Databricks Connect para 12.2 e abaixo Databricks Runtime LTS
Databricks Connect para Databricks Runtime 12.2 LTS e versões anteriores está obsoleto. O Databricks Runtime 12.2 LTS e todas as versões LTS anteriores chegaram ao fim do suporte. Use Databricks Connect para Databricks Runtime 13.3 LTS e versões superiores . Para obter informações sobre como migrar do Databricks Connect para Databricks Runtime 12.2 LTS e versões anteriores para Databricks Connect para Databricks Runtime 13.3 LTS e versões superiores, consulte Migrar para Databricks Connect para Python ou Migrar para Databricks Connect para Scala.
Databricks Connect permite que o senhor conecte IDEs populares, como Visual Studio Code e PyCharm, servidores Notebook e outros aplicativos personalizados ao Databricks clustering.
Este artigo explica como o Databricks Connect funciona, orienta você nas passos para começar a usar o Databricks Connect, explica como solucionar problemas que podem surgir ao usar o Databricks Connect e as diferenças entre a execução usando o Databricks Connect e a execução em um Databricks Notebook.
Visão geral
O Databricks Connect é uma biblioteca cliente para o Databricks Runtime. Ele permite que o senhor escreva trabalhos usando Spark APIs e os execute remotamente em um clustering Databricks em vez de na sessão local Spark.
Por exemplo, quando o senhor executa o comando DataFrame spark.read.format(...).load(...).groupBy(...).agg(...).show() usando Databricks Connect, a representação lógica do comando é enviada para o servidor Spark em execução em Databricks para execução no clustering remoto.
Com o Databricks Connect, o senhor pode:
- execução large-escala Spark Job de qualquer aplicativo Python, R, Scala, ou Java. Em qualquer lugar que possa
import pyspark,require(SparkR)ouimport org.apache.spark, o senhor pode agora executar Spark Job diretamente do seu aplicativo, sem precisar instalar nenhum plug-in de IDE ou usar scripts de envio Spark. - passo e código de depuração em seu IDE, mesmo ao trabalhar com clusters remotos.
- Iterar rapidamente ao desenvolver a biblioteca. O senhor não precisa reiniciar o clustering depois de alterar as dependências de Python ou Java biblioteca em Databricks Connect, porque cada sessão de cliente é isolada uma da outra no clustering.
- Encerrar o clustering parado sem perder o trabalho. Como o aplicativo cliente é desacoplado do clustering, ele não é afetado por reinicializações ou atualizações do clustering, o que normalmente faria com que o senhor perdesse todas as variáveis, RDDs e objetos DataFrame definidos em um Notebook.
Para o desenvolvimento do Python com consultas SQL, o Databricks recomenda que o senhor use o Databricks SQL Connector for Python em vez do Databricks Connect. O Databricks SQL Connector for Python é mais fácil de configurar do que o Databricks Connect. Além disso, o site Databricks Connect analisa e planeja a execução do trabalho no computador local, enquanto a execução do trabalho no computador remoto compute recurso. Isso pode tornar especialmente difícil depurar erros de tempo de execução. O conector Databricks SQL para Python envia consultas SQL diretamente para o recurso remoto compute e obtém os resultados.
Requisitos
Esta seção lista os requisitos para o Databricks Connect.
-
Somente as seguintes versões do Databricks Runtime são compatíveis:
- Databricks Runtime 12.2 LTS ML, Databricks Runtime 12.2 LTS
- Databricks Runtime 11.3 LTS ML, Databricks Runtime 11.3 LTS
- Databricks Runtime 10.4 LTS ML, Databricks Runtime 10.4 LTS
- Databricks Runtime 9.1 LTS ML, Databricks Runtime 9.1 LTS
- Databricks Runtime 7.3 LTS
-
Python O senhor deve instalar o Python 3 no computador de desenvolvimento e a versão secundária da instalação do cliente Python deve ser a mesma que a versão secundária do cluster Databricks. A tabela a seguir mostra a versão do Python instalada com cada Databricks Runtime.
Versão do Databricks Runtime
Versão do Python
12,2 LTS ML, 12,2 LTS
3.9
11,3 LTS ML, 11,3 LTS
3.9
10,4 LTS ML, 10,4 LTS
3.8
9,1 LTS ML, 9,1 LTS
3.8
7.3 LTS
3.7
A Databricks recomenda enfaticamente que o senhor tenha um ambiente virtual Python ativado para cada versão do Python que usar com o Databricks Connect. Os ambientes virtuais Python ajudam a garantir que o senhor esteja usando as versões corretas do Python e do Databricks Connect juntos. Isso pode ajudar a reduzir o tempo gasto na resolução de problemas técnicos relacionados.
Por exemplo, se estiver usando o venv na máquina de desenvolvimento e o clustering estiver executando o Python 3.9, o senhor deverá criar um ambiente
venvcom essa versão. O comando de exemplo a seguir gera os scripts para ativar um ambientevenvcom o Python 3.9 e esse comando coloca esses scripts em uma pasta oculta chamada.venvno diretório de trabalho atual:Bash# Linux and macOS
python3.9 -m venv ./.venv
# Windows
python3.9 -m venv .\.venvPara usar esses scripts para ativar esse ambiente
venv, consulte Como funcionam os venvs.Como outro exemplo, se o senhor estiver usando Conda na máquina de desenvolvimento e o cluster estiver executando o Python 3.9, o senhor deverá criar um ambiente Conda com essa versão, por exemplo:
Bashconda create --name dbconnect python=3.9Para ativar o ambiente Conda com esse nome de ambiente, execute
conda activate dbconnect. -
A versão maior e menor do pacote do Databricks Connect deve sempre corresponder à versão do Databricks Runtime. A Databricks recomenda que o senhor sempre use o pacote mais recente do Databricks Connect que corresponda à sua versão do Databricks Runtime. Por exemplo, quando o senhor usa um Databricks Runtime 12.2 LTS clustering, também deve usar o pacote
databricks-connect==12.2.*.
Consulte o site Databricks Connect notas sobre a versão para obter uma lista das versões e atualizações de manutenção disponíveis no site Databricks Connect.
- Java Runtime Environment (JRE) 8. O cliente foi testado com o OpenJDK 8 JRE. O cliente não é compatível com Java 11.
No Windows, se o senhor vir um erro informando que o Databricks Connect não consegue localizar winutils.exe, consulte Cannot find winutils.exe on Windows.
Configurar o cliente
Conclua as passos a seguir para configurar o cliente local para Databricks Connect.
Antes de começar a configurar o cliente local do Databricks Connect, o senhor deve atender aos requisitos do Databricks Connect.
Etapa 1: Instalar o cliente Databricks Connect
-
Com seu ambiente virtual ativado, desinstale o PySpark, se ele já estiver instalado, executando o comando
uninstall. Isso é necessário porque o pacotedatabricks-connectentra em conflito com o PySpark. Para obter detalhes, consulte Instalações conflitantes do PySpark. Para verificar se o site PySpark já está instalado, execute o comandoshow.Bash# Is PySpark already installed?
pip3 show pyspark
# Uninstall PySpark
pip3 uninstall pyspark -
Com seu ambiente virtual ainda ativado, instale o cliente Databricks Connect executando o comando
install. Use a opção--upgradepara atualizar qualquer instalação de cliente existente para a versão especificada.Bashpip3 install --upgrade "databricks-connect==12.2.*" # Or X.Y.* to match your cluster version.
