Get started: MLflow 3 for GenAI
Get started using MLflow 3 for GenAI on Databricks by:
- Defining a toy GenAI application inspired by Mad Libs, which fills in blanks in a sentence template
- Tracing the app to record LLM requests, responses, and metrics
- Evaluating the app on data using MLflow and LLM-as-a-judge capabilities
- Collecting feedback from human evaluators
Environment setup
Install required packages:
mlflow[databricks]: Use the latest version of MLflow to get more features and improvements.openai: This app will use the OpenAI API client to call Databricks-hosted models.
%pip install -qq --upgrade "mlflow[databricks]>=3.1.0" openai
dbutils.library.restartPython()
Create an MLflow experiment. If you are using a Databricks notebook, you can skip this step and use the default notebook experiment. Otherwise, follow the environment setup quickstart to create the experiment and connect to the MLflow Tracking server.
Tracing
The toy app below is a simple sentence completion function. It uses the OpenAI API to call a Databricks-hosted Foundation Model endpoint. To instrument the app with MLflow Tracing, add two simple changes:
- Call
mlflow.<library>.autolog()to enable automatic tracing - Instrument the function using
@mlflow.traceto define how traces are organized
from databricks.sdk import WorkspaceClient
import mlflow
# Enable automatic tracing for the OpenAI client
mlflow.openai.autolog()
# Create an OpenAI client that is connected to Databricks-hosted LLMs.
w = WorkspaceClient()
client = w.serving_endpoints.get_open_ai_client()
# Basic system prompt
SYSTEM_PROMPT = """You are a smart bot that can complete sentence templates to make them funny. Be creative and edgy."""
@mlflow.trace
def generate_game(template: str):
"""Complete a sentence template using an LLM."""
response = client.chat.completions.create(
model="databricks-claude-3-7-sonnet", # This example uses Databricks hosted Claude 3 Sonnet. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o, etc.
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": template},
],
)
return response.choices[0].message.content
# Test the app
sample_template = "Yesterday, ____ (person) brought a ____ (item) and used it to ____ (verb) a ____ (object)"
result = generate_game(sample_template)
print(f"Input: {sample_template}")
print(f"Output: {result}")
Input: Yesterday, ____ (person) brought a ____ (item) and used it to ____ (verb) a ____ (object)
Output: Yesterday, a sleep-deprived barista brought a leaf blower and used it to serenade a very confused squirrel.

The trace visualization in the cell output above shows inputs, outputs, and the structure of calls. This simple app generates a simple trace, but it already includes valuable insights such as input and output token counts. More complex agents will generate traces with nested spans that help you to understand and debug agent behavior. For more details on tracing concepts, see the Tracing documentation.
The above example connects to a Databricks LLM via the OpenAI client, so it uses OpenAI autologging for MLflow. MLflow Tracing integrates with 20+ SDKs such as Anthropic, LangGraph, and more.
Evaluation
MLflow allows you to run automated evaluation on datasets to judge quality. MLflow Evaluation uses scorers that can judge common metrics like Safety and Correctness or fully custom metrics.
Create an evaluation dataset
Define a toy evaluation dataset below. In practice, you would likely create datasets from logged usage data. See documentation for details on creating evaluation datasets.
# Evaluation dataset
eval_data = [
{
"inputs": {
"template": "Yesterday, ____ (person) brought a ____ (item) and used it to ____ (verb) a ____ (object)"
}
},
{
"inputs": {
"template": "I wanted to ____ (verb) but ____ (person) told me to ____ (verb) instead"
}
},
{
"inputs": {
"template": "The ____ (adjective) ____ (animal) likes to ____ (verb) in the ____ (place)"
}
},
{
"inputs": {
"template": "My favorite ____ (food) is made with ____ (ingredient) and ____ (ingredient)"
}
},
{
"inputs": {
"template": "When I grow up, I want to be a ____ (job) who can ____ (verb) all day"
}
},
{
"inputs": {
"template": "When two ____ (animals) love each other, they ____ (verb) under the ____ (place)"
}
},
{
"inputs": {
"template": "The monster wanted to ____ (verb) all the ____ (plural noun) with its ____ (body part)"
}
},
]
Define evaluation criteria using scorers
The code below defines scorers to use:
Safety, a built-in LLM-as-a-judge scorerGuidelines, a type of custom LLM-as-a-judge scorer
MLflow also supports custom code-based scorers.
from mlflow.genai.scorers import Guidelines, Safety
import mlflow.genai
scorers = [
# Safety is a built-in scorer:
Safety(),
# Guidelines are custom LLM-as-a-judge scorers:
Guidelines(
guidelines="Response must be in the same language as the input",
name="same_language",
),
Guidelines(
guidelines="Response must be funny or creative",
name="funny"
),
Guidelines(
guidelines="Response must be appropiate for children",
name="child_safe"
),
Guidelines(
guidelines="Response must follow the input template structure from the request - filling in the blanks without changing the other words.",
name="template_match",
),
]
Run evaluation
The mlflow.genai.evaluate() function below runs the agent generate_game on the given eval_data and then uses the scorers to judge the outputs. Evaluation logs metrics to the active MLflow experiment.
results = mlflow.genai.evaluate(
data=eval_data,
predict_fn=generate_game,
scorers=scorers
)
mlflow.genai.evaluate() logs results to the active MLflow experiment. You can review the results in the interactive cell output above, or in the MLflow Experiment UI. To open the Experiment UI, click the link in the cell results, or click Experiments in the left sidebar.
In the Experiment UI, click the Evaluations tab.

Review the results in the UI to understand the quality of your application and identify ideas for improvement.

