Use o aplicativo de revisão para revisões humanas de um aplicativo de AI generativa (MLflow 2)
A Databricks recomenda usar o MLflow 3 para a avaliação e monitoramento de aplicativos GenAI. Esta página descreve o MLflow 2 Agent Evaluation.
- Para uma introdução à avaliação e monitoramento no MLflow 3, consulte Avalie e monitore agentes de AI.
- Para obter informações sobre como migrar para o MLflow 3, consulte Migrar para o MLflow 3 a partir da Agent Evaluation.
- Para obter informações do MLflow 3 sobre este tópico, consulte feedback de especialistas do domínio.
Este artigo descreve como usar o aplicativo de avaliação para coletar feedback de especialistas no assunto (SMEs). É possível usar o aplicativo de avaliação para fazer o seguinte:
- Ofereça aos seus stakeholders a capacidade de conversar com um aplicativo de AI generativa em pré-produção e de fornecer feedback.
- Crie um dataset de avaliação, apoiado por uma tabela Delta no Unity Catalog.
- Utilize os especialistas no assunto para expandir e iterar sobre esse dataset de avaliação.
- Aproveite os PMEs para rotular rastreamentos de produção para entender a qualidade do seu aplicativo de AI generativa.

O que acontece em uma avaliação humana?
O aplicativo de revisão da Databricks apresenta um ambiente onde as partes interessadas podem interagir com ele. Em outras palavras, conversar, fazer perguntas, fornecer feedback e assim por diante.
Existem duas maneiras principais de usar o aplicativo de avaliação:
- **Converse com o bot**: Colete perguntas, respostas e feedback em uma tabela de inferência para que você possa analisar ainda mais o desempenho do aplicativo de AI generativa. Dessa forma, o aplicativo de revisão ajuda a garantir a qualidade e a segurança das respostas que seu aplicativo fornece.
- Rótulo das respostas em uma sessão : Colete feedback e expectativas de PMEs em uma sessão de rotulagem, armazenadas em uma execução do MLflow. Você pode, opcionalmente, sincronizar esses rótulos com um dataset de avaliação.
Requisitos
- Os desenvolvedores devem instalar o SDK
databricks-agentspara configurar permissões e o aplicativo de revisão.
%pip install databricks-agents==0.16.0
dbutils.library.restartPython()
-
Para conversar com o bot:
- Tabelas de inferência devem ser habilitadas no endpoint que está servindo o agente.
- Cada revisor humano deve ter acesso ao workspace do aplicativo de revisão ou ser sincronizado com sua conta do Databricks via SCIM. Consulte a próxima seção, Configurar permissões para usar o aplicativo de revisão.
-
Para sessões de etiquetagem:
- Cada revisor humano deve ter acesso ao workspace do aplicativo de revisão.
Configure permissões para usar o aplicativo de revisão
- Para conversar com o bot, um revisor humano *não* exige acesso ao workspace.
- Para uma sessão de etiquetagem, um revisor humano precisa de acesso ao workspace.
Configurar permissões para "Converse com o bot"
- Para usuários que não têm acesso ao workspace, um administrador da conta usa o provisionamento SCIM no nível da conta para sincronizar usuários e grupos automaticamente do seu provedor de identidade com sua conta do Databricks. Também é possível fazer o registro manual desses usuários e grupos para conceder a eles acesso ao configurar identidades no Databricks. Consulte Sincronize usuários e grupos do seu provedor de identidade usando SCIM.
- Para usuários que já têm acesso ao workspace que contém o aplicativo de revisão, nenhuma configuração adicional é necessária.
O exemplo de código a seguir mostra como dar permissão aos usuários para o modelo que foi implantado via agents.deploy. O parâmetro users aceita uma lista de endereços de email.
from databricks import agents
# Note that <user_list> can specify individual users or groups.
agents.set_permissions(model_name=<model_name>, users=[<user_list>], permission_level=agents.PermissionLevel.CAN_QUERY)
Para conceder permissões a todos os usuários no workspace, defina users=["users"].
Configurar permissões para sessões de etiquetagem
Os usuários recebem automaticamente as permissões apropriadas (acesso de gravação a um experimento e acesso de leitura a um dataset) ao criar uma sessão de rótulo e fornecer o argumento assigned_users.
