detecção de anomalia
Visualização
Este recurso está em Pré-visualização Pública.
Esta página descreve o que é detecção de anomalia, o que ela monitora e como utilizá-la.
detecção de anomalia usa armazenamentodefault.
O que é detecção de anomalia?
Utilizando a detecção de anomalias, você pode monitorar facilmente a qualidade dos dados de todas as tabelas em um esquema. O Databricks utiliza inteligência de dados, analisando padrões históricos para avaliar automaticamente a qualidade dos dados, especificamente a integridade e a atualização de cada tabela. Os proprietários dos dados têm acesso à tabela de registro, o que lhes permite identificar e resolver rapidamente anomalias em todo o metastore. Os resultados nos níveis de catálogo, esquema e tabela estão disponíveis no Explorador de Catálogo ou no Hub de Governança (Pré-visualização Privada).
Requisitos
- Workspace habilitado para o Unity Catalog.
- Os usuários existentes precisam ter compute serverless ativado. Para obter instruções, consulte Conectar-se à compute serverless.
- Para ativar a detecção de anomalia em um esquema, você deve ter privilégios de gerenciar SCHEMA ou gerenciar CATALOG no esquema do catálogo.
Como funciona a detecção de anomalia?
Databricks cria um Job em segundo plano que monitora as tabelas para verificar se os dados estão atualizados e completos . O Databricks utiliza uma varredura inteligente para determinar o momento ideal para analisar as tabelas.
A digitalização inteligente alinha automaticamente a frequência de digitalização com a cadência de atualização da tabela, garantindo que os dados permaneçam atualizados sem programação manual. O sistema prioriza tabelas de alto impacto, com base na popularidade e no uso subsequente, enquanto examina tabelas menos críticas com menos frequência ou as ignora completamente. Para excluir manualmente algumas tabelas, use a API Criar um Monitor ou Atualizar um Monitor, definindo o parâmetro excluded_table_full_names para especificar as tabelas excluídas. Para mais informações, consulte a documentaçãoAPI.
A "frescura" refere-se à frequência com que uma tabela foi atualizada. O monitoramento da qualidade dos dados analisa o histórico de commits em uma tabela e constrói um modelo por tabela para prever o momento do próximo commit. Se uma confirmação (commit) for feita com um atraso incomum, a tabela será marcada como obsoleta.
O termo "completude" refere-se ao número de linhas que se espera que sejam gravadas na tabela nas últimas 24 horas. O monitoramento da qualidade dos dados analisa a contagem histórica de linhas e, com base nesses dados, prevê um intervalo de números esperados de linhas. Se o número de linhas inseridas nas últimas 24 horas for menor que o limite inferior desse intervalo, a tabela será marcada como incompleta.
A funcionalidade de atualização de eventos, baseada em colunas de tempo do evento e latência de ingestão, estava disponível apenas para usuários da versão beta de monitoramento da qualidade dos dados. Na versão atual, a atualização constante dos eventos não é suportada.
A detecção de anomalia não modifica nenhuma das tabelas que monitora, nem adiciona sobrecarga a nenhum Job que preencha essas tabelas.
Habilitar detecção de anomalia em um esquema
Para habilitar a detecção de anomalia em um esquema, navegue até o esquema no Unity Catalog.
-
Na página do esquema, clique na tab Detalhes .
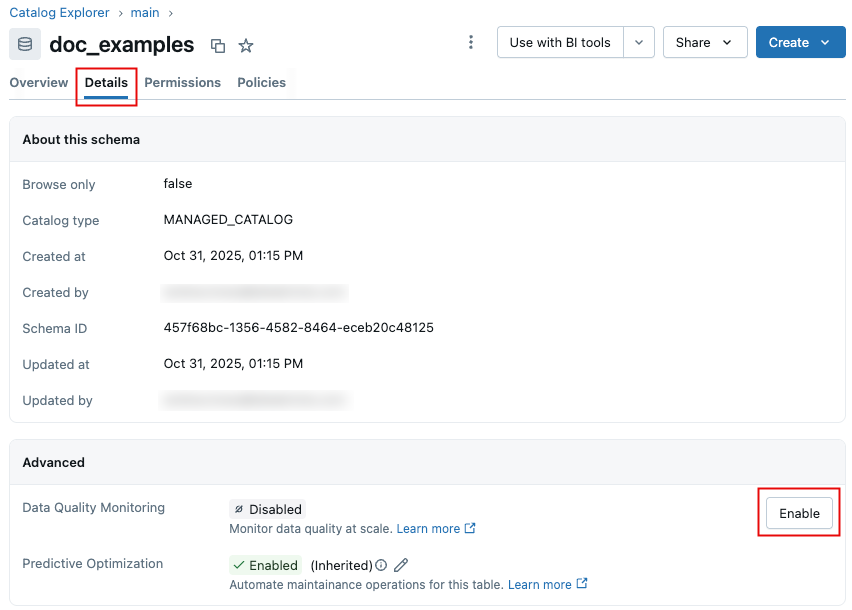
-
Clique em Ativar . Na caixa de diálogo de monitoramento da qualidade dos dados , clique em Salvar .
