Configure os endpoints do Unity AI Gateway
Beta
Este recurso está em Beta. Administradores de conta podem controlar o acesso a este recurso na página Prévias do console da conta. Consulte Gerenciar prévias do Databricks.
Esta página descreve como configurar os endpoints do Unity AI Gateway.
Requisitos
- Prévia do Unity AI Gateway ativada para sua account. Consulte Gerenciar prévias do Databricks.
- Um workspace do Databricks em uma região suportada pelo Unity AI Gateway.
- Unity Catalog habilitado para seu workspace. Consulte Ativar um workspace para o Unity Catalog.
- Operações de administração de endpoint exigem
CAN MANAGEnesse endpoint. Consulte listas de controle de acesso. - Na criação, o criador recebe
CAN MANAGEno novo endpoint. - Para evitar o desvio de mecanismos de proteção ou limites de taxa de transferência, restrinja a criação de endpoints e
CAN MANAGEa administradores, e conceda a outros usuários apenas permissões de query em endpoints aprovados.
Criar um endpoint do Unity AI Gateway
Para criar um endpoint do Unity AI Gateway:
- Na barra lateral, clique em AI Gateway .
- Clique em **Criar Endpoint do Unity AI Gateway**.
- Configure o nome do seu endpoint e o modelo principal.
- Clique em Criar .
Configurar recursos em um endpoint
Você pode atualizar os endpoints do Unity AI Gateway para ativar e desativar recursos. As atualizações nas configurações do Unity AI Gateway levam até 1 minuto para entrar em vigor.
Para atualizar os recursos do Unity AI Gateway em um endpoint existente:
- Na página do AI Gateway, clique no seu endpoint.
- Na barra lateral Detalhes do endpoint do Gateway, clique no ícone Editar ao lado do recurso que deseja atualizar.
- Faça suas alterações e clique em **Salvar**.
A tabela a seguir resume os recursos disponíveis do Unity AI Gateway e como configurá-los:
Recurso | Como configurar | Detalhes |
|---|---|---|
Habilitado por default. |
| |
Selecione Habilitar tabelas de inferência para log solicitações e respostas. |
| |
Selecione Limites de taxa para configurar queries por minuto (QPM) ou tokens por minuto (TPM). |
| |
Proteções | Selecione **Guardrails** para configurar políticas de conteúdo. |
|
Fallbacks | Selecione Adicionar modelo de fallback para configurar modelos de fallback. |
|
Divisão de tráfego | Selecione **Adicionar divisão de tráfego** para distribuir solicitações entre vários backends de modelo. |
|
APIs personalizadas | Selecione API Personalizada ao criar um endpoint para se conectar a uma API externa. |
|
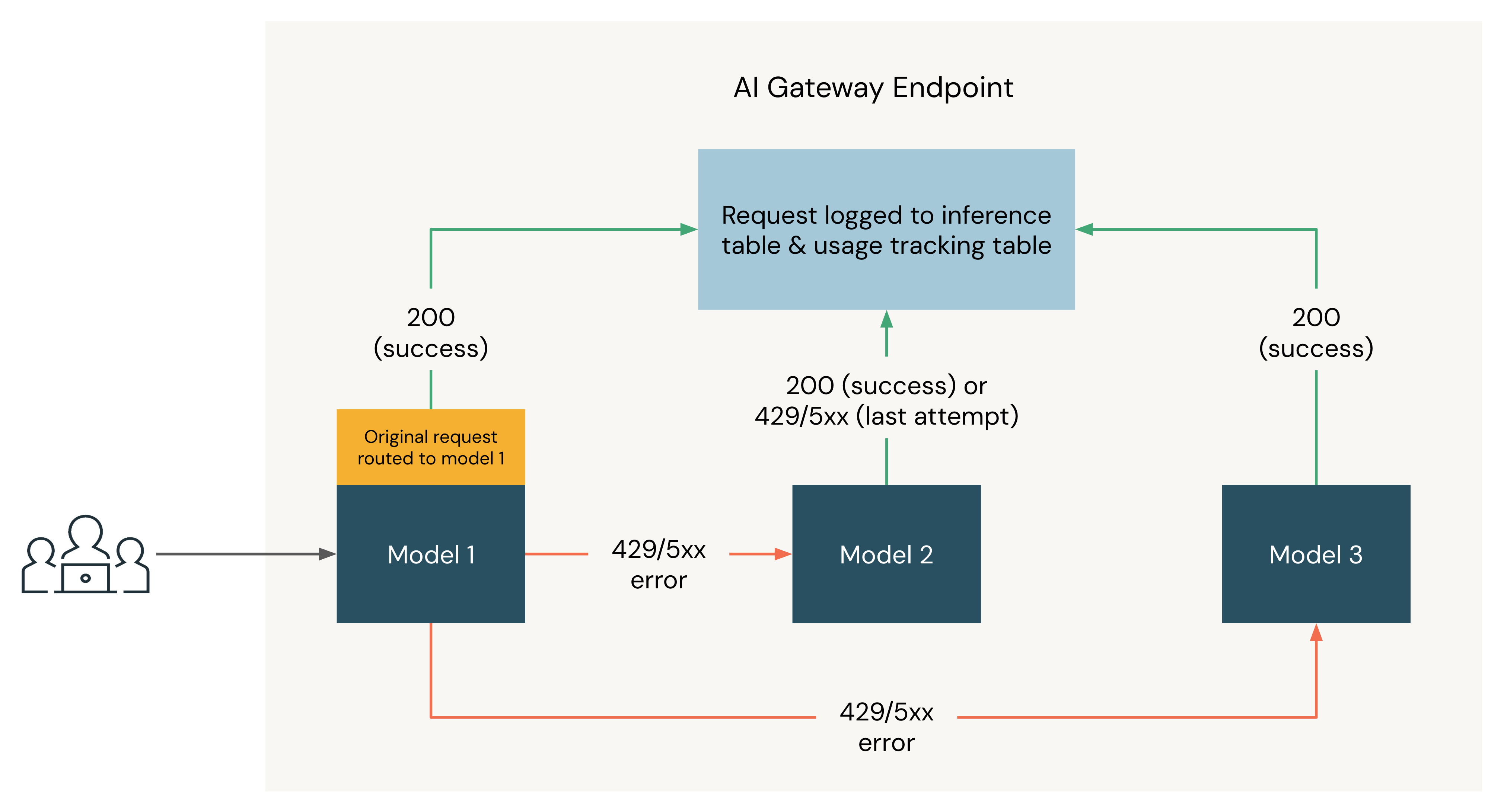
O diagrama a seguir mostra um exemplo de fallback onde três modelos estão registrados como destinos de um endpoint do Unity AI Gateway:
- A solicitação é originalmente roteada para o Modelo 1.
- Se a solicitação retornar uma resposta 200, a solicitação foi bem-sucedida no Modelo 1, e a solicitação e sua resposta serão registradas em log nas tabelas de acompanhamento de uso e de inferência.
- Se a solicitação retornar um erro
429ou5XXno Modelo 1, a solicitação recorre ao próximo modelo no endpoint, o Modelo 2. - Se a solicitação retornar um erro
429ou5XXno Modelo 2, a solicitação recorrerá ao próximo modelo no endpoint, o Modelo 3. - Se a solicitação retornar um erro
429ou5XXno Modelo 3, a solicitação falhará, pois todos os modelos de fallback foram tentados. A solicitação falha e o erro de resposta são registrados nas tabelas de acompanhamento de uso e de inferência.