Melhores práticas e recomendações CI/CD fluxo de trabalho on Databricks
CI/CD (integração contínua (CI) e entrega contínua (CD)) tornou-se a pedra angular da moderna engenharia e análise de dados, pois garante que as alterações de código sejam integradas, testadas e implantadas de forma rápida e confiável. Databricks reconhece que o senhor pode ter diversos requisitos CI/CD moldados por suas preferências organizacionais, fluxo de trabalho existente e ambiente tecnológico específico, e oferece uma estrutura flexível que suporta várias opções CI/CD.
Esta página descreve as práticas recomendadas para ajudá-lo a projetar e criar um pipeline CI/CD robusto e personalizado que se alinhe às suas necessidades e restrições exclusivas. Ao aproveitar essas percepções, o senhor pode acelerar suas iniciativas de engenharia e análise de dados, melhorar a qualidade do código e reduzir o risco de falhas na implantação.
Princípios fundamentais do CI/CD
O pipeline eficaz CI/CD compartilha princípios fundamentais, independentemente das especificidades da implementação. As práticas recomendadas universais a seguir se aplicam a todas as preferências organizacionais, ao fluxo de trabalho do desenvolvedor e aos ambientes de nuvem, e garantem a consistência em diversas implementações, independentemente de sua equipe priorizar o desenvolvimento com base no notebook ou no Infrastructure-as-Code fluxo de trabalho. Adote esses princípios como diretrizes e, ao mesmo tempo, adapte as especificidades à pilha tecnológica e aos processos de sua organização.
-
Controle tudo de versão
- Armazene o Notebook, os scripts, as definições de infraestrutura (IaC) e as configurações de trabalho em Git.
- Use estratégias de ramificação, como o Gitflow, que estejam alinhadas aos ambientes padrão de desenvolvimento, preparação e implantação de produção.
-
Automatize os testes
- Implemente testes de unidade para lógica de negócios usando biblioteca, como pytest para Python e ScalaTest para Scala.
- Valide a funcionalidade do Notebook e do fluxo de trabalho com ferramentas, como Databricks CLI bundle validate.
- Use testes de integração para fluxo de trabalho e pipeline de dados, como o chispa para Spark DataFrames.
-
Empregar a infraestrutura como código (IaC)
- Defina clusters, jobs e configurações workspace com Declarative Automation Bundles YAML ou Terraform.
- Parametrize em vez de codificar configurações específicas do ambiente, como tamanho do agrupamento e segredos.
-
Isole ambientes
- Manter espaços de trabalho separados para desenvolvimento, preparação e produção.
- Use o MLflow Model Registry para o controle de versão do modelo entre ambientes.
-
Escolha ferramentas que correspondam ao seu ecossistema de nuvem:
- Azure: Azure DevOps e pacotes de automação declarativa ou Terraform.
- AWS: GitHub Actions e pacotes de automação declarativa ou Terraform.
- GCP: Cloud Build e Declarative Automation Bundles ou Terraform.
-
Monitore e automatize reversões
- Acompanhe as taxas de sucesso da implantação, o desempenho dos trabalhos e a cobertura dos testes.
- Implemente mecanismos de reversão automatizados para implantações com falha.
-
Unificar o gerenciamento ativo
- Utilize os Pacotes de Automação Declarativa para implantar código, tarefas e infraestrutura como uma única unidade. Evite o gerenciamento isolado de notebook, biblioteca e fluxo de trabalho.
A Databricks recomenda a federação de identidade de carga de trabalho para autenticação de CI/CD. A federação de identidade de carga de trabalho elimina a necessidade de segredos da Databricks, o que a torna a maneira mais segura de autenticar seus fluxos automatizados para a Databricks. Consulte Habilitar federação de identidade de carga de trabalho em CI/CD.
Pacotes de Automação Declarativa para CI/CD
Os Declarative Automation Bundles (anteriormente conhecidos como Databricks Ativo Bundles) oferecem uma abordagem poderosa e unificada para gerenciar código, fluxo de trabalho e infraestrutura dentro do ecossistema Databricks e são recomendados para seu pipeline CI/CD . Ao agrupar esses elementos em uma única unidade definida em YAML, os pacotes simplificam a implantação e garantem a consistência entre os ambientes. No entanto, para usuários acostumados ao fluxo de trabalho tradicional CI/CD , a adoção de bundles pode exigir uma mudança de mentalidade.
