Uso de modelo para serviços de Gateway Unity AI
Beta
Este recurso está em Beta. Administradores de conta podem controlar o acesso a este recurso na página Prévias do console da conta. Consulte Gerenciar prévias do Databricks.
Esta página descreve como monitorar o uso dos serviços do Unity AI Gateway usando a tabela do sistema de acompanhamento de uso.
A tabela de acompanhamento de uso captura automaticamente os detalhes de solicitação e resposta de um serviço de modelo, registrando métricas essenciais como uso de tokens e latência. É possível usar os dados nesta tabela para monitorar usuários, acompanhar custos e obter percepções sobre o desempenho e o consumo do serviço de modelo.
O acompanhamento de uso também captura solicitações de ai_query para serviços de modelo fornecidos pelo Databricks.
Requisitos
- A prévia no nível da conta do Unity AI Gateway deve ser habilitada para sua conta. Um administrador de account habilita esta prévia na página Prévias do console da account antes que você possa usar o acompanhamento de uso ou o painel de uso integrado. Consulte Gerenciar prévias do Databricks.
- Um workspace do Databricks em uma região suportada pelo Unity AI Gateway.
- Unity Catalog habilitado para seu workspace. Consulte Ativar um workspace para o Unity Catalog.
Consultar a tabela de uso
O Unity AI Gateway log os dados de uso na tabela do sistema system.ai_gateway.usage. Você pode visualizar a tabela na interface de usuário, ou consultar a tabela do Databricks SQL ou de um Notebook.
Somente administradores do account têm permissão para view ou consultar a tabela system.ai_gateway.usage.
Para view a tabela na interface do usuário, clique no link da tabela de acompanhamento de uso na página do serviço de modelo para abrir a tabela no Explorador de Catálogos.
Para consultar a tabela do Databricks SQL ou de um Notebook:
SELECT * FROM system.ai_gateway.usage;
Genie Code (modo Agente) pode fazer isso por você. Experimente este exemplo de prompt:
Query the system.ai_gateway.usage table to analyze AI Gateway usage showing request count and total tokens, grouped by endpoint name for the last 7 days.
Dashboard de uso integrada
Alguns workspaces ainda não mostram o dropdown Govern . Nesses workspaces, use os botões independentes Criar Dashboard , Visualizar Dashboard e Atualizar na página do Unity AI Gateway em vez disso.
Criar painel de uso integrado
Admins de account podem criar um dashboard de uso integrado do Unity AI Gateway para monitorar o uso, rastrear os custos e obter percepções sobre o desempenho e o consumo do serviço de modelo. Na página do Unity AI Gateway, clique em Govern no canto superior direito e, em seguida, clique em Create Usage Dashboard . O warehouse que executa as queries do dashboard é selecionado automaticamente.
A criação de dashboards é restrita a administradores de account porque requer permissões SELECT na tabela system.ai_gateway.usage. Os dados do dashboard estão sujeitos às políticas de retenção da tabela usage. Consulte Quais tabelas do sistema estão disponíveis?.
Quando uma versão mais recente do painel de uso integrado estiver disponível, administradores de account podem clicar em **Atualizar** na linha da versão do painel no **dropdown** **Gerenciar** na página do Unity AI Gateway.
É possível usar as seguintes opções de configuração do painel para gerenciar o painel:
- Escopo: Selecione se deseja definir o escopo do painel na account ou no workspace.
- Permissões : Escolha se as consultas serão de execução com base nas permissões do proprietário do painel ou nas permissões de cada visualizador. Consulte O que são permissões de dados compartilhados?.
- Atualizações automáticas : quando você habilita esta opção, o painel atualiza automaticamente sempre que uma versão mais recente se torna disponível e um administrador de conta visita a página do Unity AI Gateway.
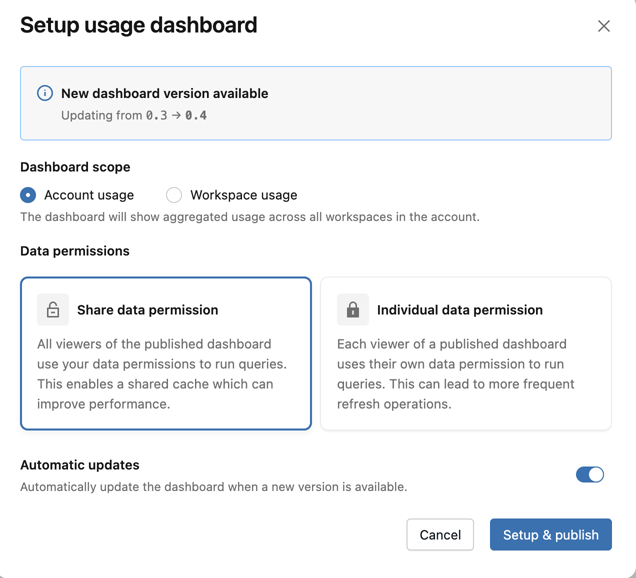
Quando o painel é atualizado para a versão 0.3 ou superior, uma programação é criada automaticamente para refresh o painel a cada 6 horas. Se necessário, este programar pode ser desativado no painel Lakeview. Consulte Criar um programar.
view painel de uso
Para visualizar o dashboard, clique em Governar no canto superior direito da página do Unity AI Gateway e, em seguida, clique em Painel de Uso . O painel abre em uma nova tab. O dashboard integrado oferece visibilidade abrangente do uso, desempenho e custo do serviço de modelo do Unity AI Gateway. Inclui várias páginas de acompanhamento de requisições, consumo de tokens, métricas de latência, taxas de erro, detalhamentos de custo, tráfego do servidor MCP externo e atividade do agente de codificação.
