Crie um arquivo JAR Scala usando Declarative Automation Bundles.
Este artigo descreve como construir, implementar e executar um JAR Scala com pacotes de automação declarativa. Para obter informações sobre pacotes, consulte O que são pacotes de automação declarativa?.
Por exemplo, a configuração que cria um arquivo Java JAR e o carrega Unity Catalog para,consulte o pacote que carrega um JAR arquivo Unity Catalog para.
Requisitos
Este tutorial requer que seu workspace Databricks atenda aos seguintes requisitos:
- Unity Catalog está ativado. Consulte Ativar um workspace para Unity Catalog.
- O senhor deve ter um volume Unity Catalog em Databricks onde deseja armazenar os artefatos de compilação e permissões para upload o JAR para um caminho de volume especificado. Consulte Criar e gerenciar volumes do Unity Catalog.
- computesem servidor está ativado. Certifique-se de revisar as limitações do recurso compute serverless .
- Seu workspace está em uma região compatível.
Além disso, seu ambiente de desenvolvimento local deve ter os seguintes itens instalados:
- Kit de Desenvolvimento Java (JDK) 17
- IntelliJ IDEA
- SBT
- Databricks CLI versão 0.218.0 ou acima. Para verificar a versão instalada do Databricks CLI, execute o comando
databricks -v. Para instalar a CLI do Databricks, consulte Instalar ou atualizar a CLI do Databricks. - A autenticação da CLI do Databricks está configurada com um perfil
DEFAULT. Para configurar a autenticação, consulte Configurar o acesso ao seu workspace.
Etapa 1: criar o pacote
Primeiro, crie o pacote usando o comando `bundle init` e o padrão de pacote do projeto Scala .
O padrão de pacote JAR Scala cria um pacote que constrói um JAR, o carrega para o volume especificado e define um Job com uma tarefa Spark com o JAR que é executada em compute serverless . O Scala no projeto Padrão define uma UDF Definida pelo Usuário) que aplica transformações simples a um DataFrame de exemplo e exibe os resultados. A fonte do padrão está no repositório bundle-examples.
-
Execute o seguinte comando em uma janela de terminal em sua máquina de desenvolvimento local. Ele solicita o valor de alguns campos obrigatórios.
Bashdatabricks bundle init default-scala -
Para obter um nome para o projeto, digite
my_scala_project. Isso determina o nome do diretório raiz desse pacote. Esse diretório raiz é criado dentro do seu diretório de trabalho atual. -
Para o caminho de destino dos volumes, forneça o caminho dos volumes do Unity Catalog no Databricks onde o senhor deseja que seja criado o diretório do pacote que conterá o JAR e outros artefatos, por exemplo,
/Volumes/my-catalog/my-schema/bundle-volumes.
O projeto Padrão configura compute serverless , mas se você alterá-lo para usar compute clássica, seu administrador poderá precisar adicionar o caminho do JAR de volumes especificado à lista de permissões. Consulte a biblioteca Allowlist e o script de inicialização no compute com acesso padrão (anteriormente modo de acesso compartilhado).
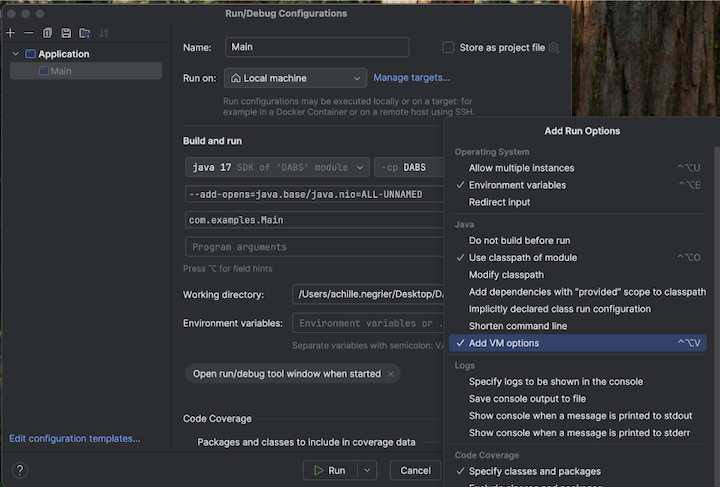
o passo 2: Configurar opções da VM
-
Importe o diretório atual no seu IntelliJ onde
build.sbtestá localizado. -
Selecione Java 17 no IntelliJ. Acesse Arquivo > Estrutura do Projeto > SDKs .