Por exemplo, os desenvolvedores do Java estão acostumados a criar JARs com o Maven ou o Gradle, a executar testes de unidade com o JUnit e a integrar essas etapas no pipeline do CI/CD. Da mesma forma, os desenvolvedores do Python costumam empacotar o código em rodas e testar com o pytest, enquanto os desenvolvedores do SQL se concentram na validação da consulta e no gerenciamento do Notebook. Com os pacotes, esses fluxos de trabalho convergem para um formato mais estruturado e prescritivo, enfatizando o agrupamento de código e infraestrutura para uma implementação perfeita.
As seções a seguir exploram como os desenvolvedores podem adaptar seu fluxo de trabalho para aproveitar os pacotes de forma eficaz.
Para começar rapidamente a usar os Pacotes de Automação Declarativa, experimente um tutorial: Desenvolver um Job com Pacotes de Automação Declarativa ou Desenvolver um pipeline com Pacotes de Automação Declarativa.
Recomendações de controle de origem CI/CD
A primeira escolha que os desenvolvedores precisam fazer ao implementar a CI/CD é como armazenar e versionar os arquivos de origem. Os pacotes permitem que você contenha facilmente tudo — código-fonte, artefatos de construção e arquivos de configuração — e os localize no mesmo repositório de código-fonte, mas outra opção é separar os arquivos de configuração do pacote dos arquivos relacionados ao código. A escolha depende do fluxo de trabalho da sua equipe, da complexidade do projeto e dos requisitos de CI/CD, mas a Databricks recomenda o seguinte:
- Em projetos pequenos ou com forte acoplamento entre o código e a configuração, use um único repositório para o código e a configuração do pacote para simplificar o fluxo de trabalho.
- Para equipes maiores ou ciclos de lançamento independentes, use repositórios separados para código e configuração de pacotes, mas estabeleça um pipeline CI/CD claro que garanta a compatibilidade entre as versões.
Independentemente de optar por co-localizar ou separar os arquivos relacionados ao código dos arquivos de configuração do pacote, sempre use artefatos com versão, como hashes Git commit , ao fazer upload para Databricks ou armazenamento externo para garantir a rastreabilidade e os recursos de reversão.
Repositório único para código e configuração
Nessa abordagem, tanto o código-fonte quanto os arquivos de configuração do pacote são armazenados no mesmo repositório. Isso simplifica o fluxo de trabalho e garante mudanças atômicas.
Prós | Contras |
|---|---|
|
|
Exemplo: Código Python em um pacote
Este exemplo tem arquivos Python e arquivos de pacote em um único repositório:
databricks-dab-repo/
├── databricks.yml # Bundle definition
├── resources/
│ ├── workflows/
│ │ ├── my_pipeline.yml # YAML pipeline def
│ │ └── my_pipeline_job.yml # YAML job def that runs pipeline
│ ├── clusters/
│ │ ├── dev_cluster.yml # development cluster def
│ │ └── prod_cluster.yml # production def
├── src/
│ ├── my_pipeline.ipynb # pipeline notebook
│ └── mypython.py # Additional Python
└── README.md
Repositórios separados para código e configuração
Nessa abordagem, o código-fonte reside em um repositório, enquanto os arquivos de configuração do pacote são mantidos em outro. Essa opção é ideal para equipes ou projetos maiores em que grupos separados lidam com o desenvolvimento de aplicativos e o gerenciamento do fluxo de trabalho do Databricks.
Prós | Contras |
|---|---|
|
|
Exemplo: Projeto e pacote Java
Neste exemplo, um projeto Java e seus arquivos estão em um repositório e os arquivos do pacote estão em outro repositório.
Repositório 1: arquivos Java
O primeiro repositório contém todos os arquivos relacionados ao Java:
java-app-repo/
├── pom.xml # Maven build configuration
├── src/
│ ├── main/
│ │ ├── java/ # Java source code
│ │ │ └── com/
│ │ │ └── mycompany/
│ │ │ └── app/
│ │ │ └── App.java
│ │ └── resources/ # Application resources
│ └── test/
│ ├── java/ # Unit tests for Java code
│ │ └── com/
│ │ └── mycompany/
│ │ └── app/
│ │ └── AppTest.java
│ └── resources/ # Test-specific resources
├── target/ # Compiled JARs and classes
└── README.md
- Os desenvolvedores escrevem o código do aplicativo em
src/main/javaousrc/main/scala. - Os testes unitários são armazenados em
src/test/javaousrc/test/scala. - Em uma solicitação pull ou commit, CI/CD pipeline:
- Compile o código em um JAR, por exemplo,
target/my-app-1.0.jar. - Faça upload do JAR para um volume Databricks Unity Catalog . Veja upload JAR.
