tutorial: execução do código de IntelliJ IDEA no classic compute
Este tutorial demonstra como começar a usar o Databricks Connect para Scala utilizando o IntelliJ IDEA e o plugin Scala.
Neste tutorial, crie um projeto em IntelliJ IDEA, instale Databricks Connect para Databricks Runtime 13.3 LTS e acima, e execute o código simples em compute em seu Databricks workspace de IntelliJ IDEA.
Para aprender como usar os Declarative Automation Bundles para criar um projeto Scala que execute código em compute serverless , consulte Criar um JAR Scala usando Declarative Automation Bundles.
Requisitos
Para completar este tutorial, você deve atender aos seguintes requisitos:
-
O site workspace, o ambiente local e o site compute atendem aos requisitos do site Databricks Connect para o site Scala. Consulte os requisitos de uso do Databricks Connect.
-
É necessário que o seu ID de agrupamento esteja disponível. Para obter o ID do seu cluster, em workspace, clique em “Compute” na barra lateral e, em seguida, clique no nome do seu cluster. Na barra de endereços do seu navegador, copie as sequências de caracteres entre
clusterseconfigurationno URL. -
O senhor tem o Java Development Kit (JDK) instalado em seu computador de desenvolvimento. Para obter informações sobre a versão a ser instalada, consulte a matriz de suporte à versão.
Caso não possua um JDK instalado ou se houver várias instalações de JDK em sua máquina de desenvolvimento, é possível instalar ou selecionar um JDK específico posteriormente, na Etapa 1. A seleção de uma instalação de JDK inferior ou superior à versão do JDK em seu cluster pode produzir resultados inesperados ou o código pode não ser executado.
-
O IntelliJ IDEA está instalado. Este tutorial foi testado com o IntelliJ IDEA Community Edition 2023.3.6. Se você estiver utilizando uma versão ou edição diferente do IntelliJ IDEA, as instruções a seguir podem variar.
-
O plugin Scala para IntelliJ IDEA está instalado.
Etapa 1: Configurar a autenticação do Databricks
Este tutorial utiliza Databricks OAuth autenticação de usuário para máquina (U2M) e um perfil de configuração Databricks para autenticação com o seu Databricks workspace. Para usar um tipo de autenticação diferente, consulte Configurar propriedades de conexão.
A configuração da autenticação OAuth U2M requer a CLI do Databricks, da seguinte forma:
- Instale a CLI do Databricks:
- Linux, macOS
- Windows
Use o Homebrew para instalar a CLI do Databricks executando os seguintes comandos:
brew tap databricks/tap
brew trust databricks/tap
brew install databricks
O brew trust comando é necessário a partir de Homebrew 6.0.0.
É possível utilizar o winget, o Chocolatey ou o Subsistema Windows para Linux (WSL) para instalar a CLI do Databricks. Caso não seja possível utilizar o “ winget”, o “Chocolatey” ou o “WSL”, é recomendável ignorar este procedimento e utilizar o “Prompt de comando” ou o “ PowerShell ” para instalar o “ Databricks CLI ” a partir da fonte.
Installing the Databricks CLI with Chocolatey is Experimental.
Para usar o winget para instalar a CLI do Databricks, execute os dois comandos a seguir e reinicie seu prompt de comando:
winget search databricks
winget install Databricks.DatabricksCLI
Para usar o Chocolatey para instalar a CLI do Databricks, execute o seguinte comando:
choco install databricks-cli
Para usar o WSL para instalar a CLI do Databricks:
-
Instale
curlezippor meio do WSL. Para obter mais informações, consulte a documentação do seu sistema operacional. -
Use o WSL para instalar a CLI do Databricks executando o seguinte comando:
Bashcurl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh
-
Confirme se a CLI do Databricks está instalada executando o seguinte comando, que exibe a versão atual da CLI do Databricks instalada. Essa versão deve ser a 0.205.0 ou superior:
Bashdatabricks -v
Inicie a autenticação OAuth U2M, conforme a seguir:
-
Utilize o comando Databricks CLI para iniciar o gerenciamento de tokens OAuth localmente, executando o seguinte comando para cada workspace alvo.