Para mais informações, consulte Criar uma sessão de etiquetagem e enviar para revisão abaixo.
Criar um aplicativo de revisão
Usando automaticamente agents.deploy()
Ao implantar um aplicativo de IA generativa usando agents.deploy(), o aplicativo de revisão é ativado e implantado automaticamente. A saída do comando mostra a URL do aplicativo de revisão. Para obter informações sobre como implantar um aplicativo de AI generativa (também chamado de "agente"), consulte Implantar um Agente para Aplicativos de AI Generativa (Model Serving).
O agente não aparece na interface do usuário do aplicativo de revisão até que o endpoint seja totalmente implantado.
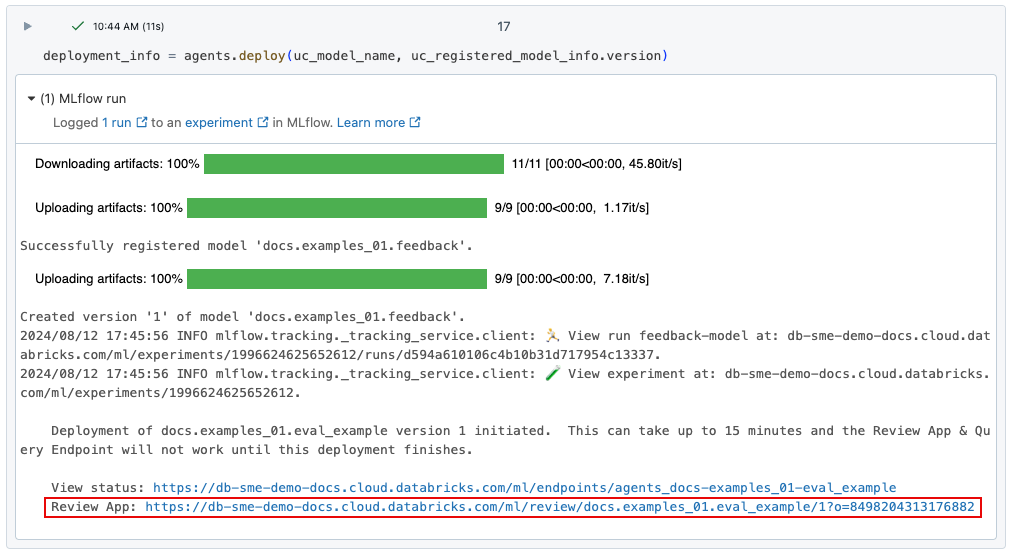
Se você perder o link para a IU do aplicativo de avaliação, você pode encontrá-lo usando get_review_app().
import mlflow
from databricks.agents import review_app
# The review app is tied to the current MLFlow experiment.
mlflow.set_experiment("same_exp_used_to_deploy_the_agent")
my_app = review_app.get_review_app()
print(my_app.url)
print(my_app.url + "/chat") # For "Chat with the bot".
Usando a API do Python manualmente
O snippet de código abaixo demonstra como criar um aplicativo de revisão e associá-lo a um endpoint de servindo modelo para conversar com o bot. Para criar sessões de rotulagem, consulte
- Criar uma sessão de etiquetagem e enviar para revisão para etiquetar um dataset de avaliação.
- Colete feedback sobre rastreamentos para adicionar rótulo aos rastreamentos. Observe que um agente ativo não é necessário para isso.
from databricks.agents import review_app
# The review app is tied to the current MLFlow experiment.
my_app = review_app.get_review_app()
# TODO: Replace with your own serving endpoint.
my_app.add_agent(
agent_name="llama-70b",
model_serving_endpoint="databricks-meta-llama-3-3-70b-instruct",
)
print(my_app.url + "/chat") # For "Chat with the bot".
