Projeto de pacotes de automação declarativa padrão
Os Declarative Automation Bundles (anteriormente conhecidos como Databricks Ativo Bundles) descrevem recursos Databricks , como Jobs, pipelines e Notebooks, como arquivos de origem, permitindo incluir metadados junto com esses arquivos para provisionar infraestrutura e outros recursos, além de fornecer uma definição completa de um projeto, tudo empacotado como um único projeto implantável. Veja O que são pacotes de automação declarativa?
O padrão de pacotes permite que os usuários criem pacotes de forma consistente e repetível, estabelecendo estruturas de pastas, etapas e tarefas de construção, testes e outros atributos DevOps Infrastructure-as-Code (IaC) comuns em uma implantação pipeline.
Por exemplo, se você executa rotineiramente trabalhos que exigem pacotes personalizados com uma etapa de compilação demorada na instalação, poderá acelerar o ciclo de desenvolvimento criando um padrão de pacote que especifique um ambiente de contêiner personalizado.
Databricks fornece um conjunto de default bundle padrão, mas o senhor também pode criar bundle padrão personalizado. Os usuários podem então inicializar os pacotes usando o comando bundle init, especificando um padrão default ou seu padrão personalizado.
Criar um pacote usando um padrão
Para usar um padrão de pacote Databricks para criar seu pacote, use o comando Databricks CLI bundle init , especificando o nome do padrão a ser usado ou selecione um padrão disponível ao criar um pacote no workspace. Consulte Criar um pacote.
Por exemplo, o seguinte comando cria um pacote usando o padrão de pacote Python default :
databricks bundle init default-python
Para usar um padrão de pacote personalizado, passe o caminho local ou o URL remoto do padrão para o comando Databricks CLI bundle init comando.
Por exemplo, o comando a seguir usa o dab-container-template padrão criado no tutorial Custom Bundle padrão:
databricks bundle init /projects/my-custom-bundle-templates/dab-container-template
Se o senhor não especificar um padrão, o comando bundle init exibirá o conjunto de default padrões disponíveis entre os quais o senhor poderá escolher.
default bundle padrão
Databricks fornece o seguinte default bundle padrão:
Template | Descrição |
|---|---|
| Um padrão para criar um pacote vazio. Este padrão contém apenas os arquivos necessários e nenhum código de exemplo, além de configurar variáveis essenciais do catálogo. Isso permite que você crie novos projetos de pacotes rapidamente. Veja default-minimal. |
| Um padrão para usar Python com Databricks. Esse padrão cria um pacote com um Job e um ETL pipeline e requer uv. Consulte defaultPython-. |
| Um padrão para usar Scala com Databricks. Este padrão cria um pacote que gera um JAR Scala configurado para implantação em compute serverless . Veja default-Scala. |
| Um padrão para usar SQL com Databricks. Esse padrão contém um arquivo de configuração que define um Job que executa SQL consultas em um SQL warehouse. Consulte default-sql. |
| Um padrão que aproveita o dbt-core para desenvolvimento local e pacotes para implementação. Esse padrão contém a configuração que define um trabalho com uma tarefa dbt, bem como um arquivo de configuração que define perfis dbt para o trabalho dbt implantado. Veja dbt-sql. |
| Um padrão avançado de pilha completa para iniciar novos projetos MLOps Stacks. Consulte mlops-stacks e Pacotes de Automação Declarativa para MLOps Stacks. |
| Uma versão modificada do padrão |
Padrão de pacote personalizado
O padrão de pacote usa a sintaxe de modelo de pacote Go, que oferece flexibilidade no padrão de pacote personalizado que o senhor pode criar. Consulte a documentação do Go pacote padrão.
estrutura do projeto padrão
No mínimo, um projeto de bundle padrão deve ter:
- Um arquivo
databricks_template_schema.jsonna raiz do projeto que define uma propriedade de solicitação do usuário para o nome do projeto do pacote. Veja o esquema de padrão. - Um arquivo
databricks.yml.tmpllocalizado em uma pastatemplateque define a configuração de todos os pacotes criados com o padrão. Se o arquivodatabricks.yml.tmplfizer referência a qualquer padrão de configuração*.yml.tmpladicional, especifique o local desses padrões no mapeamentoinclude. Ver Configuração padrão.
