CI/CD com Jenkins na Databricks
Este artigo abrange o Jenkins, que é desenvolvido por terceiros. Para entrar em contato com o provedor, consulte a Ajuda do Jenkins.
Este artigo descreve como usar o servidor de automação Jenkins com Databricks para implementar um fluxo de trabalho de desenvolvimento de CI/CD .
Para uma visão geral de CI/CD com Databricks, consulte CI/CD no Databricks. Para obter as melhores práticas, consulte fluxos de trabalho de CI/CD no Databricks e práticas recomendadas para desenvolvedores no Databricks.
Configuração da máquina de desenvolvimento local
Este exemplo utiliza o Jenkins para instruir a CLIDatabricks e os Pacotes de Automação Declarativa a realizar as seguintes tarefas:
- Crie um arquivo Python wheel em seu computador de desenvolvimento local.
- Implemente o arquivo Python wheel construído junto com os arquivos Python adicionais e o Notebook Python de sua máquina de desenvolvimento local em um Databricks workspace.
- Teste e execute o upload do arquivo Python wheel e o Notebook nesse workspace.
Para configurar o computador de desenvolvimento local para instruir o Databricks workspace a executar os estágios de compilação e upload deste exemplo, faça o seguinte no computador de desenvolvimento local:
Etapa 1: instalar as ferramentas necessárias
Nesta etapa, o senhor instala as ferramentas de compilação Databricks CLI, Jenkins, jq e Python wheel em sua máquina de desenvolvimento local. Essas ferramentas são necessárias para a execução deste exemplo.
-
Instale o site Databricks CLI versão 0.205 ou acima, caso ainda não o tenha feito. O Jenkins usa o Databricks CLI para passar as instruções de teste e execução deste exemplo para o seu workspace. Consulte Instalar ou atualizar a CLI da Databricks.
-
Instale e inicie o Jenkins, caso ainda não o tenha feito. Consulte Instalação do Jenkins para Linux, macOS ou Windows.
-
Instale o jq. Este exemplo usa o site
jqpara analisar algumas saídas de comando formatadas em JSON. -
Use
pippara instalar as ferramentas de compilação do Python wheel com o seguinte comando (alguns sistemas podem exigir que o senhor usepip3em vez depip):Bashpip install --upgrade wheel
Etapa 2: Criar um pipeline do Jenkins
