Ingerir dados do SQL Server
Aprenda como importar dados do SQL Server para o Databricks usando LakeFlow Connect.
O conector SQL Server oferece suporte aos bancos de dados SQL Azure , à Instância de Gerenciamento Azure SQL e aos bancos de dados SQL Amazon RDS. Isso inclui o SQL Server executado em máquinas virtuais (VMs) do Azure e no Amazon EC2. O conector também oferece suporte SQL Server on-premises usando as redes Azure ExpressRoute e AWS Direct Connect.
Requisitos
-
Para criar um gateway de ingestão e um pipeline de ingestão, você deve primeiro atender aos seguintes requisitos:
-
Seu workspace está habilitado para Unity Catalog.
-
O compute sem servidor está habilitado para o seu workspace. Consulte os requisitos do compute sem servidor.
-
Se você planeja criar uma conexão: Você tem privilégios
CREATE CONNECTIONno metastore. Consulte a seção sobre privilégios de gerenciamento no Unity Catalog.Se o seu conector for compatível com a criação de pipeline com base na interface do usuário, o senhor poderá criar a conexão e o pipeline ao mesmo tempo, concluindo as etapas desta página. No entanto, se o senhor usar a criação de pipeline baseada em API, deverá criar a conexão no Catalog Explorer antes de concluir as etapas desta página. Consulte Conectar-se a fontes de ingestão de gerenciar.
-
Se você planeja usar uma conexão existente: Você tem privilégios
USE CONNECTIONouALL PRIVILEGESna conexão. -
Você tem privilégios
USE CATALOGno catálogo de destino. -
Você tem privilégios
USE SCHEMA,CREATE TABLEeCREATE VOLUMEem um esquema existente ou privilégiosCREATE SCHEMAno catálogo de destino. -
O senhor tem acesso a uma instância primária do SQL Server. Os recursos de acompanhamento de alterações e captura de dados de alterações (CDC) não são suportados em réplicas de leitura ou instâncias secundárias.
-
Permissões irrestritas para criar clusters ou uma política personalizada (somente API). Uma política personalizada para o gateway deve atender aos seguintes requisitos:
-
Família: Job compute
-
A família de políticas substitui:
{
"cluster_type": {
"type": "fixed",
"value": "dlt"
},
"num_workers": {
"type": "unlimited",
"defaultValue": 1,
"isOptional": true
},
"runtime_engine": {
"type": "fixed",
"value": "STANDARD",
"hidden": true
}
}- Databricks recomenda especificar o menor número possível de nós worker para gateways de ingestão porque eles não afetam o desempenho do gateway. A política compute a seguir permite que o Databricks dimensione o gateway de ingestão para atender às necessidades de sua carga de trabalho. O requisito mínimo é de 8 núcleos para permitir a extração eficiente e eficiente de dados do seu banco de dados de origem.
Python{
"driver_node_type_id": {
"type": "fixed",
"value": "n2-highmem-64"
},
"node_type_id": {
"type": "fixed",
"value": "n2-standard-4"
}
}Para obter mais informações sobre a política de cluster, consulte Selecionar uma política de compute.
-
-
-
Para importar dados do SQL Server, você deve primeiro concluir os passos descritos em Configurar Microsoft SQL Server para importação para o Databricks.
Crie um gateway e um pipeline de ingestão.
Não interrompa manualmente o gateway de ingestão. O gateway deve estar em execução contínua para capturar as alterações antes que logs de alterações sejam truncados no banco de dados de origem. Se o gateway for interrompido, as alterações podem ser perdidas devido à retenção log , exigindo uma refresh completa de todas as tabelas afetadas. Parar e reiniciar o gateway também reconfigura a máquina virtual, o que aumenta o tempo startup . Se precisar solucionar problemas de gateway, consulte Solucionar problemas de ingestão do SQL Server ou entre em contato com o Suporte da Databricks.