-
Uma varredura foi iniciada. Databricks verifica automaticamente cada tabela na mesma frequência em que ela é atualizada, fornecendo informações atualizadas sem exigir configuração manual para cada tabela. Para esquemas habilitados antes de 24 de setembro de 2025, Databricks executa o monitoramento em dados históricos ("backtesting") na primeira verificação, para verificar a qualidade das suas tabelas como se o monitoramento da qualidade dos dados tivesse sido habilitado no seu esquema duas semanas atrás.
-
Quando a verificação estiver concluída, os problemas de qualidade detectados são registrados na tabela de saída do sistema, com as informações exibidas na interface do usuário. Para obter detalhes, consulte Revisar resultados de logs de detecção de anomalias. Você pode acessar a interface do usuário a qualquer momento clicando em "Ver resultados" ao lado da opção " Monitoramento da qualidade dos dados" .
Desativar detecção de anomalia
Para desativar a detecção de anomalia:
-
Clique no ícone do lápis.

-
Na caixa de diálogo de monitoramento da qualidade dos dados , clique no botão de alternância.
Quando você desativa a detecção de anomalia, o trabalho de detecção de anomalia e todas as tabelas de detecção de anomalia e informações são excluídas. Esta ação não pode ser desfeita.
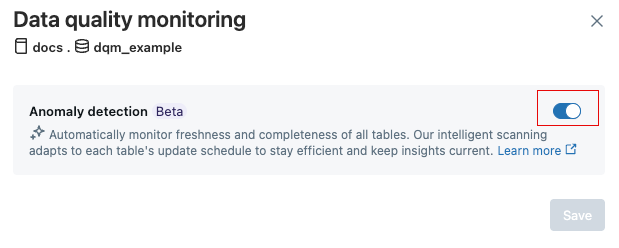 3. Clique em Salvar .
3. Clique em Salvar .
Interface de usuário para monitoramento da qualidade dos dados
Em 7 de outubro de 2025, a Databricks lançou uma nova versão do monitoramento da qualidade dos dados. Os esquemas habilitados para monitoramento da qualidade dos dados a partir dessa data possuem uma nova interface de resultados.
Para informações sobre a nova IU, consulte visualizar resultados de monitoramento de qualidade de dados na IU.
Para obter informações sobre a interface de usuário legada, consulte Painel de qualidade de dados (legado).
A Databricks recomenda que você habilite a nova versão para todos os seus esquemas existentes. O painel de controle legado da versão beta não será mais atualizado.
Para ativar a nova versão, use a opção de monitoramento da qualidade dos dados para desativar o recurso e, em seguida, use-a novamente para reativá-lo.
Visualizar os resultados do monitoramento da qualidade dos dados na interface do usuário.
Após ativar o monitoramento da qualidade dos dados em um esquema, você pode abrir a página de resultados clicando em "Exibir resultados" . Você também pode acessar os resultados de todos os esquemas que têm o monitoramento ativado no Explorador de Catálogo.
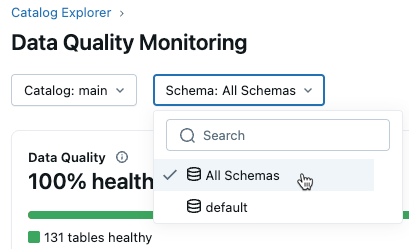
A interface de resultados contém menus suspensos para catálogo e esquema. Ao selecionar um catálogo, a dropdown de esquemas é preenchida com os esquemas desse catálogo que têm o monitoramento de qualidade de dados ativado.
-
Se você tiver privilégios de gerenciamento ou seleção no catálogo, poderá view incidentes no nível do catálogo. Para view todos os incidentes em um catálogo, selecione "Todos os Esquemas" no menu suspenso "Esquema" .
-
Para view incidentes de um esquema específico, você também precisa ter privilégios de gerenciamento ou seleção nesse esquema. Selecionar um esquema mostra os incidentes apenas para esse esquema.