Nesta etapa, o senhor usa o Jenkins para criar um pipeline do Jenkins para o exemplo deste artigo. O Jenkins oferece alguns tipos de projetos diferentes para criar o pipeline CI/CD. O pipeline Jenkins fornece uma interface para definir estágios em um pipeline Jenkins usando o código Groovy para chamar e configurar os plugins Jenkins.
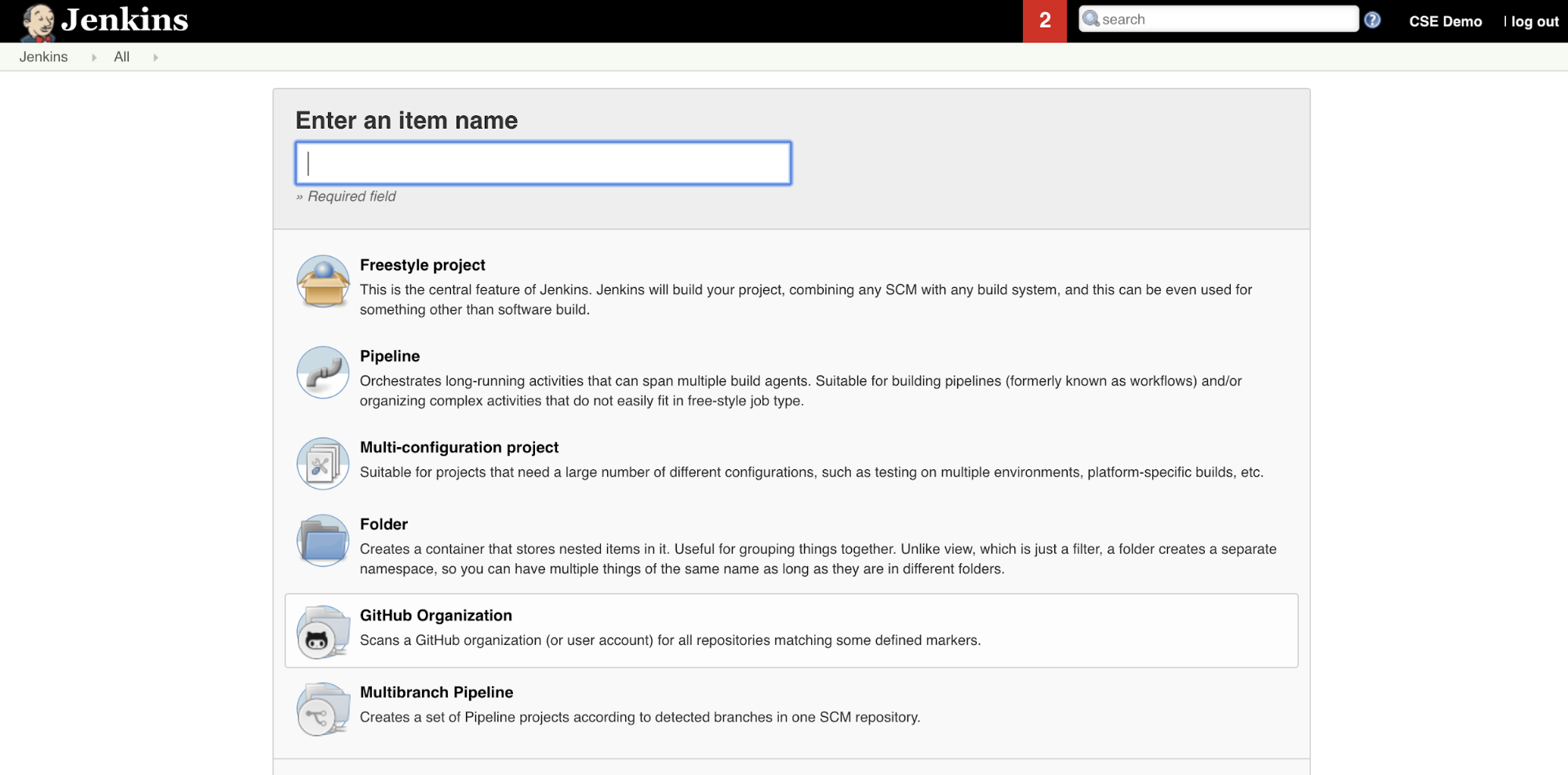
Para criar o pipeline do Jenkins no Jenkins:
- Depois de iniciar o Jenkins, no painel do Jenkins, clique em New Item (Novo item ).
- Em Enter an item name (Inserir um nome de item ), digite um nome para o pipeline do Jenkins, por exemplo,
jenkins-demo. - Clique no ícone do tipo de projeto de pipeline .
- Clique em OK . A página Configure (Configurar ) do pipeline do Jenkins é exibida.
- Na área de pipeline , na lista suspensa Definição , selecione o script de pipeline do SCM .
- Na lista suspensa SCM , selecione Git .
- Em Repository URL (URL do repositório ), digite a URL do repositório hospedado pelo seu provedor Git de terceiros.
- Em Branch Specifier , digite
*/<branch-name>, onde<branch-name>é o nome da ramificação em seu repositório que você deseja usar, por exemplo*/main. - Em Caminho do script , digite
Jenkinsfile, se ainda não estiver definido. O senhor cria oJenkinsfilemais adiante neste artigo. - Desmarque a caixa intitulada Lightweight checkout , se já estiver marcada.
- Clique em Salvar .
Etapa 3: Adicionar variável global de ambiente ao Jenkins
Neste passo, você adiciona três variáveis globais de ambiente ao Jenkins. Jenkins passa essas variáveis de ambiente para a CLI Databricks . A CLI Databricks precisa dos valores dessas variáveis de ambiente para autenticar no seu workspace Databricks . Este exemplo utiliza a autenticação OAuth máquina a máquina (M2M) para uma entidade de serviço (embora outros tipos de autenticação também estejam disponíveis). Para configurar a autenticação OAuth M2M para seu workspace Databricks , consulte Autorizar o acesso da entidade de serviço ao Databricks com OAuth.
As três variáveis globais de ambiente para este exemplo são:
DATABRICKS_HOST, definido como seu URL Databricks workspace , começando comhttps://. Consulte nomes de instância de espaço de trabalho, URLs e IDs.DATABRICKS_CLIENT_IDdefinido como o ID do cliente da entidade de serviço, que também é conhecido como ID do aplicativo.DATABRICKS_CLIENT_SECRETdefinido como o segredo do Databricks OAuth da entidade de serviço.