A Databricks recomenda que o senhor acrescente a notação "dot-asterisk" para especificar databricks-connect==X.Y.* em vez de databricks-connect=X.Y, para garantir que o pacote mais recente seja instalado.
Etapa 2: Configurar as propriedades da conexão
-
Colete as seguintes propriedades de configuração.
-
O Databricks workspaceURL.
-
Seus Databricks tokens de acesso pessoal.
-
O ID de seu clustering. O senhor pode obter o ID do clustering no URL. Aqui, o ID de clustering é
0304-201045-hoary804.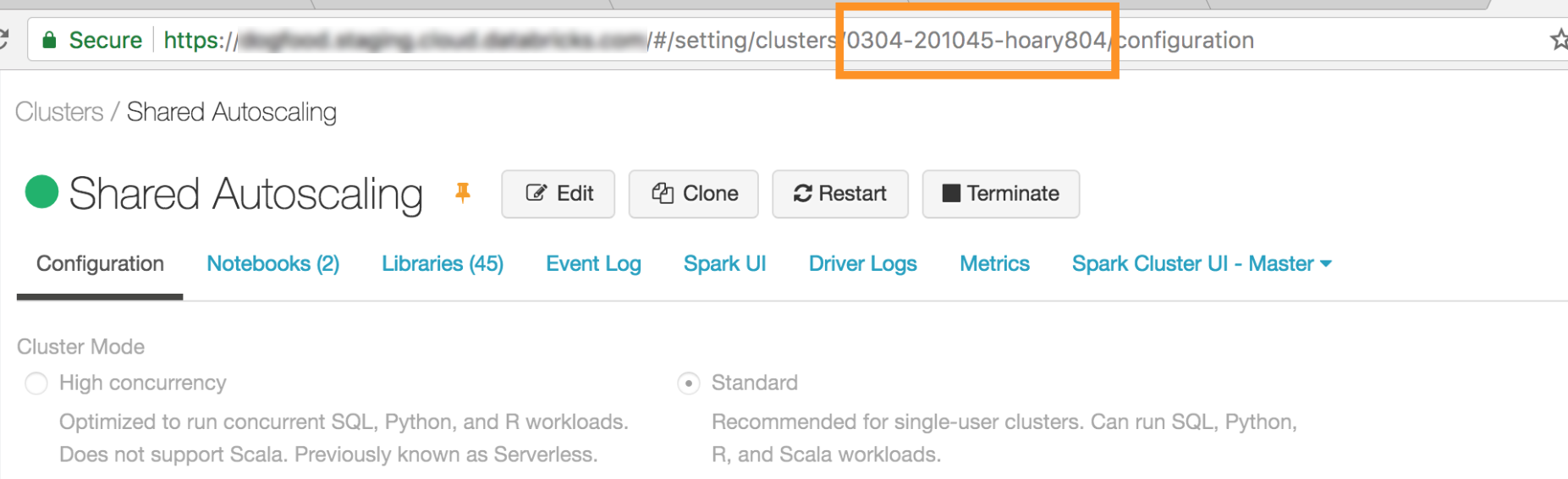
-
A porta à qual Databricks Connect se conecta em seu cluster. A porta default é
15001.
-
-
Configure a conexão da seguinte forma.
O senhor pode usar CLI, SQL configs ou variável de ambiente. A precedência dos métodos de configuração, do mais alto para o mais baixo, é: SQL config key, CLI e variável de ambiente.
-
CLIPE
- Execute
databricks-connect.
Bashdatabricks-connect configureA licença exibe:
Copyright (2018) Databricks, Inc.
This library (the "Software") may not be used except in connection with the
Licensee's use of the Databricks Platform Services pursuant to an Agreement
...- Aceite a licença e forneça os valores de configuração. Para Databricks Host e Databricks tokens , digite o URL workspace e os tokens de acesso pessoal que o senhor anotou na Etapa 1.
Do you accept the above agreement? [y/N] y
Set new config values (leave input empty to accept default):
Databricks Host [no current value, must start with https://]: <databricks-url>
Databricks Token [no current value]: <databricks-token>
Cluster ID (e.g., 0921-001415-jelly628) [no current value]: <cluster-id>
Org ID (Azure-only, see ?o=orgId in URL) [0]: <org-id>
Port [15001]: <port> - Execute
-
SQL configs ou variável de ambiente. A tabela a seguir mostra a key de configuração SQL e a variável de ambiente que correspondem às propriedades de configuração que você anotou na passo 1. Para definir uma key de configuração SQL, use
sql("set config=value"). Por exemplo:sql("set spark.databricks.service.clusterId=0304-201045-abcdefgh").Parâmetro
SQL configurar key
Nome da variável de ambiente
Hospedeiro do Databricks
spark.databricks.serviço.address
ENDEREÇO_DE_DADOS
Token de Databricks
spark.databricks.serviço.tokens
DATABRICKS_API_TOKEN
clusterId
spark.databricks.serviço.clusterId
agrupamento
ID da organização
spark.databricks.serviço.orgId
DATABRICKS_ORG_ID
Porta
spark.databricks.serviço.port
DATABRICKS_PORT
-
-
Com seu ambiente virtual ainda ativado, teste a conectividade com o Databricks da seguinte forma.
Bashdatabricks-connect testSe o clustering que o senhor configurou não estiver em execução, o teste iniciará o clustering, que permanecerá em execução até o horário de encerramento automático configurado. A saída deve ser semelhante à seguinte:
* PySpark is installed at /.../.../pyspark
* Checking java version
java version "1.8..."
Java(TM) SE Runtime Environment (build 1.8...)
Java HotSpot(TM) 64-Bit Server VM (build 25..., mixed mode)
* Testing scala command
../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set.
../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab..., invalidating prev state
../../.. ..:..:.. WARN SparkServiceRPCClient: Syncing 129 files (176036 bytes) took 3003 ms
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2...
/_/
Using Scala version 2.... (Java HotSpot(TM) 64-Bit Server VM, Java 1.8...)
Type in expressions to have them evaluated.
Type :help for more information.
scala> spark.range(100).reduce(_ + _)
Spark context Web UI available at https://...
Spark context available as 'sc' (master = local[*], app id = local-...).
Spark session available as 'spark'.
View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUi
View job details at <databricks-url>?o=0#/setting/clusters/<cluster-id>/sparkUi
res0: Long = 4950
scala> :quit
* Testing python command
../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
../../.. ..:..:.. WARN MetricsSystem: Using default name SparkStatusTracker for source because neither spark.metrics.namespace nor spark.app.id is set.
../../.. ..:..:.. WARN SparkServiceRPCClient: Now tracking server state for 5ab.., invalidating prev state
View job details at <databricks-url>/?o=0#/setting/clusters/<cluster-id>/sparkUi -
Se nenhum erro relacionado à conexão for exibido (as mensagens
WARNestão corretas), então você se conectou com sucesso.