-
Abra
src/main/scala/com/examples/Main.scala. -
Acesse a configuração principal para adicionar opções de máquina virtual:
-
Adicione o seguinte às opções da sua máquina virtual:
--add-opens=java.base/java.nio=ALL-UNNAMED
Alternativamente, ou se você estiver usando o Visual Studio Code, adicione o seguinte ao seu arquivo de compilação do sbt:
fork := true
javaOptions += "--add-opens=java.base/java.nio=ALL-UNNAMED"
Em seguida, execute seu aplicativo a partir do terminal:
sbt run
o passo 3: Explore o pacote
Para view os arquivos gerados pelo padrão, acesse o diretório raiz do pacote recém-criado e abra esse diretório em sua IDE. O padrão usa o sbt para compilar e empacotar arquivos Scala e funciona com Databricks Connect para desenvolvimento local. Para informações detalhadas, consulte o projeto gerado README.md.
Os arquivos de particular interesse incluem os seguintes:
databricks.yml: Esse arquivo especifica o nome programático do pacote, inclui uma referência à definição do trabalho e especifica as configurações sobre o destino workspace.resources/my_scala_project.job.yml: Esse arquivo especifica as configurações de tarefa e de agrupamento do Job JAR.src/: Esse diretório inclui os arquivos de origem do projeto Scala.build.sbt: Esse arquivo contém configurações importantes de compilação e de biblioteca dependente.README.md: Esse arquivo contém as etapas para começar e as instruções e configurações de compilação local.
Passo 4: Valide o arquivo de configuração do pacote do projeto
Em seguida, verifique se a configuração do pacote é válida usando o comando bundle validate.
-
No diretório raiz, execute o comando Databricks CLI
bundle validate. Entre outras verificações, isso verifica se o volume especificado no arquivo de configuração existe no site workspace.Bashdatabricks bundle validate -
Se um resumo da configuração do pacote for retornado, a validação foi bem-sucedida. Se algum erro for retornado, corrija-o e repita essa etapa.
Se você fizer alguma alteração em seu pacote após essa etapa, repita essa etapa para verificar se a configuração do pacote ainda é válida.
o passo 5: implantei o projeto local no workspaceremoto
Agora, implante o pacote em seu site remoto Databricks workspace usando o comando de implantação de pacote. Essa etapa cria o arquivo JAR e faz o upload dele para o volume especificado.
-
execução o Databricks CLI
bundle deploycomando:Bashdatabricks bundle deploy -t dev -
Para verificar se o arquivo JAR criado localmente foi implantado:
- Na barra lateral do site Databricks workspace, clique em Catalog Explorer .
- Navegue até o caminho de destino do volume que você especificou ao inicializar o pacote. O arquivo JAR deve estar localizado na seguinte pasta dentro desse caminho:
/my_scala_project/dev/<user-name>/.internal/.
-
Para verificar se o trabalho foi criado:
- Na barra lateral do site Databricks workspace, clique em Jobs & pipeline .
- Opcionalmente, selecione os filtros Empregos e de minha propriedade .
- Clique em [dev
<your-username>]my_scala_project. - Clique na aba Tarefas .
Deve haver uma tarefa: main_task .
Se você fizer alguma alteração em seu pacote após essa etapa, repita as etapas de validação e implantação.
o passo 6: execução do projeto implantado
Por fim, execute o trabalho Databricks usando o comando de execução do pacote.
-
No diretório raiz, execute o comando Databricks CLI
bundle run, especificando o nome do trabalho no arquivo de definiçãomy_scala_project.job.yml:Bashdatabricks bundle run -t dev my_scala_project -
Copie o valor de
Run URLque aparece em seu terminal e cole esse valor em seu navegador da Web para abrir o site Databricks workspace. -
No site Databricks workspace, depois que a tarefa for concluída com êxito e mostrar uma barra de título verde, clique na tarefa main_task para ver os resultados.