Arquitetura de alto nível
Este artigo fornece uma visão geral de alto nível da arquitetura do Databricks, incluindo sua arquitetura corporativa, em combinação com a nuvem do Google.
Objetos Databricks
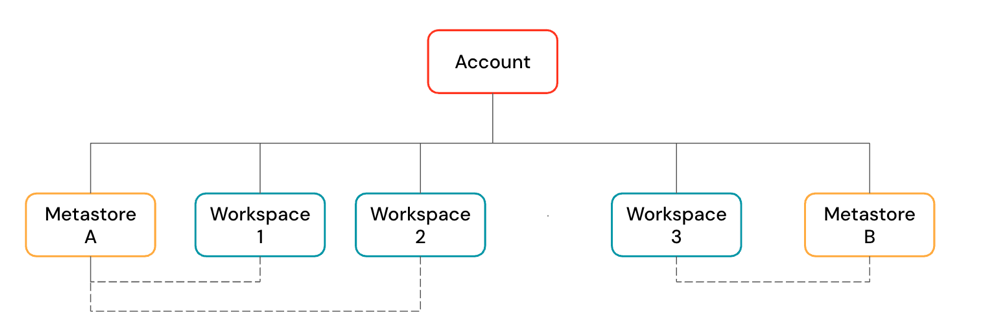
Uma account Databricks é a construção de nível superior que você usa para gerenciar Databricks em toda a sua organização. No nível account , você gerencia:
-
Identidade e acesso: Usuários, grupos, entidade de serviço, provisionamento SCIM e configuração SSO .
-
gerenciamento de espaço de trabalho: crie, atualize e exclua espaços de trabalho em várias regiões.
-
Gerenciamento de metastore Unity Catalog : crie e anexe metastore ao espaço de trabalho.
-
Gerenciamento de uso: cobrança, compliance e políticas.
Uma account pode conter vários espaços de trabalho e metastores Unity Catalog .
-
O espaço de trabalho é o ambiente de colaboração onde os usuários executam cargas de trabalho compute , como ingestão, exploração interativa, tarefas agendadas e treinamento ML .
-
Os meta-storesUnity Catalog são o sistema de governança central para ativos de dados, como tabelas e modelos ML . Você organiza dados em um metastore sob um namespace de três níveis:
<catalog-name>.<schema-name>.<object-name>
Metastores são anexados ao espaço de trabalho. Você pode vincular um único metastore a vários espaços de trabalho Databricks na mesma região, dando a cada workspace a mesma view de dados. Os controles de acesso a dados podem ser gerenciados em todos os espaços de trabalho vinculados.
arquitetura do espaço de trabalho
Databricks opera a partir de um plano de controle e de um planocompute .
-
O plano de controle inclui o serviço de backend que Databricks gerencia em sua account Databricks . O plano de controle está localizado na account Databricks , não na sua account cloud . A aplicação web está no plano de controle.
-
O planocompute é onde seus dados são processados. Há dois tipos de planos compute, dependendo do compute que o senhor estiver usando.
- Para serverless compute, o serverless compute recurso execução em um serverless compute plano em seu Databricks account.
- Para o clássico Databricks compute, o recurso compute está em seu recurso de nuvem do Google no que é chamado de plano clássico compute . Isso se refere à rede em seu recurso de nuvem do Google e seu recurso.
Para saber mais sobre os sites clássicos compute e serverless compute, consulte computar.
Arquitetura clássica workspace
Os espaços de trabalho Databricks clássico possuem três buckets de armazenamento associados, conhecidos como buckets de armazenamentoworkspace . Os buckets de armazenamento workspace estão na sua account do Google Cloud.
O diagrama a seguir descreve a arquitetura geral Databricks para o espaço de trabalho clássico.

arquitetura workspace sem servidor
O armazenamento do espaço de trabalho no espaço de trabalho serverless é armazenado no armazenamento default do workspace. Você também pode se conectar à sua account de armazenamento cloud para acessar seus dados. O diagrama a seguir descreve a arquitetura geral do espaço de trabalho serverless .
