Desenvolver um agente de AI e implantá-lo no Model Serving
Para novos casos de uso, o Databricks recomenda implantar agentes no Databricks Apps para controle total sobre o código do agente, configuração do servidor e fluxo de trabalho de implantação. Consulte Crie um agente de AI e o tenha implantado no Databricks Apps. Para migrar um agente existente, consulte Migrar um agente do Model Serving para o Databricks Apps.
Esta página mostra como criar um agente de AI em Python usando Agentes Personalizados e bibliotecas populares de criação de agentes como LangGraph e OpenAI.
Requisitos
A Databricks recomenda instalar a versão mais recente do cliente MLflow Python ao desenvolver agentes.
Para criar e implantado agentes usando a abordagem nesta página, instale os seguintes itens:
databricks-agents1.2.0 ou acimamlflow3.1.3 ou acima- Python 3.10 ou acima.
- Use serverless compute ou Databricks Runtime 13.3 LTS acima para atender a este requisito.
%pip install -U -qqqq databricks-agents mlflow
A Databricks também recomenda instalar pacotes de integração do Databricks AI Bridge para criar agentes. Esses pacotes de integração fornecem uma camada compartilhada de APIs que interagem com os recursos de IA do Databricks, como Genie Agents e AI Search, entre frameworks de autoria de agentes e SDKs.
- OpenAI
- LangChain/LangGraph
- DSPy
- Pure Python agents
%pip install -U -qqqq databricks-openai
%pip install -U -qqqq databricks-langchain
%pip install -U -qqqq databricks-dspy
%pip install -U -qqqq databricks-ai-bridge
Use ResponsesAgent para criar agentes
A Databricks recomenda a interface MLflow ResponsesAgent para criar agentes de nível de produção. ResponsesAgent permite que você crie agentes com qualquer framework de terceiros, e os integre aos recursos de AI da Databricks para funcionalidades robustas de registro em log, rastreamento, avaliação, implantação e monitoramento.
O esquema ResponsesAgent é compatível com o esquema OpenAI Responses. Para saber mais sobre OpenAI Responses, consulte OpenAI: Respostas vs. ChatCompletion.
A interface mais antiga ChatAgent ainda tem suporte no Databricks. No entanto, para novos agentes, o Databricks recomenda usar a versão mais recente do MLflow e a interface ResponsesAgent.
Consulte Esquema de agente de entrada e saída legado (Model Serving).

ResponsesAgent oferece as seguintes vantagens:
-
Capacidades avançadas de agente
- Suporte multiagente
- Saída de transmissão : Transmita a saída em blocos menores.
- História abrangente de mensagens de chamada de ferramenta : retorne várias mensagens, incluindo mensagens intermediárias de chamada de ferramenta, para melhor qualidade e gerenciamento de conversas.
- Suporte à confirmação de chamada de ferramenta
- Suporte para ferramentas de longa duração
-
Desenvolvimento, implantação e monitoramento otimizados
- **Crie agentes usando qualquer framework**: Adapte qualquer agente existente usando a
ResponsesAgentinterface para obter compatibilidade imediata com AI Playground, Agent Evaluation e Monitoramento de Agentes. - Interfaces de autoria com tipagem : escreva o código do agente usando classes Python tipadas, beneficiando-se do preenchimento automático da IDE e do Notebook.
- Inferência automática de assinatura : MLflow infere automaticamente
ResponsesAgentassinaturas ao registrar um agente, simplificando o registro e a implantação. Consulte Inferir Assinatura do Modelo durante o registro em log. - Rastreamento automático : O MLflow rastreia automaticamente suas funções
predictepredict_stream, agregando respostas de transmissão para facilitar a avaliação e a exibição. - Tabelas de inferência aprimoradas pelo AI Gateway: As tabelas de inferência do AI Gateway são ativadas automaticamente para agentes implantados, fornecendo acesso a metadados detalhados de log de solicitação.
- **Crie agentes usando qualquer framework**: Adapte qualquer agente existente usando a
Para saber como criar um ResponsesAgent, consulte os exemplos na seção a seguir e a documentação MLflow - ResponsesAgent para Model Serving.