Conceitos
dataset
Um Dataset é uma coleção de exemplos usados para avaliar um aplicativo de AI generativa. Os registros de dataset contêm inputs para um aplicativo de AI generativa e, opcionalmente, expectativas (rótulos de verdade fundamental, como expected_facts ou guidelines). Os datasets são vinculados a um experimento MLFlow e podem ser usados diretamente como inputs para mlflow.evaluate(). Os datasets são suportados por tabelas Delta no Unity Catalog, herdando as permissões definidas pela tabela Delta. Para criar um dataset, consulte Criar um Dataset.
Exemplo de dataset de avaliação, mostrando apenas as colunas de entradas e expectativas:

Datasets de avaliação têm o seguinte esquema:
Coluna | Tipo de dados | Descrição |
|---|---|---|
dataset_record_id | string | O identificador exclusivo para o registro. |
Entradas | string | Entradas para avaliação como JSON serializado |
Expectativas | string | Valores esperados como JSON serializado |
hora de criação | carimbo de data/hora | O horário em que o registro foi criado. |
criado_por | string | O usuário que criou o registro. |
Hora da última atualização | carimbo de data/hora | A hora em que o registro foi atualizado pela última vez. |
Última atualização por | string | O usuário que atualizou o registro pela última vez. |
Origem | struct | A origem do registro do dataset. |
source.human | struct | Definido quando a origem é de um humano. |
source.human.user_name | string | O nome do usuário associado ao registro. |
documento-fonte | string | Definido quando o registro foi sintetizado a partir de um documento. |
source.document.doc_uri | string | O URI do documento. |
origem.documento.conteúdo | string | O conteúdo do documento. |
source.trace | string | Definido quando o registro foi criado a partir de um rastreio. |
source.trace.trace_id | string | O identificador único para o rastreamento. |
Tags | map | Tags de key-valor para o registro do dataset. |
Sessões de etiquetagem
Um LabelingSession é um conjunto finito de rastreamentos ou registros de dataset para receber um rótulo por um SME na IU do aplicativo de avaliação. Rastreamentos podem vir de tabelas de inferência para um aplicativo em produção, ou de um rastreamento offline em experimentos MLflow. Os resultados são armazenados como uma execução MLflow. Rótulos são armazenados como Assessments em rastreamentos MLflow. Rótulos com “expectativas” podem ser sincronizados de volta para um Dataset de avaliação.