Além disso, a estrutura de pastas e os arquivos incluídos na pasta template do projeto padrão do pacote são espelhados pelos pacotes criados com o padrão. Por exemplo, se quiser que o padrão gere um pacote com um Notebook simples na pasta src e uma definição de trabalho que execute o Notebook na pasta resources, o senhor organizaria o projeto padrão da seguinte forma:
basic-bundle-template
├── databricks_template_schema.json
└── template
└── {{.project_name}}
├── databricks.yml.tmpl
├── resources
│ └── {{.project_name}}_job.yml.tmpl
└── src
└── simple_notebook.ipynb
O nome da pasta do projeto e o nome do arquivo de definição do trabalho nesse pacote padrão usam uma variável padrão. Para obter informações sobre auxiliares e variáveis de padrão, consulte auxiliares e variáveis de padrão.
esquema de padrão
Um projeto padrão de pacote personalizado deve conter um databricks_template_schema.json JSON arquivo na raiz do projeto. Esse arquivo define os campos usados pelo site Databricks CLI quando o comando bundle init é executado, como o texto do prompt.
O arquivo básico databricks_template_schema.json a seguir define uma variável de entrada project_name para o projeto do pacote, que inclui a mensagem de prompt e um valor default. Em seguida, ele define uma mensagem de sucesso para a inicialização do projeto de pacote que usa o valor da variável de entrada na mensagem.
{
"properties": {
"project_name": {
"type": "string",
"default": "basic_bundle",
"description": "What is the name of the bundle you want to create?",
"order": 1
}
},
"success_message": "\nYour bundle '{{.project_name}}' has been created."
}
campos do esquema padrão
O arquivo databricks_template_schema.json permite definir variáveis de entrada para coletar informações do usuário durante a inicialização do pacote no campo properties, bem como campos adicionais para personalizar a inicialização.
As variáveis de entrada são definidas no campo properties do esquema padrão. Cada variável de entrada define os metadados necessários para apresentar uma solicitação ao usuário durante a inicialização do pacote. O valor da variável pode ser acessado usando a sintaxe de variável padrão, como {{.project_name}}.
Você também pode definir os valores de alguns campos para personalizar o processo de inicialização do pacote.
Os campos de esquema compatíveis estão listados na tabela a seguir.
Campo do esquema | Descrição |
|---|---|
| As definições da variável de entrada do padrão do pacote. A Databricks recomenda definir pelo menos uma variável de entrada que seja o nome do projeto do pacote. |
| O nome da variável de entrada. |
| Um valor default a ser usado se um valor não for fornecido pelo usuário com |
| A mensagem de aviso do usuário associada à variável de entrada. |
| Uma lista de valores possíveis para a propriedade, como |
| Um número inteiro que define a ordem relativa das propriedades de entrada. Isso controla a ordem em que os prompts para essas variáveis de entrada são mostrados na linha de comando. |
| O padrão regexp a ser usado para validar a entrada do usuário, por exemplo, |
| A mensagem que é exibida ao usuário se o valor inserido pelo usuário não corresponder ao padrão especificado, por exemplo, |
| Ignore a solicitação da variável de entrada se esse esquema for satisfeito pela configuração já presente. Nesse caso, o valor default da propriedade é usado em seu lugar. Para obter um exemplo, consulte o padrão mlops-stacks. Somente as comparações |
| Se o valor de |
| O caminho para o diretório padrão, como |
| A primeira mensagem a ser emitida antes de solicitar a entrada do usuário. |
| A mensagem a ser impressa após a inicialização bem-sucedida do padrão. |
| A versão mínima do semver deste Databricks CLI que o padrão exige. |
| Reservado para uso futuro. A versão do esquema. Isso é usado para determinar se o esquema é compatível com a versão atual da CLI. |
Configuração padrão
Um pacote padrão personalizado deve conter um arquivo databricks.yml.tmpl em uma pasta template no projeto do pacote padrão que é usado para criar o arquivo de configuração databricks.yml do projeto do pacote. O padrão para arquivos de configuração de recurso pode ser criado na pasta resources. Preencha esses arquivos padrão com a configuração padrão YAML.
