイリアス。エイリアスは、受信者が認識し、クエリで使用する必要があるPython UDF名です。エイリアスが指定されている場合、受信者は実際のPython UDF名を使用できません。<schema-name>.<python-udf-name>の形式を使用します。
ALTER SHAREオプションの詳細については、「ALTER SHARE」を参照してください。
オブジェクトタイプをモデルとして指定する以下のコマンドを、Databricks CLI 0.210 以降を使用して実行します。
databricks shares update <share-name> \
--json '{
"updates": [
{
"action": "ADD",
"data_object": {
"name": "<python-udf-full-name>",
"data_object_type": "MODEL",
"string_shared_as": "<python-udf-alias>"
}
}
]
}'
"string_shared_as": "<python-udf-alias>" はオプションであり、Python UDF名をより読みやすくするために、代替のPython UDF名、つまりエイリアスを提供します。エイリアスは、受信者が認識し、クエリで使用する必要があるPython UDF名です。エイリアスが指定されている場合、受信者は実際のPython UDF名を使用できません。<schema-name>.<python-udf-name>の形式を使用します。
追加のパラメーターについては、databricks shares update --help を実行するか、REST API リファレンスのPATCH /api/2.1/unity-catalog/shares/ を参照してください。
共有にモデルを追加する
モデルを共有に追加する前に、要件を満たしていることを確認してください。
モデルコメントとモデルバージョンコメントは、Databricks-to-Databricks 共有を使用して共有される共有に含まれます。
追加要件
- モデル共有は、Databricks-to-Databricks 共有でのみサポートされています。
- モデルを共有に追加するときは、バージョン 2023.50 以降の SQLウェアハウス、または Databricks Runtime 14.0 以降のコンピュートリソースを使用する必要があります。
受信者とモデルを共有します
このセクションでは、カタログ エクスプローラー、Databricks CLI、または Databricks ノートブックまたは SQL クエリ エディターの SQL コマンドを使用して、共有にモデルを追加する方法について説明します。 Unity Catalog REST APIを使用したい場合は、REST APIリファレンスのPATCH /api/2.1/unity-catalog/shares/ を参照してください。
共有にモデルを追加するには:
- Catalog Explorer
- SQL
- CLI
-
Databricks ワークスペースで、
カタログ をクリックします。 -
カタログ ウィンドウの上部にある
歯車アイコンをクリックし、 OpenSharing を選択します。または、右上隅の Share > OpenSharing をクリックします。
-
自分が共有 タブで、モデルを追加する共有を見つけて、その名前をクリックします。
-
**アセットの管理 > アセットの編集**をクリックします。
-
[アセットの編集] ページで、共有したいモデルを検索または参照して選択します。
または、モデルを含むスキーマ全体を選択できます。「共有にスキーマを追加する」を参照してください。
-
(オプション)
エイリアス 列の下のをクリックして、代替のモデル名(**エイリアス**)を指定し、モデル名をより読みやすくします。エイリアスは、スキーマ全体を選択した場合は使用できません。
エイリアスは、受信者が確認する名前であり、クエリで使用する必要があります。エイリアスが指定されている場合、受信者は実際のモデル名を使用できません。
-
保存 をクリックします。
ノートブックまたは Databricks SQL クエリー エディターで次のコマンドを実行します。
ALTER SHARE <share-name> ADD MODEL <catalog-name>.<schema-name>.<model-name>
[COMMENT "<comment>"]
[AS <alias>];
次のオプションがあります。
AS <alias>:モデル名を読みやすくするための別のモデル名、またはエイリアス。エイリアスは、受信者に表示され、クエリで使用する必要があるモデル名です。エイリアスが指定されている場合、受信者は実際のモデル名を使用できません。<schema-name>.<model-name>の形式を使用してください。COMMENT "<comment>": コメントは、カタログエクスプローラーの UI と、SQL ステートメントを使用してモデルの詳細をリストおよび表示するときに表示されます。
ALTER SHAREオプションの詳細については、「ALTER SHARE」を参照してください。
Databricks CLI 0.210以降を使用して、以下のコマンドを実行します。
databricks shares update <share-name> \
--json '{
"updates": [
{
"action": "ADD",
"data_object": {
"name": "<model-full-name>",
"data_object_type": "MODEL",
"string_shared_as": "<model-alias>"
}
}
]
}'
"string_shared_as": "<model-alias>" オプションであり、モデル名を読みやすくするために、代替モデル名 (エイリアス) を提供します。エイリアスは、受信者に表示され、クエリで使用する必要があるモデル名です。エイリアスが指定されている場合、受信者は実際のモデル名を使用できません。<schema-name>.<model-name>の形式を使用します。