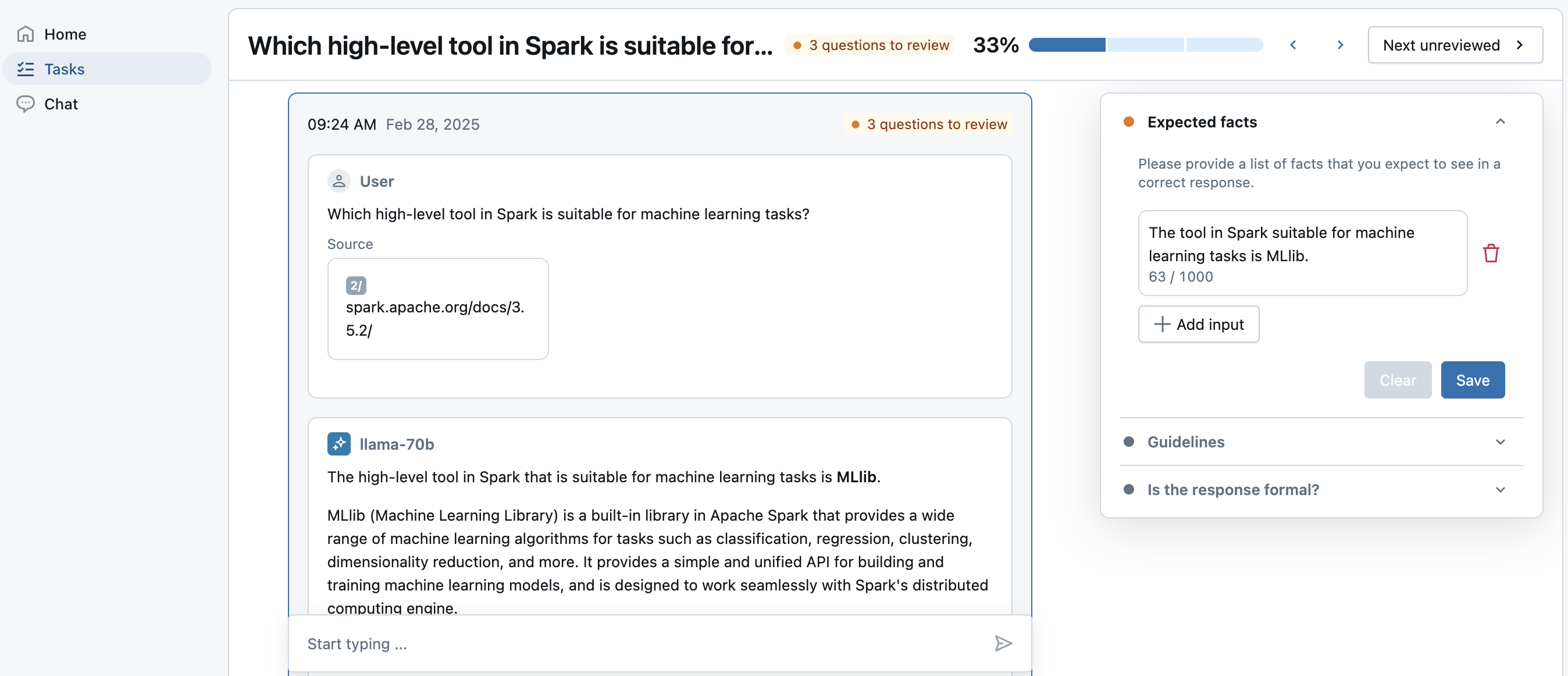
Avaliações e rótulos
Quando um especialista (SME) adiciona um rótulo a um rastreamento, avaliaçõessão gravadas no rastreamento sob o campo Trace.info.assessments. Há dois tipos de Assessment:
expectation: Rótulos que representam o que um rastreamento correto deve ter. Por exemplo:expected_factspode ser usado como um rótuloexpectation, representando os fatos que deveriam estar presentes em uma resposta ideal. Esses rótulosexpectationpodem ser sincronizados de volta para um dataset de avaliação para que possam ser usados commlflow.evaluate().feedback: Rótulos que representam feedback simples em um rastreamento, como "polegar para cima" e "polegar para baixo", ou comentários de formato livre.Assessments do tipofeedbacknão são usados com datasets de avaliação, pois são uma avaliação humana de um rastreamento MLFLow específico. Essas avaliações podem ser lidas commlflow.search_traces().
dataset
Esta seção explica como fazer o seguinte:
- Crie um dataset e use-o para avaliação, sem um SME.
- Solicite uma sessão de rótulo de um especialista no assunto para selecionar um dataset de avaliação melhor.
Criar um dataset
O exemplo a seguir cria um Dataset e insere avaliações. Para preencher o dataset com avaliações sintéticas, consulte Sintetizar Conjuntos de Avaliação.
from databricks.agents import datasets
import mlflow
# The following call creates an empty dataset. To delete a dataset, use datasets.delete_dataset(uc_table_name).
dataset = datasets.create_dataset("cat.schema.my_managed_dataset")
# Optionally, insert evaluations.
# The `guidelines` specified here are saved to the `expectations` field in the dataset.
eval_set = [{
"request": {"messages": [{"role": "user", "content": "What is the capital of France?"}]},
"guidelines": ["The response must be in English", "The response must be clear, coherent, and concise"],
}]
dataset.insert(eval_set)
Os dados deste dataset são suportados por uma tabela Delta no Unity Catalog e são visíveis no Catalog Explorer.
Diretrizes nomeadas (usando um dicionário) não são atualmente suportadas em uma sessão de rótulo.