- Databricks UI
- Declarative Automation Bundles
- Databricks notebook
- Terraform
-
Na barra lateral do site Databricks workspace, clique em ingestão de dados .
-
Na página Adicionar dados , em Conectores do Databricks , clique em SQL Server .
-
Na página **Conexão** do assistente de ingestão, selecione a conexão que armazena suas credenciais de acesso do SQL Server. Se você tiver o privilégio
CREATE CONNECTIONno metastore, poderá clicar em Criar conexão para criar uma nova conexão com os detalhes de autenticação em Criar uma conexão SQL Server.
Criar conexão para criar uma nova conexão com os detalhes de autenticação em Criar uma conexão SQL Server. -
Clique em Avançar .
-
Na página de configuração de ingestão , insira um nome exclusivo para o pipeline de ingestão. Este pipeline move dados do local de armazenamento temporário para o destino.
-
Selecione um catálogo e um esquema para gravar logs de eventos. O log de eventos contém logs de auditoria, verificações de qualidade de dados, progresso pipeline e erros. Se você tiver privilégios
USE CATALOGeCREATE SCHEMAno catálogo, poderá clicar. Para criar um novo esquema, clique em "Criar esquema" no menu suspenso. -
(Opcional) Defina a refresh automática completa para todas as tabelas como Ativada . Quando refresh automática está ativada, o pipeline tenta corrigir automaticamente problemas como eventos de limpeza log e certos tipos de evolução do esquema, atualizando completamente a tabela afetada. Se a história acompanhamento estiver habilitada, uma refresh completa apagará essa história.
-
Insira um nome exclusivo para o gateway de ingestão. O gateway é um pipeline que extrai as alterações da origem e as prepara para que o pipeline de ingestão as carregue.
-
Selecione um catálogo e um esquema para o local de preparação . Neste local é criado um volume para estágio de remoção de dados. Se você tiver privilégios
USE CATALOGeCREATE SCHEMAno catálogo, poderá clicar. Para criar um novo esquema, clique em "Criar esquema" no menu suspenso. -
Clique em Create pipeline (Criar pipeline) e continue .
-
Na página Origem , selecione as tabelas que deseja importar. Se você selecionar tabelas específicas, poderá configurar as definições da tabela:
a. (Opcional) Na tab Configurações , especifique um nome de destino para cada tabela ingerida. Isso é útil para diferenciar entre tabelas de destino quando você ingere um objeto no mesmo esquema várias vezes. Consulte Nomear uma tabela de destino.
um. (Opcional) Altere a configuração default da história acompanhamento . Consulte Habilitar história envio (SCD tipo 2).
-
Clique em Avançar e, em seguida, clique em Salvar e continuar .
-
Na página Destino , selecione um catálogo e um esquema para carregar os dados. Se você tiver privilégios
USE CATALOGeCREATE SCHEMAno catálogo, poderá clicar. Para criar um novo esquema, clique em "Criar esquema" no menu suspenso. -
Clique em Salvar e continuar .
-
Na página de configuração do banco de dados , clique em Validar para confirmar se sua fonte está configurada corretamente para ingestão no Databricks. Quaisquer configurações ausentes serão retornadas. Para saber os passos para resolver, clique em Concluir configuração . Em seguida, clique em Avançar . Alternativamente, clique em Ignorar validação .
-
(Opcional) Na página de programação e notificações , clique em
Criar programar . Defina a frequência de refresh das tabelas de destino. -
(Opcional) Clique
Adicione uma notificação para configurar notificações email para operações pipeline bem-sucedidas ou com falha e, em seguida, clique em Salvar e execute pipeline .
Antes de fazer a ingestão usando Pacotes de Automação Declarativa, é preciso ter acesso a uma conexão existente. Para obter instruções, consulte Criar uma conexão com o SQL Server.
