GDPR向けにデータを準備する
EU 一般データ保護規則(GDPR)およびカリフォルニア州消費者プライバシー法(CCPA)は、プライバシーおよびデータセキュリティに関する規制であり、企業は、顧客について収集されたすべての個人を特定できる情報(PII)を明示的な要求に応じて永久的かつ完全に削除することを義務付けています。 「忘れられる権利」(RTBF)または「データ消去の権利」とも呼ばれ、削除リクエストは指定された期間(たとえば、1暦月以内)に実行する必要があります。
この記事では、Databricks に格納されているデータに RTBF を実装する方法について説明します。この記事に含まれる例では、電子商取引会社のデータセットをモデル化し、ソース テーブルのデータを削除し、これらの変更をダウンストリーム テーブルに反映する方法を示します。
「忘れられる権利」を実現するための青写真
次の図は、「忘れられる権利」を実装する方法を示しています。
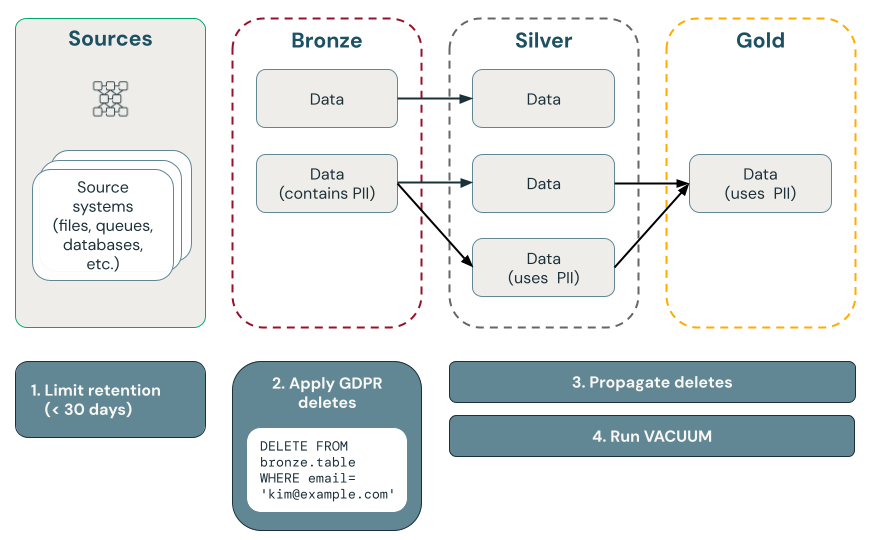
Delta Lake でのポイント削除
Delta Lake ACIDトランザクションを使用して大規模なデータレイクでのポイント削除を高速化し、コンシューマー データ GDPR や CCPA の要求に応じて個人を特定できる情報 (PII) を見つけて削除できるようにします。
Delta Lake はテーブル履歴を保持し、ポイントインタイムクエリとロールバックに使用できるようにします。vacuum機能は、 Deltaテーブルによって参照されなくなり、指定された保持しきい値よりも古いデータ ファイルを削除し、データを完全に削除します。 デフォルトと推奨事項の詳細については、 「テーブル履歴の操作」を参照してください。
削除ベクトルを使用するときにデータが削除されていることを確認する
削除ベクトルが有効になっているテーブルの場合、レコードを削除した後、基になるレコードを完全に削除するには、 REORG TABLE ... APPLY (PURGE) も実行する必要があります。これには、 Delta Lake テーブル、マテリアライズドビュー、およびストリーミングテーブルが含まれます。 Parquet データファイルへの変更の適用を参照してください。
アップストリームソースのデータの削除
GDPR と CCPA は、Kafka やファイル、データベースなど、Delta Lake 以外のソースのデータを含む、すべてのデータに適用されます。Databricks でデータを削除するだけでなく、キューやクラウド ストレージなどのアップストリーム ソースのデータも削除する必要があります。
データ削除ワークフローを実装する前に、コンプライアンスまたはバックアップの目的でワークスペース データをエクスポートする必要がある場合があります。「ワークスペース データのエクスポート」を参照してください。
難読化よりも完全な削除が望ましい
データを削除するか、難読化するかを選択する必要があります。難読化は、仮名化、データマスキングなどを使用して実装できます。ただし、実際には、再識別のリスクを排除するにはPIIデータを完全に削除する必要があるため、最も安全なオプションは完全な消去です。
ブロンズレイヤーのデータを削除し、削除をシルバーレイヤーとゴールドレイヤーに反映します
削除リクエストのテーブルをクエリするスケジュールされたジョブによって、最初にブロンズ レイヤー内のデータを削除して、 GDPRおよび CCPA コンプライアンスを開始することをお勧めします。 ブロンズレイヤーからデータを削除した後、変更をシルバーレイヤーとゴールドレイヤーに反映できます。
テーブルを定期的に管理して、履歴ファイルからデータを削除する
デフォルトでは、Delta Lake は削除されたレコードを含むテーブル履歴を 30 日間保持し、タイムトラベルやロールバックに使用できるようにします。ただし、以前のバージョンのデータが削除されたとしても、データはクラウド ストレージに保持されたままになります。したがって、データセットを定期的にメンテナンスして、以前のバージョンのデータを削除する必要があります。推奨される方法は、ストリーミング テーブルとマテリアライズドビューの両方をインテリジェントに維持するUnity Catalogマネージドテーブルの予測的最適化です。
- 予測的最適化によって管理されるテーブルの場合、 Lakeflow Spark宣言型パイプラインは、使用パターンに基づいてストリーミング テーブルとマテリアライズドビューの両方をインテリジェントに維持します。