ResponsesAgent exemplos
Os notebooks a seguir mostram como criar ResponsesAgent de transmissão e não transmissão usando bibliotecas populares. Para saber como expandir os recursos desses agentes, consulte Conectar agentes a ferramentas.
- OpenAI
- LangGraph
- DSPy
Agente de chat simples da OpenAI usando modelos hospedados no Databricks
Agente de chamada de ferramentas MCP da OpenAI
Agente de chamada de ferramentas OpenAI usando modelos hospedados no Databricks
Agente de chamada de ferramenta OpenAI usando modelos hospedados pela OpenAI
Agente de chamada de ferramentas LangGraph MCP
Agente DSPy de chamada de ferramenta de turno único
Exemplo multiagente
Para aprender a criar um sistema multiagente, consulte Usar o Genie em sistemas multiagentes (Model Serving).
E se eu já tiver um agente?
Se já tiver um agente criado com LangChain, LangGraph ou um framework similar, não é necessário reescrevê-lo para usá-lo na Databricks. Em vez disso, basta envolver seu agente existente com a interface MLflow ResponsesAgent:
-
Escreva uma classe wrapper Python que herda de
mlflow.pyfunc.ResponsesAgent.Dentro da classe wrapper, referencie o agente existente como um atributo
self.agent = your_existing_agent. -
A classe
ResponsesAgentexige a implementação de um métodopredictque retorna umResponsesAgentResponsepara lidar com solicitações sem transmissão. O seguinte é um exemplo do esquemaResponsesAgentResponses:Pythonimport uuid
# input as a dict
{"input": [{"role": "user", "content": "What did the data scientist say when their Spark job finally completed?"}]}
# output example
ResponsesAgentResponse(
output=[
{
"type": "message",
"id": str(uuid.uuid4()),
"content": [{"type": "output_text", "text": "Well, that really sparked joy!"}],
"role": "assistant",
},
]
) -
Na função
predict, converta as mensagens recebidas deResponsesAgentRequestpara o formato esperado pelo agente. Após o agente gerar uma resposta, converta sua saída para um objetoResponsesAgentResponse.
Consulte os exemplos de código a seguir para ver como converter agentes existentes para ResponsesAgent:
- Basic conversion
- Streaming with code re-use
- Migrate from ChatCompletions
Para agentes sem transmissão, converta as entradas e saídas na função predict.
from uuid import uuid4
from mlflow.pyfunc import ResponsesAgent
from mlflow.types.responses import (
ResponsesAgentRequest,
ResponsesAgentResponse,
)
class MyWrappedAgent(ResponsesAgent):
def __init__(self, agent):
# Reference your existing agent
self.agent = agent
def predict(self, request: ResponsesAgentRequest) -> ResponsesAgentResponse:
# Convert incoming messages to your agent's format
# prep_msgs_for_llm is a function you write to convert the incoming messages
messages = self.prep_msgs_for_llm([i.model_dump() for i in request.input])
# Call your existing agent (non-streaming)
agent_response = self.agent.invoke(messages)
# Convert your agent's output to ResponsesAgent format, assuming agent_response is a str
output_item = (self.create_text_output_item(text=agent_response, id=str(uuid4())),)
# Return the response
return ResponsesAgentResponse(output=[output_item])
Para agentes de transmissão, você pode ser inteligente e reutilizar a lógica para evitar duplicar o código que converte mensagens:
from typing import Generator
from uuid import uuid4
from mlflow.pyfunc import ResponsesAgent
from mlflow.types.responses import (
ResponsesAgentRequest,
ResponsesAgentResponse,
ResponsesAgentStreamEvent,
)
class MyWrappedStreamingAgent(ResponsesAgent):
def __init__(self, agent):
# Reference your existing agent
self.agent = agent
def predict(self, request: ResponsesAgentRequest) -> ResponsesAgentResponse:
"""Non-streaming predict: collects all streaming chunks into a single response."""