- Compile o código em um JAR, por exemplo,
Repositório 2: Agrupar arquivos
Um segundo repositório contém somente os arquivos de configuração do pacote:
databricks-dab-repo/
├── databricks.yml # Bundle definition
├── resources/
│ ├── jobs/
│ │ ├── my_java_job.yml # YAML job dev
│ │ └── my_other_job.yml # Additional job definitions
│ ├── clusters/
│ │ ├── dev_cluster.yml # development cluster def
│ │ └── prod_cluster.yml # production def
└── README.md
-
A configuração do pacote databricks.yml e as definições de trabalho são mantidas de forma independente.
-
O databricks.yml faz referência ao artefato de upload JAR, por exemplo:
YAML- jar: /Volumes/artifacts/my-app-${{ GIT_SHA }}.)jar
Recomendado CI/CD fluxo de trabalho
Independentemente de o senhor estar co-localizando ou separando os arquivos de código dos arquivos de configuração do pacote, um fluxo de trabalho recomendado seria o seguinte:
-
Compile e teste o código
- Acionado em um pull request ou em um commit no branch principal.
- Compilar código e executar testes unitários.
- Produza um arquivo versionado, por exemplo,
my-app-1.0.jar.
-
Faça upload e armazene o arquivo compilado, como um JAR, em um volume do Databricks Unity Catalog.
- Armazene o arquivo compilado em um volume do Databricks Unity Catalog ou em um repositório de artefatos como o AWS S3 ou o Azure Blob Storage.
- Use um esquema de controle de versão vinculado a hashes de commit do Git ou controle de versão semântico, por exemplo,
dbfs:/mnt/artifacts/my-app-${{ github.sha }}.jar.
-
Valide o pacote
- execução
databricks bundle validatepara garantir que a configuração dodatabricks.ymlesteja correta. - Essa etapa garante que as configurações incorretas, por exemplo, a falta de uma biblioteca, sejam detectadas com antecedência.
- execução
-
implantado o feixe
- Use
databricks bundle deploypara implantar o pacote em um ambiente de preparação ou produção. - Faça referência à biblioteca compilada de upload em
databricks.yml. Para obter informações sobre como referenciar a biblioteca, consulte Dependências da biblioteca dos Pacotes de Automação Declarativa.
- Use
Estratégia de ramificação
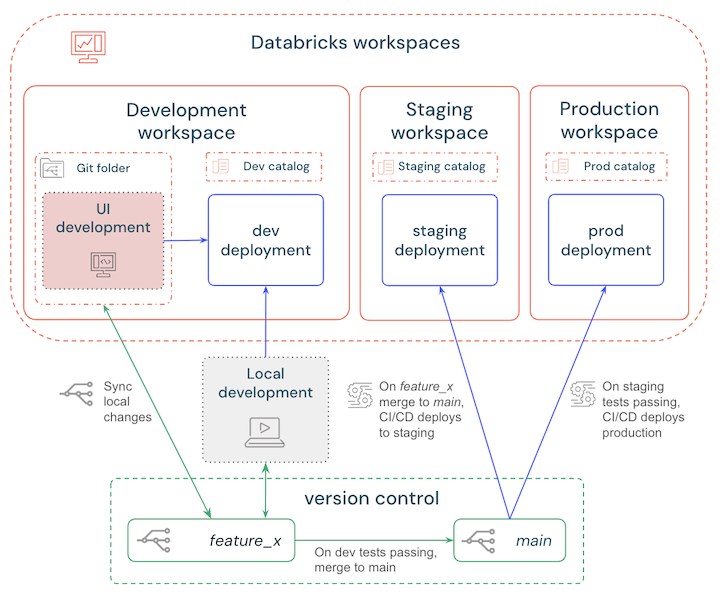
Existem diversas estratégias de ramificação que você pode escolher ao configurar seu pipeline de CI/CD. A melhor prática mais simples é:
- Desenvolva localmente ou no workspace e implante em um workspace de desenvolvimento Databricks para testar as alterações.