O catálogo e o esquema de preparação podem ser os mesmos que o catálogo e o esquema de destino. O catálogo de encenação não pode ser um catálogo estrangeiro. Especifique o local de preparação na seção gateway_definition do seu arquivo YAML de pipeline de pacotes.
O gateway de ingestão extrai o Snapshot e altera os dados do banco de dados de origem e os armazena no volume de preparação Unity Catalog. O senhor deve executar o gateway como um pipeline contínuo. Isso ajuda a acomodar quaisquer políticas de retenção de log de alterações que o senhor tenha no banco de dados de origem.
A ingestão pipeline aplica o Snapshot e altera os dados do volume de preparação nas tabelas de transmissão de destino.
Os pacotes podem conter definições YAML de Job e tarefa, são gerenciados usando a CLI Databricks e podem ser compartilhados e executados em diferentes espaços de trabalho de destino (como desenvolvimento, teste e produção). Para mais informações, consulte O que são pacotes de automação declarativa?.
-
Crie um pacote usando a CLI do Databricks:
Bashdatabricks bundle init -
Adicione sua configuração de pipeline e Job ao pacote. Consulte Exemplos para um exemplo completo com todas as opções disponíveis.
-
implantado o pipeline usando o Databricks CLI:
Bashdatabricks bundle deploy
Atualize a célula Configuration no Notebook a seguir com a conexão de origem, o catálogo de destino, o esquema de destino e as tabelas a serem ingeridas da origem.
Você pode usar Terraform para implantar e gerenciar um pipeline de ingestão SQL Server . Para um framework de exemplo completo, incluindo configurações Terraform para criação de gateways e pipeline de ingestão, consulte os exemplos Terraform LakeFlow Connect catalogados no GitHub.
Verificar se a ingestão de dados foi bem-sucedida
