Aplicar AI no uso de dados Databricks AI Functions
Visualização
Esse recurso está em Public Preview. Consulte AI e machine learning para saber sobre a disponibilidade da região.
Este artigo descreve o site Databricks AI Functions e as funções compatíveis.
O que é AI Functions?
AI Functions são funções integradas que você pode usar para aplicar AI, como tradução de texto ou análise de sentimentos, aos seus dados armazenados no Databricks. Eles podem ser executados de qualquer lugar no Databricks, incluindo Databricks SQL, Notebook, pipeline declarativo LakeFlow Spark e fluxo de trabalho.
AI Functions são simples de usar, rápidos e dimensionáveis. Os analistas podem usá-los para aplicar inteligência de dados a seus dados proprietários, enquanto os engenheiros de aprendizado de máquina e data scientists podem usá-los para criar pipeline de lotes de nível de produção.
AI Functions fornecem funções específicas para tarefas e de propósito geral.
- As funções específicas da tarefa fornecem recursos de alto nível para a tarefa AI, como resumo de texto e tradução. Essas funções específicas da tarefa são alimentadas por modelos generativos de última geração AI que são hospedados e gerenciados por Databricks. Consulte as funções específicas da tarefa AI para obter informações sobre as funções e os modelos compatíveis.
ai_queryé uma função de uso geral que permite que o senhor aplique qualquer tipo de modelo AI em seus dados. Consulte Função de uso geral:ai_query.
específico da tarefa AI funções
Funções específicas de tarefas são definidas para uma tarefa específica para que você possa automatizar ações de rotina, como resumos simples e traduções rápidas. Databricks recomenda essas funções para começar porque elas invocam modelos AI generativos de última geração mantidos pela Databricks e não exigem nenhuma personalização.
Consulte Analisar avaliações de clientes usando AI Functions para ver um exemplo.
A tabela a seguir lista as funções suportadas e as tarefas que elas executam.
Função | Descrição |
|---|---|
Realizar análise de sentimento no texto de entrada usando um modelo gerativo de última geração AI. | |
Classifique o texto de entrada de acordo com o rótulo fornecido pelo senhor usando um modelo gerativo de última geração AI. | |
Extrair entidades especificadas por rótulo do texto usando um modelo gerativo de última geração AI. | |
Corrija erros gramaticais em textos usando um modelo gerativo de última geração AI. | |
Responda ao prompt fornecido pelo usuário usando um modelo generativo de última geração AI. | |
Mascarar entidades especificadas no texto usando um modelo gerativo de última geração AI. | |
Extrair conteúdo estruturado de documentos não estruturados usando um modelo gerativo de última geração AI. | |
Compare dois strings e compute a pontuação de similaridade semântica usando um modelo gerativo AI de última geração. | |
Gerar um resumo do texto usando o site SQL e o modelo gerativo de última geração AI. | |
Traduza o texto para um idioma de destino especificado usando um modelo gerativo de última geração AI. | |
Preveja dados até um horizonte especificado. Essa função com valor de tabela foi projetada para extrapolar dados de séries temporais para o futuro. | |
Pesquisar e consultar um Mosaic AI Vector Search usando um modelo generativo de última geração AI. |
Função de uso geral: ai_query
A função ai_query() permite que o senhor aplique qualquer modelo AI aos dados para tarefas generativas AI e clássicas ML, incluindo extração de informações, resumo de conteúdo, identificação de fraudes e previsão de receita. Para obter detalhes e parâmetros de sintaxe, consulte a funçãoai_query.
A tabela a seguir resume os tipos de modelos compatíveis, os modelos associados e os requisitos de configuração do servindo modelo endpoint para cada um.
