Teste de carga do seu agente Databricks Apps
O teste de carga determina o máximo de queries por segundo (QPS) que seu agente do Databricks Apps pode sustentar antes que o desempenho se degrade. Esta página mostra como fazer o seguinte:
- Implante uma versão simulada do seu agente para isolar a taxa de transferência da infraestrutura da latência do LLM.
- Realize uma execução de teste de carga de rampa até a saturação com Locust.
- Analise os resultados com um dashboard interativo.
Você pode seguir o caminho assistido por AI usando uma habilidade do Claude Code, ou configurar cada o passo manualmente.
Requisitos
- Um workspace Databricks com Databricks Apps habilitado.
- Um aplicativo de agente implantado (ou pronto para ser implantado) no Databricks Apps usando o SDK de Agentes OpenAI, LangGraph ou uma estrutura personalizada. Consulte Criar um agente de AI e implantá-lo no Databricks Apps.
- A CLI do Databricks instalada e autenticada. Consulte Instalar ou atualizar a CLI do Databricks.
- Python 3.10+ com o
uvgerenciador de pacotes. - (Para o caminho assistido por AI) Claude Code instalado.
- (Para testes de carga com duração superior a ~1 hora) Uma entidade de serviço com credenciais OAuth M2M (
client_ideclient_secret). Consulte Autorize o acesso da entidade de serviço ao Databricks com OAuth.- Para testes de carga curtos (menos de ~1 hora), suas credenciais OAuth de usuário (U2M) existentes de
databricks auth loginfuncionam bem. Para testes mais longos, use OAuth M2M com uma entidade de serviço do Databricks — os tokens U2M expiram durante execuções longas e causam falhas no meio do teste. A criação de uma entidade de serviço do Databricks requer acesso de administrador do workspace.
- Para testes de carga curtos (menos de ~1 hora), suas credenciais OAuth de usuário (U2M) existentes de
Configuração assistida por AI (recomendado)
Se você usar o Claude Code, a habilidade /load-testing automatiza o fluxo de trabalho. Ele lê o código do seu agente, gera um simulado, cria scripts de teste de carga e o orienta na implantação.
Diga ao Claude Code para fazer isso por você:
Clone https://github.com/databricks/app-templates and run the /load-testing skill against the {your-template} template.
Ou siga os passos abaixo.
O passo 1: Clonar um padrão de agente
A skill /load-testing está incluída no repositórios databricks/app-templates, tanto como a skill agent-load-testing de nível superior quanto pré-sincronizada em cada padrão de agente individual. Se você já tiver um projeto do app-templates, você já terá a skill.
Clone o repo e mude para o diretório padrão para o agente que você deseja testar a carga:
git clone https://github.com/databricks/app-templates.git
cd app-templates/{your-template}
O passo 2: a execução da habilidade de teste de carga
No Claude Code, execução:
/load-testing
A habilidade o guia interativamente pelos os passos. Pode-se ignorar a simulação para testar o agente real, ou ignorar a implantação caso os aplicativos já estejam em execução.
- Coleta de parâmetros : pergunta sobre seu status de implantação, tamanhos de compute, configurações de worker e credenciais OAuth.
- Criação de scripts de teste de carga : gera
locustfile.py,run_load_test.pyedashboard_template.pyadaptados ao seu projeto. - Simulando seu LLM : cria um cliente simulado específico para seu SDK (SDK de Agentes OpenAI, LangGraph ou personalizado) que substitui chamadas reais de LLM por atrasos de transmissão configuráveis.
- **Implantação de aplicativos de teste**: guia você pela implantação de múltiplas configurações de aplicativos com diferentes tamanhos de compute e contagens de worker.
- Executando testes : executa o teste de carga com autenticação OAuth M2M e ramp-to-saturation.
- Gerando resultados : produz um painel HTML interativo com QPS, latência e métricas de falha.