A lista view na página de detalhes pipeline mostra o número de registros processados à medida que os dados são ingeridos. Esses números refresh automaticamente.
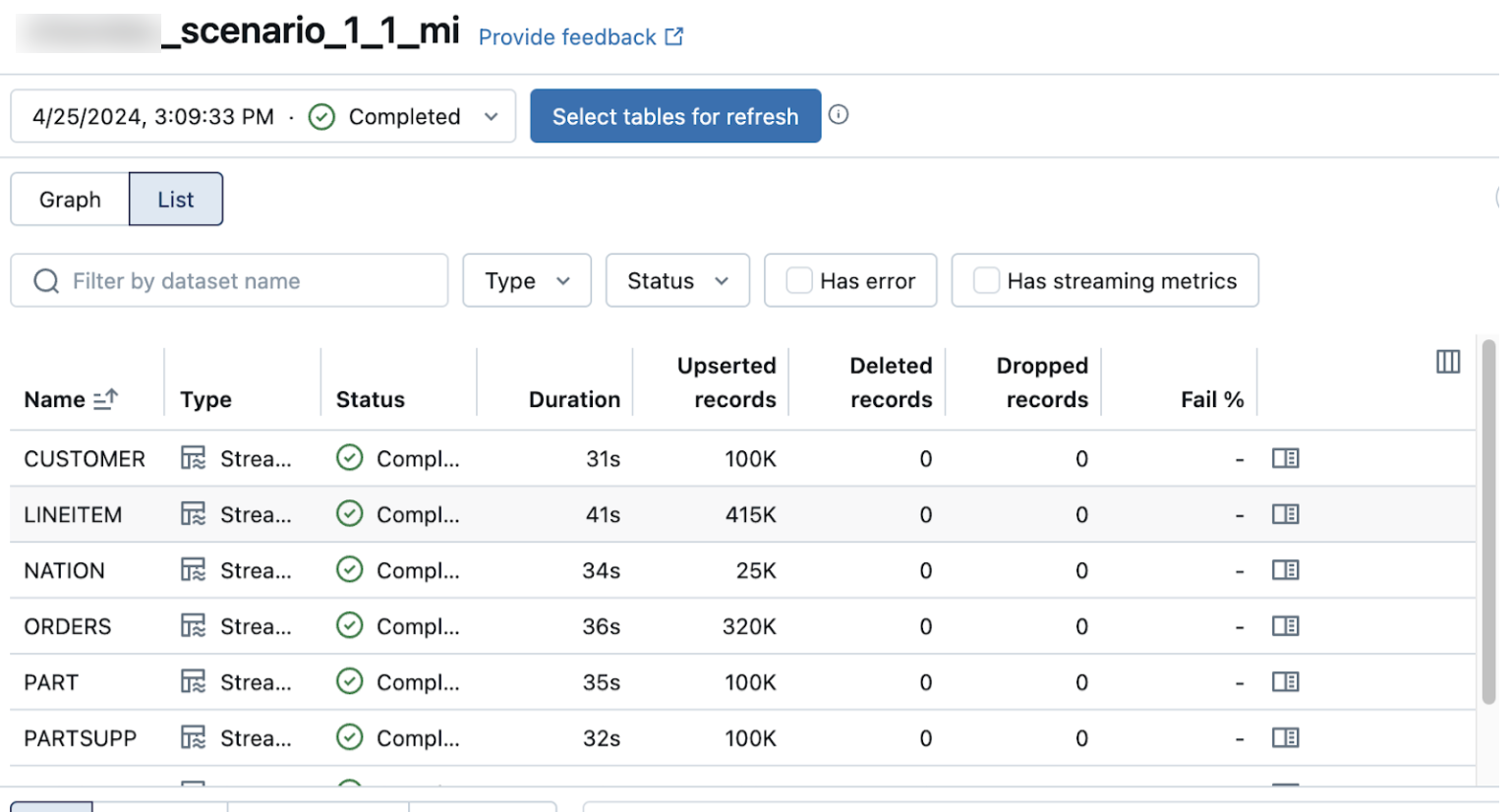
As colunas Upserted records e Deleted records não são exibidas por default. Você pode ativá-las clicando no ![]() botão de configuração das colunas e selecionando-as.
botão de configuração das colunas e selecionando-as.
Exemplos
Utilize esses exemplos para configurar seu pipeline.
Configuração do pipeline
- Declarative Automation Bundles
- Databricks notebook
O pacote a seguir define um pipeline de gateway, um pipeline de ingestão e um job agendado. Opções comentadas mostram toda a configuração disponível. Atualize as seções variables e targets com os detalhes de sua origem e destino.
bundle:
name: lakeflow-connect-sqlserver
# Variables parameterize the bundle for different environments and sources.
# Set values here, override per-target, or pass with: databricks bundle deploy -var="key=value"
variables:
# The name of the Unity Catalog connection to your SQL Server instance.
# This connection must already exist and be of type SQLSERVER.
connection_name:
description: 'Unity Catalog connection name for the SQL Server source'
# The SQL Server database name to ingest from.
# In Lakeflow Connect, this maps to source_catalog in the table/schema spec.
source_database:
description: 'SQL Server database name (maps to source_catalog in table specs)'
# The SQL Server schema to ingest from (for example, "dbo", "sales").
source_schema:
description: 'SQL Server schema name to ingest from'
# The Unity Catalog catalog where ingested Delta tables are created.
dest_catalog:
description: 'Destination Unity Catalog catalog for ingested tables'
# The Unity Catalog schema where ingested Delta tables are created.
dest_schema:
description: 'Destination Unity Catalog schema for ingested tables'