Tipo | Descrição | Modelos compatíveis | Requisitos |
|---|---|---|---|
Modelos pré-implantados | Esses modelos de base são hospedados pelo Databricks e oferecem endpoints pré-configurados que você pode consultar usando | Esses modelos são suportados e otimizados para começar com lotes de inferência e fluxo de trabalho de produção:
Outros modelos hospedados Databricksestão disponíveis para uso com AI Functions, mas não são recomendados para produção de lotes de inferência de fluxo de trabalho em escala. Esses outros modelos são disponibilizados para inferência de tempo real usando APIs de modelo de fundação pay-per-tokens. | Databricks Runtime 15.4 LTS ou acima é necessário para usar essa funcionalidade. Não requer provisionamento ou configuração no site endpoint. O uso desses modelos pelo senhor está sujeito às licenças e aos termos aplicáveis do desenvolvedor do modelo e à disponibilidade regional do AI Functions. |
Traga seu próprio modelo | Você pode trazer seus próprios modelos e consultá-los usando AI Functions. AI Functions oferece flexibilidade para que você possa consultar modelos para cenários de inferência de tempo real ou de lotes. |
|
|
Usar ai_query com modelos de fundação
O exemplo a seguir demonstra como usar o site ai_query usando um modelo básico hospedado pela Databricks.
- Consulte a função
ai_querypara obter detalhes e parâmetros de sintaxe. - Consulte Entradas multimodais para exemplos de consultas de entrada multimodal.
- Consulte Exemplos de cenários avançados para obter orientações sobre como configurar parâmetros para casos de uso avançados, como:
- Lidar com erros usando
failOnError - Saídas estruturadas no Databricks sobre como especificar saídas estruturadas para suas respostas de consulta.
- Lidar com erros usando
SELECT text, ai_query(
"databricks-meta-llama-3-3-70b-instruct",
"Summarize the given text comprehensively, covering key points and main ideas concisely while retaining relevant details and examples. Ensure clarity and accuracy without unnecessary repetition or omissions: " || text
) AS summary
FROM uc_catalog.schema.table;
Exemplo de Notebook: inferência de lotes e extração de dados estruturados
O exemplo a seguir do Notebook demonstra como executar extração básica de dados estruturados usando ai_query para transformar dados brutos e não estruturados em informações organizadas e utilizáveis por meio de técnicas de extração automatizadas. Este Notebook também mostra como aproveitar a Avaliação de Agentes Mosaic AI para avaliar a precisão usando dados de verdade.
Caderno de lotes de inferência e extração de dados estruturados
Use ai_query com modelos de ML tradicionais
ai_query suporta modelos tradicionais de ML, inclusive modelos totalmente personalizados. Esses modelos devem ser implantados no endpoint do modelo de serviço. Para obter detalhes e parâmetros de sintaxe, consulte Função de funçãoai_query.
SELECT text, ai_query(
endpoint => "spam-classification",
request => named_struct(
"timestamp", timestamp,
"sender", from_number,
"text", text),
returnType => "BOOLEAN") AS is_spam
FROM catalog.schema.inbox_messages
LIMIT 10
Exemplo de Notebook: inferência de lotes usando BERT para reconhecimento de entidades nomeadas
O Notebook a seguir mostra um exemplo tradicional de inferência de lotes de modelo de ML usando BERT.
inferência de lotes usando BERT para reconhecimento de entidade nomeada Notebook
Use AI Functions em Python fluxo de trabalho existente
AI Functions pode ser facilmente integrado ao Python fluxo de trabalho existente.
O seguinte grava a saída do ai_query em uma tabela de saída:
df_out = df.selectExpr(
"ai_query('databricks-meta-llama-3-3-70b-instruct', CONCAT('Please provide a summary of the following text: ', text), modelParameters => named_struct('max_tokens', 100, 'temperature', 0.7)) as summary"
)
df_out.write.mode("overwrite").saveAsTable('output_table')
O texto a seguir grava o texto resumido em uma tabela:
df_summary = df.selectExpr("ai_summarize(text) as summary")
df_summary.write.mode('overwrite').saveAsTable('summarized_table')
Use AI Functions na produção fluxo de trabalho
Para inferência de lotes em grande escala, você pode integrar AI Functions específicas de tarefas ou a função de propósito geral ai_query em seu fluxo de trabalho de produção, como pipeline declarativo LakeFlow Spark , fluxo de trabalho Databricks e transmissão estruturada. Isso possibilita o processamento em escala de nível de produção. Consulte o pipeline de inferência de lotes de implante para exemplos e detalhes.