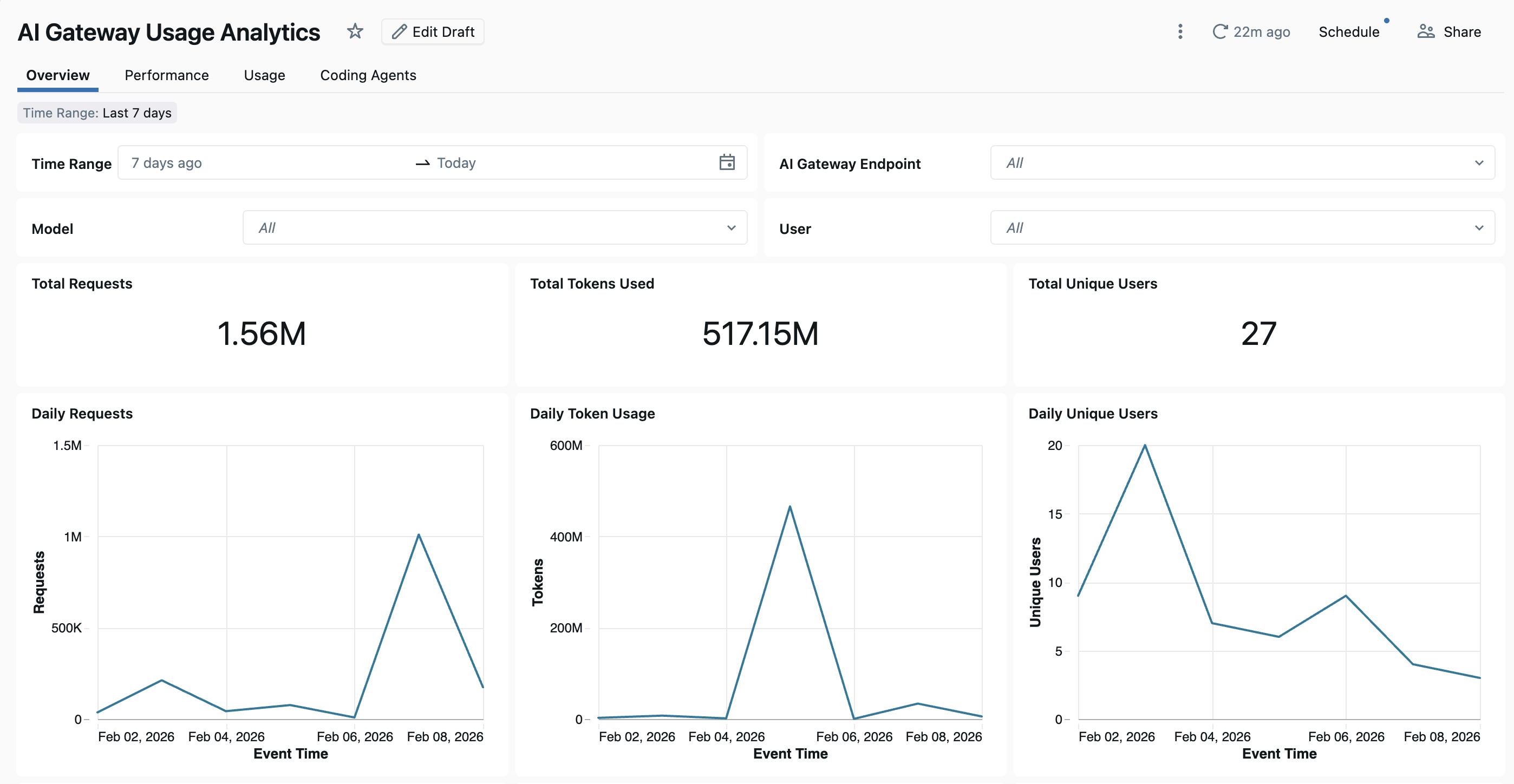
O dashboard fornece analítica entre workspaces por default. Todas as páginas do dashboard podem ser filtradas por intervalo de datas e ID do workspace.
- Tab Visão Geral : Exibe métricas de uso de alto nível, incluindo volume diário de solicitações, tendências de uso de tokens ao longo do tempo, principais usuários por consumo de tokens e contagens totais de usuários únicos. Use esta tab para obter um Snapshot rápido da atividade geral do Unity AI Gateway e identificar os usuários e modelos mais ativos.