Usar o Databricks Connect
A seção descreve como configurar o servidor IDE ou Notebook de sua preferência para usar o cliente para Databricks Connect.
Nesta secção:
- JupyterLab
- Classic Jupyter Notebook
- PyCharm
- SparkR e RStudio Desktop
- Sparklyr e RStudio Desktop
- IntelliJ (Scala ou Java)
- PyDev com o Eclipse
- Eclipse
- SBT
- Shell Spark
Jupyter Lab
Antes de começar a usar o Databricks Connect, o senhor deve atender aos requisitos e configurar o cliente para o Databricks Connect.
Para usar o Databricks Connect com o JupyterLab e o Python, siga estas instruções.
-
Para instalar o JupyterLab, com o ambiente virtual Python ativado, execute o seguinte comando no terminal ou no Prompt de comando:
Bashpip3 install jupyterlab -
Para iniciar o JupyterLab em seu navegador da Web, execute o seguinte comando a partir do ambiente virtual Python ativado:
Bashjupyter labSe o JupyterLab não aparecer em seu navegador da Web, copie o URL que começa com
localhostou127.0.0.1de seu ambiente virtual e insira-o na barra de endereços do navegador da Web. -
Crie um novo Notebook: no JupyterLab, clique em File > New > Notebook no menu principal, selecione Python 3 (ipykernel) e clique em Select .
-
Na primeira célula do Notebook, digite o código de exemplo ou seu próprio código. Se você usa seu próprio código, no mínimo deve instanciar uma instância de
SparkSession.builder.getOrCreate(), conforme mostrado no código de exemplo. -
Para executar o Notebook, clique em executar > executar All Cells .
-
Para depurar o Notebook, clique no ícone de bug (Enable Debugger ) ao lado de Python 3 (ipykernel) na barra de ferramentas do Notebook. Defina um ou mais pontos de interrupção e, em seguida, clique em executar > executar All Cells .
-
Para desligar o JupyterLab, clique em Arquivo > Desligar. Se o processo do JupyterLab ainda estiver em execução no terminal ou no prompt de comando, interrompa esse processo pressionando
Ctrl + ce, em seguida, digitandoypara confirmar.
Para obter instruções de depuração mais específicas, consulte Depurador.
Jupyter Notebook clássico
Antes de começar a usar o Databricks Connect, o senhor deve atender aos requisitos e configurar o cliente para o Databricks Connect.
O script de configuração do Databricks Connect adiciona automaticamente o pacote à configuração do seu projeto. Para começar em um kernel Python, execute:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
Para ativar a abreviação %sql para executar e visualizar consultas SQL, use o seguinte snippet:
from IPython.core.magic import line_magic, line_cell_magic, Magics, magics_class
@magics_class
class DatabricksConnectMagics(Magics):
@line_cell_magic
def sql(self, line, cell=None):
if cell and line:
raise ValueError("Line must be empty for cell magic", line)
try:
from autovizwidget.widget.utils import display_dataframe
except ImportError:
print("Please run `pip install autovizwidget` to enable the visualization widget.")
display_dataframe = lambda x: x
return display_dataframe(self.get_spark().sql(cell or line).toPandas())
def get_spark(self):
user_ns = get_ipython().user_ns
if "spark" in user_ns:
return user_ns["spark"]
else:
from pyspark.sql import SparkSession
user_ns["spark"] = SparkSession.builder.getOrCreate()
return user_ns["spark"]
ip = get_ipython()
ip.register_magics(DatabricksConnectMagics)
Código do Visual Studio
Antes de começar a usar o Databricks Connect, o senhor deve atender aos requisitos e configurar o cliente para o Databricks Connect.
Para usar o Databricks Connect com o Visual Studio Code, faça o seguinte:
-
Verifique se a extensão Python está instalada.
-
Abra a paleta do comando (comando+Shift+P no macOS e Ctrl+Shift+P no Windows/Linux).
-
Selecione um interpretador Python. Vá para Código > Preferências > Configurações e escolha Python settings .
-
Execute
databricks-connect get-jar-dir. -
Adicione o diretório retornado pelo comando ao JSON de configurações do usuário em
python.venvPath. Isso deve ser adicionado à configuração do Python. -
Desative o linter. Clique em ... no lado direito e edite as configurações de JSON . As configurações modificadas são as seguintes:
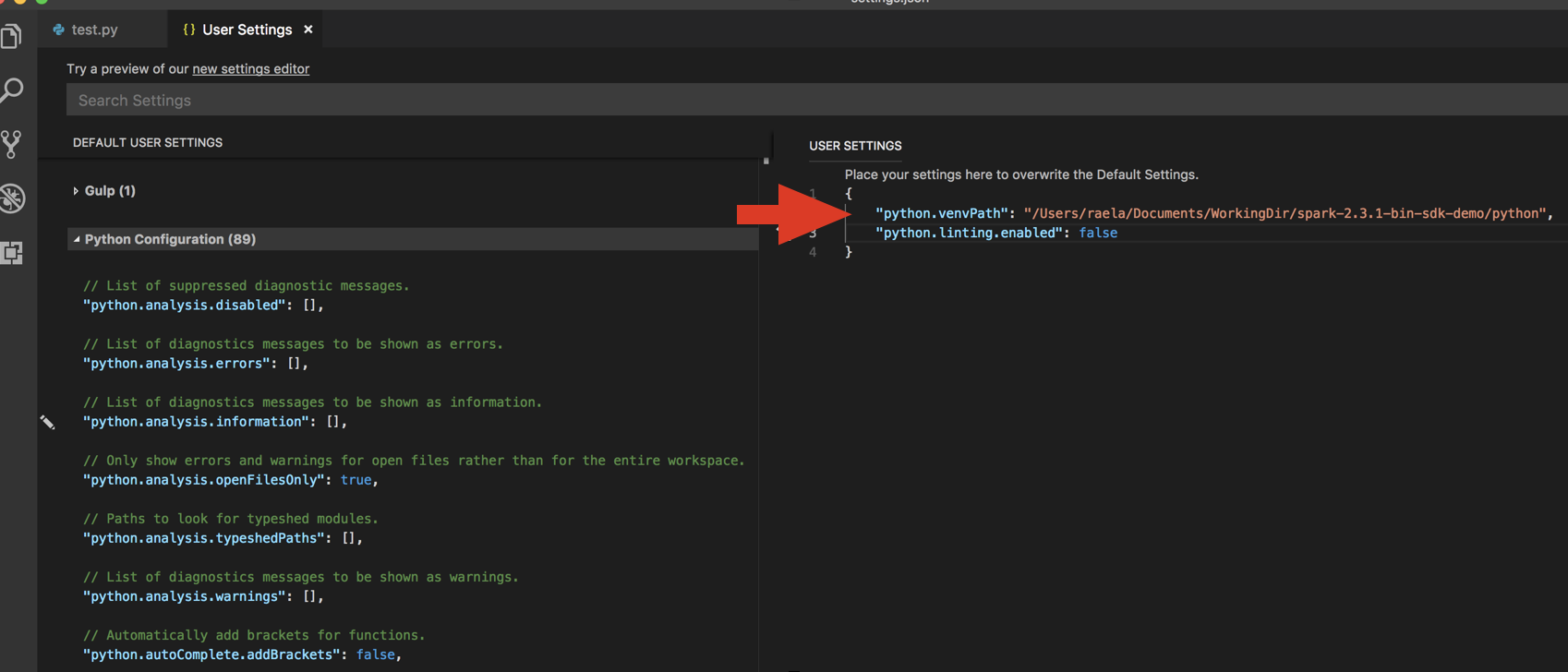
-
Se estiver executando com um ambiente virtual, que é a maneira recomendada de desenvolver para Python no VS Code, na paleta de comando, digite
select python interpretere aponte para o ambiente que corresponde à versão do Python de clustering.
