tutorial: execução do código de PyCharm no classic compute
Este artigo se aplica a Databricks Connect para Databricks Runtime 13.3 LTS e acima.
Databricks Connect permite conectar IDEs populares, como PyCharm, servidores de notebooks e outros aplicativos personalizados ao Databricks compute. See Databricks Connect.
Este artigo demonstra como iniciar rapidamente o uso do Databricks Connect para Python utilizando PyCharm. Crie um projeto em PyCharm, instale Databricks Connect para Databricks Runtime 13.3 LTS e acima, e execute o código simples no classic compute em seu Databricks workspace de PyCharm.
Requisitos
Para completar este tutorial, você deve atender aos seguintes requisitos:
- O site workspace, o ambiente local e o site compute atendem aos requisitos do site Databricks Connect para o site Python. Consulte os requisitos de uso do Databricks Connect.
- Você tem o PyCharm instalado. Este tutorial foi testado com o PyCharm Community Edition 2023.3.5. Se você usar uma versão ou edição diferente do PyCharm, as instruções a seguir podem variar.
- Se estiver utilizando o compute clássico, será necessário o ID do clustering. Para obter o ID do cluster, em workspace, clique em “Compute” na barra lateral e, em seguida, clique no nome do cluster. Na barra de endereços do seu navegador, copie as sequências de caracteres entre
clusterseconfigurationno URL.
Etapa 1: Configurar a autenticação do Databricks
Este tutorial utiliza Databricks OAuth autenticação de usuário para máquina (U2M) e um perfil de configuração Databricks para autenticação no seu Databricks workspace. Para usar um tipo de autenticação diferente, consulte Configurar propriedades de conexão.
A configuração da autenticação OAuth U2M requer o Databricks CLI. Para obter informações sobre como instalar o,Databricks CLI acesse. Para obter informações sobre como instalar ou atualizar o, acesse.Databricks CLI
Inicie a autenticação OAuth U2M, conforme a seguir:
-
Utilize o comando Databricks CLI para iniciar o gerenciamento de tokens OAuth localmente, executando o seguinte comando para cada workspace de destino.
No comando a seguir, substitua
<workspace-url>pelo Databricks workspace URL da sua instância do, porhttps://1234567890123456.7.gcp.databricks.comexemplo,.Bashdatabricks auth login --configure-cluster --host <workspace-url>
Para utilizar serverless compute com Databricks Connect, consulte Configurar uma conexão com serverless compute .
-
O Databricks CLI solicita que você salve as informações inseridas como um perfil de configuração Databricks. Pressione
Enterpara aceitar o nome de perfil sugerido ou insira o nome de um perfil novo ou existente. Qualquer perfil existente com o mesmo nome será substituído pelas informações que você inseriu. É possível utilizar perfis para alternar rapidamente o contexto de autenticação entre várias áreas de trabalho.Para obter uma lista de todos os perfis existentes, em um terminal separado ou prompt de comando, utilize o comando “ Databricks ” CLI para executar o comando “
databricks auth profiles”. view Para alterar as configurações existentes de um perfil específico, execute o comandodatabricks auth env --profile <profile-name>. -
No navegador da web, conclua as instruções na tela para fazer log in no workspace do Databricks.
-
Na lista de agrupamentos disponíveis que aparece no seu terminal ou prompt de comando, utilize as setes para selecionar o agrupamento de Databricks no seu workspace e, em seguida, pressione
Enter. Também é possível digitar qualquer parte do nome de exibição do agrupamento para filtrar a lista de agrupamentos disponíveis. -
view Para obter o valor atual dos tokens OAuth de um perfil e o carimbo de data/hora de expiração dos tokens, execute um dos seguintes comandos:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Se você tiver vários perfis com o mesmo valor
--host, talvez seja necessário especificar as opções--hoste-pjuntas para ajudar a CLI do Databricks a encontrar as informações de token OAuth correspondentes corretas.
Etapa 2: criar o projeto
- Inicie o PyCharm.
- No menu principal, clique em Arquivo > Novo projeto .
- Na caixa de diálogo Novo projeto , clique em Python puro .