- Tab de desempenho : Acompanha as key métricas de desempenho, incluindo percentis de latência (P50, P90, P95, P99), tempo até o primeiro byte, taxas de erro e distribuições de código de status HTTP. Use esta tab para monitorar a integridade do serviço de modelo e identificar gargalos de desempenho ou problemas de confiabilidade.
- Tab Uso : Mostra detalhamentos de consumo detalhados por serviço de modelo, workspace e solicitante. Esta tab mostra padrões de uso de tokens, distribuições de solicitações e taxas de acerto de cache.
- Tab de Observabilidade de Custo : Mostra a discriminação de custos por serviço de modelo, modelo de destino, usuário, tags de serviço e tags de solicitação. Esta tab também inclui o custo estimado para modelos externos. Consulte Monitorar o custo do Unity AI Gateway.
- Tab do Servidor MCP Externo : mostra o volume de solicitações, taxas de erro, usuários e conexões, e tendências de uso diário para o tráfego do servidor MCP externo.
- Tab Agentes de codificação : rastreia a atividade de agentes de codificação integrados, incluindo Cursor, Claude Code, Gemini CLI e Codex CLI. Esta tab mostra métricas como dias ativos, sessões de codificação, commits e linhas de código adicionadas ou removidas para monitorar o uso de ferramentas do desenvolvedor. Consulte o painel de agentes de codificação para obter mais detalhes.
Esquema da tabela de uso
A tabela system.ai_gateway.usage tem o seguinte esquema:
Nome da coluna | Tipo | Descrição | Exemplo |
|---|---|---|---|
| String | O ID da account. |
|
| String | O ID do workspace. |
|
| String | Um identificador exclusivo para a solicitação. |
|
| String | Um identificador exclusivo para cada chamada de inferência individual. Múltiplas invocações podem compartilhar o mesmo |
|
| Integer | A versão do esquema do registro de uso. |
|
| String | O ID exclusivo do serviço de modelo do Unity AI Gateway. |
|
| String | O nome do serviço de modelo do Unity AI Gateway. |
|
| Mapa | Tags configuradas no serviço de modelo no momento da criação ou atualização. Eles se aplicam a todas as solicitações para o serviço de modelo e são úteis para categorizar serviços por equipe, centro de custo ou projeto. |
|
| struct | Metadados do serviço de modelo, incluindo |
|
| Timestamp | O carimbo de data/hora quando a solicitação foi recebida. |
|
| Long | A latência total em milissegundos. |
|
| Long | O tempo para o primeiro byte em milissegundos. |
|
| String | O tipo de destino (por exemplo, modelo externo ou modelo básico). |
|
| String | O nome do modelo ou provedor de destino. |
|
| String | A ID exclusiva do destino. |
|
| String | O modelo específico utilizado para a solicitação. |
|
| String | O ID do usuário ou da entidade de serviço que fez a solicitação. |
|
| String | O tipo de solicitante (usuário, entidade de serviço ou grupo de usuários). |
|
| String | O endereço IP do solicitante. |
|
| String | A URL da solicitação. |
|
| String | O agente do usuário do solicitante. |
|
| String | O tipo de chamada de API (por exemplo, chat, conclusões ou incorporações). |
|
| Mapa | Tags fornecidas pelo usuário enviadas com solicitações individuais usando o cabeçalho HTTP |
|
| struct | Metadados gerados pelo sistema sobre a chamada de inferência. Contém |
|
| Long | O número de tokens de entrada. |
|
| Long | O número de tokens de saída. |
|
| Long | O número total de tokens (entrada + saída). |
|
| struct | Detalhamento de tokens, incluindo |
|
| String | O tipo de conteúdo da resposta. |
|
| INT | O código de status HTTP da resposta. |
|
| struct | Detalhes de roteamento para tentativas de fallback. Contém um array |
|
Solicitações de tag para acompanhamento de uso
Tags de solicitação são pares key-value personalizados que o chamador anexa a solicitações individuais. Use tags de solicitação para atribuir o uso por projeto, equipe, ambiente, usuário final ou qualquer outra dimensão relevante para sua organização. Tags de solicitação são registradas na tabela system.ai_gateway.usage e podem ser usadas para filtrar, agregar e analisar dados de uso.
Para adicionar tag a solicitações individuais, inclua o cabeçalho HTTP Databricks-Ai-Gateway-Request-Tags com um objeto JSON que mapeia key de strings para valores de strings. As tags de solicitação são registradas na coluna request_tags na tabela de uso e em tabelas de inferência.
Para exemplos que mostram como definir tags de solicitação com a API REST, OpenAI SDK e Anthropic SDK, consulte Tag de solicitações para acompanhamento de uso.
Por exemplo, pode agregar o uso por projeto usando tags de solicitação:
SELECT
request_tags['project'] AS project,
COUNT(*) AS request_count,
SUM(total_tokens) AS total_tokens
FROM system.ai_gateway.usage
WHERE request_tags['project'] IS NOT NULL
GROUP BY request_tags['project']
ORDER BY total_tokens DESC;
Limitações
- O Unity AI Gateway não rastreia o uso de tokens para respostas não transmissão e sem embedding maiores que 1 MiB.