# Reuse the streaming logic and collect all output items
output_items = []
for stream_event in self.predict_stream(request):
if stream_event.type == "response.output_item.done":
output_items.append(stream_event.item)
# Return all collected items as a single response
return ResponsesAgentResponse(output=output_items)
def predict_stream(
self, request: ResponsesAgentRequest
) -> Generator[ResponsesAgentStreamEvent, None, None]:
"""Streaming predict: the core logic that both methods use."""
# Convert incoming messages to your agent's format
# prep_msgs_for_llm is a function you write to convert the incoming messages, included in full examples linked below
messages = self.prep_msgs_for_llm([i.model_dump() for i in request.input])
# Stream from your existing agent
item_id = str(uuid4())
aggregated_stream = ""
for chunk in self.agent.stream(messages):
# Convert each chunk to ResponsesAgent format
yield self.create_text_delta(delta=chunk, item_id=item_id)
aggregated_stream += chunk
# Emit an aggregated output_item for all the text deltas with id=item_id
yield ResponsesAgentStreamEvent(
type="response.output_item.done",
item=self.create_text_output_item(text=aggregated_stream, id=item_id),
)
Se o seu agente existente usar a API ChatCompletions do OpenAI, você pode migrá-lo para ResponsesAgent sem reescrever sua lógica central. Adicione um wrapper que:
- Converte as mensagens
ResponsesAgentRequestde entrada para o formatoChatCompletionsque seu agente espera. - Traduz
ChatCompletionssaídas para o esquemaResponsesAgentResponse. - Opcionalmente, oferece suporte à transmissão, mapeando deltas incrementais de
ChatCompletionspara objetosResponsesAgentStreamEvent.
from typing import Generator
from uuid import uuid4
from databricks.sdk import WorkspaceClient
from mlflow.pyfunc import ResponsesAgent
from mlflow.types.responses import (
ResponsesAgentRequest,
ResponsesAgentResponse,
ResponsesAgentStreamEvent,
)
# Legacy agent that outputs ChatCompletions objects
class LegacyAgent:
def __init__(self):
self.w = WorkspaceClient()
self.OpenAI = self.w.serving_endpoints.get_open_ai_client()
def stream(self, messages):
for chunk in self.OpenAI.chat.completions.create(
model="databricks-claude-sonnet-4-5",
messages=messages,
stream=True,
):
yield chunk.to_dict()
# Wrapper that converts the legacy agent to a ResponsesAgent
class MyWrappedStreamingAgent(ResponsesAgent):
def __init__(self, agent):
# `agent` is your existing ChatCompletions agent
self.agent = agent
def prep_msgs_for_llm(self, messages):
# dummy example of prep_msgs_for_llm
# real example of prep_msgs_for_llm included in full examples linked below
return [{"role": "user", "content": "Hello, how are you?"}]
def predict(self, request: ResponsesAgentRequest) -> ResponsesAgentResponse:
"""Non-streaming predict: collects all streaming chunks into a single response."""
# Reuse the streaming logic and collect all output items
output_items = []
for stream_event in self.predict_stream(request):
if stream_event.type == "response.output_item.done":
output_items.append(stream_event.item)
# Return all collected items as a single response
return ResponsesAgentResponse(output=output_items)
def predict_stream(
self, request: ResponsesAgentRequest
) -> Generator[ResponsesAgentStreamEvent, None, None]:
"""Streaming predict: the core logic that both methods use."""
# Convert incoming messages to your agent's format
messages = self.prep_msgs_for_llm([i.model_dump() for i in request.input])
# process the ChatCompletion output stream
agent_content = ""
tool_calls = []
msg_id = None
for chunk in self.agent.stream(messages): # call the underlying agent's stream method
delta = chunk["choices"][0]["delta"]
msg_id = chunk.get("id", None)
content = delta.get("content", None)
if tc := delta.get("tool_calls"):
if not tool_calls: # only accommodate for single tool call right now
tool_calls = tc
else:
tool_calls[0]["function"]["arguments"] += tc[0]["function"]["arguments"]
elif content is not None:
agent_content += content
yield ResponsesAgentStreamEvent(**self.create_text_delta(content, item_id=msg_id))
# aggregate the streamed text content
yield ResponsesAgentStreamEvent(
type="response.output_item.done",
item=self.create_text_output_item(agent_content, msg_id),
)
for tool_call in tool_calls:
yield ResponsesAgentStreamEvent(
type="response.output_item.done",
item=self.create_function_call_item(
str(uuid4()),
tool_call["id"],
tool_call["function"]["name"],
tool_call["function"]["arguments"],
),
)
agent = MyWrappedStreamingAgent(LegacyAgent())
for chunk in agent.predict_stream(
ResponsesAgentRequest(input=[{"role": "user", "content": "Hello, how are you?"}])
):
print(chunk)
Para exemplos completos, consulte exemplos deResponsesAgent.