Configuração manual
Siga os passos para configurar e realizar a execução de testes de carga sem assistência de AI.
O passo 1: Simule as chamadas de LLM do seu agente (opcional)
Ignore este o passo se desejar resultados de ponta a ponta que incluam a latência real do LLM. Para medir a Taxa de transferência da infraestrutura do Databricks Apps isoladamente, simule o LLM para que a sua latência por solicitação (geralmente 1-30 segundos) não se torne o gargalo.
Um mock retorna respostas pré-definidas com um atraso de transmissão configurável, preservando o pipeline completo de solicitação/resposta (transmissão SSE, despacho de ferramenta, runner SDK) e trocando apenas o LLM. Isso expõe o QPS máximo que a plataforma Databricks Apps pode entregar e evita custos de tokens da API do Foundation Model durante testes de carga.
O tempo simulado é controlado por duas variáveis de ambiente:
Variável | Padrão | Descrição |
|---|---|---|
|
| Atraso em milissegundos entre blocos de texto de transmissão |
|
| Número de blocos de texto por resposta |
Com o default, cada resposta simulada leva aproximadamente 800 ms (10 ms x 80 chunks), significativamente mais rápido do que uma resposta real de LLM (3–15 segundos). Os números de taxa de transferência refletem a plataforma, não o modelo.
Crie um cliente simulado que substitui o cliente LLM real. O restante do código do seu agente permanece inalterado, e a abordagem depende do seu SDK. Para a OpenAI, consulte a implementação de referênciamock_openai_client.py em databricks/app-templates. O mesmo padrão se adapta a outros SDKs.
- OpenAI Agents SDK
- LangGraph
- Custom agents
Crie agent_server/mock_openai_client.py — uma classe MockAsyncOpenAI que implementa chat.completions.create() com transmissão. Ele retorna blocos de chamada de ferramenta instantaneamente (simulando o LLM decidindo chamar uma ferramenta) e blocos de resposta de texto com atraso configurável das variáveis de ambiente MOCK_CHUNK_DELAY_MS e MOCK_CHUNK_COUNT.
Swap-o em seu agente:
from agent_server.mock_openai_client import MockAsyncOpenAI
from agents import set_default_openai_client, set_default_openai_api
set_default_openai_client(MockAsyncOpenAI())
set_default_openai_api("chat_completions")
O restante do seu código de agente (manipuladores, ferramentas, lógica de transmissão) permanece inalterado.
Substitua o modelo ChatDatabricks por um mock que retorna objetos AIMessage pré-fabricados:
# Before:
# model = ChatDatabricks(endpoint="databricks-claude-sonnet-4")
# After:
from agent_server.mock_llm import MockChatModel
model = MockChatModel()
O mock deve retornar AIMessage objetos com chamadas de ferramenta na primeira invocação e conteúdo de texto em invocações subsequentes, com atrasos de transmissão configuráveis.
Involva quaisquer chamadas de API externas que seu agente faça (LLM, AI Search, APIs de ferramentas) com implementações simuladas que retornam formas de resposta realistas com atrasos configuráveis.
Etapa 2: Configurar scripts de teste de carga
Crie um diretório load-test-scripts/ em seu projeto. O framework de teste de carga consiste em três scripts que são agnósticos ao framework e funcionam com qualquer agente de Databricks Apps.
<project-root>/
agent_server/ # Your existing agent code
load-test-scripts/ # Load testing scripts (create this)
run_load_test.py # CLI orchestrator
locustfile.py # Locust test with SSE streaming + TTFT tracking
dashboard_template.py # Interactive HTML dashboard generator
load-test-runs/ # Results (auto-created per run)
<run-name>/
dashboard.html # Interactive dashboard
test_config.json # Test parameters for reproducibility
<label>/ # Per-config Locust CSV output
A estrutura inclui os seguintes arquivos:
locustfile.py: Um teste de carga Locust que enviaPOST /invocationssolicitações comstream: true, analisa transmissões SSE, rastreia o tempo para o primeiro token (TTFT) como uma métrica personalizada, usa troca de tokens OAuth M2M com refresh automático e implementa umStepRampShapeque aumenta o número de usuários destep_sizeparamax_users, mantendo cada nível porstep_durationsegundos.run_load_test.py** **: Um orquestrador de CLI que testa cada URL de aplicativo sequencialmente com métricas isoladas por configuração. Ele lida com o refresh de tokens OAuth, executa uma verificação de integridade e aquecimento antes de cada teste e salva os resultados emload-test-runs/<run-name>/<label>/.dashboard_template.py** **: Gera um painel HTML autocontido usando Chart.js com cartões de KPI, gráficos de barras (QPS, latência, TTFT por configuração), gráficos de linha de progressão de rampa de QPS e uma tabela de resultados completa. Pode ser feito em execução:uv run dashboard_template.py ../load-test-runs/<run-name>/.
Instalar dependências
Os scripts de teste de carga usam seu próprio pyproject.toml dentro de load-test-scripts/ para evitar contaminar as dependências de produção do seu agente. Criar load-test-scripts/pyproject.toml:
[project]
name = "load-test-scripts"
version = "0.1.0"
requires-python = ">=3.10"
dependencies = [
"locust>=2.32,<2.40",
"urllib3<2.3",
"requests",
]
Pin locust em <2.40. Versões mais recentes (>=2.43) têm um RecursionError conhecido que causa falha em testes de carga longos.
Instale a partir do diretório load-test-scripts/:
cd load-test-scripts/
uv sync
O passo 3: Aplicativos de teste implantados com configurações variadas
Implante vários Databricks Apps com diferentes tamanhos de compute e contagens de worker para encontrar a configuração ideal para sua carga de trabalho.
Matriz de teste recomendada
As configurações abaixo concentram-se no ponto ideal identificado em testes anteriores. Se você quiser uma cobertura mais ampla, adicione uma configuração de cada lado (por exemplo, medium-w1 ou large-w12), mas as seis abaixo geralmente são suficientes.
Tamanho de compute | Workers | Nome de aplicativo sugerido |
|---|---|---|
Médio | 2 |
|
Médio | 3 |
|
Médio | 4 |
|
Grande | 6 |
|
Grande | 8 |
|
Grande | 10 |
|
Configurar tamanho de compute
Use a CLI do Databricks para definir o tamanho do compute ao criar ou atualizar um aplicativo:
# Create a new app with Medium compute
databricks apps create <app-name> --compute-size MEDIUM
# Update an existing app to Large compute
databricks apps update <app-name> --compute-size LARGE
Configure a contagem de worker com Pacotes de Automação Declarativa
start-server (via AgentServer.run()) aceita um sinalizador --workers diretamente. Passe a contagem de worker na matriz command usando uma variável DAB:
variables:
app_name:
default: 'my-agent-medium-w2'
workers:
default: '2'
resources:
apps:
load_test_app:
name: ${var.app_name}
source_code_path: .
config:
command: ['uv', 'run', 'start-server', '--workers', '${var.workers}']
env:
- name: MOCK_CHUNK_DELAY_MS
value: '10'
- name: MOCK_CHUNK_COUNT
value: '80'
targets:
medium-w2:
default: true
variables:
app_name: 'my-agent-medium-w2'
workers: '2'
large-w8:
variables:
app_name: 'my-agent-large-w8'
workers: '8'
Implantar e verificar
Implante cada destino com a CLI do Databricks:
databricks bundle deploy --target medium-w2
databricks bundle run load_test_app --target medium-w2
Verifique se os aplicativos estão ativos antes de executar testes de carga:
databricks apps get <app-name> --output json | jq '{app_status, compute_status, url}'
Aguarde que todos os aplicativos atinjam o status ACTIVE antes de prosseguir. Aplicativos que ainda estão iniciando produzem resultados enganosos.
O passo 4: execução de testes de carga
Configurar autenticação
Selecione a sua autenticação com base na duração planejada da execução:
- Testes curtos (menos de ~1 hora) : use suas credenciais de usuário existentes de
databricks auth login. Nenhuma configuração extra necessária. - Testes longos (com mais de aproximadamente 1 hora, como execuções noturnas): use o OAuth M2M com uma entidade de serviço do Databricks. Os tokens U2M expiram e interrompem seu teste no meio da execução. A criação de uma entidade de serviço do Databricks exige acesso de administrador do workspace.
Para OAuth M2M, exporte as credenciais da entidade de serviço do Databricks antes de executar os testes:
export DATABRICKS_HOST=https://your-workspace.cloud.databricks.com
export DATABRICKS_CLIENT_ID=<your-client-id>
export DATABRICKS_CLIENT_SECRET=<your-client-secret>
Referência de parâmetros
Parâmetro | Obrigatório | Padrão | Descrição |
|---|---|---|---|
| Sim | — | URL(s) do aplicativo para testar (repetível) |
| Para testes longos |
| ID de cliente da entidade de serviço (M2M OAuth) |
| Para testes longos |
| Segredo do cliente da entidade de serviço (M2M OAuth) |
| Não | Derivado automaticamente da URL | Rótulo legível por humanos por aplicativo (repetível) |
| Não | Detectado automaticamente ou | Tag de tamanho de compute por aplicativo: |
| Não |
| Número máximo de usuários simulados concorrentes |
| Não |
| Usuários adicionados por o passo de rampa |
| Não |
| Segundos por o passo de rampa. |
| Não |
| Taxa de geração de usuários (usuários/seg) |
| Não |
| Nome para esta execução — resultados salvos em |
| Não | Desativada | Gerar dashboard HTML interativo após a conclusão dos testes |
Exemplos de comandos
Teste rápido de aplicativo único (execução curta — usa sua sessão databricks auth login):
cd load-test-scripts/
uv run run_load_test.py \
--app-url https://my-app.aws.databricksapps.com \
--dashboard --run-name quick-test
Matriz completa nas 6 configurações recomendadas (execução longa — passar credenciais M2M). Passe --compute-size sinalizadores na mesma ordem que --app-url:
uv run run_load_test.py \
--app-url https://my-app-medium-w2.aws.databricksapps.com \
--app-url https://my-app-medium-w3.aws.databricksapps.com \
--app-url https://my-app-medium-w4.aws.databricksapps.com \
--app-url https://my-app-large-w6.aws.databricksapps.com \
--app-url https://my-app-large-w8.aws.databricksapps.com \
--app-url https://my-app-large-w10.aws.databricksapps.com \
--compute-size medium --compute-size medium --compute-size medium \
--compute-size large --compute-size large --compute-size large \
--client-id $DATABRICKS_CLIENT_ID \
--client-secret $DATABRICKS_CLIENT_SECRET \
--dashboard --run-name overnight-sweep
Várias execuções para consistência estatística:
for RUN in r1 r2 r3 r4 r5; do
uv run run_load_test.py \
--app-url https://my-app.aws.databricksapps.com \
--client-id $DATABRICKS_CLIENT_ID \
--client-secret $DATABRICKS_CLIENT_SECRET \
--max-users 1000 --step-size 20 --step-duration 10 \
--run-name my_test_${RUN} --dashboard || break
done
O que acontece durante uma execução
- Verificação de integridade : verifica se o aplicativo faz a transmissão corretamente (recebe
[DONE]). - Aquecimento : envia solicitações sequenciais para aquecer o aplicativo.
- Rampa para saturação : aumenta os passos de usuários concorrentes a cada
step_durationsegundos. - Detecção de saturação : quando o QPS atinge um platô, apesar de adicionar mais usuários, você atingiu o limite da taxa de transferência.
Duração estimada
Cada aplicativo em teste passa por sua própria rampa, de modo que o tempo total de execução escala com o número de configurações em sua matriz. Use a fórmula abaixo para planejar sua janela de execução.
Duração por aplicativo: (max_users / step_size) * step_duration segundos.
Com defaults (--max-users 300 --step-size 20 --step-duration 30):
- 15 os passos x 30 segundos = aproximadamente 7,5 minutos por aplicativo
- Para a matriz recomendada de 6 configurações: aproximadamente 45 minutos por execução
O passo 5: View e interpretar resultados
-
Abrir o painel:
Bashopen load-test-runs/<run-name>/dashboard.html -
(Opcional) Regenerar o painel a partir de dados existentes, por exemplo, após atualizar o padrão:
Bashcd load-test-scripts/
uv run dashboard_template.py ../load-test-runs/<run-name>/
Seções do painel
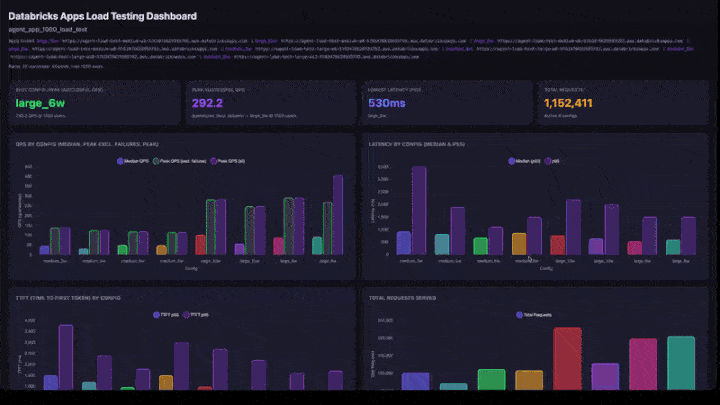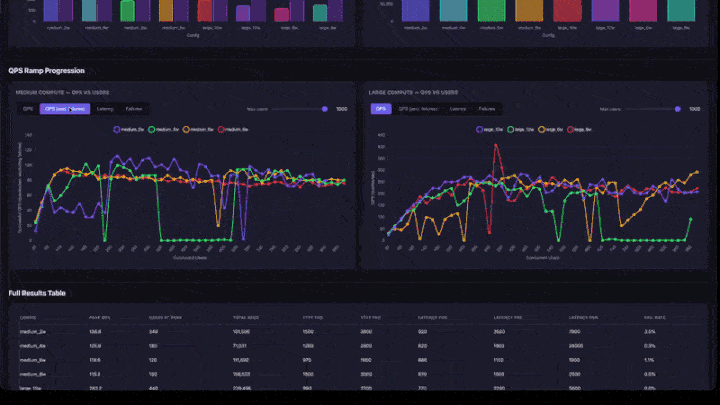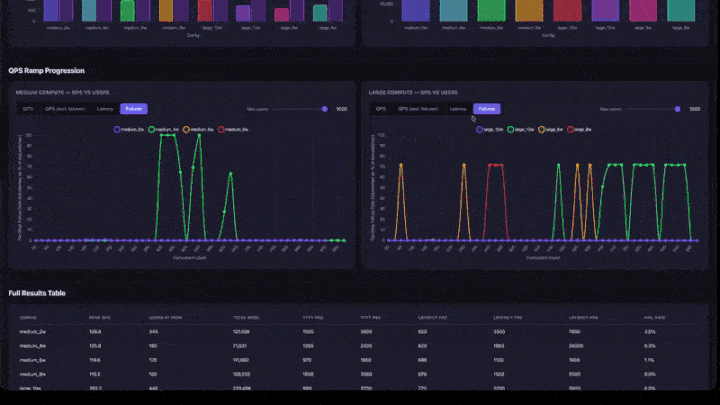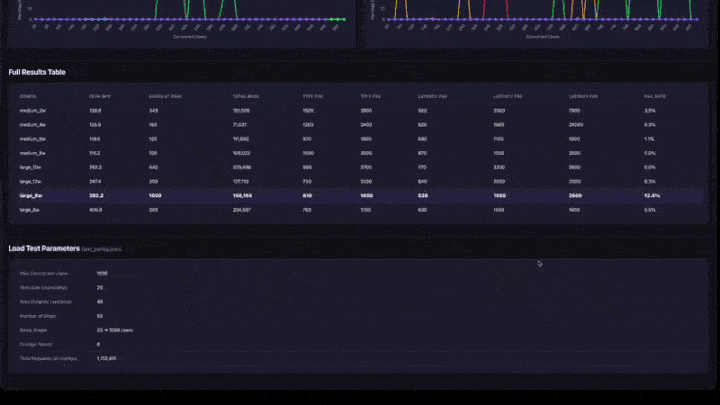
O dashboard interativo inclui:
- Cartões KPI : melhor configuração (por QPS de pico bem-sucedido), QPS de pico geral, menor latência e total de solicitações atendidas.
- QPS por Configuração : gráfico de barras agrupadas mostrando QPS mediana, QPS de pico excluindo falhas e QPS de pico lado a lado para cada configuração.
- Latência por Configuração : barras agrupadas mostrando latência p50 e p95.
- TTFT por Configuração : tempo até o primeiro token (p50 e p95).
- Total de solicitações atendidas: contagem de solicitações por configuração.
- Progressão de Rampa de QPS : gráficos de linha com tabs para QPS, QPS (excluindo falhas), Latência e Falhas. Inclui um controle deslizante de usuários máximos para aprofundar-se nos intervalos de simultaneidade mais baixos. Os gráficos são agrupados por tamanho de compute (médio e grande lado a lado).
- Tabela de Resultados Completos : todas as configurações com QPS de pico, usuários no pico, percentis de latência e taxa de falha.
- Parâmetros de Teste : resumo da configuração para reprodutibilidade.
Como interpretar os resultados
- QPS de pico : o QPS máximo alcançado em qualquer o passo de rampa. Este é o limite da taxa de transferência para essa configuração.
- Usuários de pico : o número de usuários concorrentes quando o pico de QPS foi atingido. Adicionar mais usuários além deste ponto não aumenta a taxa de transferência.
- Taxa de Falha : deve ser 0% ou muito baixa. Uma alta taxa de falha significa que o aplicativo está sobrecarregado nesse nível de simultaneidade.
- Gráfico de rampa de QPS : observe onde a linha se estabiliza. Este é o ponto de saturação: adicionar mais usuários não aumentará a taxa de transferência.
Referência de execução de benchmark em dados sintéticos
Esta seção relata o que uma execução de benchmark interno do Databricks mediu em relação a um aplicativo de agente sintético, onde cada chamada de LLM foi simulada. É um exercício separado do teste de carga do seu próprio agente: use-o para ver o formato dos resultados que você pode esperar e para obter um ponto de partida aproximado para o dimensionamento.
O que esta execução mostrou
- Ponto de partida recomendado : 2 workers em compute Médio, ou 8 workers em compute Grande.
- **Mais workers nem sempre é melhor.** No Medium, 2 workers (155,1 QPS) superam 4 workers (116,5 QPS) em aproximadamente 33%. A carga de trabalho simulada é limitada pela CPU, portanto, após 2 workers, há contenção de CPU/memória que anula o paralelismo extra. Um agente IO-bound real que espera principalmente por um Endpoint de modelo pode escalar mais do que esta simulação, portanto, certifique-se de testar seu próprio agente.
- Tamanho do compute : o Grande entregou aproximadamente 2,2x o throughput do Médio (278,0 vs 123,5 de pico médio de QPS).
- Latência : Grande apresentou desempenho ~20% menor que Médio (~906 ms vs 1.180 ms p50), com TTFT de ~1.100 ms em Grande vs 1.720-1.820 ms em Médio.
- **Confiabilidade**: a taxa de falha permaneceu em ou perto de 0% para todas as configurações, mesmo com 1.000 usuários concorrentes.
Como o LLM foi simulado (transmissão simulada com atrasos fixos por chunk), esses são números de throughput da infraestrutura, e não números de agente de ponta a ponta. Eles medem quantos requests o FastAPI AgentServer do Databricks Apps pode processar em paralelo, e não a latência de um modelo real. Um agente de produção que chama um endpoint de LLM ativo apresenta QPS mais baixo e latência mais alta, dominado pelo tempo de resposta do modelo. Os seus próprios números variam com a complexidade do agente, tamanho da carga útil, chamadas de ferramentas, região e o endpoint do modelo que você chama. Para um dimensionamento preciso, execute um teste de carga em seu próprio agente.
Os resultados tabelados abaixo mostram o detalhamento completo por configuração.
Condições de teste
- **Execução de referência**: 5 rodadas idênticas contra 8 configurações de aplicativo (4 compute médio, 4 compute grande), cada uma com uma contagem diferente de workers uvicorn.
- Rampa : 20 a 1.000 usuários concorrentes, em os passos de 20 usuários mantidos por 10 segundos cada (50 os passos por configuração).
- Agente de simulação : transmissão de respostas de aproximadamente 95 blocos por solicitação, simulando a transmissão de tokens LLM.
- Volume : cerca de 1,46 milhão de solicitações totais em todas as execuções.
Pico de QPS por configuração
O QPS de pico é calculado a média das 5 execuções.
Tamanho de compute | Workers | QPS de pico médio | Faixa de pico | Taxa de falha |
|---|---|---|---|---|
Médio | 2 | 155,1 | 137,0–166,6 | 0,0% |
Médio | 4 | 116,5 | 112,6–121,8 | 0,1% |
Médio | 6 | 111,9 | 102,6–117,5 | 0,0% |
Médio | 8 | 110,3 | 108,3–112,1 | 0,0% |
Grande | 6 | 281,6 | 268,2–292,4 | 0,0% |
Grande | 8 | 268,2 | 265,8–271,0 | 0,0% |
Grande | 10 | 288,1 | 280,3–299,4 | 0,0% |
Grande | 12 | 274,2 | 269,4–278,8 | 0,0% |
Média por tamanho de compute:
Tamanho de compute | QPS de pico médio | QPS médio |
|---|---|---|
Médio | 123,5 | 45,5 |
Grande | 278,0 | 100,1 |
Nesta execução, o compute grande entregou aproximadamente 2,2x o throughput do compute médio.
Solução de problemas
Problema | soluções |
|---|---|
O tokens de autenticação expirou no meio do teste | Para testes com duração superior a cerca de 1 hora, mude de U2M para M2M OAuth passando |
Falha na verificação de integridade | Verifique se o aplicativo está ATIVO: |
0 QPS ou nenhum resultado | Verifique se há erros em |
Baixo QPS apesar do alto número de usuários | O aplicativo está saturado. Experimente mais workers ou compute maior. |
Alta taxa de falha | O aplicativo está sobrecarregado. Reduza |
O painel não mostra dados de rampa. | Verifique se |
Recursos adicionais
- Teste com chamadas reais de LLM : ignore o passo de simulação e implante seu agente real para medir a latência de ponta a ponta, incluindo o tempo de resposta do LLM.
- Ajustar contagem de workers : use os resultados da matriz de teste para encontrar a contagem ideal de workers para o tamanho do seu compute.
- Tutorial: Avaliar e melhorar um aplicativo GenAI para medir a precisão, relevância e segurança, juntamente com a taxa de transferência.
- Coloque seu agente de Databricks Apps em produção para a sequência completa de prontidão de produção, incluindo o AI Gateway.