Usando um dataset para avaliação
O exemplo a seguir lê o dataset do Unity Catalog, usando o dataset de avaliação para avaliar um agente de prompt de sistema simples.
import mlflow
from mlflow.deployments import get_deploy_client
# Define a very simple system-prompt agent to test against our evaluation set.
@mlflow.trace(span_type="AGENT")
def llama3_agent(request):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={
"messages": [
{"role": "system", "content": SYSTEM_PROMPT},
*request["messages"]
]
}
)
evals = spark.read.table("cat.schema.my_managed_dataset")
mlflow.evaluate(
data=evals,
model=llama3_agent,
model_type="databricks-agent"
)
Criar uma sessão de etiquetagem e enviar para revisão
O exemplo a seguir cria uma LabelingSession do dataset acima usando ReviewApp.create_labeling_session, configurando a sessão
para coletar guidelines e expected_facts de PMEs usando os ReviewApp.label_schemas campo. Você também pode criar esquemas de rótulo personalizados com ReviewApp.create_label_schema
-
Ao criar uma sessão de etiquetagem, os usuários atribuídos são:
- Dada a permissão de GRAVAÇÃO para o experimento MLflow.
- Conceder permissão QUERY a quaisquer endpoints servindo modelo associados ao aplicativo de revisão.
-
Ao adicionar um dataset a uma sessão de rótulo, os usuários atribuídos recebem permissão SELECT para as tabelas delta dos datasets usados para alimentar a sessão de rótulo.
Para conceder permissões a todos os usuários no workspace, defina assigned_users=["users"].
from databricks.agents import review_app
import mlflow
# The review app is tied to the current MLFlow experiment.
my_app = review_app.get_review_app()
# You can use the following code to remove any existing agents.
# for agent in list(my_app.agents):
# my_app.remove_agent(agent.agent_name)
# Add the llama3 70b model serving endpoint for labeling. You should replace this with your own model serving endpoint for your
# own agent.
# NOTE: An agent is required when labeling an evaluation dataset.
my_app.add_agent(
agent_name="llama-70b",
model_serving_endpoint="databricks-meta-llama-3-3-70b-instruct",
)
# Create a labeling session and collect guidelines and/or expected-facts from SMEs.
# Note: Each assigned user is given QUERY access to the serving endpoint above and write access.
# to the MLFlow experiment.
my_session = my_app.create_labeling_session(
name="my_session",
agent="llama-70b",
assigned_users = ["email1@company.com", "email2@company.com"],
label_schemas = [review_app.label_schemas.GUIDELINES, review_app.label_schemas.EXPECTED_FACTS]
)
# Add the records from the dataset to the labeling session.
# Note: Each assigned user above is given SELECT access to the UC delta table.
my_session.add_dataset("cat.schema.my_managed_dataset")
# Share the following URL with your SMEs for them to bookmark. For the given review app linked to an experiment, this URL never changes.
print(my_app.url)
# You can also link them directly to the labeling session URL, however if you
# request new labeling sessions from SMEs there will be new URLs. Use the review app
# URL above to keep a permanent URL.
print(my_session.url)
Neste ponto, pode enviar os URLs acima aos seus SMEs.
Enquanto seu SME está etiquetando, você pode view o status da etiquetagem com o seguinte código:
mlflow.search_traces(run_id=my_session.mlflow_run_id)
Sincronize as expectativas da sessão de rotulagem de volta ao dataset
Depois que o SME concluir a etiquetagem, você pode sincronizar os rótulos expectation de volta ao dataset com LabelingSession.sync_expectations. Exemplos de rótulos com o tipo expectation incluem GUIDELINES, EXPECTED_FACTS ou seu próprio esquema de rótulos personalizado que tem um tipo expectation.
my_session.sync_expectations(to_dataset="cat.schema.my_managed_dataset")
display(spark.read.table("cat.schema.my_managed_dataset"))
Agora você pode usar este dataset de avaliação:
eval_results = mlflow.evaluate(
model=llama3_agent,
data=dataset.to_df(),
model_type="databricks-agent"
)
Colete feedback sobre rastreamentos
Esta seção descreve como coletar rótulos em objetos de rastreamento MLFlow que podem vir de qualquer um dos seguintes:
- Um experimento ou execução do MLflow.
- Uma tabela de inferência.
- Qualquer objeto MLFlow Python Trace.
Colete feedback de um experimento ou execução do MLFlow
Este exemplo cria um conjunto de rastreamentos a serem identificados com um rótulo pelos seus especialistas (SMEs).
import mlflow
from mlflow.deployments import get_deploy_client
@mlflow.trace(span_type="AGENT")
def llama3_agent(messages):
SYSTEM_PROMPT = """
You are a chatbot that answers questions about Databricks.