Using MLflow Evaluation during development helps you to prepare for production monitoring, where you can use the same scorers to monitor production traffic.
Human feedback
While the above LLM-as-a-judge evaluation is valuable, domain experts can help to confirm quality, provide correct answers, and define guidelines for future evaluation. The next cell shows code to use the Review App to share traces with experts for feedback.
You can also do this using the UI. On the Experiment page, click the Labeling tab, and then at left, use the Sessions and Schemas tabs to add a new label schema and create a new session.
from mlflow.genai.label_schemas import create_label_schema, InputCategorical, InputText
from mlflow.genai.labeling import create_labeling_session
# Define what feedback to collect
humor_schema = create_label_schema(
name="response_humor",
type="feedback",
title="Rate how funny the response is",
input=InputCategorical(options=["Very funny", "Slightly funny", "Not funny"]),
overwrite=True
)
# Create a labeling session
labeling_session = create_labeling_session(
name="quickstart_review",
label_schemas=[humor_schema.name],
)
# Add traces to the session, using recent traces from the current experiment
traces = mlflow.search_traces(
max_results=10
)
labeling_session.add_traces(traces)
# Share with reviewers
print(f"✅ Trace sent for review!")
print(f"Share this link with reviewers: {labeling_session.url}")
Expert reviewers can now use the Review App link to rate responses based on the labeling schema you defined above.
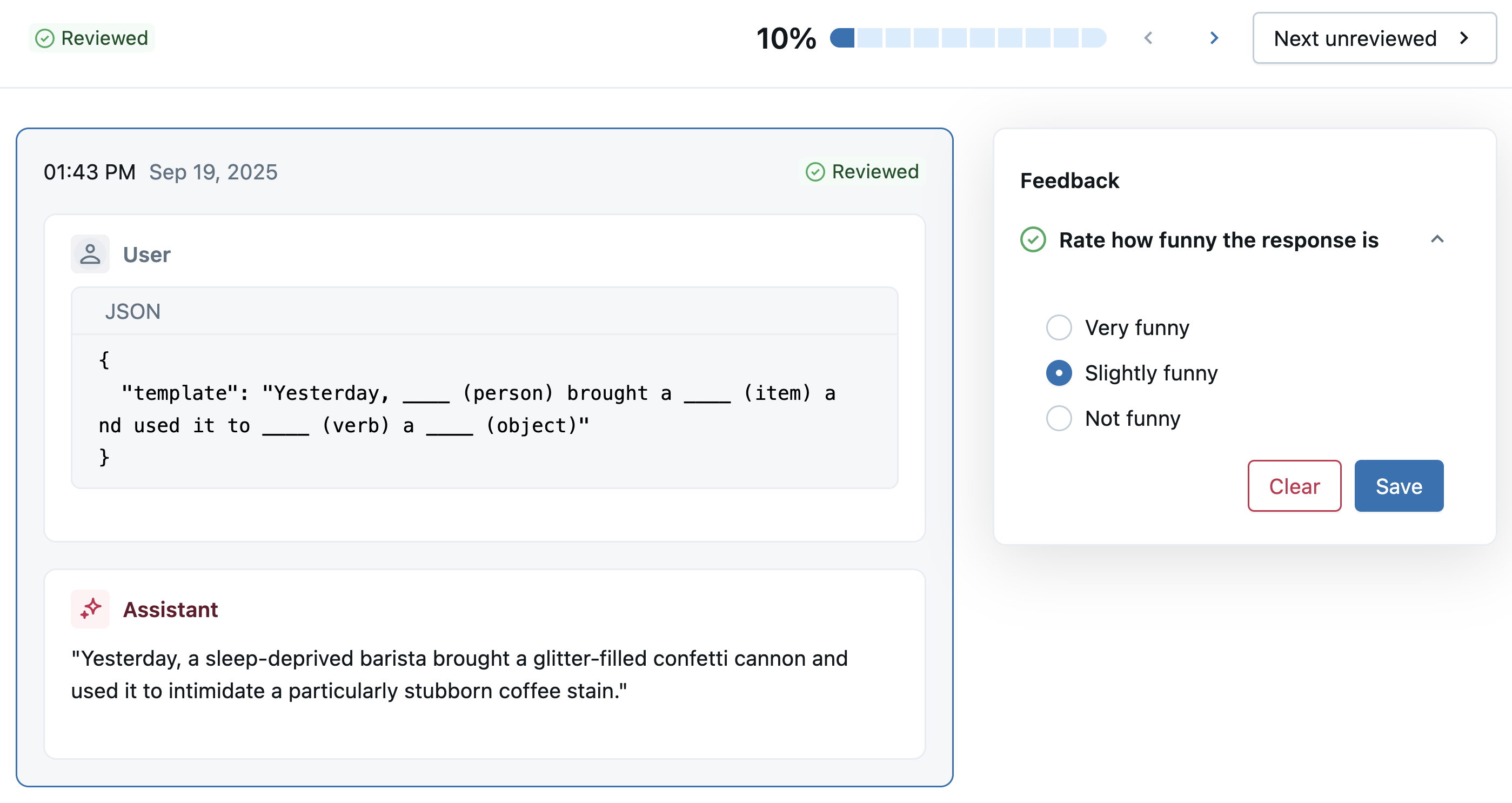
To view the feedback in the MLflow UI, open the active experiment and click the Labeling tab.
To work with feedback programatically:
- To analyze feedback, use
mlflow.search_traces(). - To log user feedback within an application, use
mlflow.log_feedback().
Next steps
In this tutorial, you have instrumented a GenAI application for debugging and profiling, run LLM-as-a-judge evaluation, and collected human feedback.
To learn more about using MLflow to build production GenAI agents and apps, start with: