Configurar o AI Gateway no endpoint modelo servindo
Experimente a nova versão beta do Unity AI Gateway.
Uma nova experiência do Unity AI Gateway está disponível em Beta. O novo Unity AI Gateway é o plano de controle corporativo para governar o endpoint LLM e os agentes de codificação com recurso aprimorado. Consulte Governança de AI com Unity AI Gateway.
Neste artigo, você aprenderá como configurar AI Gateway em um endpoint do modelo de serviço.
Requisitos
-
Um Databricks workspace em uma região onde o servindo modelo é suportado. Veja a disponibilidade do modelo de recurso servindo.
-
A servindo o modelo endpoint. O senhor pode usar um dos endpoints pré-configurados de pay-per-tokens em seu site workspace ou fazer o seguinte:
- Para criar um endpoint para modelos externos, conclua as etapas 1 e 2 de Criar um modelo de serviço externo endpoint.
- Para criar um endpoint para provisionamento Taxa de transferência, consulte provisionamento Taxa de transferência Foundation Model APIs.
- Para criar um endpoint para um modelo personalizado, consulte Criar um endpoint.
-
Operações de administrador de endpoint exigem
CAN MANAGEnesse endpoint. Ver Listas de controle de acesso. -
Na criação, o criador recebe
CAN MANAGEno novo endpoint. -
Para evitar o desvio de guardrails ou limites de taxa de transferência, restrinja a criação de endpoints e
CAN MANAGEa administradores, e conceda a outros usuários apenas permissões de consulta em endpoints aprovados.
Configure o Unity AI Gateway usando a interface do usuário.
Na seção AI Gateway da página de criação endpoint , você pode configurar individualmente o recurso do Unity AI Gateway. Consulte Recurso suportado para quais recursos estão disponíveis em endpoint de modelo de operação externa e provisionamento Taxa de transferência de endpoint.
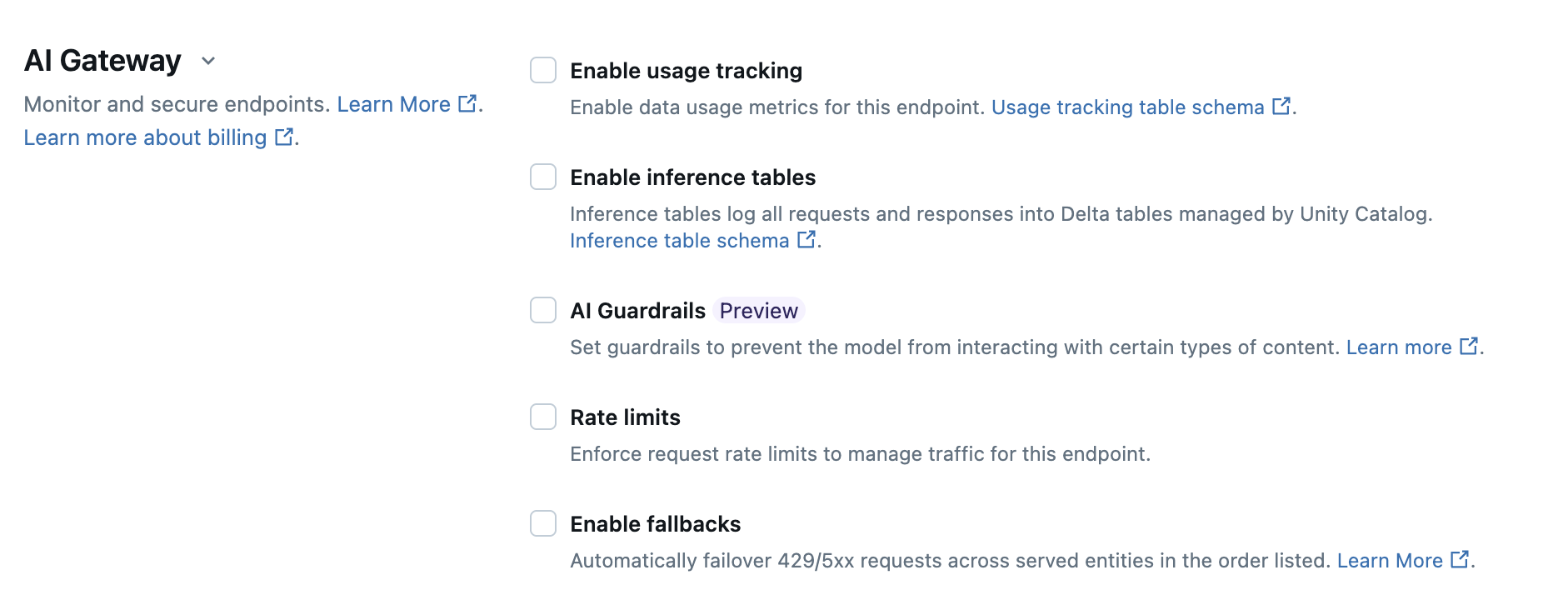
A tabela a seguir resume como configurar o Unity AI Gateway durante a criação endpoint usando a interface de usuário Serving UI. Se preferir fazer isso programaticamente, veja o exemplo no Notebook.