A página de resultados exibe uma seção de resumo na parte superior, que mostra a qualidade geral dos dados para o escopo selecionado, incluindo a porcentagem de tabelas íntegras e a porcentagem de esquemas/tabelas atualmente monitorados. Abaixo desta seção encontra-se uma tabela listando os incidentes em todas as tabelas monitoradas no escopo selecionado. Use os botões para exibir as tabelas "Não Saudável" , "Saudável" ou "Erro" .
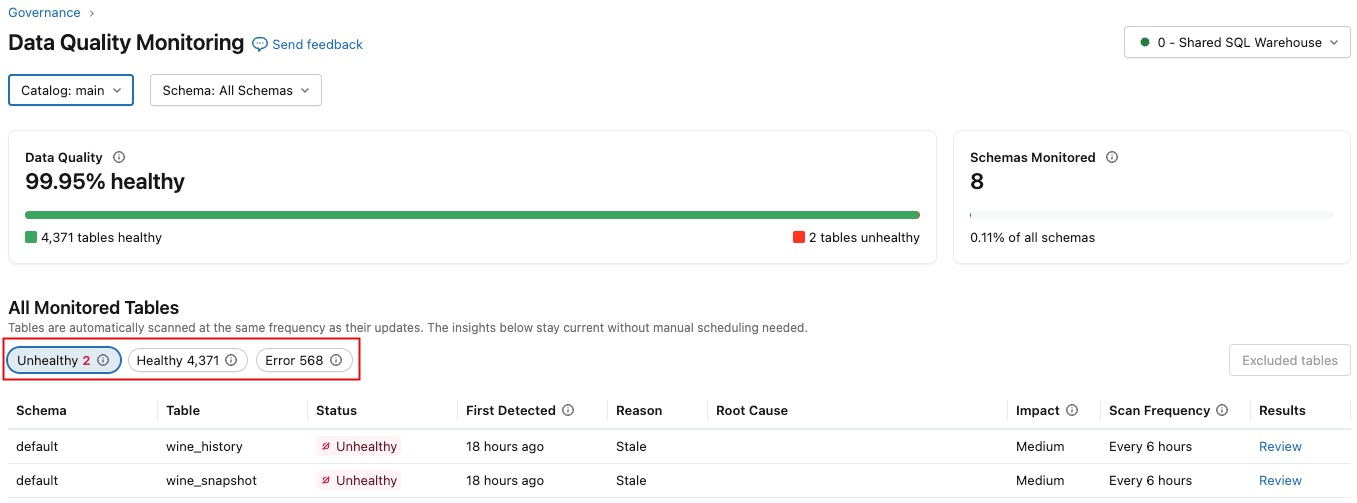
A tabela a seguir descreve as colunas, que são ligeiramente diferentes dependendo se você selecionar Não saudável , Saudável ou Erro .
Coluna | Descrição |
|---|---|
Status |
|
Detectado pela primeira vez | Quando o primeiro incidente foi detectado. Aparece apenas na tab "Não Saudável" . |
Última digitalização | Quando a tabela foi digitalizada pela última vez. Aparece apenas na tab Saúde . |
Razão | Se a mesa está insalubre devido ao frescor ou ao fato de estar cheia. Aparece apenas na tab "Não Saudável" . |
Causa raiz | informações sobre o trabalho upstream que contribui para o problema (consulte Revisar resultados de logs de detecção de anomalia para obter detalhes). Aparece apenas na tab "Não Saudável" . |
Impacto | Uma medida qualitativa do impacto subsequente ( Alto , Médio ou Baixo ), com base no número de tabelas e consultas subsequentes afetadas. |
Frequência de varredura | Com que frequência a tabela foi analisada na última semana. |
Resultados | Um link para a página de qualidade da tabela , onde você pode view tendências históricas e gráficos que explicam por que uma anomalia foi detectada. |
Estado de erro | Mensagem de erro. Aparece apenas na tab Erro . |
Detalhes | Detalhes sobre a mensagem de erro. Aparece apenas na tab Erro . |
visualizar resultados no nível do metastore
Esta seção fornece um padrão que você pode importar para seu workspace. Este padrão cria um painel que permite view todos os resultados de qualidade em todo o metastore.
Para usar este padrão, você deve ter acesso à tabela system.data_quality_monitoring.table_results . Por default, somente os administradores account têm acesso a esta tabela. Eles podem conceder acesso a outras pessoas conforme necessário.
Como usar o padrão
Siga estes passos:
- Baixe o arquivo padrão: metastore-quality- JSON .
