Solução de problemas de ingestão do PostgreSQL
Visualização
O conector PostgreSQL para LakeFlow Connect está em versão prévia pública. Entre em contato com a equipe da sua account Databricks para se inscrever na Prévia Pública.
Esta página descreve os problemas comuns com o conector PostgreSQL no Databricks LakeFlow Connect e como resolvê-los.
Solução de problemas pipeline em dutos
Os passos de resolução de problemas nesta seção aplicam-se a todos os pipelines de ingestão no LakeFlow Connect.
Se um pipeline falhar durante a execução, clique na etapa que falhou e confirme se a mensagem de erro fornece informações suficientes sobre a natureza do erro.
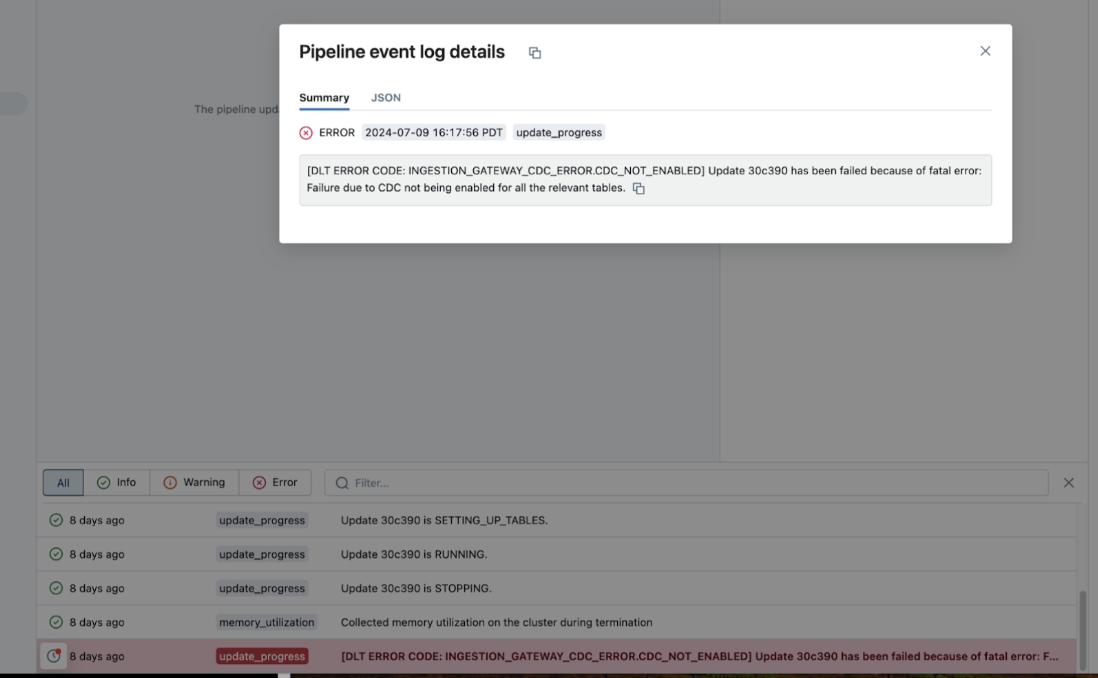
Você também pode verificar e download os logs cluster na página de detalhes pipeline , clicando em Atualizar detalhes no painel direito e, em seguida, em Logs . Analise os logs em busca de erros ou exceções.
Solução de problemas específicos do conector
Os passos de resolução de problemas nesta seção são específicos para o conector PostgreSQL .
Erros de permissão
Se você receber um erro de permissão, verifique se o usuário de replicação possui os privilégios necessários. Consulte os requisitos de usuário do banco de dados PostgreSQL para obter a lista completa de privilégios necessários.
ERRO: permissão negada para a tabela
Este erro indica que o usuário de replicação não tem privilégios SELECT na tabela especificada. Conceda os privilégios necessários:
GRANT SELECT ON TABLE schema_name.table_name TO databricks_replication;
ERRO: é necessário ser superusuário ou ter a função de replicação para usar os slots de replicação.
Este erro indica que o usuário de replicação não tem o privilégio REPLICATION . Atribua a função de replicação:
-- For standard PostgreSQL
ALTER USER databricks_replication WITH REPLICATION;
-- For AWS RDS/Aurora
GRANT rds_replication TO databricks_replication;
-- For GCP Cloud SQL
ALTER USER databricks_replication with REPLICATION;
Verifique se a replicação lógica está ativada.
Para verificar se a replicação lógica está ativada:
SHOW wal_level;
A saída deve ser logical. Caso contrário, atualize o parâmetro wal_level e reinicie o servidor PostgreSQL.
Para gerenciamento cloud PostgreSQL:
- AWS RDS/Aurora : Defina
rds.logical_replicationpara1no grupo de parâmetros. - Banco de Dados do Azure para PostgreSQL : Habilite a replicação lógica nos parâmetros do servidor.
- GCP cloud SQL : Defina o sinalizador
cloudsql.logical_decodingparaon.
Verifique se existe uma publicação.