Recurso | Como habilitar | Detalhes |
|---|---|---|
Uso acompanhamento | Selecione Ativar acompanhamento de uso para ativar o acompanhamento e o monitoramento do uso de dados métricos. |
|
Registro de carga útil | Selecione Enable inference tables (Ativar tabelas de inferência ) para automaticamente log solicitações e respostas de seu endpoint em Delta tabelas gerenciadas por Unity Catalog. |
|
| ||
Limites de taxa | Selecione Limites de taxa para gerenciar e especificar o número de consultas por minuto (QPM) ou tokens por minuto (TPM) que seu endpoint pode suportar.
|
|
Divisão de tráfego | Na seção Entidades atendidas , especifique a porcentagem do tráfego que você deseja que seja roteado para modelos específicos. Para configurar a divisão de tráfego em seu endpoint de forma programática, consulte Servir vários modelos externos a um endpoint. |
|
recuo | Selecione Enable fallback (Ativar fallback ) na seção AI Gateway para enviar sua solicitação a outros modelos atendidos no endpoint como um fallback. |
|
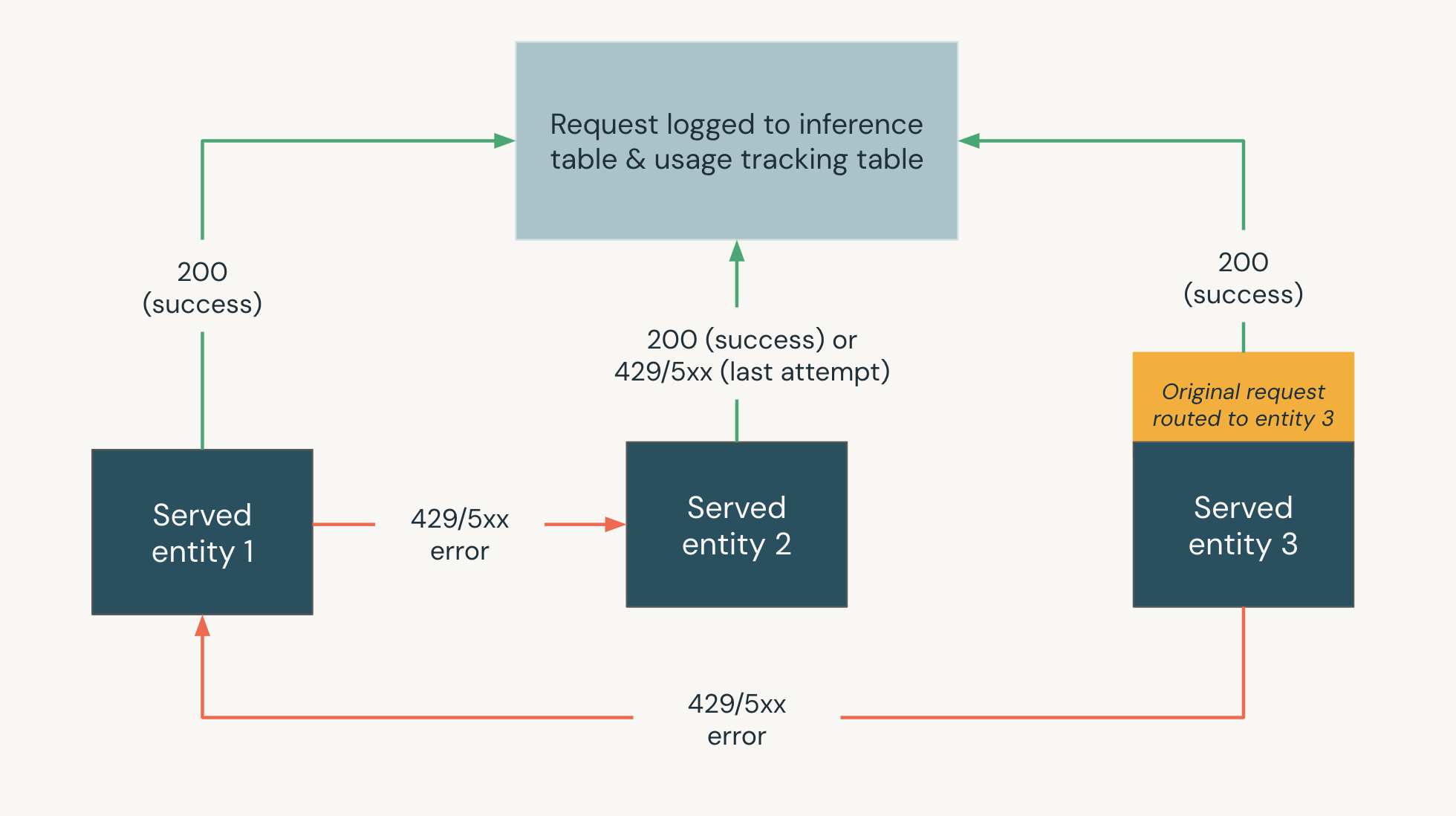
O diagrama a seguir mostra um exemplo de fallback em que o senhor é o único a ter acesso,
- Três entidades atendidas são atendidas em um modelo de atendimento endpoint.