追加のパラメーターについては、databricks shares update --help を実行するか、REST API リファレンスのPATCH /api/2.1/unity-catalog/shares/ を参照してください。
共有からモデルを削除する方法については、共有の更新を参照してください。
ノートブック ファイルを共有に追加します
ノートブック ファイルを共有に追加する前に、要件を満たしていることを確認してください。
カタログエクスプローラ を使用して、ノートブック ファイルを共有に追加します。
-
Databricks ワークスペースで、
カタログ をクリックします。 -
「OpenSharing >」ボタンをクリックしてください。
-
**自分が共有**タブで、ノートブックを追加したい共有を見つけて、その名前をクリックします。
-
「アセットの管理」をクリックし、「ノートブックファイルを追加」を選択します。
-
ノートブックファイルを追加 ページで、ファイルアイコンをクリックして、共有するノートブックを参照します。
- 共有するファイルをクリックし、 選択 をクリックします。
- (オプション) **Share as** フィールドで、ファイルにユーザーフレンドリーなエイリアスを指定します。これは受信者に表示される識別子です。
- **[ストレージの場所]** の下の、ノートブックを格納するクラウドストレージの外部ロケーション を入力します。定義済みの外部ロケーションの下にサブパスを指定できます。外部ロケーションを指定しない場合、ノートブックはメタストアレベルのストレージロケーション(または「メタストアのルートロケーション」)に保存されます。メタストアにルートロケーションが定義されていない場合は、ここに外部ロケーションを入力する必要があります。「既存のメタストアにマネージドストレージを追加する」を参照してください。
-
保存 をクリックします。
共有ノートブックファイルが、「 ノートブックファイル 」リストの「 アセット 」タブに表示されます。
共有からノートブックファイルを削除
共有からノートブックファイルを削除するには:
-
Databricks ワークスペースで、
カタログ をクリックします。 -
カタログ ウィンドウの上部にある
歯車アイコンをクリックし、 OpenSharing を選択します。または、右上隅の Share > OpenSharing をクリックします。
-
**自分が共有**タブで、ノートブックを含む共有を見つけて、共有名をクリックします。
-
[ アセット ] タブで、共有から削除したいノートブック ファイルを見つけます。
-
行の右側にある
 ケバブメニューをクリックし、 「ノートブック ファイルの削除」 を選択します。
ケバブメニューをクリックし、 「ノートブック ファイルの削除」 を選択します。 -
確認ダイアログで、 [削除] をクリックします。
共有内のノートブック ファイルを更新する
既に共有しているノートブックを更新するには、**共有名**フィールドに新しいエイリアスを指定して再度追加する必要があります。Databricksでは、ノートブックの改訂済みステータスを示す<old-name>-update-1のような名前を使用することをお勧めします。受信者に変更について通知する必要がある場合があります。受信者は、更新を活用するために新しいノートブックを選択してクローンを作成する必要があります。
外部 Iceberg クライアントへの共有を有効にする
Apache Iceberg REST Catalog APIを使用する外部のIcebergクライアントと、Delta テーブル、外部 Iceberg テーブル、ビュー、マテリアライズドビュー、およびストリーミングテーブルを共有できます。
共有する前に、データアセットを共有に追加するために必要なOpenSharing要件を満たしていることを確認してください。
この機能は、マネージド Iceberg テーブルの共有とは異なります。
追加の制限
- 削除ベクトルが有効になっているテーブルはサポートされていません。
- マネージド Iceberg テーブルはサポートされていません。
- デフォルトストレージを使用するアセットは、外部のIcebergクライアントと共有できません。Databricks のデフォルト ストレージを参照してください。
外部の Iceberg クライアントと共有
外部のIcebergクライアントとデータ資産を共有するには:
-
Delta テーブルを共有している場合は、
IcebergCompatV3を使用して各 Delta テーブルを構成し、Iceberg 互換テーブルとして公開してください。これにより、標準的な Delta オペレーションと並行して Iceberg メタデータの非同期生成が可能になります。Iceberg クライアントと Delta テーブルを共有するための要件を満たしていることを確認し、制限を遵守してください。Iceberg 読み取りを有効にする方法については、Iceberg 読み取り (UniForm) を有効にするを参照してください。Snowflakeに共有する場合、ユニフォーム対応のテーブルのみが受信者に表示されます。他のテーブルはフィルタリングされています。
- 「
DESCRIBE HISTORY」を使用して、Iceberg クライアントからテーブルをクエリできるようになる前に Iceberg メタデータ生成が完了したことを確認します。 - OIDC認証タイプはサポートされていません。
-
データアセットを共有に追加します。詳細な手順については、以下を参照してください:
プロバイダー側でのデータ具体化は、ビュー、マテリアライズドビュー、またはストリーミングテーブルを共有する場合にトリガーされ、コンピュートコストの蓄積につながる可能性があります。詳細については、「オープン共有費用を発生させ、確認する方法」を参照してください。
- オープン共有の受信者と共有してください。受信者を作成し、共有へのアクセスを付与する方法については、ベアラー トークンを使用して非Databricksユーザーの受信者オブジェクトを作成する (Databricks-to-Open 共有)またはOpenSharing 受信者向けに Open ID Connect (OIDC) フェデレーションを有効にするを参照してください。