- Na barra lateral workspace , clique em
 Painéis de controle .
Painéis de controle . - No canto superior direito, selecione Importar painel de controle do arquivo no menu suspenso Criar painel de controle .
- Na caixa de diálogo, clique em Escolher arquivo , navegue até o arquivo padrão e clique em Importar painel .
O arquivo foi importado e o painel de controle apareceu.
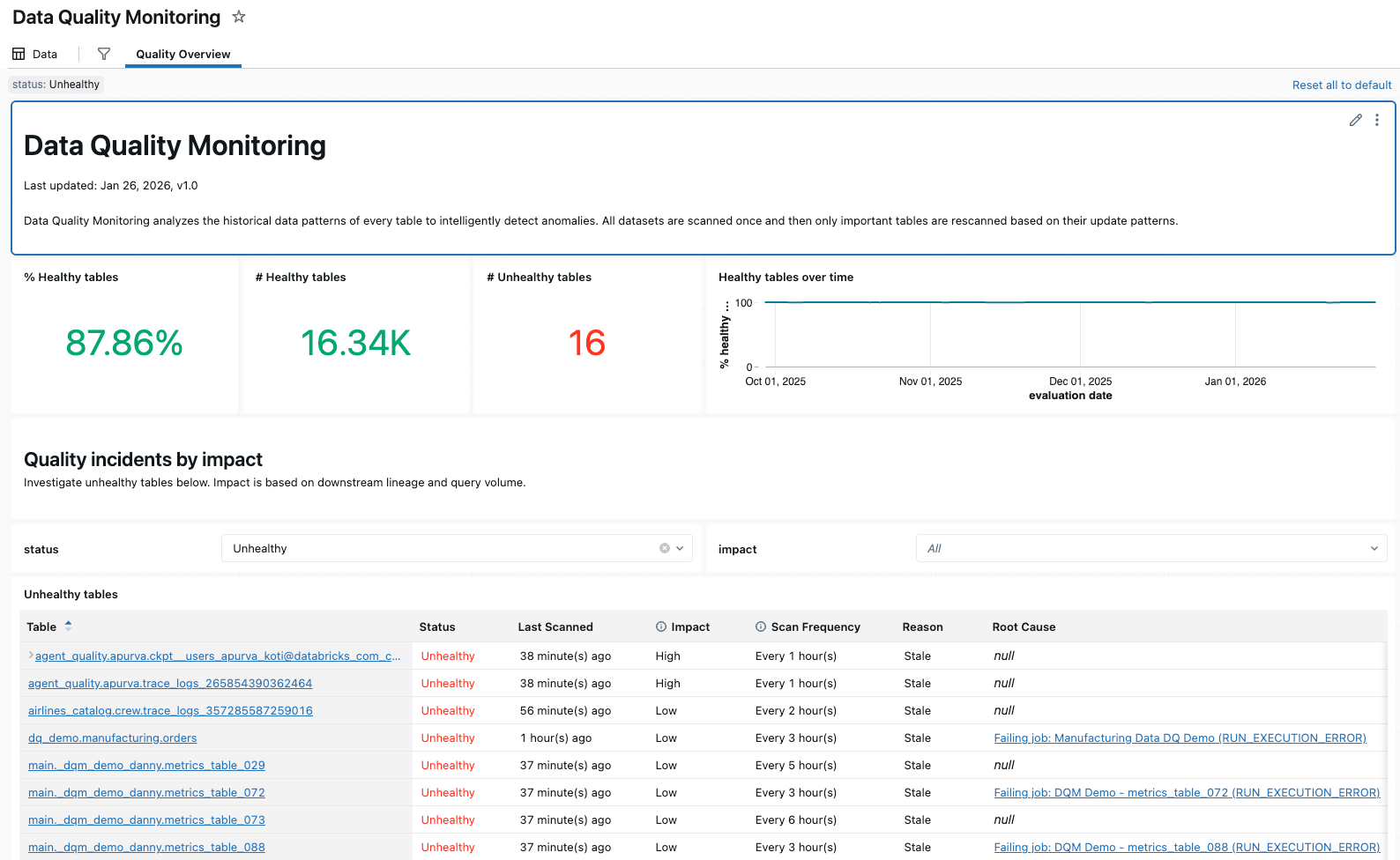
Detalhes de qualidade da mesa
A interface de usuário Detalhes da Qualidade da Tabela permite que você explore as tendências em detalhes e entenda por que anomalias foram detectadas em tabelas específicas do seu esquema. Você pode acessar essa view de diversas maneiras:
- Na interface de resultados (nova experiência), clique no link de revisão na lista de incidentes.