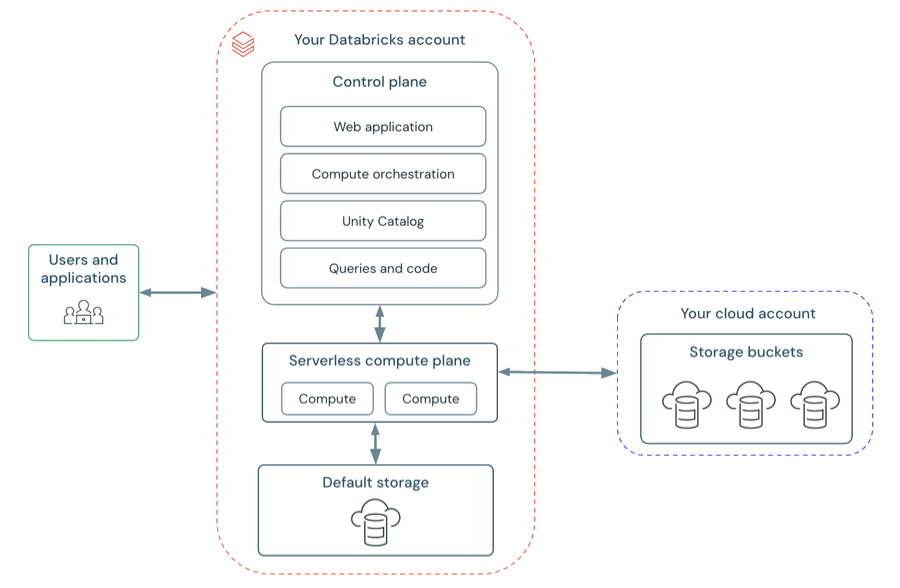
sem servidor compute plane
No plano serverless compute , Databricks compute recurso execução em uma camada compute dentro do seu Databricks account. Databricks cria um plano serverless compute na mesma região da nuvem do Google que o plano clássico compute do seu workspace. O senhor seleciona essa região ao criar um workspace.
Para proteger os dados do cliente dentro do plano serverless compute , serverless compute execução dentro de um limite de rede para o workspace, com várias camadas de segurança para isolar diferentes espaços de trabalho do cliente Databricks e controles de rede adicionais entre clusters o mesmo cliente.
Para saber mais sobre a rede no plano serverless compute , a rede no plano compute sem servidor.
Clássico compute avião
No plano clássico compute, Databricks compute recurso execução em sua nuvem do Google account. Novos recursos do compute são criados em cada rede virtual do workspace na nuvem do Google do cliente account.
Um plano compute clássico tem isolamento natural porque é executado na nuvem do Google de cada cliente account. Para saber mais sobre a rede no plano compute clássico, consulte Rede no plano compute clássico.
Para obter suporte regional, consulte Databricks clouds e regiões.
armazenamento de espaço de trabalho
O armazenamento do espaço de trabalho é tratado de forma diferente dependendo do tipo do seu workspace . Para obter mais informações sobre os tipos workspace , consulte Criar um workspace.
espaço de trabalho sem servidor
O espaço de trabalho sem servidor usa o armazenamento default , que é um local de armazenamento totalmente específico para dados internos do sistema workspace e dados ativos Unity Catalog . O espaço de trabalho sem servidor também oferece suporte à capacidade de se conectar aos seus locais de armazenamento cloud para seus próprios catálogos, tabelas e outros dados ativos. Veja o armazenamento padrão no Databricks.
Espaço de trabalho clássico
Ao criar um workspace clássico, Databricks cria três buckets na sua account do Google Cloud para serem usados como buckets de armazenamento workspace .
- Um bucket de armazenamento workspace armazena dados do sistemaworkspace que são gerados à medida que o senhor usa vários recursos Databricks, como a criação do Notebook. Esse bucket inclui revisões do Notebook, detalhes da execução do trabalho, resultados do comando e Spark logs.
- Outro bucket de armazenamento workspace é o armazenamento raiz do seu workspace para DBFS , que é legado e pode estar desabilitado no seu workspace. DBFS (Databricks File System) é um sistema de arquivos distribuído em ambientes Databricks acessível sob o namespace
dbfs:/. DBFS root e as montagens DBFS estão ambas no namespacedbfs:/. Armazenar e acessar o uso de dados DBFS root ou montagens DBFS é um padrão obsoleto e não recomendado pelo Databricks. Para mais informações, consulte O que é DBFS?. - Se o seu workspace foi ativado para Unity Catalog automaticamente, um terceiro bucket de armazenamento workspace contém o catálogo default Unity Catalog workspace . Todos os usuários do site workspace podem criar ativos no esquema default desse catálogo. Veja Get começar com Unity Catalog.
Para limitar o acesso aos seus buckets de armazenamento workspace, consulte Proteger os buckets workspace's GCS em seu projeto.