No comando a seguir, substitua
<workspace-url>pelo Databricks workspace URL da sua instância do, porhttps://1234567890123456.7.gcp.databricks.comexemplo,.Bashdatabricks auth login --configure-cluster --host <workspace-url> -
O Databricks CLI solicita que você salve as informações inseridas como um perfil de configuração Databricks. Pressione
Enterpara aceitar o nome de perfil sugerido ou insira o nome de um perfil novo ou existente. Qualquer perfil existente com o mesmo nome será substituído pelas informações que você inseriu. É possível utilizar perfis para alternar rapidamente o contexto de autenticação entre várias áreas de trabalho.databricks auth profilesPara obter uma lista de todos os perfis existentes, em um terminal separado ou prompt de comando, utilize o comando “ Databricks ” e execute o comando “ CLI ”. view Para alterar as configurações existentes de um perfil específico, execute o comandodatabricks auth env --profile <profile-name>. -
No navegador da web, conclua as instruções na tela para fazer log in no workspace do Databricks.
-
Na lista de agrupamentos disponíveis que aparece no seu terminal ou prompt de comando, utilize as setes para selecionar o agrupamento de Databricks no seu workspace e, em seguida, pressione
Enter. Também é possível digitar qualquer parte do nome de exibição do agrupamento para filtrar a lista de agrupamentos disponíveis. -
view Para obter o valor atual dos tokens OAuth de um perfil e o carimbo de data/hora de expiração dos tokens, execute um dos seguintes comandos:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Se você tiver vários perfis com o mesmo valor
--host, talvez seja necessário especificar as opções--hoste-pjuntas para ajudar a CLI do Databricks a encontrar as informações de token OAuth correspondentes corretas.
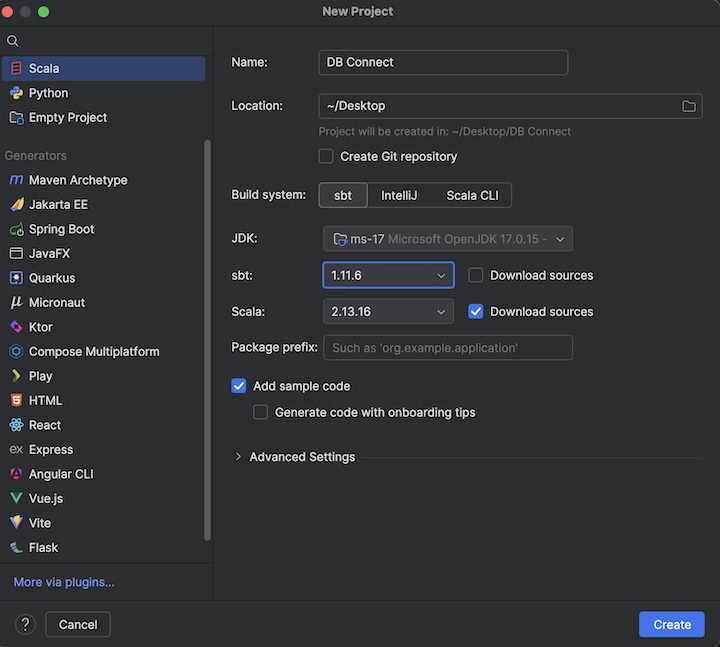
Etapa 2: criar o projeto
-
Iniciar o IntelliJ IDEA.
-
No menu principal, clique em Arquivo > Novo Projeto > .
-
Dê ao seu projeto um nome significativo.
-
Para Localização , clique no ícone da pasta e siga as instruções na tela para especificar o caminho para o seu novo projeto Scala.
-
Para Idioma , selecione Scala .
-
Em Build system , clique em sbt .
-
download Na lista suspensa JDK , selecione uma instalação existente do JDK em sua máquina de desenvolvimento que corresponda à versão do JDK em seu clustering ou selecione baixar JDK e siga as instruções na tela para baixar um JDK que corresponda à versão do JDK em seu clustering. Consulte os requisitos.
Escolher uma instalação do JDK superior ouabaixo à versão do JDK em seus clusters pode produzir resultados inesperados ou seu código pode não ser executado.
-
Na lista suspensa sbt , selecione a versão mais recente.
-
Na lista suspensa Scala lista suspensa, selecione a versão do Scala que corresponde à versão do Scala no seu clustering. Consulte os requisitos.
A escolha de uma versão do Scala que esteja abaixo ou acima da versão do Scala no seu clustering pode produzir resultados inesperados ou o seu código pode não ser executado.
-
Certifique-se de que a caixa Fontes de download ao lado de Scala esteja marcada.
-
Para o prefixo do pacote , insira algum valor de prefixo do pacote para as fontes do seu projeto, por exemplo,
org.example.application. -
Verifique se a caixa Adicionar código de amostra está marcada.