- No painel de monitoramento (painel antigo Lakeview ), clique no nome da tabela na tab Visão geral da qualidade.
- A partir do visualizador de tabelas da UC , acessando a tab Qualidade na página da tabela.
Todas as opções levam você à mesma view de Detalhes da Qualidade da Tabela para a tabela selecionada.
Dada uma tabela, a interface do usuário exibe resumos de cada verificação de qualidade da tabela, com gráficos dos valores previstos e observados em cada registro de tempo de avaliação. O gráfico apresenta os resultados dos dados da última semana.
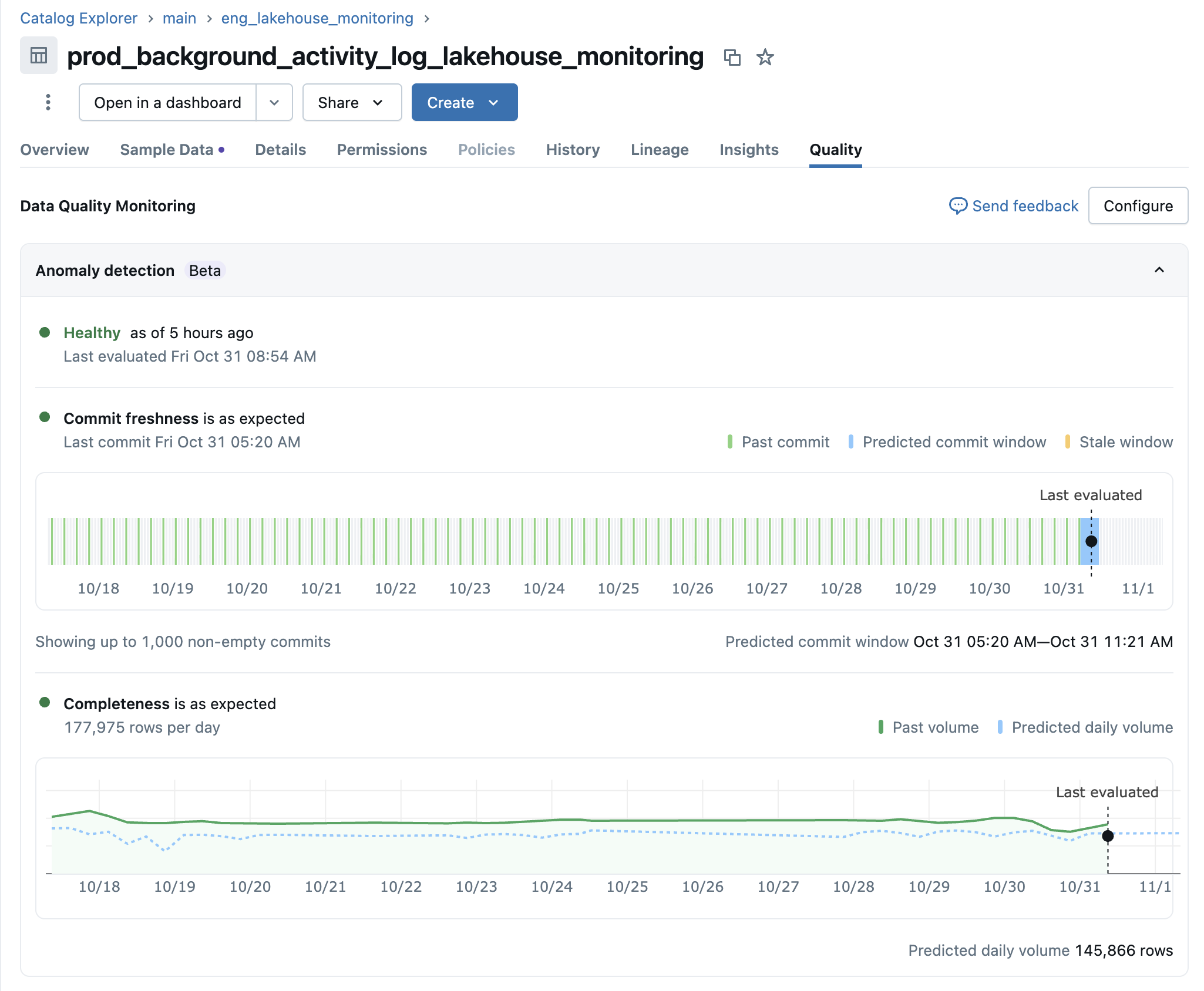
Caso a tabela não passe nas verificações de qualidade, a interface do usuário também exibirá qualquer tarefa upstream que tenha sido identificada como a causa raiz.
