データファイルサイズを制御する
手動チューニングの推奨事項は、自動ファイルサイズチューニングを使用する Unity Catalog マネージドテーブルには適用されません。新しいテーブルには、デフォルト設定で Unity Catalog マネージドテーブルを使用してください。
Databricks Runtime 13.3 LTS 以降では、Databricks ではテーブル レイアウトにクラスターを使用することをお勧めします。「テーブルにリキッドクラスタリングを使用する」を参照してください。
Databricks では、予測的最適化を使用して、テーブルの OPTIMIZE と VACUUM を自動的に実行することをお勧めします。Unity Catalog マネージドテーブルの予測的最適化を参照してください。
自動コンパクションと最適化された書き込みは、MERGE、UPDATE、および DELETE の操作に対して常に有効になります。この機能を無効にすることはできません。
Databricks は Unity Catalog マネージドテーブルのファイルサイズを自動的にチューニングします。外部テーブルとレガシーワークロードの場合、データの書き込み方法と圧縮方法を制御するために、自動圧縮、最適化された書き込み、およびターゲットファイルサイズを設定できます。
Unity Catalog でマネージドテーブルの場合、SQLウェアハウスまたは Databricks Runtime 11.3 LTS 以降を使用していると、Databricks はほとんどの構成を自動的に調整します。
Databricks Runtime 10.4 LTS以下からワークロードをアップグレードしている場合は、バックグラウンド自動圧縮へのアップグレードを参照してください。
実行タイミング: OPTIMIZE
自動圧縮と最適化された書き込みは、それぞれ小さなファイルの問題を軽減しますが、OPTIMIZEの完全な代替ではありません。1 TBを超えるテーブルの場合、Databricksでは、ファイルをさらに統合するために、スケジュールに従ってOPTIMIZEを実行することをお勧めします。Databricks では、強化されたデータスキップのためにリキッドクラスタリングを推奨しています。リキッドクラスタリングが有効になっている場合、OPTIMIZE はクラスタリングキーによってデータを自動的に再編成します。「テーブルにリキッドクラスタリングを使用する」を参照してください。
Unity Catalog マネージドテーブルの場合、予測的最適化は、予測的最適化が有効になっているテーブルに対して OPTIMIZE を自動的に実行します。
自動最適化
**自動最適化**は、設定autoOptimize.autoCompact とautoOptimize.optimizeWrite を記述します。「自動圧縮」と「最適化された書き込み」を参照してください。
オートコンパクト
自動圧縮は、テーブルパーティション内の小さなファイルを結合して、小さなファイルの問題を軽減します。書き込みが成功した後、書き込みを実行したクラスター上で同期的に実行され、以前に圧縮されていないファイルのみを圧縮します。
自動圧縮と予測的最適化は、個別に、または一緒に利用できる独立した機能です。自動圧縮は、書き込みを実行しているクラスター上で実行されますが、予測的最適化は、サーバレスコンピュートを使用して非同期でメンテナンス操作を実行します。
自動コンパクションを設定するには、以下の設定を使用します。
設定 | Delta | Iceberg | 説明 |
|---|---|---|---|
自動圧縮を有効にする(テーブルプロパティ) |
|
| テーブルレベルで自動圧縮を有効にします。 |
自動圧縮を有効にする(Spark セッション) |
|
| セッションレベルで自動コンパクションを有効にできます。 |
最大出力ファイルサイズ |
|
| ターゲットファイルサイズを制御します。 |
圧縮をトリガーする最小ファイル数 |
|
| パーティションまたはテーブルで自動圧縮をトリガーするために必要となる小さなファイルの最小数を設定します。 |
これらの設定では、次のオプションを使用できます:
オプション | 挙動 |
|---|---|
| 他の自動チューニング機能を尊重しながら、ターゲットファイルサイズを調整します。 |
|
|
| ターゲットファイルサイズとして128 MBを使用します。動的なサイズ設定はありません。 |
| 自動圧縮をオフにします。セッションレベルで設定して、ワークロードで変更されたすべてのテーブルの自動圧縮をオーバーライドできます。 |