- 予測的最適化が有効になっていないテーブルの場合、 Lakeflow Spark宣言型パイプラインは、ストリーミング テーブルとマテリアライズドビューが更新されてから 24 時間以内にメンテナンス タスクを自動的に実行します。
予測的最適化またはLakeflow Spark宣言型パイプラインを使用していない場合は、 DeltaテーブルでVACUUMコマンドを実行して、以前のバージョンのデータを完全に削除する必要があります。 デフォルトでは、タイムトラベル機能は 7 日間に短縮されます (これは構成可能な設定です)。また、問題となるデータの履歴バージョンもクラウド ストレージから削除されます。
ブロンズレイヤーからPIIデータを削除する
レイクハウスの設計によっては、PII ユーザー データと非 PII ユーザー データの間のリンクを切断できる場合があります。たとえば、Eメールのような自然キーの代わりに user_id などの非自然キーを使用している場合は、PIIデータを削除して、非PIIデータをそのままにすることができます。
この記事の残りの部分では、すべてのブロンズ テーブルからユーザー レコードを完全に削除することで RTBF を処理します。データを削除するには、次のコードに示すように、 DELETE コマンドを実行します。
spark.sql("DELETE FROM bronze.users WHERE user_id = 5")
一度に多数のレコードをまとめて削除する場合は、 MERGE コマンドを使用することをお勧めします。次のコードでは、user_id 列を含む gdpr_control_table という制御テーブルがあることを前提としています。このテーブルに「忘れられる権利」を要求したすべてのユーザーのレコードをこのテーブルに挿入します。
MERGE コマンドは、行を一致させるための条件を指定します。この例では、user_idに基づいて、target_table のレコードと gdpr_control_table のレコードを照合します。一致するものがある場合 (たとえば、target_tableとgdpr_control_tableの両方でuser_idがある場合)、target_tableの行は削除されます。この MERGE コマンドが成功したら、制御テーブルを更新して、要求が処理されたことを確認します。
spark.sql("""
MERGE INTO target
USING (
SELECT user_id
FROM gdpr_control_table
) AS source
ON target.user_id = source.user_id
WHEN MATCHED THEN DELETE
""")
ブロンズからシルバー、ゴールドレイヤーへの変更の伝播
ブロンズレイヤーでデータを削除した後、シルバーレイヤーとゴールドレイヤーのテーブルに変更を反映させる必要があります。
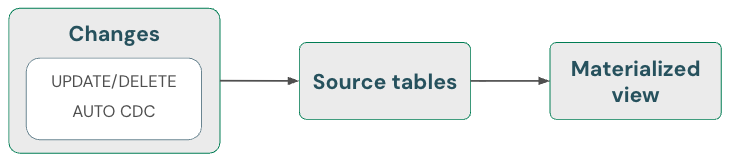
マテリアライズドビュー:削除を自動的に処理
マテリアライズドビューは、ソースの削除を自動的に処理します。したがって、ソースから削除されたデータがマテリアライズドビューに含まれないようにするために、特別な操作を行う必要はありません。マテリアライズドビューと実行メンテナンスを更新して、削除が完全に処理されるようにする必要があります。
マテリアライズドビューは、完全な再計算よりもコストがかからない場合はインクリメンタル計算を使用しますが、正確性を犠牲にすることはありませんので、常に正しい結果を返します。つまり、ソースからデータを削除すると、マテリアライズドビューが完全に再計算される可能性があります。
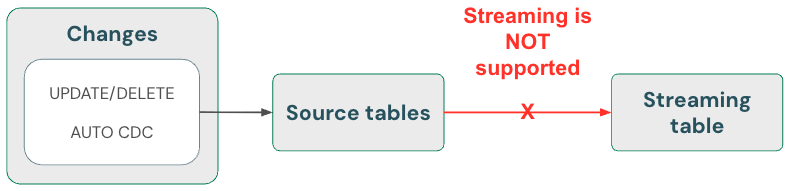
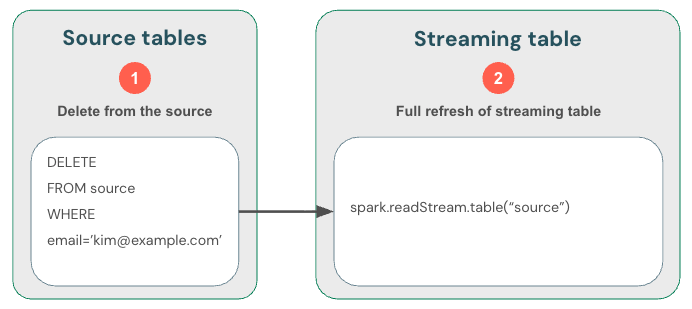
ストリーミングテーブル: skipChangeCommits を使用してデータを削除し、ストリーミング ソースを読み取ります
ストリーミング テーブルは、 Deltaテーブル ソースからストリームするときに追加専用データを処理します。 ストリーミング ソースからのレコードの更新や削除など、その他の操作はサポートされておらず、ストリームが中断されます。
より堅牢なストリーミング実装を実現するには、代わりにDeltaテーブルの変更フィードからストリーミングし、処理コードで更新と削除を処理します。 「ソースDeltaテーブルへの変更の処理」を参照してください。