Por exemplo, se o seu clustering for Python 3.9, seu ambiente de desenvolvimento deverá ser Python 3.9.

PyCharm
Antes de começar a usar o Databricks Connect, o senhor deve atender aos requisitos e configurar o cliente para o Databricks Connect.
O script de configuração do Databricks Connect adiciona automaticamente o pacote à configuração do seu projeto.
Python 3 agrupamento
-
Quando o senhor criar um projeto PyCharm, selecione Existing Interpreter (Interpretador existente ). No menu suspenso, selecione o ambiente Conda que o senhor criou (consulte Requisitos).

-
Acesse o site > Edit Configurations .
-
Adicione
PYSPARK_PYTHON=python3como uma variável de ambiente.
SparkR e RStudio Desktop
Antes de começar a usar o Databricks Connect, o senhor deve atender aos requisitos e configurar o cliente para o Databricks Connect.
Para usar o Databricks Connect com o SparkR e o RStudio Desktop, faça o seguinte:
-
Faça o download e descompacte a distribuição Spark de código aberto em sua máquina de desenvolvimento. Escolha a mesma versão do seu clustering Databricks (Hadoop 2.7).
-
execução
databricks-connect get-jar-dir. Esse comando retorna um caminho como/usr/local/lib/python3.5/dist-packages/pyspark/jars. Copie o caminho do arquivo de um diretório acima do caminho do arquivo do diretório JAR, por exemplo,/usr/local/lib/python3.5/dist-packages/pyspark, que é o diretórioSPARK_HOME. -
Configure o caminho da biblioteca do Spark e a página inicial do Spark adicionando-os ao topo do seu script R. Defina
<spark-lib-path>para o diretório onde você descompactou o pacote Spark de código aberto na passo 1. Defina<spark-home-path>para o diretório Databricks Connect da passo 2.R# Point to the OSS package path, e.g., /path/to/.../spark-2.4.0-bin-hadoop2.7
library(SparkR, lib.loc = .libPaths(c(file.path('<spark-lib-path>', 'R', 'lib'), .libPaths())))
# Point to the Databricks Connect PySpark installation, e.g., /path/to/.../pyspark
Sys.setenv(SPARK_HOME = "<spark-home-path>") -
Inicie uma sessão Spark e comece a executar SparkR comando.
RsparkR.session()
df <- as.DataFrame(faithful)
head(df)
df1 <- dapply(df, function(x) { x }, schema(df))
collect(df1)
Sparklyr e Desktop RStudio
Antes de começar a usar o Databricks Connect, o senhor deve atender aos requisitos e configurar o cliente para o Databricks Connect.
Visualização
Esse recurso está em Public Preview.
O senhor pode copiar o código dependente do sparklyr que desenvolveu localmente usando Databricks Connect e executá-lo em um notebook Databricks ou em um servidor RStudio hospedado em seu Databricks workspace com o mínimo ou nenhuma alteração no código.
Nesta secção:
Requisitos
- sparklyr 1.2 ouacima.
- Databricks Runtime 7.3 LTS ouacima com a versão correspondente do Databricks Connect.
Instalar, configurar e usar Sparklyr
-
No RStudio Desktop, instale o sparklyr 1.2 ouacima do CRAN ou instale a versão master mais recente do GitHub.
R# Install from CRAN
install.packages("sparklyr")
# Or install the latest master version from GitHub
install.packages("devtools")
devtools::install_github("sparklyr/sparklyr") -
Ative o ambiente Python com a versão correta do Databricks Connect instalada e execute o seguinte comando no terminal para obter o
<spark-home-path>:Bashdatabricks-connect get-spark-home -
Inicie uma sessão Spark e comece a executar Sparklyr comando.
Rlibrary(sparklyr)
sc <- spark_connect(method = "databricks", spark_home = "<spark-home-path>")
iris_tbl <- copy_to(sc, iris, overwrite = TRUE)
library(dplyr)
src_tbls(sc)
iris_tbl %>% count -
Feche a conexão.
Rspark_disconnect(sc)
recurso
Para obter mais informações, consulte o Sparklyr GitHub LEIAME do site .
Para obter exemplos de código, consulte Sparklyr.
Sparklyr e Limitações do desktop RStudio
Os seguintes recursos não são suportados:
- Sparklyr transmissão APIs
- Sparklyr ML APIs
- APIs da vassoura
- modo de serialização csv_file
- Spark Submit
IntelliJ (Scala ou Java)
Antes de começar a usar o Databricks Connect, o senhor deve atender aos requisitos e configurar o cliente para o Databricks Connect.
Para usar o Databricks Connect com o IntelliJ (Scala ou Java), faça o seguinte:
-
Execute
databricks-connect get-jar-dir. -
Aponta as dependências para o diretório retornado pelo comando. Vá para o Arquivo > Estrutura do projeto > Módulos > Dependências > '+' sign > JARs ou diretórios.