Para definir a variável global de ambiente no Jenkins, no painel do Jenkins:
- Na barra lateral, clique em gerenciar Jenkins .
- Na seção Configuração do sistema , clique em Sistema .
- Na seção Propriedades globais , marque a caixa intitulada variável de ambiente .
- Clique em Add e digite o nome e o valor da variável de ambiente. Repita esse procedimento para cada variável de ambiente adicional.
- Quando terminar de adicionar a variável de ambiente, clique em Salvar para retornar ao seu painel do Jenkins.
Projetar o pipeline do Jenkins
O Jenkins oferece alguns tipos de projetos diferentes para criar o pipeline CI/CD. Este exemplo implementa um pipeline do Jenkins. O pipeline do Jenkins fornece uma interface para definir estágios em um pipeline do Jenkins usando o código Groovy para chamar e configurar os plugins do Jenkins.
O senhor escreve uma definição de pipeline do Jenkins em um arquivo de texto chamado Jenkinsfile , que, por sua vez, é verificado no repositório de controle de origem de um projeto. Para obter mais informações, consulte o pipeline do Jenkins. Aqui está o pipeline do Jenkins para o exemplo deste artigo. Neste exemplo Jenkinsfile, substitua os seguintes espaços reservados:
- Substitua
<user-name>e<repo-name>pelo nome de usuário e pelo nome do repositório hospedado pelo seu provedor Git de terceiros. Este artigo usa um URL GitHub como exemplo. - Substitua
<release-branch-name>pelo nome da ramificação de lançamento em seu repositório. Por exemplo, isso pode sermain. - Substitua
<databricks-cli-installation-path>pelo caminho em seu computador de desenvolvimento local onde a CLI da Databricks está instalada. Por exemplo, no macOS, isso pode ser/usr/local/bin. - Substitua
<jq-installation-path>pelo caminho em sua máquina de desenvolvimento local ondejqestá instalado. Por exemplo, no macOS, isso pode ser/usr/local/bin. - Substitua
<job-prefix-name>por algumas cadeias de caracteres para ajudar a identificar exclusivamente o trabalho que é criado em seu workspace para este exemplo. Por exemplo, isso pode serjenkins-demo. - Observe que
BUNDLETARGETestá definido comodev, que é o nome do alvo Declarative Automation Bundles que será definido posteriormente neste artigo. Em implementações reais, altere isso para o nome do seu próprio alvo de pacote. Mais detalhes sobre os destinos dos pacotes serão fornecidos posteriormente neste artigo.
Aqui está o Jenkinsfile, que deve ser adicionado à raiz do seu repositório:
// Filename: Jenkinsfile
node {
def GITREPOREMOTE = "https://github.com/<user-name>/<repo-name>.git"
def GITBRANCH = "<release-branch-name>"
def DBCLIPATH = "<databricks-cli-installation-path>"
def JQPATH = "<jq-installation-path>"
def JOBPREFIX = "<job-prefix-name>"
def BUNDLETARGET = "dev"
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
-t ${BUNDLETARGET} \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
}
O restante deste artigo descreve cada estágio desse pipeline do Jenkins e como configurar os artefatos e o comando para o Jenkins executar nesse estágio.
Obtenha os artefatos mais recentes do repositório de terceiros
O primeiro estágio desse pipeline do Jenkins, o estágio Checkout, é definido da seguinte forma:
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
Essa etapa garante que o diretório de trabalho que o Jenkins usa em sua máquina de desenvolvimento local tenha os artefatos mais recentes do repositório Git de terceiros. Normalmente, o Jenkins define esse diretório de trabalho como <your-user-home-directory>/.jenkins/workspace/<pipeline-name>. Isso permite que o senhor, na mesma máquina de desenvolvimento local, mantenha sua própria cópia de artefatos em desenvolvimento separada dos artefatos que o Jenkins usa do seu repositório Git de terceiros.
Validar o pacote Databricks ativo
O segundo estágio desse pipeline do Jenkins, o estágio Validate Bundle, é definido da seguinte forma:
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
Esta etapa garante que o pacote, que define o fluxo de trabalho para testar e executar seus artefatos, esteja sintaticamente correto. Os Declarative Automation Bundles permitem expressar análises de dados completas e projetos ML como uma coleção de arquivos de origem. Veja O que são pacotes de automação declarativa?