# The Unity Catalog catalog for the gateway's internal staging volume.
# Can be the same as dest_catalog. Must not be a foreign catalog.
staging_catalog:
description: 'Catalog for gateway staging volume'
# The Unity Catalog schema for the gateway's internal staging volume.
staging_schema:
description: 'Schema for gateway staging volume'
resources:
pipelines:
# --- Gateway pipeline ---
# Extracts change data from SQL Server and stages it in a Unity Catalog
# volume. Must run continuously to capture changes before change logs are
# truncated in the source database.
gw_pipeline:
name: 'lfc-sqlserver-gateway-${bundle.target}'
# Gateway pipelines must be continuous.
continuous: true
# "CURRENT" (stable) or "PREVIEW" (early access).
channel: 'CURRENT'
# (Optional) Associate with a budget policy for cost tracking.
# budget_policy_id: "<policy-uuid>"
# The gateway runs on classic compute. Cluster settings are managed
# automatically. You can optionally customize the cluster:
# clusters:
# - label: "default"
# autoscale:
# min_workers: 1
# max_workers: 4
# # node_type_id: "i3.xlarge"
# # Restrict the cluster to an approved cluster policy.
# # policy_id: "<cluster-policy-id>"
catalog: ${var.staging_catalog}
schema: ${var.staging_schema}
gateway_definition:
# (Required) Unity Catalog connection name (type SQLSERVER).
connection_name: ${var.connection_name}
# (Required) Catalog and schema for the staging volume.
gateway_storage_catalog: ${var.staging_catalog}
gateway_storage_schema: ${var.staging_schema}
# (Optional) Custom staging volume name. If not set, the system
# auto-generates: __databricks_ingestion_gateway_staging_data-<pipeline_id>
# gateway_storage_name: "my_custom_staging_volume"
# --- Ingestion pipeline ---
# Reads staged data from the gateway and applies it to Delta tables.
mi_pipeline:
name: 'lfc-sqlserver-ingestion-${bundle.target}'
# Continuous mode is not supported for the ingestion pipeline.
# Use a scheduled job to trigger runs.
continuous: false
channel: 'CURRENT'
# (Optional) Associate with a budget policy for cost tracking.
# budget_policy_id: "<policy-uuid>"
# The ingestion pipeline runs on serverless compute only.
serverless: true
# (Optional) Development mode for faster iteration (no retries).
# development: true
catalog: ${var.dest_catalog}
schema: ${var.dest_schema}
# (Optional) Email notifications for pipeline events.
# notifications:
# - email_recipients:
# - "team@example.com"
# alerts:
# - "on-update-failure"
# - "on-update-fatal-failure"
# - "on-flow-failure"
# (Optional) Run as a service principal for production.
# run_as:
# service_principal_name: "my-service-principal"
ingestion_definition:
# (Required) References the gateway pipeline. The connection is
# inherited from the gateway. Do not specify connection_name here.
ingestion_gateway_id: ${resources.pipelines.gw_pipeline.id}
# Pipeline-level table configuration defaults. These apply to all
# tables unless overridden at the schema or table level.
table_configuration:
# SCD Type: How changes are applied to destination tables.
# SCD_TYPE_1: Overwrites rows with latest values (default).
# SCD_TYPE_2: Preserves history with __START_AT/__END_AT columns.
# Requires CDC on source. CT does not support SCD_TYPE_2.
# APPEND_ONLY: Inserts only. Updates and deletes are ignored.
scd_type: 'SCD_TYPE_1'
# (Optional) Auto full refresh policy. Triggers a snapshot when the
# pipeline detects issues resolvable by re-reading all source data
# (for example, CT/CDC retention window expired).
# auto_full_refresh_policy:
# enabled: true
# min_interval_hours: 24
# (Optional) Schedule automatic full refreshes.
# full_refresh_window:
# start_hour: 2
# days_of_week:
# - "SUNDAY"
# time_zone_id: "America/Los_Angeles"
objects:
# Option 1: Schema-level ingestion. Ingests all tables from a source
# schema. New tables added to the schema are picked up automatically.
- schema:
source_catalog: ${var.source_database}
source_schema: ${var.source_schema}
destination_catalog: ${var.dest_catalog}
destination_schema: ${var.dest_schema}
# (Optional) Override table_configuration for this schema.
# table_configuration:
# scd_type: "SCD_TYPE_2"
# Option 2: Table-level ingestion. Provides granular control.
# Replace or combine with the schema-level spec.
# - table:
# source_catalog: ${var.source_database}
# source_schema: ${var.source_schema}
# source_table: "customers"
# destination_catalog: ${var.dest_catalog}
# destination_schema: ${var.dest_schema}
# # (Optional) Rename the table at the destination.
# # destination_table: "customers_v2"
# table_configuration:
# scd_type: "SCD_TYPE_1"
# # Include only specific columns (mutually exclusive with exclude_columns).
# # include_columns:
# # - "customer_id"
# # - "first_name"
# # - "email"
# # Exclude specific columns. All other columns are included.
# # exclude_columns:
# # - "internal_notes"
# # Override the primary key used for change detection.
# # primary_keys:
# # - "customer_id"
# # Logical ordering columns for change resolution.
# # sequence_by:
# # - "updated_at"
# # Auto full refresh for this table.
# # auto_full_refresh_policy:
# # enabled: true
# # min_interval_hours: 48
# (Optional) Grant additional users or groups access.
# permissions:
# - user_name: "analyst@example.com"
# level: "CAN_VIEW"
# - group_name: "data-engineers"
# level: "CAN_RUN"
# --- Scheduled job ---
# Triggers the ingestion pipeline on a schedule.
jobs:
mi_schedule:
name: 'lfc-sqlserver-ingestion-schedule-${bundle.target}'
# Quartz cron syntax: "seconds minutes hours day month day-of-week"
# Examples: "0 0 * * * ?" (hourly), "0 0 */4 * * ?" (every 4 hours)
schedule:
quartz_cron_expression: '0 */30 * * * ?'
timezone_id: 'UTC'
tasks:
- task_key: 'run_ingestion'
pipeline_task:
pipeline_id: ${resources.pipelines.mi_pipeline.id}
# email_notifications:
# on_failure:
# - "team@example.com"
# Deploy to different workspaces with: databricks bundle deploy -t <target>
targets:
dev:
default: true
workspace:
host: https://<workspace-url>.cloud.databricks.com
variables:
connection_name: '<sqlserver-connection>'
source_database: '<database-name>'
source_schema: 'dbo'
dest_catalog: '<dest-catalog>'
dest_schema: '<dest-schema>'
staging_catalog: '<staging-catalog>'
staging_schema: '<staging-schema>'
Segue abaixo um exemplo da seção Configuration de uma especificação de pipeline:
# The name of the UC connection with the credentials to access the source database
connection_name = "my_connection"
# The name of the UC catalog and schema to store the replicated tables
target_catalog_name = "main"
target_schema_name = "lakeflow_sqlserver_connector_cdc"
# The name of the UC catalog and schema to store the staging volume with intermediate
# CDC and snapshot data. Use the destination catalog/schema by default.
stg_catalog_name = target_catalog_name
stg_schema_name = target_schema_name
# The name of the Gateway pipeline to create
gateway_pipeline_name = "cdc_gateway"
# The name of the Ingestion pipeline to create
ingestion_pipeline_name = "cdc_ingestion"
# Construct the full list of tables to replicate.
# IMPORTANT: The letter case of catalog, schema, and table names must match exactly
# the case used in the source database system tables.
tables_to_replicate = replicate_full_db_schema("MY_DB", ["MY_DB_SCHEMA"])
# Append tables from additional schemas as needed:
# + replicate_tables_from_db_schema("MY_DB", "MY_SCHEMA_2", ["table3", "table4"])
Padrões comuns
Para configurações avançadas pipeline , consulte Padrões comuns para gerenciar pipeline de ingestão.
Próximos passos
começar, programar e definir alerta em seu pipeline. Consulte Tarefa comum de manutenção pipeline.