- Crie uma ramificação de recurso para controlar as versões das atualizações e sincronize regularmente as alterações locais ou do seu workspace .
- Quando os testes estiverem concluídos, merge a branch de recursos com a branch principal.
- CI/CD implanta automaticamente a ramificação principal em um workspace de preparação e os testes automatizados são acionados.
- Quando os testes e verificações de homologação forem aprovados, CI/CD implantará a ramificação principal em um workspace de produção.
Esses passos estão descritos no diagrama a seguir:
CI/CD para aprendizado de máquina
Os projetos de aprendizado de máquina apresentam desafios únicos de CI/CD em comparação com o desenvolvimento tradicional de software. Ao implementar CI/CD para projetos de ML, o senhor provavelmente precisará considerar o seguinte:
- Coordenação de várias equipes: cientistas de dados, engenheiros e equipes de MLOps frequentemente usam ferramentas e fluxos de trabalho diferentes. O Databricks unifica esses processos com o MLflow para acompanhamento de experimentos, o OpenSharing para governança de dados e os Declarative Automation Bundles para Infrastructure-as-Code.
- Controle de versão de dados e modelos: ML pipelines exigem acompanhamento não apenas de código, mas também de esquemas de dados, distribuição de recursos e artefatos de modelos. Delta Lake fornece transações ACID e viagem do tempo para versionamento de dados, enquanto MLflow Model Registry cuida da linhagem do modelo.
- Reprodutibilidade em diferentes ambientes: os modelos ML dependem de combinações específicas de dados, código e infraestrutura. Os pacotes de automação declarativa garantem a implantação atômica desses componentes em ambientes de desenvolvimento, teste e produção com definições YAML.
- Retreinamento e monitoramento contínuos: os modelos se degradam devido à deriva dos dados. Os Jobs LakeFlow permitem o retreinamento automatizado do pipeline, enquanto MLflow se integra ao Prometheus e ao monitoramento de qualidade de dados Databricks para acompanhamento de desempenho.
Pilhas de MLOps para CI/CD de ML
Databricks aborda a complexidade CI/CD ML por meio do MLOps Stacks, uma estrutura de nível de produção que combina pacotes de automação declarativa, fluxo de trabalho CI/CD pré-configurado e padrão de projeto ML máquina modular. Essas estruturas reforçam as melhores práticas, ao mesmo tempo que permitem flexibilidade para a colaboração entre várias equipes nas áreas de engenharia de dados, ciência de dados e operações de multitarefa (MLOps).
Equipe | Responsabilidades | Exemplos de componentes do pacote | Exemplos de artefatos |
|---|---|---|---|
engenheiro de dados | Crie o pipeline ETL, reforce a qualidade dos dados | LakeFlow Spark Declarative pipeline YAML, política de cluster |
|
data scientists | Desenvolver a lógica de treinamento do modelo, validar as métricas | MLflow Projetos, fluxo de trabalho baseado em notebook |
|
Engenheiros de MLOps | Orquestrar implementações, monitorar o pipeline | variável de ambiente, monitoramento de dashboards |
|
A colaboração ML CI/CD pode ser semelhante:
- engenheiro de dados commit ETL pipeline alterações em um pacote, acionando a validação automatizada do esquema e uma implantação de teste.
- data scientists submetem o código ML , que é executado em testes unitários e implantado em um workspace teste para testes de integração.
- Os engenheiros de MLOps analisam as métricas de validação e promovem modelos aprovados para produção usando o MLflow Registry.
Para obter detalhes da implementação, consulte:
- Pacote MLOps Stacks: Orientação passo a passo para inicialização e implementação do pacote.
- MLOps Repositório Stacks GitHub: Padrão pré-configurado para treinamento, inferência e CI/CD.
Ao alinhar as equipes com pacotes padronizados e pilhas de MLOps, as organizações podem simplificar a colaboração e, ao mesmo tempo, manter a capacidade de auditoria em todo o ciclo de vida do ML.
CI/CD para desenvolvedores de SQL
SQL Os desenvolvedores que utilizam o site Databricks SQL para gerenciar tabelas de transmissão e visualizações materializadas podem aproveitar a integração Git e o pipeline CI/CD para agilizar seu fluxo de trabalho e manter um pipeline de alta qualidade. Com a introdução do suporte do Git para consultas, os desenvolvedores de SQL podem se concentrar em escrever consultas e, ao mesmo tempo, aproveitar o Git para controlar a versão de seus arquivos .sql, o que permite a colaboração e a automação sem a necessidade de um profundo conhecimento de infraestrutura. Além disso, o editor SQL permite a colaboração em tempo real e se integra perfeitamente ao Git fluxo de trabalho.