Delta テーブルからのストリーミングでは新しいデータのみが処理されるため、データの変更は自分で処理する必要があります。推奨される方法は次のとおりです: (1) DML を使用してDeltaテーブルのデータを削除し、(2) DML を使用してストリーミング テーブルからデータを削除し、(3) skipChangeCommitsを使用するようにストリーミング読み取りを更新します。 このフラグは、ストリーミング テーブルが更新や削除などの挿入以外のものをスキップする必要があることを示します。
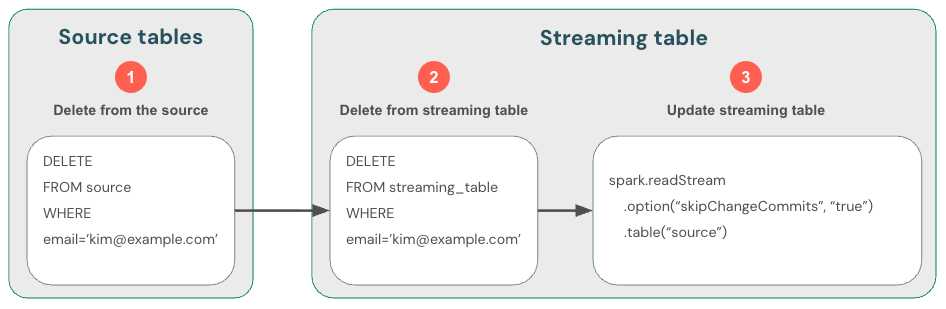
あるいは、(1) ソースからデータを削除してから、(2) ストリーミング テーブルを完全に更新することもできます。 ストリーミング テーブルを完全に更新すると、テーブルのストリーミング状態がクリアされ、すべてのデータが再処理されます。 保持期間を超えたアップストリーム データ ソース (たとえば、7 日後にデータが古くなるKafkaトピック) は再度処理されないため、データが失われる可能性があります。 ストリーミング テーブルに対してこのオプションを推奨するのは、ヒストリカル データが利用可能であり、その再処理にコストがかからないシナリオの場合のみです。
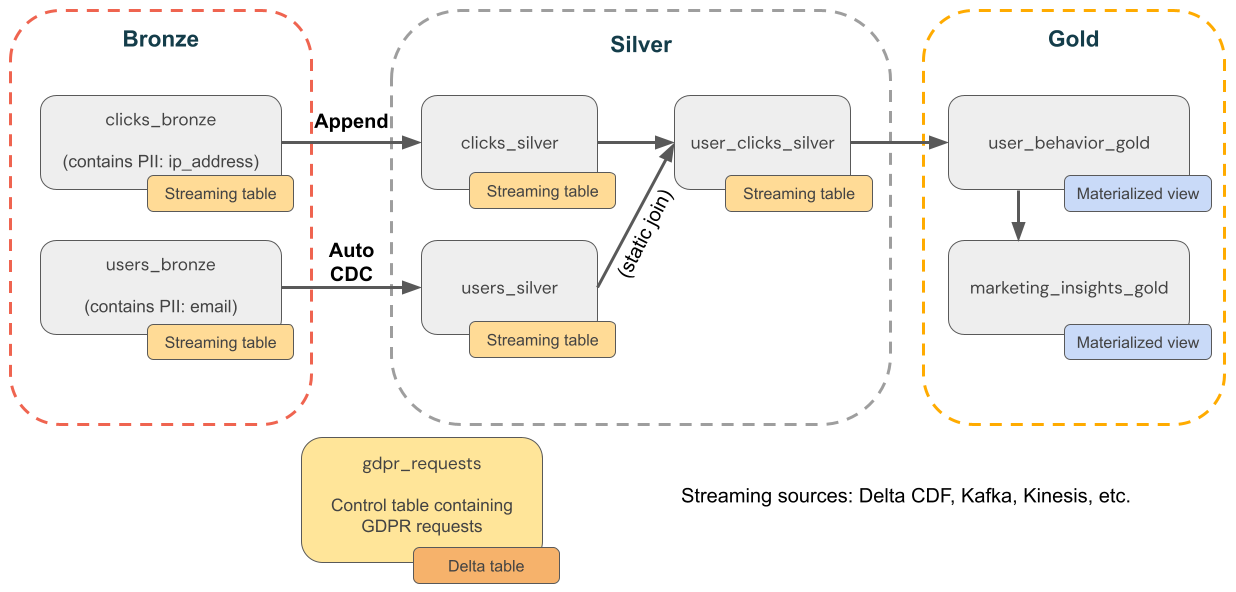
例: eコマース企業の GDPR と CCPA のコンプライアンス
次の図は、 GDPR & CCPA コンプライアンスを実装する必要がある電子商取引会社のメダリオンアーキテクチャを示しています。 ユーザーのデータが削除されても、ダウンストリーム集計でユーザーのアクティビティをカウントしたい場合があります。
-
ソーステーブル
source_users- ユーザーのストリーミング ソース テーブル (例としてここで作成)。本番運用環境では通常、 Kafka 、 Kinesis 、または同様のストリーミング プラットフォームを使用します。source_clicks- クリックのストリーミング ソース テーブル (例としてここで作成)。本番運用環境では通常、 Kafka 、 Kinesis 、または同様のストリーミング プラットフォームを使用します。
-
制御テーブル
gdpr_requests- 「忘れられる権利」の対象となるユーザー ID を含む制御テーブル。ユーザーが削除をリクエストした場合は、ここに追加します。
-
ブロンズレイヤー
users_bronze- ユーザーディメンション。PII が含まれています (例: Eメール アドレス)。clicks_bronze- [イベント]をクリックします。PII (IP アドレスなど) が含まれています。
-
シルバーレイヤー
clicks_silver- クリックデータをクリーンアップして標準化しました。users_silver- ユーザーデータをクリーンアップして標準化しました。user_clicks_silver-users_silverのスナップショットを使用してclicks_silver(ストリーミング) に参加します。
-
ゴールドレイヤー
user_behavior_gold- 集約されたユーザー行動メトリクス。marketing_insights_gold- 市場知識のためのユーザーセグメント。
ステップ 1: テーブルにサンプル データを設定する
次のコードは、この例のためにこれら 2 つのテーブルを作成し、サンプル データを入力します。
source_usersユーザーに関するディメンション データが含まれます。このテーブルには、emailという PII 列が含まれています。source_clicksユーザーが実行したアクティビティに関するイベント データが含まれます。これには、ip_addressという PII 列が含まれています。
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, MapType, DateType
catalog = "users"
schema = "name"
# Create table containing sample users
users_schema = StructType([
StructField('user_id', IntegerType(), False),
StructField('username', StringType(), True),
StructField('email', StringType(), True),
StructField('registration_date', StringType(), True),
StructField('user_preferences', MapType(StringType(), StringType()), True)