- A solicitação foi originalmente roteada para a entidade servida 3 .
- Se a solicitação retornar uma resposta 200, a solicitação foi bem-sucedida na entidade Served 3 e a solicitação e sua resposta serão registradas nas tabelas de acompanhamento de uso e de registro de carga útil do site endpoint.
- Se a solicitação retornar um erro 429 ou 5xx na entidade atendida 3 , a solicitação voltará para a próxima entidade atendida no site endpoint, entidade atendida 1 .
- Se a solicitação retornar um erro 429 ou 5xx na entidade atendida 1 , a solicitação voltará para a próxima entidade atendida no site endpoint, entidade atendida 2 .
- Se a solicitação retornar um erro 429 ou 5xx na entidade servida 2 , a solicitação falhará, pois esse é o número máximo de entidades de retorno. A solicitação com falha e o erro de resposta são registrados nas tabelas de acompanhamento de uso e de registro de carga útil.
Configurar AI Guardrails na interface do usuário
Visualização
Esse recurso está em Public Preview.
A tabela a seguir mostra como configurar os guardrails suportados.
Guardrail | Como habilitar |
|---|---|
Segurança | Selecione Segurança para ativar salvaguardas para impedir que seu modelo interaja com conteúdo inseguro e prejudicial. |
Detecção de informações de identificação pessoal (PII) | Selecione para bloquear ou mascarar dados de PII, como nomes, endereços, números de cartão de crédito, se essas informações forem detectadas nas solicitações e respostas do site endpoint. Caso contrário, selecione Nenhum para que nenhuma detecção de PII ocorra. |

Uso de esquemas de tabelas de acompanhamento
As seções a seguir resumem os esquemas de tabela de acompanhamento de uso para as tabelas de sistema system.serving.served_entities e system.serving.endpoint_usage.
system.serving.served_entities uso acompanhamento esquema de tabela
A tabela do sistema de acompanhamento de uso system.serving.served_entities tem o seguinte esquema:
Nome da coluna | Descrição | Tipo |
|---|---|---|
| O ID exclusivo da entidade atendida. | String |
| O ID do account do cliente para o OpenSharing. | String |
| O cliente workspace ID do serviço endpoint. | String |
| O nome do criador. Pode ser o nome de um usuário, de uma entidade de serviço ou de um grupo. Para o endpoint de pagamento por tokens, isto é | String |
| O nome do endpoint de serviço. | String |
| A ID exclusiva do endpoint de atendimento. | String |
| O nome da entidade atendida. | String |
| Tipo da entidade que é atendida. Pode ser | String |
| O nome subjacente da entidade. Diferente do | String |
| A versão da entidade servida. | String |
| A versão da configuração do site endpoint. | INT |
| O tipo de tarefa. Pode ser | String |
| Configurações para modelos externos. Por exemplo, | struct |
| Configurações para modelos de fundação. Por exemplo, | struct |
| Configurações para modelos personalizados. Por exemplo, | struct |
| Configurações para especificações de recurso. Por exemplo, | struct |
| Carimbo de data e hora da mudança para a entidade atendida. | Timestamp |
| Carimbo de data e hora da exclusão da entidade. O endpoint é o contêiner da entidade atendida. Depois que o endpoint é excluído, a entidade servida também é excluída. | Timestamp |
system.serving.endpoint_usage uso acompanhamento esquema de tabela
A tabela do sistema de acompanhamento de uso system.serving.endpoint_usage tem o seguinte esquema:
Nome da coluna | Descrição | Tipo |
|---|---|---|
| O cliente account ID. | String |
| O cliente workspace id do serviço endpoint. | String |
| O identificador de solicitação fornecido pelo usuário que pode ser especificado no corpo da solicitação do modelo de serviço. Para o endpoint de modelo personalizado, não há suporte para solicitações maiores que 4 MiB. | String |
| Um identificador de solicitação gerado pelo site Databricks anexado a todas as solicitações de servindo modelo. | String |