Databricks は、テーブルサイズに基づいた自動チューニングを使用して、出力ファイルサイズを制御することを推奨しています。「テーブルサイズに基づいてファイルサイズを自動調整します」を参照してください。
自動圧縮がテーブルで実行されたことを確認するには、テーブルの履歴を確認してください。自動圧縮は、operationParameters.autoフィールドがtrueに設定されたOPTIMIZE操作として表示されます。手動で実行されたOPTIMIZEコマンドは、autoがfalseに設定されています。「OPTIMIZE操作のタイプを識別する」を参照してください。
最適化された書き込み
書き込みが最適化されると、データが書き込まれるときのファイルサイズが改善され、その後のテーブルの読み取りが向上します。
最適化された書き込みは、各パーティションに書き込まれる小さなファイルの数を減らすため、パーティション分割されたテーブルに対して最も効果的です。小さなファイルを多数書き込むよりも、大きなファイルの書き込みを少なくするほうが効率的ですが、データが書き込まれる前にシャッフルされるため、書き込み遅延が増加する可能性があります。
次の図は、最適化された書き込みがどのように機能するかを示しています:
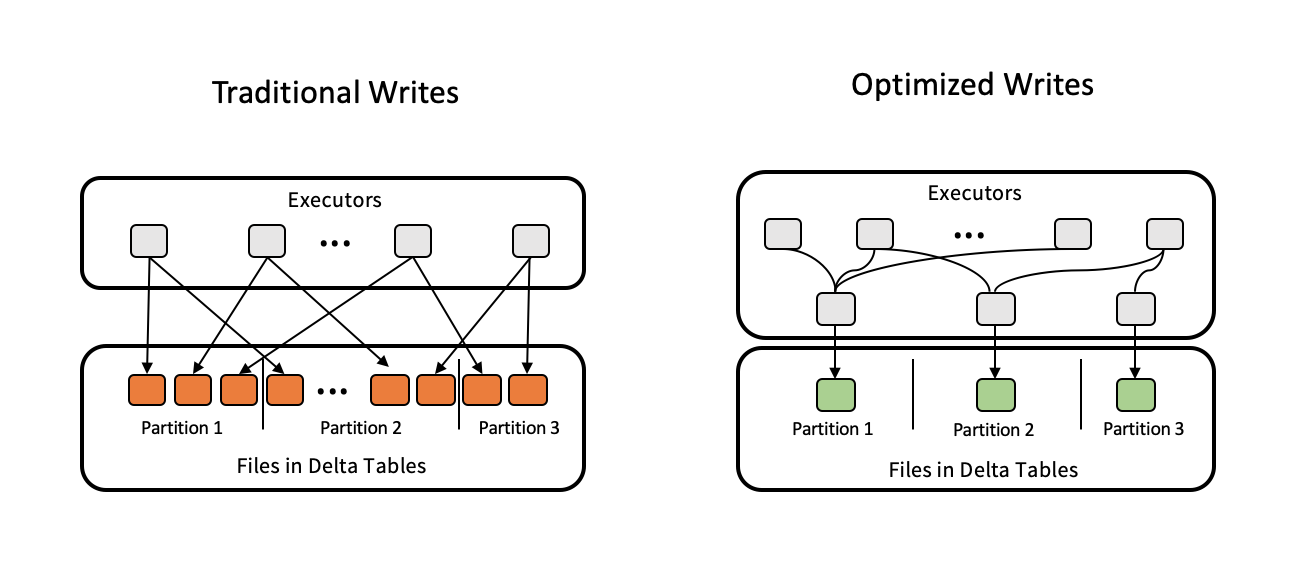
最適化された書き込みを使用する場合、書き込まれるファイル数を制御するために、書き込みの直前にcoalesce(n)またはrepartition(n)を実行しないことをDatabricksは推奨します。
最適化された書き込みは、次のオペレーションでデフォルトで有効になっています:
MERGEUPDATEサブクエリー付きDELETEサブクエリー付き
SQLウェアハウスを使用する場合、最適化された書き込みは、CTASステートメントとINSERTオペレーションに対しても有効になります。Databricks Runtime 13.3 LTS 以降では、Unity Catalogに登録されているすべてのテーブルで、パーティション分割テーブルのCTASステートメントとINSERTオペレーションに対して最適化された書き込みが有効になっています。
最適化された書き込みは、次の設定を使用してテーブルレベルまたはセッションレベルで有効にすることができます:
- テーブルプロパティ:
autoOptimize.optimizeWrite - SparkSession設定:
spark.databricks.delta.optimizeWrite.enabled(Delta)またはspark.databricks.iceberg.optimizeWrite.enabled(Iceberg)
これらの設定では、次のオプションを使用できます:
オプション | 挙動 |
|---|---|
| ターゲットファイルサイズとして128 MBを使用します。 |
| 最適化された書き込みをオフにします。セッションレベルで設定して、ワークロードで変更されたすべてのテーブルの最適化された書き込みをオーバーライドできます。 |
目標ファイルサイズを設定する
テーブル内のファイルのサイズを調整するには、テーブルプロパティ targetFileSize を希望のサイズに設定します。設定すると、すべてのデータレイアウト最適化操作は、optimize、リキッドクラスタリング、自動コンパクション、最適化された書き込みなど、指定されたサイズのファイルを生成するために最大限の努力をします。
Unity Catalogで管理されるテーブルとSQLウェアハウス、またはDatabricks Runtime 11.3 LTS以降を使用する場合、OPTIMIZEコマンドのみがtargetFileSize設定を尊重します。
属性 | 説明 |
|---|---|
| タイプ:バイト単位以上のサイズ。 説明 :ターゲットファイルサイズ。たとえば、 デフォルト値 : なし |
既存のテーブルの場合、SQLコマンドALTER TABLE SET TBL PROPERTIESを使用してプロパティを設定および設定解除できます。Sparkセッション構成を使用して新しいテーブルを作成するときに、これらのプロパティを自動的に設定することもできます。詳細については「テーブル プロパティ リファレンス」を参照してください。
テーブルサイズに基づいてファイルサイズを自動調整します