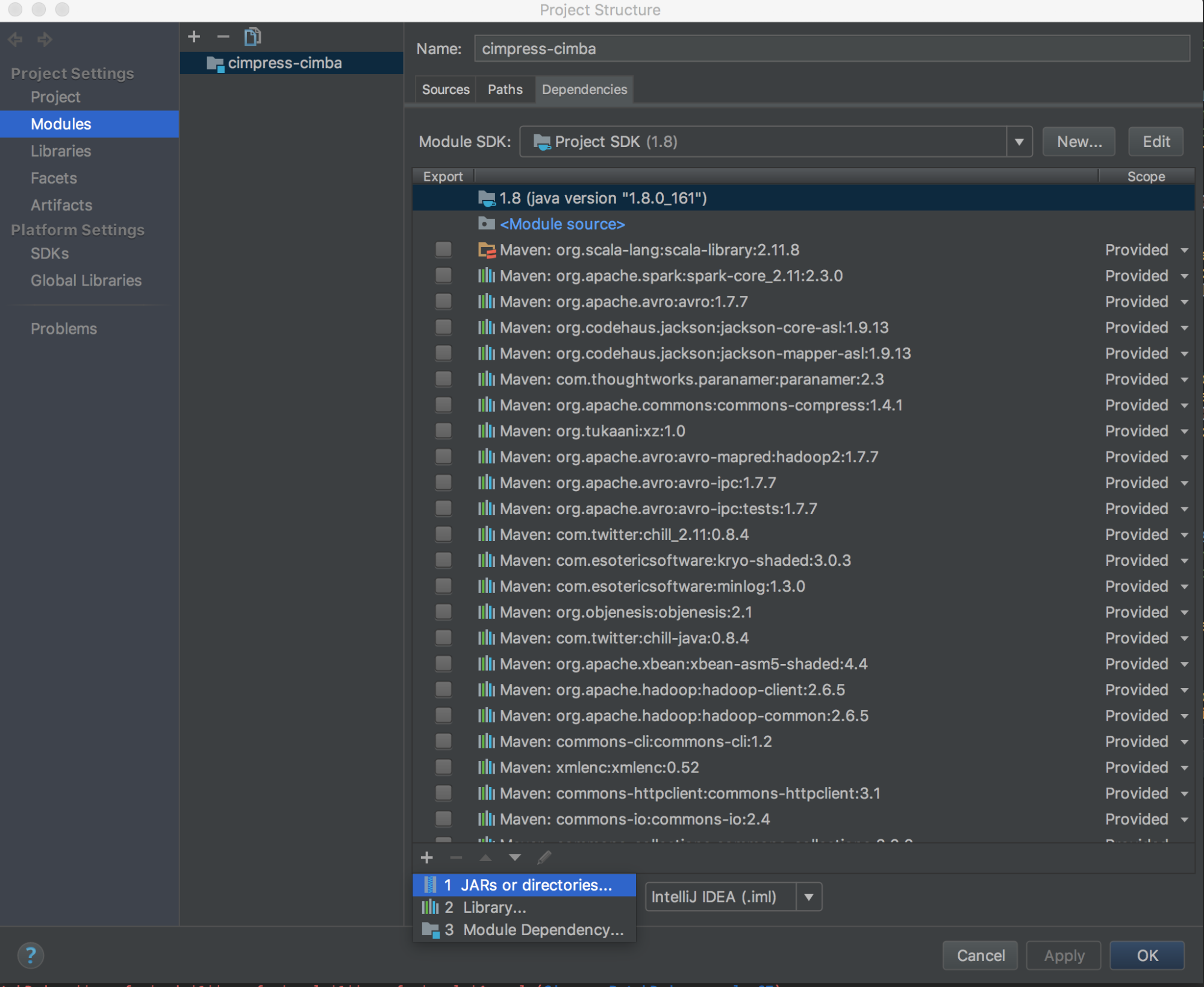
Para evitar conflitos, é altamente recomendável remover quaisquer outras instalações do Spark de seu classpath. Se isso não for possível, certifique-se de que os JARs adicionados estejam na frente do classpath. Em particular, eles devem estar à frente de qualquer outra versão instalada do Spark (caso contrário, o senhor usará uma dessas outras versões do Spark e executará localmente ou lançará um
ClassDefNotFoundError). -
Verifique a configuração da opção breakout no IntelliJ. O site default é All e causará timeouts de rede se o senhor definir breakpoints para depuração. Defina-o como Thread para evitar interromper os threads de rede em segundo plano.

PyDev com o Eclipse
Antes de começar a usar o Databricks Connect, o senhor deve atender aos requisitos e configurar o cliente para o Databricks Connect.
Para usar o Databricks Connect e o PyDev com o Eclipse, siga estas instruções.
- Eclipse.
- Crie um projeto: clique em Arquivo > Novo > Projeto > PyDev > Projeto PyDev e clique em Avançar.
- Especifique um nome de projeto .
- Para o conteúdo do projeto , especifique o caminho para o ambiente virtual do Python.
- Clique em Configure um intérprete antes de continuar .
- Clique em Configuração manual.
- Clique em New > Browse for Python /pypy exe.
- Navegue até o caminho completo do interpretador Python referenciado no ambiente virtual e selecione-o. Em seguida, clique em Open .
- Na caixa de diálogo Selecionar intérprete , clique em OK.
- Na caixa de diálogo Seleção necessária , clique em OK .
- Na caixa de diálogo Preferências , clique em Aplicar e fechar .
- Na caixa de diálogo Projeto PyDev , clique em Concluir.
- Clique em Abrir perspectiva .
- Adicione ao projeto um arquivo de código Python (
.py) que contenha o código de exemplo ou seu próprio código. Se você usa seu próprio código, no mínimo deve instanciar uma instância deSparkSession.builder.getOrCreate(), conforme mostrado no código de exemplo. - Com o arquivo de código Python aberto, defina os pontos de interrupção em que deseja que o código faça uma pausa durante a execução.
- Clique em execução > execução ou execução > Debug .
Para obter instruções mais específicas sobre execução e depuração, consulte Execução de um programa.
Eclipse
Antes de começar a usar o Databricks Connect, o senhor deve atender aos requisitos e configurar o cliente para o Databricks Connect.
Para usar o Databricks Connect e o Eclipse, faça o seguinte:
-
Execute
databricks-connect get-jar-dir. -
Aponte a configuração de JARs externos para o diretório retornado pelo comando. Acesse o menu Project (Projeto) > Properties (Propriedades) > Java Build Path (Caminho de compilação) > biblioteca > Add External Jars (Adicionar jars externos ).

Para evitar conflitos, é altamente recomendável remover quaisquer outras instalações do Spark de seu classpath. Se isso não for possível, certifique-se de que os JARs adicionados estejam na frente do classpath. Em particular, eles devem estar à frente de qualquer outra versão instalada do Spark (caso contrário, o senhor usará uma dessas outras versões do Spark e executará localmente ou lançará um
ClassDefNotFoundError).
SBT
Antes de começar a usar o Databricks Connect, o senhor deve atender aos requisitos e configurar o cliente para o Databricks Connect.
Para usar o Databricks Connect com o SBT, o senhor deve configurar o arquivo build.sbt para vincular-se aos JARs do Databricks Connect em vez da dependência usual da biblioteca do Spark. O senhor faz isso com a diretiva unmanagedBase no seguinte exemplo de arquivo de compilação, que pressupõe um aplicativo Scala que tem um objeto principal com.example.Test:
build.sbt
name := "hello-world"
version := "1.0"
scalaVersion := "2.11.6"
// this should be set to the path returned by ``databricks-connect get-jar-dir``
unmanagedBase := new java.io.File("/usr/local/lib/python2.7/dist-packages/pyspark/jars")
mainClass := Some("com.example.Test")
Spark shell
Antes de começar a usar o Databricks Connect, o senhor deve atender aos requisitos e configurar o cliente para o Databricks Connect.
Para usar o Databricks Connect com o Spark shell e Python ou Scala, siga estas instruções.
-
Com o ambiente virtual ativado, certifique-se de que o
databricks-connect testcomando execução com êxito em Set up the client (Configurar o cliente). -
Com seu ambiente virtual ativado, acesse o site Spark shell. Para Python, execute o comando
pyspark. Para Scala, execute o comandospark-shell.Bash# For Python:
pysparkBash# For Scala:
spark-shell -
O shell do Spark é exibido, por exemplo, para Python:
Python 3... (v3...)
[Clang 6... (clang-6...)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3....
/_/
Using Python version 3... (v3...)