O seguinte exemplo simples de configuração padrão para databricks.yml e o *Job.yml associado estabelecem o nome do pacote e dois ambientes de destino, e definem um trabalho que executa o Notebook no pacote, para pacotes criados usando esse padrão. Esse padrão de configuração aproveita as substituições de pacotes e os auxiliares de padrão de pacotes.
template/{{.project_name}}/databricks.yml.tmpl:
# databricks.yml
# This is the configuration for the bundle {{.project_name}}.
bundle:
name: {{.project_name}}
include:
- resources/*.yml
targets:
# The deployment targets. See https://docs.databricks.com/en/dev-tools/bundles/deployment-modes.html
dev:
mode: development
default: true
workspace:
host: {{workspace_host}}
prod:
mode: production
workspace:
host: {{workspace_host}}
# Deploy to a folder whose write access is restricted to the deploying
# identity. Avoid /Shared, which is writable by all workspace users.
root_path: /Workspace/Production/.bundle/${bundle.name}
{{- if not is_service_principal}}
run_as:
# This runs as {{user_name}} in production. Alternatively,
# a service principal could be used here using service_principal_name
user_name: {{user_name}}
{{end -}}
template/{{.project_name}}/resources/{{.project_name}}_job.yml.tmpl:
# {{.project_name}}_job.yml
# The main job for {{.project_name}}
resources:
jobs:
{{.project_name}}_job:
name: {{.project_name}}_job
tasks:
- task_key: notebook_task
job_cluster_key: job_cluster
notebook_task:
notebook_path: ../src/simple_notebook.ipynb
job_clusters:
- job_cluster_key: job_cluster
new_cluster:
node_type_id: i3.xlarge
spark_version: 13.3.x-scala2.12
ajudantes e variáveis padrão
Os padrão helpers são funções fornecidas pelo site Databricks que podem ser usadas nos arquivos padrão para obter informações específicas do usuário em tempo de execução ou interagir com o mecanismo padrão. O senhor também pode definir suas próprias variáveis padrão.
Os seguintes auxiliares de padrão estão disponíveis para Databricks bundle padrão projects. Para obter informações sobre o uso de Go padrão e variáveis, consulte Go padrão.
Ajudante | Descrição |
|---|---|
| Um alias para https://pkg.go.dev/net/url#Parse. Isso permite o uso de todos os métodos de |
| Um alias para https://pkg.go.dev/regexp#Compile. Isso permite o uso de todos os métodos de |
| Retorna, como um int, um número pseudo-aleatório não negativo no intervalo semiaberto (0, n). |
| Retorna, como uma string, um UUID que é um Universal Unique IDentifier de 128 bits (16 bytes), conforme definido na RFC 4122. Esse ID é estável durante a execução do padrão e pode ser usado para preencher o campo |
| Uma ID exclusiva para o pacote. Várias invocações dessa função retornarão o mesmo UUID. |
| Um par key-value. Isso é usado com o auxiliar |
| Converte uma lista de pares em um objeto de mapa. Isso é útil para passar vários objetos para o padrão definido no diretório da biblioteca. Como a sintaxe do padrão de texto Go para invocar um padrão só permite a especificação de um único argumento, essa função pode ser usada para contornar essa limitação. Por exemplo, na linha a seguir, |
| Retorna o menor tipo de nó. |
| O caractere separador de caminho para o sistema operacional. Isso é |
| O URL do host workspace no qual o usuário está autenticado no momento. |
| O nome completo do usuário que está inicializando o padrão. |
| O nome abreviado do usuário que está inicializando o padrão. |
| Retorna o catálogo default workspace . Se não houver default, ou se Unity Catalog não estiver habilitado, isso retorna uma cadeia de caracteres vazia. |
| Se o usuário atual é ou não uma entidade de serviço. |
| Faz com que o mecanismo de modelo ignore a geração de todos os arquivos e diretórios que correspondem ao padrão glob de entrada. Para obter um exemplo, consulte o padrão mlops-stacks. |
Ajudantes de padrão personalizados
Para definir seus próprios auxiliares padrão, crie um arquivo padrão na pasta library do projeto padrão e use a sintaxe de modelo Go para definir os auxiliares. Por exemplo, o conteúdo a seguir de um arquivo library/variables.tmpl define as variáveis cli_version e model_name. Quando esse padrão é usado para inicializar um pacote, o valor da variável model_name é construído usando o campo input_project_name definido no arquivo de esquema do padrão. O valor desse valor de campo é a entrada do usuário após uma solicitação.