For requests unrelated to Databricks, reject the request.
"""
return get_deploy_client("databricks").predict(
endpoint="databricks-meta-llama-3-3-70b-instruct",
inputs={"messages": [{"role": "system", "content": SYSTEM_PROMPT}, *messages]}
)
# Create a trace to be labeled.
with mlflow.start_run(run_name="llama3") as run:
run_id = run.info.run_id
llama3_agent([{"content": "What is databricks?", "role": "user"}])
llama3_agent([{"content": "How do I set up a SQL Warehouse?", "role": "user"}])
É possível obter rótulos para o rastreamento e criar uma sessão de etiquetagem a partir deles. Este exemplo configura uma sessão de etiquetagem com um único esquema de rótulo para coletar feedback de "formalidade" na resposta do Agente. Os rótulos do SME são armazenados como uma Avaliação no Rastreamento MLFlow.
Para obter mais tipos de entradas de esquema, consulte SDK databricks-agents.
# The review app is tied to the current MLFlow experiment.
my_app = review_app.get_review_app()
# Use the run_id from above.
traces = mlflow.search_traces(run_id=run_id)
formality_label_schema = my_app.create_label_schema(
name="formal",
# Type can be "expectation" or "feedback".
type="feedback",
title="Is the response formal?",
input=review_app.label_schemas.InputCategorical(options=["Yes", "No"]),
instruction="Please provide a rationale below.",
enable_comment=True
)
my_session = my_app.create_labeling_session(
name="my_session",
# NOTE: An `agent` is not required. If you do provide an Agent, your SME can ask follow up questions in a converstion and create new questions in the labeling session.
assigned_users=["email1@company.com", "email2@company.com"],
# More than one label schema can be provided and the SME will be able to provide information for each one.
# We use only the "formal" schema defined above for simplicity.
label_schemas=["formal"]
)
# NOTE: This copies the traces into this labeling session so that labels do not modify the original traces.
my_session.add_traces(traces)
# Share the following URL with your SMEs for them to bookmark. For the given review app, linked to an experiment, this URL will never change.
print(my_app.url)
# You can also link them directly to the labeling session URL, however if you
# request new labeling sessions from SMEs there will be new URLs. Use the review app
# URL above to keep a permanent URL.
print(my_session.url)
Depois que o PME terminar a etiquetagem, os rastreamentos e avaliações resultantes se tornarão parte da execução associada à sessão de etiquetagem.
mlflow.search_traces(run_id=my_session.mlflow_run_id)
Agora, é possível usar estas avaliações para melhorar o seu modelo ou atualizar o dataset de avaliação.
Encontre respostas de feedback na tabela de inferência
Se seu endpoint tiver tabelas de inferência habilitadas, o Databricks também gravará as respostas de feedback na view de logs de avaliação em:
{catalog_name}.{schema_name}.{model_name}_payload_assessment_logs_view
Esta view substitui a tabela _payload_assessment_logs descontinuada. Para o esquema completo e o status de descontinuação, consulte Tabelas de inferência do agente: Logs de solicitação e avaliação (descontinuadas).
Coletar feedback de uma tabela de inferência
Este exemplo mostra como adicionar rastreamentos diretamente da tabela de inferência (logs de payload de solicitação) em uma sessão de etiquetagem.
# CHANGE TO YOUR PAYLOAD REQUEST LOGS TABLE
PAYLOAD_REQUEST_LOGS_TABLE = "catalog.schema.my_agent_payload_request_logs"
traces = spark.table(PAYLOAD_REQUEST_LOGS_TABLE).select("trace").limit(3).toPandas()
my_session = my_app.create_labeling_session(
name="my_session",
assigned_users = ["email1@company.com", "email2@company.com"],
label_schemas=[review_app.label_schemas.EXPECTED_FACTS]
)
# NOTE: This copies the traces into this labeling session so that labels do not modify the original traces.
my_session.add_traces(traces)
print(my_session.url)
Notebooks de exemplo
Os notebooks a seguir ilustram as diferentes maneiras de usar datasets e sessões de rotulagem na Agent Evaluation.