Spark context Web UI available at http://...:...
Spark context available as 'sc' (master = local[*], app id = local-...).
SparkSession available as 'spark'.
>>>Para Scala:
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
../../.. ..:..:.. WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://...
Spark context available as 'sc' (master = local[*], app id = local-...).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3...
/_/
Using Scala version 2... (OpenJDK 64-Bit Server VM, Java 1.8...)
Type in expressions to have them evaluated.
Type :help for more information.
scala> -
Consulte Análise interativa com o Spark shell para obter informações sobre como usar o shell Spark shell com Python ou Scala para executar comandos em seu clustering.
Use a variável integrada
sparkpara representar oSparkSessionem seus clusters em execução, por exemplo, para Python:>>> df = spark.read.table("samples.nyctaxi.trips")
>>> df.show(5)
+--------------------+---------------------+-------------+-----------+----------+-----------+
|tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip|
+--------------------+---------------------+-------------+-----------+----------+-----------+
| 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171|
| 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110|
| 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023|
| 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017|
| 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282|
+--------------------+---------------------+-------------+-----------+----------+-----------+
only showing top 5 rowsPara Scala:
>>> val df = spark.read.table("samples.nyctaxi.trips")
>>> df.show(5)
+--------------------+---------------------+-------------+-----------+----------+-----------+
|tpep_pickup_datetime|tpep_dropoff_datetime|trip_distance|fare_amount|pickup_zip|dropoff_zip|
+--------------------+---------------------+-------------+-----------+----------+-----------+
| 2016-02-14 16:52:13| 2016-02-14 17:16:04| 4.94| 19.0| 10282| 10171|
| 2016-02-04 18:44:19| 2016-02-04 18:46:00| 0.28| 3.5| 10110| 10110|
| 2016-02-17 17:13:57| 2016-02-17 17:17:55| 0.7| 5.0| 10103| 10023|
| 2016-02-18 10:36:07| 2016-02-18 10:41:45| 0.8| 6.0| 10022| 10017|
| 2016-02-22 14:14:41| 2016-02-22 14:31:52| 4.51| 17.0| 10110| 10282|
+--------------------+---------------------+-------------+-----------+----------+-----------+
only showing top 5 rows -
Para interromper o Spark shell, pressione
Ctrl + douCtrl + z, ou execute o comandoquit()ouexit()para Python ou:qou:quitpara Scala.
Exemplos de código
Esse exemplo de código simples consulta a tabela especificada e, em seguida, mostra as primeiras 5 linhas da tabela especificada. Para usar uma tabela diferente, ajuste a chamada para spark.read.table.
from pyspark.sql.session import SparkSession
spark = SparkSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
Esse exemplo de código mais longo faz o seguinte:
- Cria um DataFrame na memória.
- Cria uma tabela com o nome
zzz_demo_temps_tableno esquemadefault. Se a tabela com esse nome já existir, ela será excluída primeiro. Para usar um esquema ou tabela diferente, ajuste as chamadas paraspark.sql,temps.write.saveAsTableou ambos. - Salva o conteúdo do DataFrame na tabela.
- executar uma consulta
SELECTsobre o conteúdo da tabela. - Mostra o resultado da consulta.
- Exclui a tabela.
- Python
- Scala
- Java
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from datetime import date
spark = SparkSession.builder.appName('temps-demo').getOrCreate()
# Create a Spark DataFrame consisting of high and low temperatures
# by airport code and date.
schema = StructType([
StructField('AirportCode', StringType(), False),
StructField('Date', DateType(), False),
StructField('TempHighF', IntegerType(), False),
StructField('TempLowF', IntegerType(), False)
])
data = [
[ 'BLI', date(2021, 4, 3), 52, 43],
[ 'BLI', date(2021, 4, 2), 50, 38],
[ 'BLI', date(2021, 4, 1), 52, 41],
[ 'PDX', date(2021, 4, 3), 64, 45],
[ 'PDX', date(2021, 4, 2), 61, 41],
[ 'PDX', date(2021, 4, 1), 66, 39],
[ 'SEA', date(2021, 4, 3), 57, 43],
[ 'SEA', date(2021, 4, 2), 54, 39],
[ 'SEA', date(2021, 4, 1), 56, 41]
]
temps = spark.createDataFrame(data, schema)
# Create a table on the Databricks cluster and then fill
# the table with the DataFrame's contents.
# If the table already exists from a previous run,
# delete it first.
spark.sql('USE default')
spark.sql('DROP TABLE IF EXISTS zzz_demo_temps_table')
temps.write.saveAsTable('zzz_demo_temps_table')
# Query the table on the Databricks cluster, returning rows
# where the airport code is not BLI and the date is later
# than 2021-04-01. Group the results and order by high
# temperature in descending order.
df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " \
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " \
"GROUP BY AirportCode, Date, TempHighF, TempLowF " \
"ORDER BY TempHighF DESC")
df_temps.show()
# Results:
#
# +-----------+----------+---------+--------+
# |AirportCode| Date|TempHighF|TempLowF|
# +-----------+----------+---------+--------+
# | PDX|2021-04-03| 64| 45|
# | PDX|2021-04-02| 61| 41|
# | SEA|2021-04-03| 57| 43|
# | SEA|2021-04-02| 54| 39|
# +-----------+----------+---------+--------+
# Clean up by deleting the table from the Databricks cluster.
spark.sql('DROP TABLE zzz_demo_temps_table')
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import java.sql.Date
object Demo {
def main(args: Array[String]) {
val spark = SparkSession.builder.master("local").getOrCreate()
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
val schema = StructType(Array(
StructField("AirportCode", StringType, false),
StructField("Date", DateType, false),
StructField("TempHighF", IntegerType, false),
StructField("TempLowF", IntegerType, false)
))
val data = List(
Row("BLI", Date.valueOf("2021-04-03"), 52, 43),
Row("BLI", Date.valueOf("2021-04-02"), 50, 38),
Row("BLI", Date.valueOf("2021-04-01"), 52, 41),
Row("PDX", Date.valueOf("2021-04-03"), 64, 45),
Row("PDX", Date.valueOf("2021-04-02"), 61, 41),
Row("PDX", Date.valueOf("2021-04-01"), 66, 39),
Row("SEA", Date.valueOf("2021-04-03"), 57, 43),
Row("SEA", Date.valueOf("2021-04-02"), 54, 39),
Row("SEA", Date.valueOf("2021-04-01"), 56, 41)
)
val rdd = spark.sparkContext.makeRDD(data)
val temps = spark.createDataFrame(rdd, schema)
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default")
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table")
temps.write.saveAsTable("zzz_demo_temps_table")
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
val df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC")
df_temps.show()
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table")
}
}
import java.util.ArrayList;
import java.util.List;
import java.sql.Date;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.Dataset;
public class App {
public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.appName("Temps Demo")
.config("spark.master", "local")
.getOrCreate();
// Create a Spark DataFrame consisting of high and low temperatures
// by airport code and date.