Respostas de transmissão
A transmissão permite que os agentes enviem respostas em partes em tempo real em vez de esperar pela resposta completa. Para implementar a transmissão com ResponsesAgent, emita uma série de eventos delta seguidos por um evento de conclusão final:
- Emitir eventos delta : Enviar vários eventos
output_text.deltacom o mesmoitem_idpara transmitir blocos de texto em tempo real. - Finalizar com evento de conclusão : Envie um evento
response.output_item.donefinal com o mesmoitem_idque os eventos delta contendo o texto de saída final completo.
Cada evento delta faz uma transmissão de um fragmento de texto para o cliente. O evento de conclusão final contém o texto completo da resposta e sinaliza à Databricks para fazer o seguinte:
- Rastreie a saída do seu agente com o rastreamento do MLflow
- Agregue respostas de transmissão em tabelas de inferência do AI Gateway
- Mostrar a saída completa na UI do AI Playground
Propagação de erros de transmissão
Databricks propaga quaisquer erros encontrados durante a transmissão com o último token em databricks_output.error. Cabe ao cliente chamador lidar e expor esse erro adequadamente.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}
Recursos avançados
Entradas e saídas personalizadas
Alguns cenários podem exigir entradas adicionais do agente, como client_type e session_id, ou saídas como links de fonte de recuperação que não devem ser incluídos na história do chat para interações futuras.
Para esses cenários, o MLflow ResponsesAgent suporta nativamente os campos custom_inputs e custom_outputs. É possível acessar as entradas personalizadas via request.custom_inputs em todos os exemplos linkados acima em Exemplos de Agente de Respostas.
O aplicativo de revisão do Agent Evaluation não oferece suporte à renderização de rastreamentos para agentes com campos de entrada adicionais.
Consulte os seguintes Notebooks para aprender a definir entradas e saídas personalizadas.
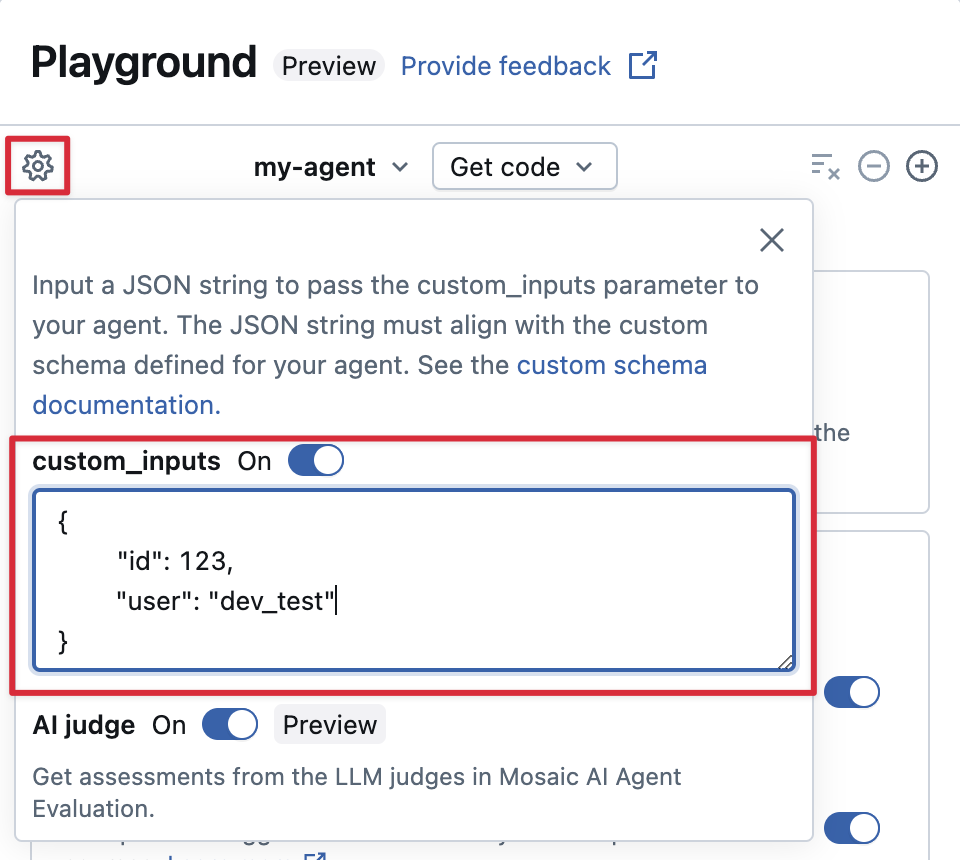
Forneça custom_inputs no AI Playground e no aplicativo de revisão
Se o agente aceitar entradas adicionais usando o campo custom_inputs, é possível fornecer essas entradas manualmente no AI Playground e no aplicativo de avaliação.
-
No AI Playground ou no Aplicativo de Revisão de Agente, selecione o ícone de engrenagem
 .
. -
Habilitar custom_inputs .
-
Forneça um objeto JSON que corresponda ao esquema de entrada definido do seu agente.
Especificar esquemas personalizados do retriever
Agentes de AI comumente usam recuperadores para encontrar e consultar dados não estruturados de índices de Pesquisa de AI. Para ferramentas de recuperador, consulte Conectar agentes a dados não estruturados.