Monitorar o progresso do site AI Functions
Para entender quantas inferências foram concluídas ou falharam e solucionar problemas de desempenho, você pode monitorar o progresso das AI Functions usando o recurso de perfil de consulta.
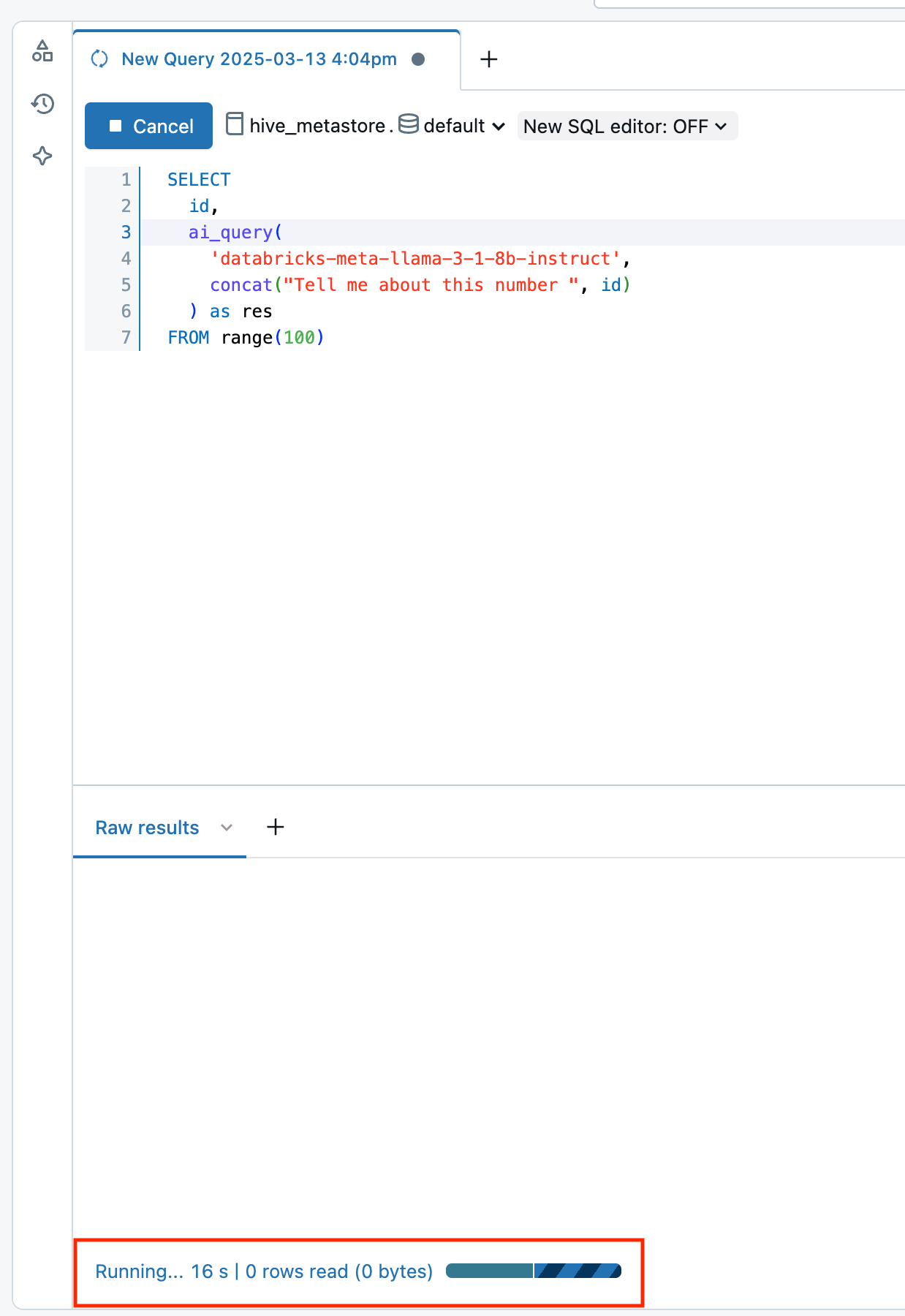
Em Databricks Runtime 16.1 ML e acima, na janela de consulta do editor SQL em seu workspace:
- Selecione o link Running--- na parte inferior da janela de resultados brutos . A janela de desempenho é exibida à direita.