Configurar alerta
Para configurar um alerta Databricks SQL na tabela de resultados de saída, consulte Configurar alerta com base na detecção de anomalia.
Limitações
- detecção de anomalia não suporta visualização.
- A determinação da completude não leva em account métricas como a fração de valores nulos, zero ou NaN.
Painel de qualidade de dados (legado)
O painel de monitoramento da qualidade dos dados estava disponível apenas para usuários da versão antiga. Na versão atual, utilize a visualização dos resultados do monitoramento da qualidade dos dados na interface do usuário.
A primeira execução do monitor de qualidade de dados cria um painel para resumir os resultados e as tendências derivadas da tabela de registro. O painel é preenchido automaticamente com informações sobre o esquema digitalizado. Um único painel é criado por workspace neste caminho: /Shared/Databricks Quality Monitoring/Data Quality Monitoring.
Visão geral da qualidade
A tab Visão Geral da Qualidade exibe um resumo do status de qualidade mais recente das tabelas em seu esquema, com base na avaliação mais recente.
Para começar, você precisa inserir a tabela de logs do esquema que deseja analisar para preencher o painel.
A parte superior do painel de controle exibe uma visão geral dos resultados da verificação.
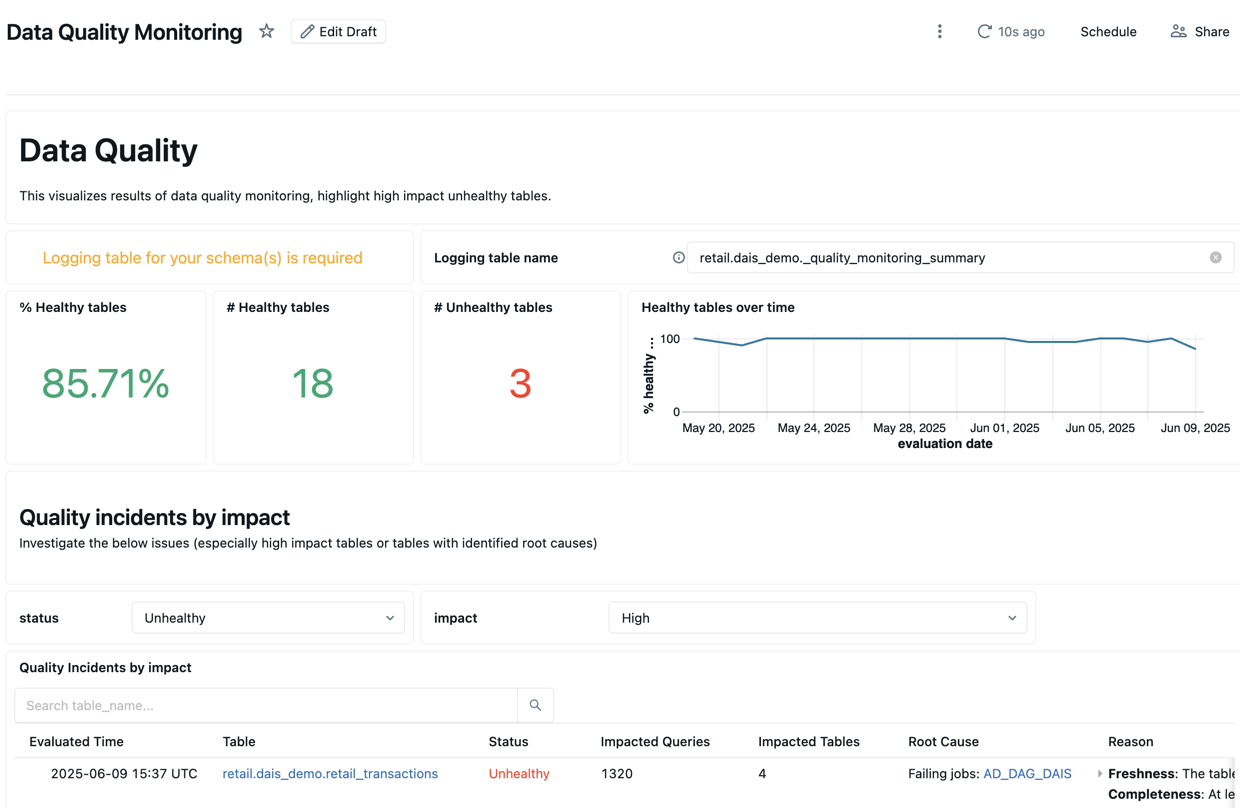
Abaixo do resumo encontra-se uma tabela listando os incidentes de qualidade por impacto. Quaisquer causas raiz identificadas são exibidas na coluna root_cause_analysis .