Para definir o pacote para esse artigo, crie um arquivo chamado databricks.yml na raiz do repositório clonado em seu computador local. Neste exemplo de arquivo databricks.yml, substitua os seguintes espaços reservados:
- Substitua
<bundle-name>por um nome programático exclusivo para o pacote. Por exemplo, isso pode serjenkins-demo. - Substitua
<job-prefix-name>por algumas cadeias de caracteres para ajudar a identificar exclusivamente o trabalho que é criado em seu workspace para este exemplo. Por exemplo, isso pode serjenkins-demo. Ele deve corresponder ao valorJOBPREFIXem seu arquivo Jenkins. - Substitua
<spark-version-id>pelo ID da versão Databricks Runtime do seu Job clustering, por exemplo,13.3.x-scala2.12. - Substitua
<cluster-node-type-id>pelo ID do tipo de nó do Job clustering, por exemplo,n2-highmem-4. - Observe que
devno mapeamentotargetsé o mesmo queBUNDLETARGETem seu arquivo Jenkins. Um destino de pacote especifica o host e os comportamentos de implantação relacionados.
Aqui está o arquivo databricks.yml, que deve ser adicionado à raiz do seu repositório para que este exemplo funcione corretamente:
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
data_security_mode: SINGLE_USER
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: '/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl'
evaluate-notebook-runs:
name: ${var.job_prefix}-evaluate-notebook-runs
tasks:
- task_key: ${var.job_prefix}-evaluate-notebook-runs-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
spark_python_task:
python_file: ./evaluate_notebook_runs.py
source: WORKSPACE
libraries:
- pypi:
package: unittest-xml-reporting
targets:
dev:
mode: development
Para obter mais informações sobre o arquivo databricks.yml , consulte Configuração de pacotes de automação declarativa.
implantado o pacote em seu workspace
O terceiro estágio do pipeline Jenkins, intitulado Deploy Bundle, é definido da seguinte forma:
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
Esse estágio faz duas coisas:
- Como o mapeamento
artifactno arquivodatabricks.ymlestá definido comowhl, isso instrui o Databricks CLI a criar o arquivo Python wheel usando o arquivosetup.pyno local especificado. - Após a criação do arquivo Python wheel em sua máquina de desenvolvimento local, a CLI Databricks implanta o arquivo Python wheel criado, juntamente com os arquivos Python e o Notebook especificados, em seu workspace Databricks . Por default, os pacotes de automação declarativa implantam o arquivo Python wheel e outros arquivos em
/Workspace/Users/<your-username>/.bundle/<bundle-name>/<target-name>.
Para permitir que o arquivo Python wheel seja criado conforme especificado no arquivo databricks.yml, crie as seguintes pastas e arquivos na raiz do repositório clonado em seu computador local.
Para definir a lógica e os testes unitários para o arquivo Python wheel que o Notebook executará, crie dois arquivos chamados addcol.py e test_addcol.py e adicione-os a uma estrutura de pastas chamada python/dabdemo/dabdemo dentro da pasta Libraries do seu diretório:
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ └── dabdemo
│ ├── addcol.py
│ └── test_addcol.py
├── ...
O arquivo addcol.py contém uma função de biblioteca que é posteriormente compilada em um arquivo Python wheel e então instalada em um cluster Databricks . Esta função adiciona uma nova coluna, preenchida com um valor literal, a um DataFrame do Apache Spark:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
O arquivo test_addcol.py contém testes para passar um objeto DataFrame simulado para a função with_status, definida em addcol.py. O resultado do
é então comparado a um objeto DataFrame que contém os valores esperados. Se os valores corresponderem, o que acontece nesse caso, o teste será aprovado:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Para permitir que a CLI Databricks empacote corretamente este código de biblioteca em um arquivo Python wheel , crie dois arquivos chamados __init__.py e __main__.py na mesma pasta que os dois arquivos anteriores. Além disso, crie um arquivo chamado setup.py na pasta python/dabdemo :
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ ├── dabdemo
│ │ ├── __init__.py
│ │ ├── __main__.py
│ │ ├── addcol.py
│ │ └── test_addcol.py
│ └── setup.py
├── ...