])
users_data = [
(1, 'alice', 'alice@example.com', '2021-01-01', {'theme': 'dark', 'language': 'en'}),
(2, 'bob', 'bob@example.com', '2021-02-15', {'theme': 'light', 'language': 'fr'}),
(3, 'charlie', 'charlie@example.com', '2021-03-10', {'theme': 'dark', 'language': 'es'}),
(4, 'david', 'david@example.com', '2021-04-20', {'theme': 'light', 'language': 'de'}),
(5, 'eve', 'eve@example.com', '2021-05-25', {'theme': 'dark', 'language': 'it'})
]
users_df = spark.createDataFrame(users_data, schema=users_schema)
users_df.write.mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_users")
# Create table containing clickstream (i.e. user activities)
from pyspark.sql.types import TimestampType
clicks_schema = StructType([
StructField('click_id', IntegerType(), False),
StructField('user_id', IntegerType(), True),
StructField('url_clicked', StringType(), True),
StructField('click_timestamp', StringType(), True),
StructField('device_type', StringType(), True),
StructField('ip_address', StringType(), True)
])
clicks_data = [
(1001, 1, 'https://example.com/home', '2021-06-01T12:00:00', 'mobile', '192.168.1.1'),
(1002, 1, 'https://example.com/about', '2021-06-01T12:05:00', 'desktop', '192.168.1.1'),
(1003, 2, 'https://example.com/contact', '2021-06-02T14:00:00', 'tablet', '192.168.1.2'),
(1004, 3, 'https://example.com/products', '2021-06-03T16:30:00', 'mobile', '192.168.1.3'),
(1005, 4, 'https://example.com/services', '2021-06-04T10:15:00', 'desktop', '192.168.1.4'),
(1006, 5, 'https://example.com/blog', '2021-06-05T09:45:00', 'tablet', '192.168.1.5')
]
clicks_df = spark.createDataFrame(clicks_data, schema=clicks_schema)
clicks_df.write.format("delta").mode("overwrite").saveAsTable(f"{catalog}.{schema}.source_clicks")
ステップ 2: PII データを処理するパイプラインを作成する
次のコードは、上記のメダリオンアーキテクチャのブロンズ、シルバー、およびゴールドレイヤーを作成します。
from pyspark import pipelines as dp
from pyspark.sql.functions import col, concat_ws, count, countDistinct, avg, when, expr
catalog = "users"
schema = "name"
