Como a Databricks impõe o isolamento do usuário?
Esta página explica como o Databricks usa o Lakeguard para impor o isolamento do usuário em ambientes compute compartilhados e o controle de acesso refinado em compute dedicado.
O que é Lakeguard?
Lakeguard é um conjunto de tecnologias no Databricks que impõe isolamento de código e filtragem de dados para que vários usuários possam compartilhar o mesmo recurso compute de forma segura e econômica, além de acessar dados com controles de acesso detalhados implementados na compute , oferecendo acesso privilegiado à máquina.
Como funciona o Lakeguard?
Em ambientes de compute compartilhado, como compute clássico padrão, Serverless compute e SQL Warehouse, o Lakeguard isola o código do usuário do mecanismo Spark e de outros usuários. Esse design permite que muitos usuários compartilhem os mesmos recursos de compute, mantendo limites rígidos entre usuários, o driver Spark e os executores. Como esse isolamento está em vigor, o compute padrão pode impor nativamente controles de acesso detalhados, como filtros de linha e máscaras de coluna.
O compute dedicado usa a arquitetura Spark clássica, onde o código do usuário não é isolado do mecanismo, portanto, ele não pode impor controles de acesso detalhados no local sem o risco de excesso de busca. Em vez disso, o compute dedicado delega a filtragem de dados para o compute serverless do seu workspace, que é isolado pelo Lakeguard e realiza a filtragem em seu nome. É por isso que o controle de acesso detalhado no compute dedicado exige que seu workspace esteja habilitado para compute serverless. Consulte Controle de acesso detalhado em compute dedicado.
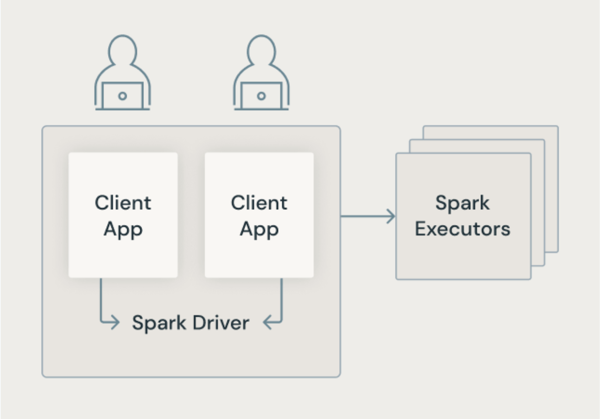
Arquitetura clássica do Spark
A imagem a seguir mostra como, na arquitetura tradicional do Spark, os aplicativos de usuário compartilham uma JVM com acesso privilegiado à máquina subjacente.
Arquitetura Lakeguard
O Lakeguard isola todo o código do usuário usando contêineres seguros. Isso permite que várias cargas de trabalho sejam executadas no mesmo recurso compute, mantendo o isolamento estrito entre os usuários.
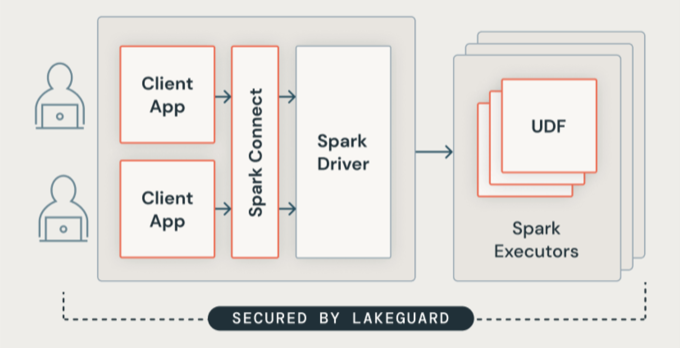
Isolamento do cliente Spark
O Lakeguard isola os aplicativos clientes do driver Spark e uns dos outros usando dois componentes key:
- Spark Connect : O Lakeguard usa o Spark Connect (introduzido com o Apache Spark 3.4) para desacoplar os aplicativos clientes do driver. Os aplicativos clientes e os drivers não compartilham mais o mesmo JVM ou classpath. Essa separação impede o acesso não autorizado aos dados. Esse design também impede que os usuários acessem dados resultantes da busca excessiva quando as consultas incluem filtros em nível de linha ou coluna.
O Spark Connect adia a análise e a resolução de nomes para o momento da execução, o que pode alterar o comportamento do seu código. Veja Comparar Spark Connect com Spark Classic.
- Sandbox de contêiner : cada aplicativo cliente é executado em seu próprio ambiente de contêiner isolado. Isso impede que o código do usuário acesse os dados de outros usuários ou a máquina subjacente. O sandbox usa técnicas de isolamento baseadas em contêineres para criar limites seguros entre os usuários.
Isolamento do UDF
Em default, o executor Spark não isola os UDFs. Essa falta de isolamento pode permitir que os UDFs gravem arquivos ou acessem a máquina subjacente.
O Lakeguard isola o código definido pelo usuário, incluindo UDFs, no executor Spark:
- colocar em sandbox o ambiente de execução no executor Spark.
- Isolar o tráfego de saída da rede dos UDFs para impedir o acesso externo não autorizado.
- Replicar o ambiente do cliente no site UDF sandbox para que os usuários possam acessar a biblioteca necessária.
Esse isolamento se aplica aos UDFs no armazém padrão compute e aos UDFs Python nos armazéns serverless compute e SQL.