O arquivo __init__.py contém o número da versão da biblioteca e o autor. Substitua <my-author-name> pelo seu nome:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
O arquivo __main__.py contém o ponto de entrada da biblioteca:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
O arquivo setup.py contém configurações adicionais para criar a biblioteca em um arquivo Python wheel. Substitua <my-url>, <my-author-name>@<my-organization> e <my-package-description> por valores significativos:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Teste a lógica dos componentes do site Python wheel
O estágio Run Unit Tests, o quarto estágio deste pipeline do Jenkins, usa o pytest para testar a lógica de uma biblioteca e garantir que ela funcione como foi construída. Esse estágio é definido da seguinte forma:
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
Essa etapa usa o site Databricks CLI para executar um trabalho de notebook. Este trabalho executa o Notebook Python com o nome de arquivo run-unit-test.py. A execução do Notebook pytest contraria a lógica da biblioteca.
Para executar os testes de unidade deste exemplo, adicione um arquivo do Notebook Python chamado run_unit_tests.py com o seguinte conteúdo à raiz do repositório clonado em seu computador local:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Use o Python wheel
A quinta etapa desse pipeline do Jenkins, intitulada Run Notebook, executa um notebook Python que chama a lógica no arquivo Python wheel criado, como segue:
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
Esse estágio executa o Databricks CLI, que, por sua vez, instrui o workspace a executar um Notebook Job. Este Notebook cria um objeto DataFrame, passa-o para a função with_status da biblioteca, imprime o resultado e informa os resultados da execução do Job. Crie o Notebook adicionando um arquivo Python Notebook chamado dabdaddemo_notebook.py com o seguinte conteúdo na raiz do repositório clonado em seu computador de desenvolvimento local:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │first_name │last_name │email │status |
# +============+===========+=========================+=========+
# │paula │white │paula.white@example.com │checked |
# +------------+-----------+-------------------------+---------+
# │john │baer │john.baer@example.com │checked |
# +------------+-----------+-------------------------+---------+
Avaliar os resultados da execução do Notebook Job
O estágio Evaluate Notebook Runs, o sexto estágio desse pipeline do Jenkins, avalia os resultados da execução do Notebook Job anterior. Esse estágio é definido da seguinte forma:
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
Essa etapa executa o Databricks CLI, que, por sua vez, instrui o workspace a executar um arquivo Job Python. Esse arquivo Python determina os critérios de falha e sucesso para a execução do Notebook Job e informa esse resultado de falha ou sucesso. Crie um arquivo chamado evaluate_notebook_runs.py com o seguinte conteúdo na raiz do seu repositório clonado em sua máquina de desenvolvimento local:
import unittest
import xmlrunner
import json