# ----------------------------
# Bronze Layer - Raw Data Ingestion
# ----------------------------
@dp.table(
name=f"{catalog}.{schema}.users_bronze",
comment='Raw users data loaded from source'
)
def users_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_users")
)
@dp.table(
name=f"{catalog}.{schema}.clicks_bronze",
comment='Raw clicks data loaded from source'
)
def clicks_bronze():
return (
spark.readStream.table(f"{catalog}.{schema}.source_clicks")
)
# ----------------------------
# Silver Layer - Data Cleaning and Enrichment
# ----------------------------
@dp.create_streaming_table(
name=f"{catalog}.{schema}.users_silver",
comment='Cleaned and standardized users data'
)
@dp.view
@dp.expect_or_drop('valid_email', "email IS NOT NULL")
def users_bronze_view():
return (
spark.readStream
.table(f"{catalog}.{schema}.users_bronze")
.withColumn('registration_date', col('registration_date').cast('timestamp'))
.dropDuplicates(['user_id', 'registration_date'])
.select('user_id', 'username', 'email', 'registration_date', 'user_preferences')
)
@dp.create_auto_cdc_flow(
target=f"{catalog}.{schema}.users_silver",
source="users_bronze_view",
keys=["user_id"],
sequence_by="registration_date",
)
@dp.table(
name=f"{catalog}.{schema}.clicks_silver",
comment='Cleaned and standardized clicks data'
)
@dp.expect_or_drop('valid_click_timestamp', "click_timestamp IS NOT NULL")
def clicks_silver():
return (
spark.readStream
.table(f"{catalog}.{schema}.clicks_bronze")
.withColumn('click_timestamp', col('click_timestamp').cast('timestamp'))
.withWatermark('click_timestamp', '10 minutes')
.dropDuplicates(['click_id'])
.select('click_id', 'user_id', 'url_clicked', 'click_timestamp', 'device_type', 'ip_address')
)
@dp.table(
name=f"{catalog}.{schema}.user_clicks_silver",
comment='Joined users and clicks data on user_id'
)
def user_clicks_silver():
# Read users_silver as a static DataFrame - each refresh
# will use a snapshot of the users_silver table.
users = spark.read.table(f"{catalog}.{schema}.users_silver")
# Read clicks_silver as a streaming DataFrame.
clicks = spark.readStream \