-
Clique em Criar .
Etapa 3: Adicionar o pacote Databricks Connect
-
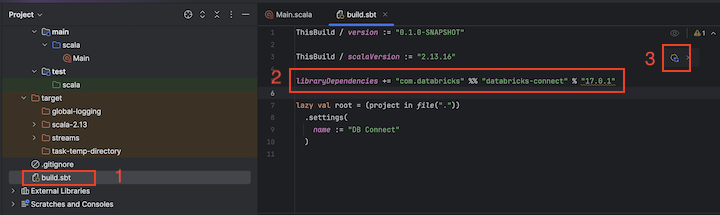
Com o novo projeto Scala aberto, na janela de ferramentas do projeto ( exiba a ferramenta >, selecione Windows e, em seguida, > Project ), abra o arquivo chamado
build.sbt, em project-name > target . -
Adicione o seguinte código ao final do arquivo
build.sbt, que declara a dependência do seu projeto de uma versão específica da biblioteca Databricks Connect para Scala, compatível com a versão Databricks Runtime do seu clustering:libraryDependencies += "com.databricks" %% "databricks-connect" % "17.3.+"Substitua
17.3pela versão da biblioteca do Databricks Connect que corresponde à versão do Databricks Runtime no seu cluster. Por exemplo, Databricks Connect 17.3.+ Corresponde ao Databricks Runtime 17.3 LTS. Você pode encontrar os números de versão da biblioteca Databricks Connect no repositório Maven Central (para Databricks Runtime 16.4 LTS e abaixo) ou no repositório Maven Central (para Databricks Runtime 17.0 e acima).
Ao construir com o Databricks Connect, não inclua artefatos do Apache Spark, como org.apache.spark:spark-core , no seu projeto. Em vez disso, compile diretamente no Databricks Connect.
-
Clique no ícone Notificar alterações no sbt para atualizar seu projeto Scala com o novo local da biblioteca e a dependência.
-
Espere até que o indicador de progresso
sbtna parte inferior do IDE desapareça. O processo de carregamento dosbtpode levar alguns minutos para ser concluído.
Etapa 4: adicionar código
-
Na janela da ferramenta Projeto , abra o arquivo chamado
Main.scala, em nome-do-projeto > src > main > Scala . -
Substitua qualquer código existente no arquivo pelo código a seguir e salve o arquivo, dependendo do nome do seu perfil de configuração.
Se o perfil de configuração da Etapa 1 se chamar
DEFAULT, substitua qualquer código existente no arquivo pelo código a seguir e salve o arquivo:Scalapackage org.example.application
import com.databricks.connect.DatabricksSession
import org.apache.spark.sql.SparkSession
object Main {
def main(args: Array[String]): Unit = {
val spark = DatabricksSession.builder().remote().getOrCreate()
val df = spark.read.table("samples.nyctaxi.trips")
df.limit(5).show()
}
}Se o seu perfil de configuração da Etapa 1 não tiver o nome
DEFAULT, substitua qualquer código existente no arquivo pelo código a seguir. Substitua o espaço reservado<profile-name>pelo nome do seu perfil de configuração da Etapa 1 e salve o arquivo:Scalapackage org.example.application
import com.databricks.connect.DatabricksSession
import com.databricks.sdk.core.DatabricksConfig
import org.apache.spark.sql.SparkSession
object Main {
def main(args: Array[String]): Unit = {
val config = new DatabricksConfig().setProfile("<profile-name>")
val spark = DatabricksSession.builder().sdkConfig(config).getOrCreate()
val df = spark.read.table("samples.nyctaxi.trips")
df.limit(5).show()
}
}
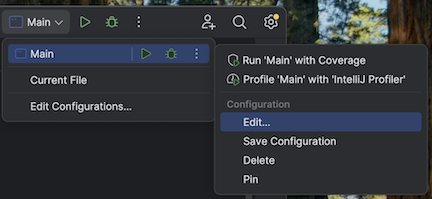
o passo 5: Configurar as opções da VM
-
Importe o diretório atual no seu IntelliJ onde
build.sbtestá localizado. -
Escolha Java 17 no IntelliJ. Vá para Arquivo > Estrutura do Projeto > SDKs .