{{ define `cli_version` -}}
v0.240.0
{{- end }}
{{ define `model_name` -}}
{{ .input_project_name }}-model
{{- end }}
Para ver um exemplo completo, consulte o arquivo de variáveis padrão mlops-stacks.
Teste o padrão do pacote
Por fim, certifique-se de testar seu padrão. Por exemplo, use o endereço Databricks CLI para inicializar um novo pacote usando o padrão definido nas seções anteriores:
databricks bundle init basic-bundle-template
Para o prompt, What is your bundle project name?, digite my_test_bundle.
Depois que o pacote de teste é criado, a mensagem de sucesso do arquivo de esquema é emitida. Se você examinar o conteúdo da pasta my_test_bundle, deverá ver o seguinte:
my_test_bundle
├── databricks.yml
├── resources
│ └── my_test_bundle_job.yml
└── src
└── simple_notebook.ipynb
E o arquivo databricks.yml e o Job agora estão personalizados:
# databricks.yml
# This is the configuration for the bundle my-test-bundle.
bundle:
name: my_test_bundle
include:
- resources/*.yml
targets:
# The 'dev' target, used for development purposes. See [_](https://docs.databricks.com/en/dev-tools/bundles/deployment-modes.html#development-mode)
dev:
mode: development
default: true
workspace:
host: https://my-host.cloud.databricks.com
# The 'prod' target, used for production deployment. See [_](https://docs.databricks.com/en/dev-tools/bundles/deployment-modes.html#production-mode)
prod:
mode: production
workspace:
host: https://my-host.cloud.databricks.com
# Deploy to a folder whose write access is restricted to the deploying
# identity. Avoid /Shared, which is writable by all workspace users.
root_path: /Workspace/Production/.bundle/${bundle.name}
run_as:
# This runs as someone@example.com in production. Alternatively,
# a service principal could be used here using service_principal_name
user_name: someone@example.com
# my_test_bundle_job.yml
# The main job for my_test_bundle
resources:
jobs:
my_test_bundle_job:
name: my_test_bundle_job
tasks:
- task_key: notebook_task
job_cluster_key: job_cluster
notebook_task:
notebook_path: ../src/simple_notebook.ipynb
job_clusters:
- job_cluster_key: job_cluster
new_cluster:
node_type_id: i3.xlarge
spark_version: 13.3.x-scala2.12
Compartilhe um padrão personalizado
Se você deseja compartilhar um pacote padrão com outros usuários, pode armazená-lo em um sistema de controle de versão com qualquer provedor compatível Git e ao qual seus usuários tenham acesso. Para executar o comando bundle init com um URL Git , certifique-se de que o arquivo databricks_template_schema.json esteja no local raiz relativo a esse URL Git .
Você pode colocar o arquivo databricks_template_schema.json em uma pasta diferente, em relação à raiz do pacote. Em seguida, o senhor pode usar a opção --template-dir do comando bundle init para fazer referência a essa pasta, que contém o arquivo databricks_template_schema.json.
Configure uma pasta padrão personalizada no workspace
Beta
Este recurso está em versão Beta.
É possível disponibilizar um padrão de pacote personalizado para a criação de pacotes no workspace.
-
Armazene seu pacote padrão em um repositório GitHub e configure uma pasta Git para se conectar a ele. Para obter informações sobre como configurar uma pasta Git , consulte Clonar um repo.