- Clique em See query profile (Ver perfil de consulta ) para view detalhes de desempenho.
- Clique em AI Query para ver as métricas dessa consulta específica, incluindo o número de inferências concluídas e com falha e o tempo total que a solicitação levou para ser concluída.
visualizar custos para cargas de trabalho da função AI
Os custos da função AI são registrados como parte do produto MODEL_SERVING sob o tipo de oferta BATCH_INFERENCE . Veja os custos de visualização para cargas de trabalho de inferência de lotes para um exemplo de consulta.
Para ai_parse_document os custos são registrados como parte do produto AI_FUNCTIONS . Veja os custos de visualização para a execução de ai_parse_document para um exemplo de consulta.
ver custos para cargas de trabalho de inferência de lotes
Os exemplos a seguir mostram como filtrar cargas de trabalho de inferência de lotes com base em Job, compute, SQL Warehouse e pipeline declarativo LakeFlow Spark .
Consulte Monitorar custos do modelo de abastecimento para obter exemplos gerais sobre como view custos para suas cargas de trabalho de inferência de lotes que usam AI Functions.
- Jobs
- Compute
- Lakeflow Spark Declarative Pipelines
- SQL warehouse
A consulta a seguir mostra quais tarefas estão sendo usadas para inferência de lotes usando a tabela de sistemas system.workflow.jobs . Veja Monitorar custos e desempenho do trabalho com tabelas do sistema.
SELECT *
FROM system.billing.usage u
JOIN system.workflow.jobs x
ON u.workspace_id = x.workspace_id
AND u.usage_metadata.job_id = x.job_id
WHERE u.usage_metadata.workspace_id = <workspace_id>
AND u.billing_origin_product = "MODEL_SERVING"
AND u.product_features.model_serving.offering_type = "BATCH_INFERENCE";
A seguir são mostrados quais clusters estão sendo usados para inferência de lotes usando a tabela de sistemas system.compute.clusters .
SELECT *
FROM system.billing.usage u
JOIN system.compute.clusters x
ON u.workspace_id = x.workspace_id
AND u.usage_metadata.cluster_id = x.cluster_id
WHERE u.usage_metadata.workspace_id = <workspace_id>
AND u.billing_origin_product = "MODEL_SERVING"
AND u.product_features.model_serving.offering_type = "BATCH_INFERENCE";
A seguir, são mostrados quais pipelines declarativos LakeFlow Spark estão sendo usados para inferência de lotes usando a tabela de sistemas system.lakeflow.pipelines .
SELECT *
FROM system.billing.usage u
JOIN system.lakeflow.pipelines x
ON u.workspace_id = x.workspace_id
AND u.usage_metadata.dlt_pipeline_id = x.pipeline_id
WHERE u.usage_metadata.workspace_id = <workspace_id>
AND u.billing_origin_product = "MODEL_SERVING"
AND u.product_features.model_serving.offering_type = "BATCH_INFERENCE";
A seguir é mostrado qual warehouse SQL está sendo usado para inferência de lotes usando a tabela de sistemas system.compute.warehouses .
SELECT *
FROM system.billing.usage u
JOIN system.compute.clusters x
ON u.workspace_id = x.workspace_id
AND u.usage_metadata.cluster_id = x.cluster_id
WHERE u.workspace_id = <workspace_id>
AND u.billing_origin_product = "MODEL_SERVING"
AND u.product_features.model_serving.offering_type = "BATCH_INFERENCE";
ver custos para execução de ai_parse_document
O exemplo a seguir mostra como consultar as tabelas do sistema de faturamento para view os custos da execução de ai_parse_document .
SELECT *
FROM system.billing.usage u
WHERE u.workspace_id = <workspace_id>
AND u.billing_origin_product = "AI_FUNCTIONS"
AND u.product_features.ai_functions.ai_function = "AI_PARSE_DOCUMENT";