| O ID do usuário ou da entidade de serviço cujas permissões são usadas para a solicitação de invocação do serviço endpoint. | String |
| O código de status HTTP que foi retornado do modelo. | Integer |
| A data e hora em que a solicitação é recebida. | Timestamp |
| A contagem de tokens da entrada. Isso será 0 para solicitações de modelos personalizados. | Long |
| A contagem de tokens da saída. Isso será 0 para solicitações de modelos personalizados. | Long |
| A contagem de caracteres das strings de entrada ou prompt. Isso será 0 para solicitações de modelos personalizados. | Long |
| A contagem de caracteres das strings de saída da resposta. Isso será 0 para solicitações de modelos personalizados. | Long |
| O mapa fornecido pelo usuário contendo identificadores do usuário final ou do aplicativo do cliente que faz a chamada para o endpoint. Consulte Definir melhor o uso com | Mapa |
| Se a solicitação está no modo de transmissão. | Booleana |
| O ID exclusivo usado para join com a tabela de dimensão | String |
Defina ainda mais o uso com usage_context
Ao consultar um modelo externo com o acompanhamento de uso ativado, o senhor pode fornecer o parâmetro usage_context com o tipo Map[String, String]. O mapeamento do contexto de uso aparece na tabela de acompanhamento de uso na coluna usage_context. O tamanho do mapa usage_context não pode exceder 10 KiB.
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
Se estiver usando o cliente OpenAI Python, o senhor pode especificar o endereço usage_context incluindo-o no parâmetro extra_body.
from openai import OpenAI
client = OpenAI(
api_key="dapi-your-databricks-token",
base_url="https://example.staging.cloud.databricks.com/serving-endpoints"
)
response = client.chat.completions.create(
model="databricks-claude-sonnet-4-5",
messages=[{"role": "user", "content": "What is Databricks?"}],
temperature=0,
extra_body={"usage_context": {"project": "project1"}},
)
answer = response.choices[0].message.content
print("Answer:", answer)
Os administradores de conta podem agregar diferentes linhas com base no contexto de uso para obter percepções e podem join essas informações com as informações na tabela de registro de carga útil. Por exemplo, o senhor pode adicionar end_user_to_charge ao usage_context para acompanhar a atribuição de custos para os usuários finais.
Monitorar o uso do endpoint
Para monitorar o uso do endpoint, o senhor pode join as tabelas do sistema e as tabelas de inferência do seu endpoint.
unir tabelas do sistema
Este exemplo se aplica a endpoints externos, de provisionamento de taxa de transferência, de pagamento por tokens e de modelo personalizado.
Para join as tabelas de sistema endpoint_usage e served_entities, use o seguinte SQL:
SELECT * FROM system.serving.endpoint_usage as eu
JOIN system.serving.served_entities as se
ON eu.served_entity_id = se.served_entity_id
WHERE created_by = "\<user_email\>";
Atualizar recurso do Unity AI Gateway no endpoint
Você pode atualizar o recurso do Unity AI Gateway no endpoint do modelo de serviço que o tinha habilitado anteriormente e no endpoint que não o tinha. As atualizações nas configurações do Unity AI Gateway levam cerca de 20 a 40 segundos para serem aplicadas, porém as atualizações com limitação de taxa podem levar até 60 segundos.
A seguir, mostraremos como atualizar um recurso do Unity AI Gateway em um endpoint do modelo Servindo usando a interface de usuário Serving UI.
Na seção Gateway da página do endpoint , você pode ver quais recursos estão habilitados. Para atualizar esses recursos, clique em Editar Unity AI Gateway .

Notebook exemplo
O seguinte Notebook demonstra como habilitar e usar programaticamente o recurso Databricks Unity AI Gateway para gerenciar e governar modelos de provedores. Consulte o PUT /api/2.0/serving-endpoint/{name}/AI-gateway Para obter detalhes sobre a API REST.