-
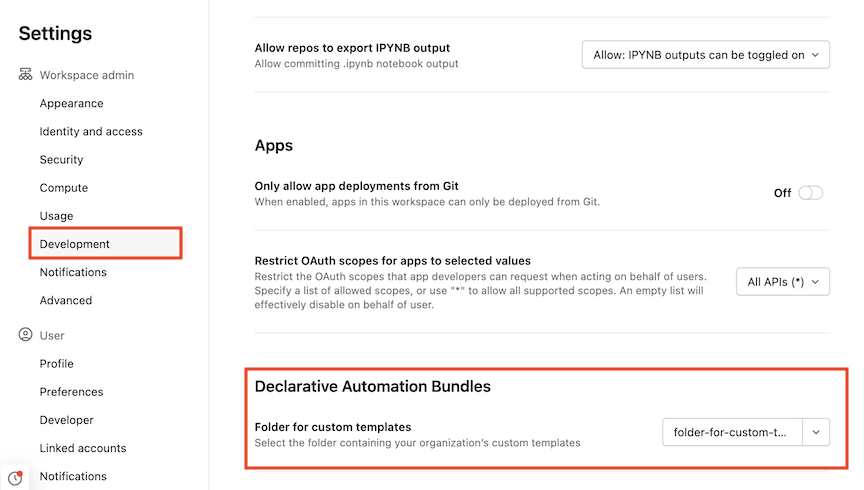
Como administrador account ou workspace , acesse as Configurações no workspace. Veja como gerenciar seu workspace.
-
Clique em Desenvolvimento .
-
Em Declarative Automation Bundles , selecione uma pasta para padrão personalizado. Todos os pacotes padrão personalizados devem estar disponíveis no nível raiz da pasta.
-
Quando a caixa de diálogo de permissões aparecer, conceda a todos os usuários acesso CAN VIEW à pasta para padrões personalizados ou selecione Não conceder acesso para definir permissões mais específicas.
-
Para definir permissões mais específicas, selecione os três pontos dentro de qualquer pasta e clique em "Exibir detalhes" .
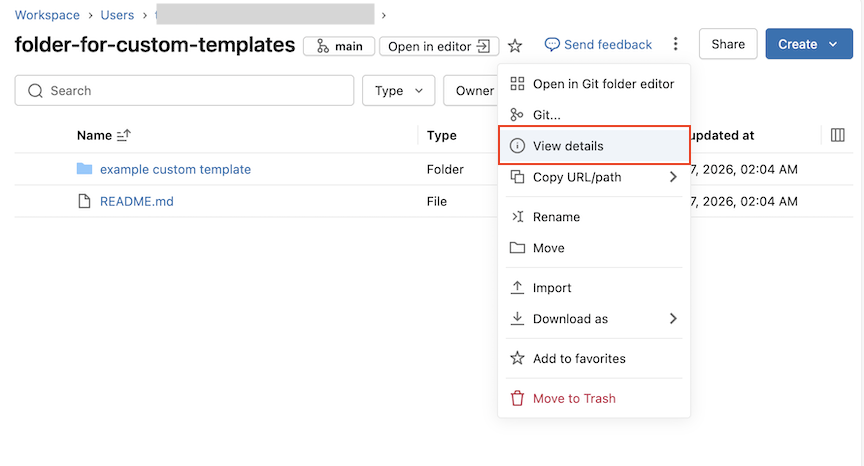
-
Clique em Compartilhar no painel de detalhes da pasta Git .
-
Escolha quem pode editar o padrão (CAN MANAGE) e quem pode criar pacotes usando o padrão (CAN VIEW).
Para obter mais informações sobre permissões, consulte ACLs de pastas e ACLs de pastasGit.
-
Os padrões nesta pasta agora estão disponíveis para os usuários quando eles criam pacotes no workspace. Consulte Criar um pacote.
Próximas etapas
- Procure outros padrões criados e mantidos por Databricks. Consulte o repositório de amostras de pacotes no GitHub.
- Para usar MLOps Stacks com o padrão Declarative Automation Bundles, consulte Declarative Automation Bundles para MLOps Stacks.
- Saiba mais sobre o modelo de pacote Go. Consulte a documentação do Go pacote padrão.