.table('clicks_silver')
# Perform the join - join of a static dataset with a
# streaming dataset creates a streaming table.
joined_df = clicks.join(users, on='user_id', how='inner')
return joined_df
# ----------------------------
# Gold Layer - Aggregated and Business-Level Data
# ----------------------------
@dp.materialized_view(
name=f"{catalog}.{schema}.user_behavior_gold",
comment='Aggregated user behavior metrics'
)
def user_behavior_gold():
df = spark.read.table(f"{catalog}.{schema}.user_clicks_silver")
return (
df.groupBy('user_id')
.agg(
count('click_id').alias('total_clicks'),
countDistinct('url_clicked').alias('unique_urls')
)
)
@dp.materialized_view(
name=f"{catalog}.{schema}.marketing_insights_gold",
comment='User segments for marketing insights'
)
def marketing_insights_gold():
df = spark.read.table(f"{catalog}.{schema}.user_behavior_gold")
return (
df.withColumn(
'engagement_segment',
when(col('total_clicks') >= 100, 'High Engagement')
.when((col('total_clicks') >= 50) & (col('total_clicks') < 100), 'Medium Engagement')
.otherwise('Low Engagement')
)
)
ステップ 3: ソース テーブルのデータを削除する
このステップでは、PII が見つかったすべてのテーブルのデータを削除します。 次の関数は、PII を含むテーブルからユーザーの PII のすべてのインスタンスを削除します。
catalog = "users"
schema = "name"
def apply_gdpr_delete(user_id):
tables_with_pii = ["clicks_bronze", "users_bronze", "clicks_silver", "users_silver", "user_clicks_silver"]
for table in tables_with_pii:
print(f"Deleting user_id {user_id} from table {table}")
spark.sql(f"""
DELETE FROM {catalog}.{schema}.{table}
WHERE user_id = {user_id}
""")
ステップ 4: 影響を受けるストリーミングテーブルの定義に skipChangeCommits を追加する
このステップでは、追加以外の行をスキップするようにLakeFlow Spark宣言型パイプラインに指示する必要があります。 次のメソッドに skipChangeCommits オプションを追加します。マテリアライズドビューの定義は更新と削除を自動的に処理するため、更新する必要はありません。
users_bronzeusers_silverclicks_bronzeclicks_silveruser_clicks_silver
次のコードは、 users_bronze メソッドを更新する方法を示しています。
def users_bronze():
return (
spark.readStream.option('skipChangeCommits', 'true').table(f"{catalog}.{schema}.source_users")
)
パイプラインを再度実行すると、パイプラインは正常に更新されます。