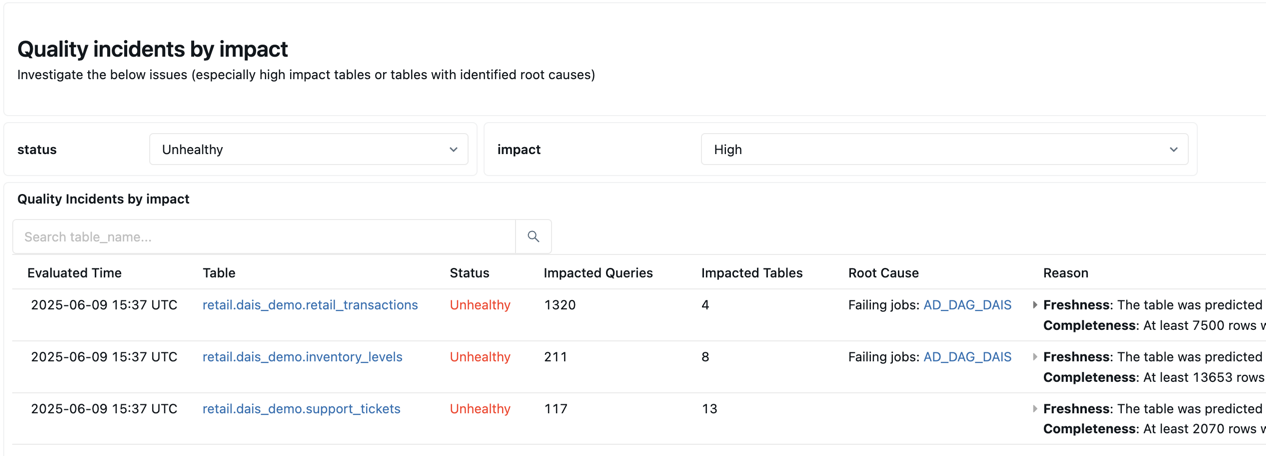
Abaixo da tabela de incidentes de qualidade, encontra-se uma tabela com as tabelas estáticas identificadas que não foram atualizadas há muito tempo.
Definir parâmetros para avaliação de frescor e integridade (legado)
A partir de 21 de julho de 2025, a configuração dos parâmetros do Job não será mais suportada para novos clientes. Se precisar configurar as definições da tarefa, entre em contato com Databricks.
Para editar os parâmetros que controlam a tarefa, como a frequência de execução ou o nome da tabela de resultados dos logs, você deve editar os parâmetros da tarefa na tab Tarefa" da página da tarefa.
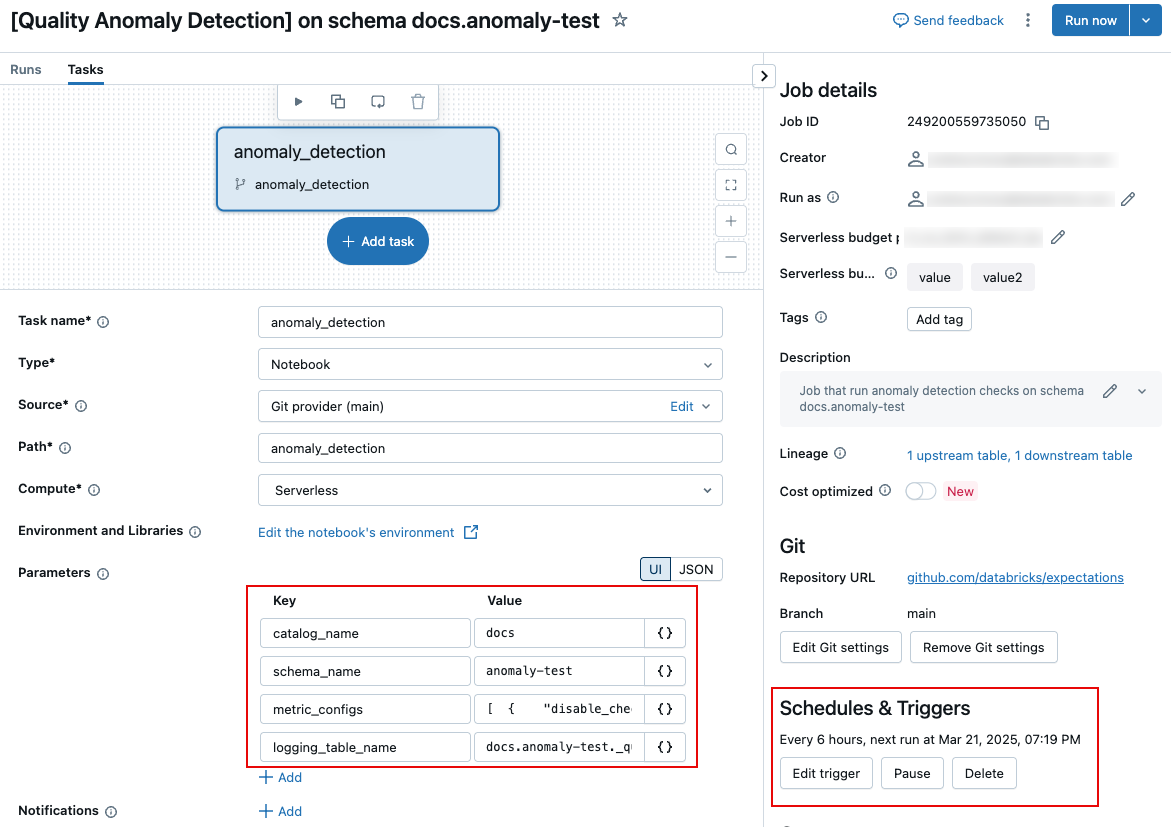
As seções a seguir descrevem configurações específicas. Para informações sobre como definir parâmetros de tarefa, consulte Configurar parâmetros de tarefa.
programação e notificações (legado)
Para personalizar o programador da tarefa ou configurar notificações, use as configurações de programador e gatilhos na página da tarefa. Veja Automatizando tarefas com programadores e gatilhos.
Nome da tabela de registro (legada)
Para alterar o nome da tabela de registro ou salvar a tabela em um esquema diferente, edite o parâmetro da tarefa Job logging_table_name e especifique o nome desejado. Para salvar a tabela de registro em um esquema diferente, especifique o nome completo de 3 níveis.
Personalizar avaliações freshness e completeness (legado)
Todos os parâmetros desta seção são opcionais. Por default, a detecção de anomalia determina o limite com base na análise da história da tabela.
Esses parâmetros são campos dentro do parâmetro de tarefa metric_configs. O formato de metric_configs é uma string JSON com os seguintes valores default :
[
{
"disable_check": false,
"tables_to_skip": null,
"tables_to_scan": null,
"table_threshold_overrides": null,