手動チューニングを最小限に抑えるため、Databricks はテーブルのサイズに基づいてテーブルのファイルサイズを自動的に調整します。Databricks は、テーブル内のファイル数が大きくなりすぎないように、小さいテーブルには小さいファイルサイズを、大きいテーブルには大きいファイルサイズを使用します。Databricks は、特定のターゲットサイズで調整したテーブルを自動調整しません。
ターゲットファイルサイズは、テーブルの現在のサイズに基づきます。2.56 TB未満のテーブルの場合、自動調整されるターゲットファイルサイズは256 MBです。サイズが2.56 TBから10 TBのテーブルの場合、ターゲットサイズは256 MBから1 GBまで直線的に増加します。10 TBを超えるテーブルの場合、ターゲットファイルサイズは1 GBです。
テーブルのターゲットファイルサイズが大きくなった場合、既存のファイルは、OPTIMIZEコマンドによってより大きなファイルに再最適化されません。したがって、大きなテーブルには、ターゲットサイズよりも小さいファイルが常に含まれる可能性があります。これらの小さいファイルをさらに大きいファイルに最適化する必要がある場合は、targetFileSizeテーブルプロパティを使用してテーブルの固定ターゲットファイルサイズを構成できます。
テーブルが増分的に書き込まれる場合、ターゲットファイルサイズとファイル数は、テーブルサイズに基づいて次の数値に近くなります。このテーブルのファイル数は単なる例です。実際の結果は、多くの要因によって異なります。
テーブルサイズ | ターゲットファイルサイズ | テーブル内のファイルのおおよその数 |
|---|---|---|
10 GB | 256 MB | 40 |
1 TB | 256 MB | 4096 |
2.56 TB | 256 MB | 10240 |
3TB | 307 MB | 12108 |
5 TB | 512 MB | 17339 |
7 TB | 716 MB | 20784 |
10 TB | 1 GB | 24437 |
20 TB | 1 GB | 34437 |
50 TB | 1 GB | 64437 |
100 TB | 1 GB | 114437 |
データファイルに書き込まれる行を制限する
場合によっては、狭いデータを含むテーブルで、特定のデータファイル内の行数がParquet形式のサポート制限を超えたことによりエラーが発生することがあります。このエラーを回避するには、SQLセッション構成spark.sql.files.maxRecordsPerFileを使用して、テーブルの1つのファイルに書き込むレコードの最大数を指定します。ゼロまたは負の値を指定することは、制限がないことを表します。
DataFrame APIs を使用してテーブルに書き込むときに、DataFrameWriter オプション maxRecordsPerFile も使用できます。maxRecordsPerFileを指定した場合、SQLセッション構成の値spark.sql.files.maxRecordsPerFileは無視されます。
Databricksでは、エラーを回避する必要がある場合を除き、maxRecordsPerFile の使用は推奨しません。この設定は、非常に狭いデータを持つ一部の Unity Catalog マネージドテーブルで必要になる場合があります。
バックグラウンド自動圧縮へのアップグレード
バックグラウンド自動圧縮は、Unity Catalog のマネージドテーブルで利用できます。バックグラウンド自動圧縮には、予測的最適化は必要ありません。レガシー ワークロードまたはテーブルを移行するときは、次の手順を実行してください:
- クラスターまたはノートブックの構成設定から Spark 構成
spark.databricks.delta.autoCompact.enabled(Delta) またはspark.databricks.iceberg.autoCompact.enabled(Iceberg) を削除します。 - 以前の自動圧縮設定をすべて削除するには、各テーブルで
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact)(Delta) またはALTER TABLE <table_name> UNSET TBLPROPERTIES (iceberg.autoOptimize.autoCompact)(Iceberg) を実行してください。
これらのレガシー構成を削除した後、すべての Unity Catalog マネージドテーブルに対してバックグラウンドの自動コンパクションが自動的にトリガーされます。