Rastreie esses retrievers em seu agente com intervalos MLflow RETRIEVER para habilitar recursos de produto Databricks, incluindo:
- Exibindo automaticamente links para documentos de origem recuperados na interface do usuário do AI Playground
- Execução automática de avaliadores de fundamentação de recuperação e de relevância em Agent Evaluation
O Databricks recomenda usar ferramentas de recuperação fornecidas pelos pacotes do Databricks AI Bridge, como databricks_langchain.VectorSearchRetrieverTool e databricks_openai.VectorSearchRetrieverTool, porque eles já estão em conformidade com o esquema de recuperação do MLflow. Consulte Desenvolver um recuperador localmente usando o AI Bridge.
Se o seu agente incluir intervalos de retriever com um esquema personalizado, chame mlflow.models.set_retriever_schema ao definir seu agente no código. Isso mapeia as colunas de saída do seu recuperador para os campos esperados do MLflow (primary_key, text_column, doc_uri).
import mlflow
# Define the retriever's schema by providing your column names
# For example, the following call specifies the schema of a retriever that returns a list of objects like
# [
# {
# 'document_id': '9a8292da3a9d4005a988bf0bfdd0024c',
# 'chunk_text': 'MLflow is the largest open source AI engineering platform for agents, LLMs, and ML models...',
# 'doc_uri': 'https://mlflow.org/docs/latest/index.html',
# 'title': 'MLflow: The Largest Open Source AI Engineering Platform'
# },
# {
# 'document_id': '7537fe93c97f4fdb9867412e9c1f9e5b',
# 'chunk_text': 'A great way to get started with MLflow is to use the autologging feature. Autologging automatically logs your model...',
# 'doc_uri': 'https://mlflow.org/docs/latest/getting-started/',
# 'title': 'Getting Started with MLflow'
# },
# ...
# ]
mlflow.models.set_retriever_schema(
# Specify the name of your retriever span
name="mlflow_docs_vector_search",
# Specify the output column name to treat as the primary key (ID) of each retrieved document
primary_key="document_id",
# Specify the output column name to treat as the text content (page content) of each retrieved document
text_column="chunk_text",
# Specify the output column name to treat as the document URI of each retrieved document
doc_uri="doc_uri",
# Specify any other columns returned by the retriever
other_columns=["title"],
)
A coluna doc_uri é especialmente importante ao avaliar o desempenho do recuperador. doc_uri é o principal identificador para documentos retornados pelo recuperador, permitindo que você os compare com conjuntos de avaliação de verdade fundamental. Consulte Conjuntos de avaliação (MLflow 2).