-
Abra
src/main/scala/com/examples/Main.scala. -
Navegue até a configuração principal para adicionar opções de VM:
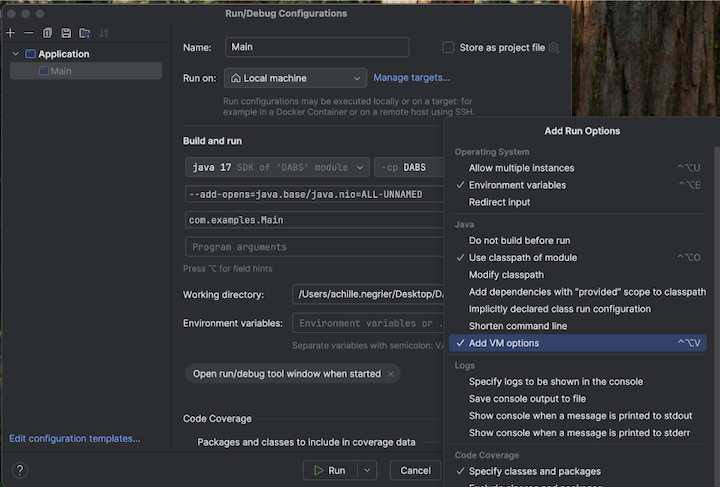
-
Adicione o seguinte às opções da sua VM:
--add-opens=java.base/java.nio=ALL-UNNAMED
Como alternativa, ou se você estiver usando o Visual Studio Code, adicione o seguinte ao seu arquivo de compilação sbt:
fork := true
javaOptions += "--add-opens=java.base/java.nio=ALL-UNNAMED"
Em seguida, execute sua aplicação a partir do terminal:
sbt run
o passo 6: execução do código
- Inicie o cluster de destino no seu workspace remoto do Databricks.
- Após o início do agrupamento, no menu principal, clique em “Execução” e selecione “ > ” e “Executar”.
- Na janela da ferramenta de execução ( visualização > Ferramenta Windows > execução ), na guia Principal ( tab), as primeiras 5 linhas da tabela
samples.nyctaxi.tripssão exibidas.
o passo 7: Depurar o código
-
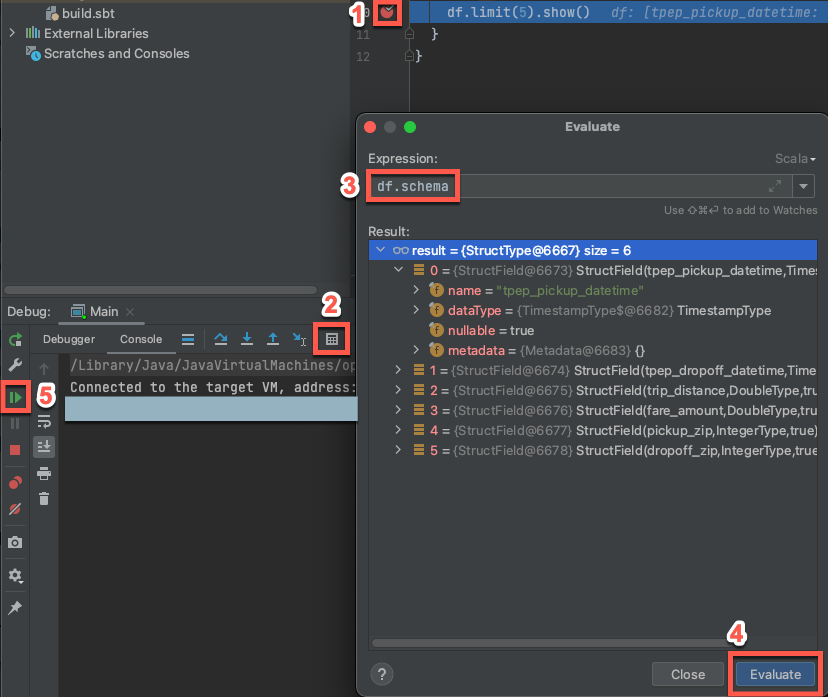
Com o agrupamento de alvos ainda em execução, no código anterior, clique na margem ao lado de “
df.limit(5).show()” para definir um ponto de interrupção. -
No menu principal, clique em execução > Depurar 'Principal' . Na janela da ferramenta Depuração ( exibir > Windows de ferramentas > Depurar ), na tab Console , clique no ícone da calculadora ( Avaliar expressão ).
-
Digite a expressão
df.schema. -
Clique em Avaliar para mostrar o esquema do DataFrame.
-
Na barra lateral da janela da ferramenta Depuração , clique no ícone de seta verde ( Retomar programa ). As primeiras 5 linhas da tabela
samples.nyctaxi.tripsaparecem no painel Console .