Protocolo de contexto do modelo (MCP) no Databricks
MCP é um padrão de código aberto que conecta agentes AI a ferramentas, recursos, prompts e outras informações contextuais.
A Databricks oferece os seguintes tipos de servidores MCP:
-
- MCP
- Acesse imediatamente o recurso Databricks usando servidores MCP pré-configurados.
-
- MCP externo
- Conecte-se com segurança a servidores MCP hospedados fora do Databricks usando o gerenciamento de conexões.
-
- MCP personalizado
- Hospede um servidor MCP personalizado como um aplicativo Databricks.
Para visualizar os servidores MCP disponíveis, acesse seu workspace > Agentes > Servidores MCP :
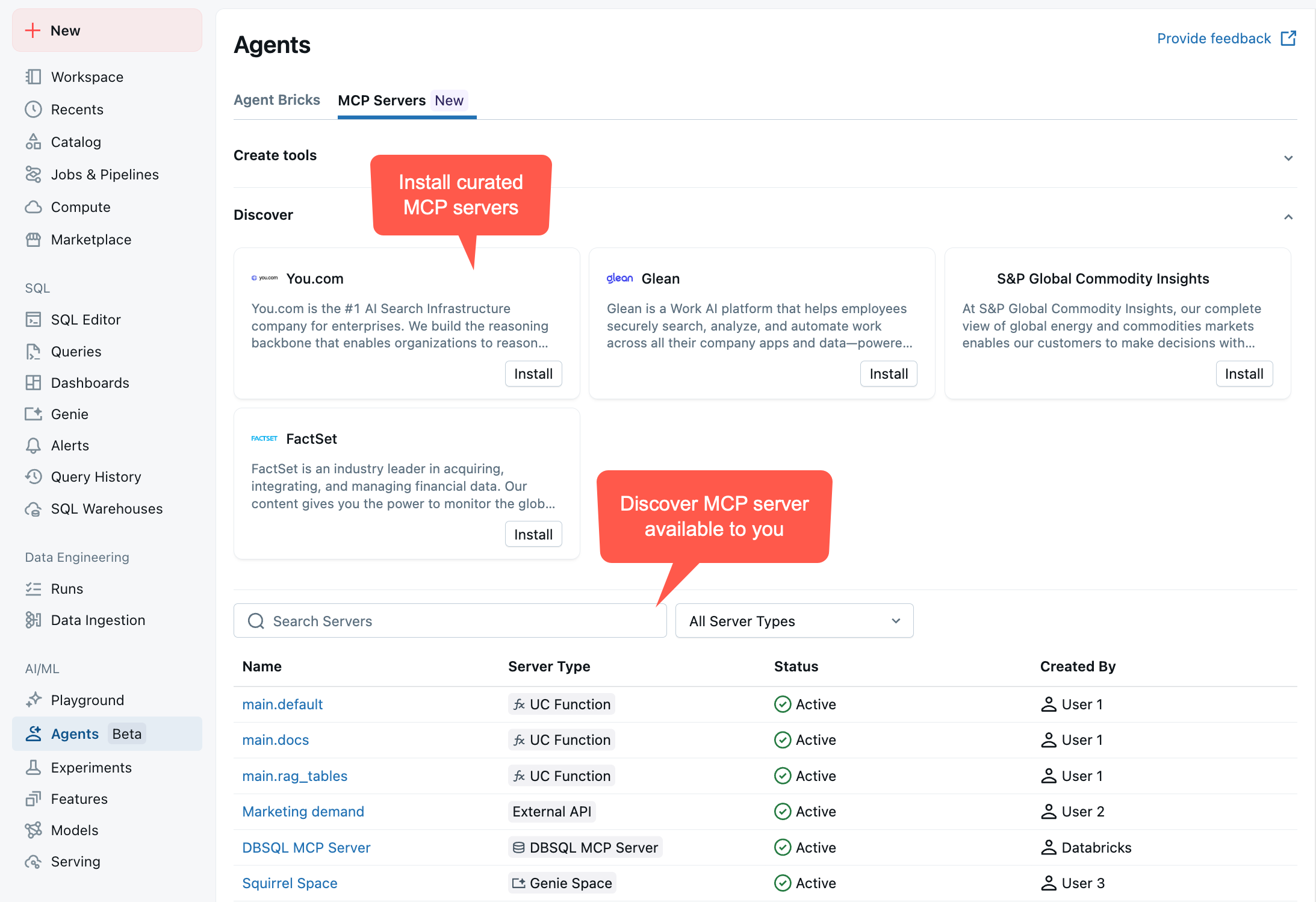
Como usar os servidores MCP
O MCP foi projetado para ser usado com um LLM que descobre dinamicamente as ferramentas disponíveis, decide quais ferramentas chamar e interpreta a saída. Ao criar agentes que utilizam servidores MCP, a Databricks recomenda:
- Não insira nomes de ferramentas diretamente no código : o conjunto de ferramentas disponíveis pode mudar à medida que o Databricks adiciona novas funcionalidades ou modifica as existentes. Seu agente deve descobrir ferramentas dinamicamente em tempo de execução, listando-as.
- Não analise a saída da ferramenta programaticamente : Não há garantia de que os formatos de saída da ferramenta permaneçam estáveis. Deixe que seu LLM interprete e extraia informações das respostas da ferramenta.
- Deixe que o LLM decida : O LLM do seu agente deve determinar quais ferramentas chamar com base na solicitação do usuário e nas descrições das ferramentas fornecidas pelo servidor MCP.
Essas práticas permitem que seus agentes se beneficiem automaticamente das melhorias nos servidores MCP sem a necessidade de alterações no código.
computar preços
Os servidores MCP personalizados estão sujeitos aos preços do Databricks Apps.
O gerenciamento dos preços do servidor MCP depende do tipo de recurso:
-
As funções Unity Catalog usam preços gerais compute serverless.
-
Genie spaces usam serverless SQL compute.
-
Os servidores Databricks SQL usam preçosDatabricks SQL.
-
Os índices de pesquisa vetorial usam os preços da pesquisa vetorial.