Considerações de implantação
Prepare-se para o Databricks Model Serving
Databricks tem ResponsesAgents implantados em um ambiente distribuído no Databricks Model Serving. Isso significa que, durante uma conversa em vários turnos, a mesma réplica de serviço pode não lidar com todas as solicitações. Preste atenção às seguintes implicações para gerenciar o estado do agente:
-
Evite o cache local : Ao ter um
ResponsesAgentimplantado, não presuma que a mesma réplica lide com todas as solicitações em uma conversa de várias rodadas. Reconstrua o estado interno usando um esquemaResponsesAgentRequestde dicionário para cada turno. -
Estado thread-safe : Projete o estado do agente para ser thread-safe, evitando conflitos em ambientes multi-threaded.
-
Inicialize o estado na função
predict: Inicialize o estado sempre que a funçãopredictfor chamada, não durante a inicialização deResponsesAgent. Armazenar o estado no nível deResponsesAgentpoderia vazar informações entre conversas e causar conflitos, pois uma única réplica deResponsesAgentpoderia lidar com solicitações de várias conversas.
Parametrizar código para implantação em vários ambientes
Parametrizar o código do agente para reutilizar o mesmo código do agente em diferentes ambientes.
Os parâmetros são pares chave-valor que você define em um dicionário no Python ou em um arquivo .yaml.
Para configurar o código, crie um ModelConfig usando um dicionário Python ou um arquivo .yaml. ModelConfig é um conjunto de parâmetros key-valor que permite um gerenciamento de configuração flexível. Por exemplo, você pode usar um dicionário durante o desenvolvimento e então convertê-lo em um arquivo .yaml para implantação em produção e CI/CD.
Um exemplo ModelConfig é mostrado abaixo:
llm_parameters:
max_tokens: 500
temperature: 0.01
model_serving_endpoint: databricks-meta-llama-3-3-70b-instruct
vector_search_index: ml.docs.databricks_docs_index
prompt_template: 'You are a hello world bot. Respond with a reply to the user''s
question that indicates your prompt template came from a YAML file. Your response
must use the word "YAML" somewhere. User''s question: {question}'
prompt_template_input_vars:
- question
No código do seu agente, você pode referenciar uma configuração default (desenvolvimento) do arquivo ou dicionário .yaml:
import mlflow
# Example for loading from a .yml file
config_file = "configs/hello_world_config.yml"
model_config = mlflow.models.ModelConfig(development_config=config_file)
# Example of using a dictionary
config_dict = {
"prompt_template": "You are a hello world bot. Respond with a reply to the user's question that is fun and interesting to the user. User's question: {question}",
"prompt_template_input_vars": ["question"],
"model_serving_endpoint": "databricks-meta-llama-3-3-70b-instruct",
"llm_parameters": {"temperature": 0.01, "max_tokens": 500},
}
model_config = mlflow.models.ModelConfig(development_config=config_dict)
# Use model_config.get() to retrieve a parameter value
# You can also use model_config.to_dict() to convert the loaded config object
# into a dictionary
value = model_config.get('sample_param')
Então, ao fazer log de seu agente, especifique o parâmetro model_config para log_model para especificar um conjunto personalizado de parâmetros a serem usados ao carregar o agente que teve log feito. Consulte a documentação do MLflow - ModelConfig.
Use código síncrono ou padrões de retorno de chamada
Para garantir estabilidade e compatibilidade, use código síncrono ou padrões baseados em callback na implementação do seu agente.
O Databricks gerencia automaticamente a comunicação assíncrona para fornecer simultaneidade e desempenho ideais ao ter um agente implantado. A introdução de loops de evento personalizados ou frameworks assíncronos pode levar a erros como RuntimeError: This event loop is already running and caused unpredictable behavior.
A Databricks recomenda evitar a programação assíncrona, como o uso de asyncio ou a criação de loops de evento personalizados, ao desenvolver agentes.