import glob
import os
class TestJobOutput(unittest.TestCase):
test_output_path = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output"
def test_performance(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
duration = data['tasks'][0]['execution_duration']
if duration > 100000:
status = 'FAILED'
else:
status = 'SUCCESS'
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
def test_job_run(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
status = data['state']['result_state']
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
if __name__ == '__main__':
unittest.main(
testRunner = xmlrunner.XMLTestRunner(
output = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output/test-results",
),
failfast = False,
buffer = False,
catchbreak = False,
exit = False
)
Importar e relatar resultados de testes
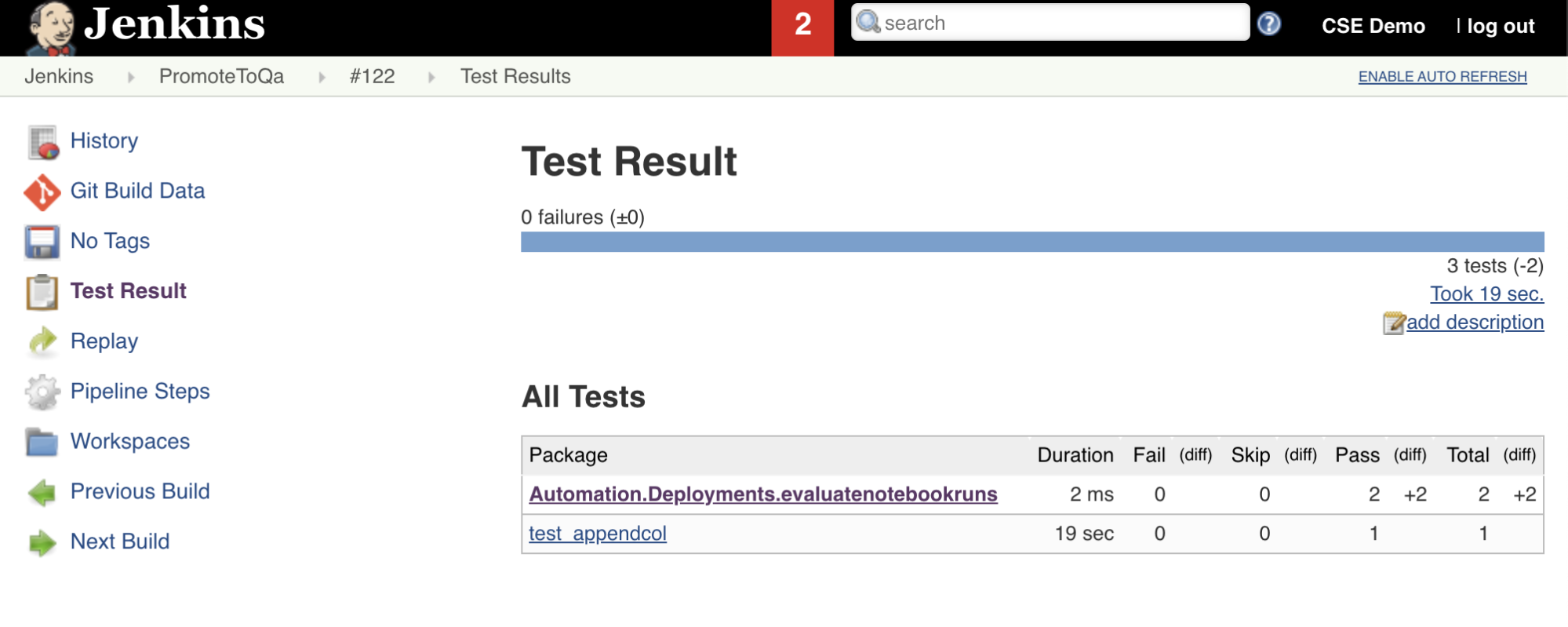
A sétima etapa desse pipeline do Jenkins, intitulada Import Test Results, usa o Databricks CLI para enviar os resultados dos testes do workspace para a máquina de desenvolvimento local. A oitava e última etapa, intitulada Publish Test Results, publica os resultados do teste no Jenkins usando o plugin junit Jenkins. Isso permite que você visualize relatórios e painéis relacionados ao status dos resultados do teste. Esses estágios são definidos da seguinte forma:
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
Envie todas as alterações de código para seu repositório de terceiros
Agora você deve enviar o conteúdo do seu repositório clonado, localizado em sua máquina de desenvolvimento local, para o seu repositório de terceiros. Antes de enviar as alterações, você deve adicionar as seguintes entradas ao arquivo .gitignore no seu repositório clonado, pois provavelmente não é recomendável enviar arquivos de trabalho internos do pacote, relatórios de validação, arquivos de compilação do Python e caches do Python para o seu repositório de terceiros. Normalmente, você desejará gerar novos relatórios de validação e integrar Python wheel mais recente ao seu workspace Databricks , em vez de usar relatórios de validação e versões Python wheel potencialmente desatualizados:
.databricks/
.vscode/
Libraries/python/dabdemo/build/
Libraries/python/dabdemo/__pycache__/
Libraries/python/dabdemo/dabdemo.egg-info/
Validation/
executar seu pipeline Jenkins
Agora você está pronto para executar seu pipeline do Jenkins manualmente. Para fazer isso, acesse o painel de controle do Jenkins:
- Clique no nome do pipeline do Jenkins.
- Na barra lateral, clique em Criar agora .
- Para ver os resultados, clique na última execução do pipeline (por exemplo,
#1) e, em seguida, clique em Console Output (Saída do console ).
Nesse ponto, o pipeline de CI/CD concluiu um ciclo de integração e implantação. Ao automatizar esse processo, o senhor pode garantir que seu código seja testado e implantado por um processo eficiente, consistente e repetível. Para instruir o provedor terceirizado Git a executar o Jenkins sempre que ocorrer um evento específico, como uma solicitação de pull do repositório, consulte a documentação do provedor terceirizado Git.