StructType schema = new StructType(new StructField[] {
new StructField("AirportCode", DataTypes.StringType, false, Metadata.empty()),
new StructField("Date", DataTypes.DateType, false, Metadata.empty()),
new StructField("TempHighF", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("TempLowF", DataTypes.IntegerType, false, Metadata.empty()),
});
List<Row> dataList = new ArrayList<Row>();
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-03"), 52, 43));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-02"), 50, 38));
dataList.add(RowFactory.create("BLI", Date.valueOf("2021-04-01"), 52, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-03"), 64, 45));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-02"), 61, 41));
dataList.add(RowFactory.create("PDX", Date.valueOf("2021-04-01"), 66, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-03"), 57, 43));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-02"), 54, 39));
dataList.add(RowFactory.create("SEA", Date.valueOf("2021-04-01"), 56, 41));
Dataset<Row> temps = spark.createDataFrame(dataList, schema);
// Create a table on the Databricks cluster and then fill
// the table with the DataFrame's contents.
// If the table already exists from a previous run,
// delete it first.
spark.sql("USE default");
spark.sql("DROP TABLE IF EXISTS zzz_demo_temps_table");
temps.write().saveAsTable("zzz_demo_temps_table");
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
Dataset<Row> df_temps = spark.sql("SELECT * FROM zzz_demo_temps_table " +
"WHERE AirportCode != 'BLI' AND Date > '2021-04-01' " +
"GROUP BY AirportCode, Date, TempHighF, TempLowF " +
"ORDER BY TempHighF DESC");
df_temps.show();
// Results:
//
// +-----------+----------+---------+--------+
// |AirportCode| Date|TempHighF|TempLowF|
// +-----------+----------+---------+--------+
// | PDX|2021-04-03| 64| 45|
// | PDX|2021-04-02| 61| 41|
// | SEA|2021-04-03| 57| 43|
// | SEA|2021-04-02| 54| 39|
// +-----------+----------+---------+--------+
// Clean up by deleting the table from the Databricks cluster.
spark.sql("DROP TABLE zzz_demo_temps_table");
}
}
Trabalhe com dependências
Normalmente, sua classe principal ou arquivo Python terá outros JARs e arquivos de dependência. Você pode adicionar esses JARs e arquivos de dependência chamando sparkContext.addJar("path-to-the-jar") ou sparkContext.addPyFile("path-to-the-file"). Você também pode adicionar arquivos Egg e arquivos zip com a interface addPyFile(). Toda vez que o senhor executa o código em seu IDE, os JARs e arquivos de dependência são instalados no clustering.
- Python
- Scala
from lib import Foo
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
sc = spark.sparkContext
#sc.setLogLevel("INFO")
print("Testing simple count")
print(spark.range(100).count())
print("Testing addPyFile isolation")
sc.addPyFile("lib.py")
print(sc.parallelize(range(10)).map(lambda i: Foo(2)).collect())
class Foo(object):
def __init__(self, x):
self.x = x
UDFs Python + Java
from pyspark.sql import SparkSession
from pyspark.sql.column import _to_java_column, _to_seq, Column
## In this example, udf.jar contains compiled Java / Scala UDFs:
#package com.example
#
#import org.apache.spark.sql._
#import org.apache.spark.sql.expressions._
#import org.apache.spark.sql.functions.udf
#
#object Test {
# val plusOne: UserDefinedFunction = udf((i: Long) => i + 1)
#}
spark = SparkSession.builder \
.config("spark.jars", "/path/to/udf.jar") \
.getOrCreate()
sc = spark.sparkContext
def plus_one_udf(col):
f = sc._jvm.com.example.Test.plusOne()
return Column(f.apply(_to_seq(sc, [col], _to_java_column)))
sc._jsc.addJar("/path/to/udf.jar")
spark.range(100).withColumn("plusOne", plus_one_udf("id")).show()
package com.example
import org.apache.spark.sql.SparkSession
case class Foo(x: String)
object Test {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
...
.getOrCreate();
spark.sparkContext.setLogLevel("INFO")
println("Running simple show query...")
spark.read.format("parquet").load("/tmp/x").show()
println("Running simple UDF query...")
spark.sparkContext.addJar("./target/scala-2.11/hello-world_2.11-1.0.jar")
spark.udf.register("f", (x: Int) => x + 1)
spark.range(10).selectExpr("f(id)").show()
println("Running custom objects query...")
val objs = spark.sparkContext.parallelize(Seq(Foo("bye"), Foo("hi"))).collect()
println(objs.toSeq)
}
}
Acesse Databricks utilidades
Esta seção descreve como usar Databricks Connect para acessar Databricks utilidades.
O senhor pode usar as utilidades dbutils.fs e dbutils.secrets do módulo de referênciaDatabricks utilidades (dbutils).
Os comandos suportados são dbutils.fs.cp, dbutils.fs.head, dbutils.fs.ls, dbutils.fs.mkdirs, dbutils.fs.mv, dbutils.fs.put, dbutils.fs.rm, dbutils.secrets.get, dbutils.secrets.getBytes, dbutils.secrets.list, dbutils.secrets.listScopes.
Consulte Utilidades do sistema de arquivos (dbutils.fs) ou execução dbutils.fs.help() e utilidades Secrets (dbutils.secrets ) ou execução dbutils.secrets.help().
- Python
- Scala
from pyspark.sql import SparkSession
from pyspark.dbutils import DBUtils
spark = SparkSession.builder.getOrCreate()
dbutils = DBUtils(spark)
print(dbutils.fs.ls("dbfs:/"))
print(dbutils.secrets.listScopes())
Ao usar Databricks Runtime 7.3 LTS ouacima, para acessar o módulo DBUtils de uma maneira que funcione localmente e em clusters Databricks, use o seguinte get_dbutils():
def get_dbutils(spark):
from pyspark.dbutils import DBUtils
return DBUtils(spark)
Caso contrário, use o seguinte get_dbutils():
def get_dbutils(spark):
if spark.conf.get("spark.databricks.service.client.enabled") == "true":
from pyspark.dbutils import DBUtils
return DBUtils(spark)
else:
import IPython
return IPython.get_ipython().user_ns["dbutils"]
val dbutils = com.databricks.service.DBUtils
println(dbutils.fs.ls("dbfs:/"))
println(dbutils.secrets.listScopes())
Copiar arquivos entre sistemas de arquivos locais e remotos
Você pode usar dbutils.fs para copiar arquivos entre seu cliente e sistemas de arquivos remotos. O esquema file:/ se refere ao sistema de arquivos local no cliente.
from pyspark.dbutils import DBUtils
dbutils = DBUtils(spark)
dbutils.fs.cp('file:/home/user/data.csv', 'dbfs:/uploads')
dbutils.fs.cp('dbfs:/output/results.csv', 'file:/home/user/downloads/')
O tamanho máximo do arquivo que pode ser transferido dessa forma é 250 MB.
Habilitar dbutils.secrets.get
Devido a restrições de segurança, a capacidade de chamar dbutils.secrets.get é desativada pelo site default. Entre em contato com o suporte Databricks para habilitar esse recurso para o seu workspace.