- Para Localização , clique no ícone da pasta e siga as instruções na tela para especificar o caminho do seu novo projeto Python.
- Deixe Criar um script de boas-vindas main.py selecionado.
- Para Tipo de interpretador , clique em venv do projeto .
- Expanda a versão do Python e use o ícone de pasta ou a lista suspensa para especificar o caminho para o interpretador do Python a partir dos requisitos anteriores.
- Clique em Criar .

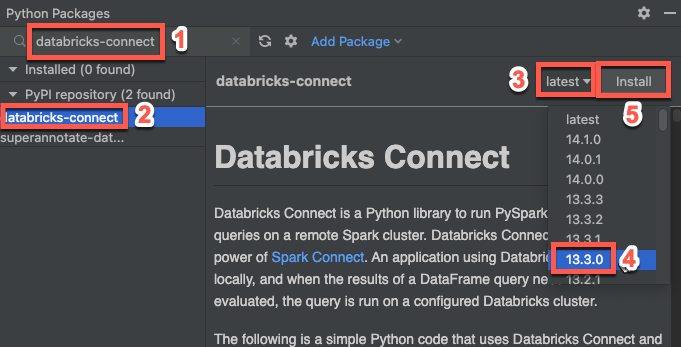
Etapa 3: Adicionar o pacote Databricks Connect
- No menu principal de PyCharm, clique em “View” (Exibir) e selecione “ > ” (Ferramentas de atualização). Windows > Python pacote .
- Na caixa de pesquisa, insira
databricks-connect. - Na lista de repositórios do PyPI , clique em databricks-connect .
- Na lista suspensa mais recente do painel de resultados, selecione a versão que corresponde à versão do Databricks Runtime do seu cluster. Por exemplo, se o seu clustering tiver um Databricks Runtime e 14.3 instalado, selecione 14.3.1 .
- Clique em Instalar pacote .
- Após a instalação do pacote, você pode fechar a janela Pacotes Python .
Etapa 4: adicionar código
-
Na janela da ferramenta Projeto , clique com o botão direito do mouse na pasta raiz do projeto e clique em Novo arquivo Python ( > ) .
-
Digite
main.pye clique duas vezes no arquivo Python . -
Digite o código a seguir no arquivo e salve-o, dependendo do nome do seu perfil de configuração.
Se o seu perfil de configuração do Passo 1 for denominado
DEFAULT, insira o seguinte código no arquivo e salve-o:Pythonfrom databricks.connect import DatabricksSession
spark = DatabricksSession.builder.getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)Se o seu perfil de configuração do Passo 1 não for nomeado
DEFAULT, insira o código a seguir no arquivo. Substitua o placeholder<profile-name>pelo nome do seu perfil de configuração do passo 1 e salve o arquivo:Pythonfrom databricks.connect import DatabricksSession
spark = DatabricksSession.builder.profile("<profile-name>").getOrCreate()
df = spark.read.table("samples.nyctaxi.trips")
df.show(5)
Passo 5: execute o código
- Inicie o cluster de destino no seu workspace remoto do Databricks.
- Após o agrupamento ter começado, no menu principal, clique em “Execução” e selecione “ > ” e “Execução 'main'”.
- Na janela da ferramenta Execução ( exibir Ferramenta > Windows > execução ), no painel principal da janela Execução tab, as primeiras 5 linhas da janela
samples.nyctaxi.tripssão exibidas.
Etapa 6: depurar o código
- Com o cluster ainda em execução, no código anterior, clique na medianiz ao lado de
df.show(5)para definir um ponto de interrupção. - No menu principal, clique em “Execução” e selecione “ > ”.
- Na janela da ferramenta Depuração ( visualização Ferramenta > Windows > ), no painel Variáveis do Depurador tab, expanda os nós das variáveis df e spark para navegar pelas informações sobre as variáveis
dfesparkdo código. - Na barra lateral da janela da ferramenta de depuração , clique no ícone da seta verde ( Retomar programa ).
- No painel Console do Debugger ( tab), as primeiras 5 linhas do
samples.nyctaxi.tripssão exibidas.