Para fluxo de trabalho centrado em SQL:
-
Controle de versão de arquivos SQL
- Armazenar .sql arquivos em repositórios Git usando pastas Git da Databricks ou provedores Git externos, por exemplo, GitHub, Azure DevOps.
- Use ramificações (por exemplo, desenvolvimento, preparação, produção) para gerenciar alterações específicas do ambiente.
-
Integre os arquivos
.sqlao pipeline CI/CD para automatizar a implementação:- Valide as alterações de sintaxe e esquema durante solicitações pull.
- implantado
.sqlarquivos para Databricks SQL fluxo de trabalho ou Job.
-
Parametrize para isolamento do ambiente
-
Use variáveis nos arquivos
.sqlpara fazer referência dinâmica a recursos específicos do ambiente, como caminhos de dados ou nomes de tabelas:SQLCREATE OR REFRESH STREAMING TABLE ${env}_sales_ingest AS SELECT * FROM read_files('s3://${env}-sales-data')
-
-
atualização de programa e monitor
- Use a tarefa SQL em um Databricks Job para programar atualizações em tabelas e visualizações materializadas (
REFRESH MATERIALIZED VIEW view_name). - Monitorar refresh história usando tabelas do sistema.
- Use a tarefa SQL em um Databricks Job para programar atualizações em tabelas e visualizações materializadas (
Um fluxo de trabalho pode ser:
- Desenvolva: Escreva e teste
.sqlscripts localmente ou no editor Databricks SQL e, em seguida, commit -os em uma ramificação Git. - Validar: durante uma pull request, valide a compatibilidade de sintaxe e esquema usando verificações automatizadas de CI.
- implantado: Em merge, implantado o .sql scripts para o ambiente de destino usando o pipeline CI/CD, por exemplo, o pipeline GitHub Actions ou Azure.
- Monitore: Use os painéis e alertas do site Databricks para monitorar o desempenho das consultas e a atualização dos dados.
CI/CD para desenvolvedores de painéis
Databricks oferece suporte à integração de painéis no fluxo de trabalho CI/CD usando pacotes de automação declarativa. Essa funcionalidade permite que os desenvolvedores de painéis de controle:
- Painéis de controle de versão, que garantem auditabilidade e simplificam a colaboração entre equipes.
- Automatize as implementações de dashboards juntamente com o Job e o pipeline em todos os ambientes, para alinhamento de ponta a ponta.
- Reduza os erros manuais e garanta que as atualizações sejam aplicadas de forma consistente em todos os ambientes.
- Manter um fluxo de trabalho analítico de alta qualidade e aderir às práticas recomendadas do site CI/CD.
Para painéis de controle em CI/CD:
-
Use o comando
databricks bundle generatepara exportar painéis existentes como arquivos JSON e gerar a configuração YAML que os inclui no pacote:YAMLresources:
dashboards:
sales_dashboard:
display_name: 'Sales Dashboard'
file_path: ./dashboards/sales_dashboard.lvdash.json
warehouse_id: ${var.warehouse_id} -
Armazene esses arquivos
.lvdash.jsonem repositórios Git para acompanhar as alterações e colaborar de forma eficaz. -
Implantação automática de dashboards no pipeline CI/CD com
databricks bundle deploy. Por exemplo, o GitHub Actions é o passo para implantação:YAMLname: Deploy Dashboard
run: databricks bundle deploy --target=prod
env:
DATABRICKS_TOKEN: ${{ secrets.DATABRICKS_TOKEN }} -
Use variáveis, por exemplo,
${var.warehouse_id}, para parametrizar configurações como SQL warehouse ou fonte de dados, garantindo uma implementação perfeita em ambientes de desenvolvimento, preparação e produção. -
Use a opção
bundle generate --watchpara sincronizar continuamente os arquivos JSON do painel local com as alterações feitas na interface do usuário do Databricks. Se ocorrerem discrepâncias, use o sinalizador--forcedurante a implantação para substituir painéis remotos por versões locais.
Para obter informações sobre dashboards em pacotes, consulte recurso de dashboard. Para obter detalhes sobre o comando do pacote, consulte bundle comando group.