Para verificar se existe uma publicação para suas tabelas:
SELECT * FROM pg_publication WHERE pubname = 'databricks_publication';
-- Check which tables are included in the publication
SELECT schemaname, tablename
FROM pg_publication_tables
WHERE pubname = 'databricks_publication';
Se a publicação não existir, crie-a:
CREATE PUBLICATION databricks_publication FOR TABLE schema_name.table_name;
Verificar identidade da réplica
Para verificar a configuração de identidade da réplica de uma tabela:
SELECT schemaname, tablename, relreplident
FROM pg_tables t
JOIN pg_class c ON t.tablename = c.relname
WHERE schemaname = 'your_schema' AND tablename = 'your_table';
A coluna relreplident deve exibir os seguintes valores:
fpara identidade de réplica COMPLETA (necessária para tabelas sem chave primária ou colunas TOASTable).dpara identidade de réplica padrão (usa key primária).
Se a identidade da réplica não estiver configurada corretamente, atualize-a:
ALTER TABLE schema_name.table_name REPLICA IDENTITY FULL;
Erros de slot de replicação
Acúmulo de WAL e problemas de espaço em disco
Se o gateway de ingestão for interrompido por um período prolongado, o slot de replicação pode causar o acúmulo de arquivos de log de gravação antecipada (WAL), potencialmente preenchendo o espaço em disco.
Para verificar o uso do disco WAL:
SELECT pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(), restart_lsn)) AS retained_wal
FROM pg_replication_slots
WHERE slot_name = 'your_slot_name';
Para evitar o acúmulo de WAL:
- Garanta que o gateway de ingestão esteja em execução contínua.
- Monitore regularmente o atraso de replicação e o espaço em disco.
Se houver acúmulo de arquivos WAL, você pode remover manualmente o slot de replicação:
SELECT pg_drop_replication_slot('your_slot_name');
Se um slot de replicação for descartado ou se tornar inválido, atualize a especificação pipeline com um novo slot para esse banco de dados e execute uma refresh completa.
Tempo limite excedido ao aguardar tokens da tabela
O pipeline de ingestão pode expirar enquanto aguarda o fornecimento de informações pelo gateway. Isso pode ser devido a um dos seguintes motivos:
- Você está executando uma versão antiga do gateway.
- Ocorreu um erro ao gerar as informações necessárias. Verifique os logs do driver do gateway em busca de erros.
- A captura inicial do instantâneo está demorando mais do que o esperado. Para tabelas grandes, considere aumentar o tempo limite do pipeline ou executar a carga inicial fora do horário de pico.
conflito de nomenclatura da tabela de origem
Ingestion pipeline error: "org.apache.spark.sql.catalyst.ExtendedAnalysisException: Cannot have multiple queries named `orders_snapshot_load` for `orders`. Additional queries on that table must be named. Note that unnamed queries default to the same name as the table.
Isso indica que há um conflito de nomes devido a várias tabelas de origem chamadas orders em diferentes esquemas de origem que estão sendo ingeridas pelo mesmo pipeline de ingestão para o mesmo esquema de destino.
Crie vários pares de gateway-pipeline, gravando essas tabelas conflitantes em esquemas de destino diferentes.
Alterações de esquema incompatíveis
Uma alteração de esquema incompatível faz com que o pipeline de ingestão falhe com um erro INCOMPATIBLE_SCHEMA_CHANGE . Para continuar a replicação, acione uma refresh completa das tabelas afetadas.
Alterações de esquema incompatíveis incluem o seguinte:
- Alterar o tipo de dados de uma coluna
- Renomear uma coluna
- Alterar a key primária de uma tabela
- Remover uma coluna que faz parte da identidade da réplica.
A Databricks não pode garantir que todas as linhas anteriores à alteração do esquema tenham sido ingeridas quando o pipeline de ingestão falha devido a uma alteração de esquema incompatível.
erros de tempo limite de conexão
Se você receber erros de tempo limite de conexão, execute as seguintes verificações:
- Verifique se as regras do firewall permitem conexões do workspace Databricks .
- Verifique se o servidor PostgreSQL está acessível a partir da rede Databricks.
- Certifique-se de que o arquivo
pg_hba.confpermita conexões do intervalo de IP do Databricks. - Verifique se as credenciais de conexão estão corretas.
erros de conexão SSL/TLS
Se você receber erros de conexão SSL/TLS, realize as seguintes verificações:
-
Verifique se o servidor PostgreSQL suporta conexões SSL.
-
Verifique o parâmetro
sslna configuração do PostgreSQL:SQLSHOW ssl; -
Certifique-se de que o arquivo
pg_hba.confexige ou permite conexões SSL para o usuário de replicação. -
Para bancos de dados PostgreSQL gerenciados em cloud, verifique se o SSL está imposto nas configurações do servidor.
Autenticaçãodefault : não é possível configurar credenciais default
Se você receber esse erro, há um problema ao descobrir as credenciais do usuário atual. Tente substituir o seguinte:
w = WorkspaceClient()
com:
w = WorkspaceClient(host=input('Databricks Workspace URL: '), token=input('Token: '))
Consulte a seção Autenticação na documentação do SDK do Databricks para Python.
PERMISSÃO NEGADA: Você não tem autorização para criar clusters. Por favor, entre em contato com o administrador.
Contate um administrador account Databricks para conceder a você permissões Unrestricted cluster creation .
CÓDIGO DE ERRO DLT: INGESTION_GATEWAY_INTERNAL_ERROR
Verifique os arquivos stdout nos logs do driver para obter mensagens de erro detalhadas. As causas comuns incluem o seguinte:
- Erros de slot de replicação
- Problemas de configuração de publicação
- Problemas de conectividade de rede
- Privilégios insuficientes no banco de dados de origem
erros de certificado do servidor TLS
Para solucionar problemas de validação de certificado TLS do servidor, consulte Solucionar problemas de erros de certificado TLS.