Definir as configurações do Hadoop
No cliente, o senhor pode definir as configurações do Hadoop usando a API spark.conf.set, que se aplica às operações SQL e DataFrame. Hadoop As configurações definidas no sparkContext devem ser definidas na configuração de clustering ou usando um Notebook. Isso ocorre porque as configurações definidas em sparkContext não estão vinculadas a sessões de usuário, mas se aplicam a todo o cluster.
Solução de problemas
execução databricks-connect test para verificar se há problemas de conectividade. Esta seção descreve alguns problemas comuns que o senhor pode encontrar com o Databricks Connect e como resolvê-los.
Nesta secção:
- Incompatibilidade de versão do Python
- Servidor não habilitado
- Instalações conflitantes do PySpark
- Conflitante
SPARK_HOME - Entrada
PATHconflitante ou ausente para binários - Configurações de serialização conflitantes no clustering
- Não é possível localizar o site
winutils.exeno Windows - A sintaxe do nome do arquivo, do diretório ou do rótulo do volume está incorreta no Windows
Incompatibilidade de versão do Python
Verifique se a versão do Python que o senhor está usando localmente tem, no mínimo, a mesma versão secundária da versão no clustering (por exemplo, 3.9.16 versus 3.9.15 está OK, 3.9 versus 3.8 não está).
Se tiver várias versões do Python instaladas localmente, certifique-se de que o Databricks Connect esteja usando a versão correta, definindo a variável de ambiente PYSPARK_PYTHON (por exemplo, PYSPARK_PYTHON=python3).
Servidor não habilitado
Certifique-se de que o clustering tenha o servidor Spark ativado com spark.databricks.service.server.enabled true. O senhor deve ver as seguintes linhas no driver log se for o caso:
../../.. ..:..:.. INFO SparkConfUtils$: Set spark config:
spark.databricks.service.server.enabled -> true
...
../../.. ..:..:.. INFO SparkContext: Loading Spark Service RPC Server
../../.. ..:..:.. INFO SparkServiceRPCServer:
Starting Spark Service RPC Server
../../.. ..:..:.. INFO Server: jetty-9...
../../.. ..:..:.. INFO AbstractConnector: Started ServerConnector@6a6c7f42
{HTTP/1.1,[http/1.1]}{0.0.0.0:15001}
../../.. ..:..:.. INFO Server: Started @5879ms
Instalações conflitantes do PySpark
O pacote databricks-connect entra em conflito com o PySpark. Ter ambos instalados causará erros ao inicializar o contexto do Spark no Python. Isso pode se manifestar de várias maneiras, incluindo erros de "transmissão corrompida" ou "classe não encontrada". Se tiver o PySpark instalado em seu ambiente Python, certifique-se de que ele seja desinstalado antes de instalar o databricks-connect. Depois de desinstalar o PySpark, certifique-se de reinstalar totalmente o pacote Databricks Connect:
pip3 uninstall pyspark
pip3 uninstall databricks-connect
pip3 install --upgrade "databricks-connect==12.2.*" # or X.Y.* to match your specific cluster version.
Conflitante SPARK_HOME
Se o senhor já usou o Spark anteriormente em seu computador, seu IDE pode estar configurado para usar uma dessas outras versões do Spark em vez do Databricks Connect Spark. Isso pode se manifestar de várias formas, incluindo erros de "transmissão corrompida" ou "classe não encontrada". O senhor pode ver qual versão do Spark está sendo usada verificando o valor da variável de ambiente SPARK_HOME:
- Python
- Scala
- Java
import os
print(os.environ['SPARK_HOME'])
println(sys.env.get("SPARK_HOME"))
System.out.println(System.getenv("SPARK_HOME"));
Resolução
Se SPARK_HOME estiver definido para uma versão do Spark diferente da que está no cliente, o senhor deverá redefinir a variável SPARK_HOME e tentar novamente.
Verifique as configurações de variável de ambiente do seu IDE, o arquivo .bashrc, .zshrc ou .bash_profile e qualquer outro lugar onde a variável de ambiente possa estar definida. Provavelmente, você precisará sair e reiniciar seu IDE para limpar o estado antigo, e talvez até mesmo precise criar um novo projeto se o problema persistir.
Você não deve precisar definir SPARK_HOME como um novo valor; desativá-lo deve ser suficiente.
Entrada PATH conflitante ou ausente para binários
É possível que seu PATH esteja configurado de modo que o comando like spark-shell execute algum outro binário instalado anteriormente em vez do fornecido com Databricks Connect. Isso pode fazer com que o databricks-connect test falhe. O senhor deve certificar-se de que os binários do Databricks Connect tenham precedência ou remover os instalados anteriormente.
Se não conseguir executar o comando como em spark-shell, também é possível que o PATH não tenha sido configurado automaticamente por pip3 install e será necessário adicionar manualmente o diretório de instalação bin ao PATH. É possível usar o Databricks Connect com IDEs mesmo que isso não esteja configurado. No entanto, o comando databricks-connect test não funcionará.
Configurações de serialização conflitantes no clustering
Se o senhor vir erros de "transmissão corrompida" ao executar databricks-connect test, isso pode ser devido a configurações de serialização de clustering incompatíveis. Por exemplo, definir a configuração spark.io.compression.codec pode causar esse problema. Para resolver esse problema, considere remover essas configurações das definições de clustering ou definir a configuração no cliente Databricks Connect.
Não é possível localizar o site winutils.exe no Windows
Se o senhor estiver usando o Databricks Connect no Windows e ver:
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
Siga as instruções para configurar o caminho do Hadoop no Windows.
A sintaxe do nome do arquivo, do diretório ou do rótulo do volume está incorreta no Windows
Se o senhor estiver usando o Windows e o Databricks Connect e ver:
The filename, directory name, or volume label syntax is incorrect.
O Java ou o Databricks Connect foi instalado em um diretório com um espaço no seu caminho. Você pode contornar isso instalando em um caminho de diretório sem espaços ou configurando seu caminho usando o formulário de nome abreviado.
Limitações
-
transmissão estruturada.
-
Execução de código arbitrário que não faz parte de um trabalho Spark no clustering remoto.
-
Não há suporte para APIs nativas de Scala, Python e R para operações de tabela Delta (por exemplo,
DeltaTable.forPath). No entanto, o SQL API (spark.sql(...)) com Delta Lake operações e o Spark API (por exemplo,spark.read.load) em Delta tabelas são compatíveis. -
Copie para.
-
Usando funções SQL, UDFs Python ou Scala que fazem parte do catálogo do servidor. No entanto, as UDFs Scala e Python introduzidas localmente funcionam.
-
Apache Zeppelin 0.7.x e abaixo.
-
Conectando-se ao clustering com controle de acesso da tabela.
-
Conectando-se ao clustering com o isolamento do processo ativado (em outras palavras, onde
spark.databricks.pyspark.enableProcessIsolationestá definido comotrue). -
Delta
CLONESQL comando. -
Visualização temporária global.
-
Koalas e
pyspark.pandas. -
CREATE TABLE table AS SELECT ...SQL comando nem sempre funcionam. Em vez disso, usespark.sql("SELECT ...").write.saveAsTable("table"). -
A CLI da Databricks.
-
A seguinte referênciaDatabricks utilidades (
dbutils):