"table_latency_threshold_overrides": null,
"static_table_threshold_override": null,
"event_timestamp_col_names": null,
"metric_type": "FreshnessConfig"
},
{
"disable_check": true,
"tables_to_skip": null,
"tables_to_scan": null,
"table_threshold_overrides": null,
"metric_type": "CompletenessConfig"
}
]
Os seguintes parâmetros podem ser usados tanto para avaliações freshness quanto para avaliações completeness .
Nome do campo | Descrição | Exemplo |
|---|---|---|
| Somente as tabelas especificadas são verificadas. |
|
| As tabelas especificadas são ignoradas durante a verificação. |
|
| A digitalização não é execução. Use este parâmetro se quiser desativar apenas a varredura |
|
Os seguintes parâmetros aplicam-se apenas à avaliação freshness :
Nome do campo | Descrição | Exemplo |
|---|---|---|
| Lista de colunas de carimbo de data/hora que as tabelas em seu esquema podem ter. Se uma tabela tiver uma dessas colunas, ela será marcada com |
|
| Um dicionário que consiste em nomes de tabelas e limites (em segundos) que especificam o intervalo máximo desde a última atualização da tabela antes de marcar uma tabela como |
|
| Um dicionário que consiste em nomes de tabelas e limite de latência (em segundos) que especifica o intervalo máximo desde o último carimbo de data/hora na tabela antes de marcar uma tabela como |
|
| Quantidade de tempo (em segundos) antes que uma tabela seja considerada estática (ou seja, que não seja mais atualizada). |
|
O parâmetro a seguir aplica-se somente à avaliação completeness :
Nome do campo | Descrição | Exemplo |
|---|---|---|
| Um dicionário composto por nomes de tabelas e limites de volume de linhas (especificados como números inteiros). Se o número de linhas adicionadas a uma tabela nas últimas 24 horas for menor que o limite especificado, a tabela será marcada como |
|