Conceitos de pipeline declarativoLakeFlow Spark
Aprenda o que é LakeFlow Spark Declarative Pipeline (SDP), os conceitos principais (como pipeline, tabelas de transmissão e visão materializada) que o definem, as relações entre esses conceitos e os benefícios de usá-lo no seu fluxo de trabalho de processamento de dados.
O que é SDP?
Lakeflow Spark Declarative Pipelines é uma estrutura declarativa para desenvolver e executar pipelines de dados em lote e em transmissão em SQL e Python. O Lakeflow SDP estende e é interoperável com o Apache Spark Declarative Pipelines, enquanto é executado no Databricks Runtime otimizado para desempenho, e a API flows do Lakeflow Spark Declarative Pipelines usa a mesma API do DataFrame que o Apache Spark e a transmissão estructurada. Casos de uso comuns para SDP incluem ingestão de dados incremental de fontes como armazenamento em nuvem (incluindo Amazon S3, Azure ADLS Gen2 e Google Cloud Storage) e barramentos de mensagens (como Apache Kafka, Amazon Kinesis, Google Pub/Sub, Azure EventHub e Apache Pulsar), transformações em lote e de transmissão incrementais com operadores com estado e sem estado, e processamento de transmissão em tempo real entre armazenamentos transacionais como barramentos de mensagens e bancos de dados.
Para mais detalhes sobre processamento de dados declarativos, consulte Processamento de dados procedural vs. declarativo no Databricks.
Quais são os benefícios do SDP?
A natureza declarativa do SDP oferece os seguintes benefícios em comparação com o desenvolvimento de processos de dados com as APIs Apache Spark e Spark Transstructurada e sua execução com o Databricks Runtime usando orquestração manual via LakeFlow Jobs.
- Orquestração automática : O SDP orquestra o processamento dos passos (chamados de "fluxos") automaticamente para garantir a ordem correta de execução e o nível máximo de paralelismo para um desempenho ideal. Além disso, o pipeline tenta novamente de forma automática e eficiente em caso de falhas transitórias. O processo de repetição começa com a unidade mais granular e econômica: a tarefa Spark. Se a tentativa de repetição em nível de tarefa falhar, o SDP tenta novamente o fluxo e, se necessário, todo o pipeline.
- Processamento declarativo : O SDP fornece funções declarativas que podem reduzir centenas ou até milhares de linhas de código manual Spark e Transcriptada para apenas algumas linhas. A APISDP AUTO CDC simplifica o processamento de eventos de captura de dados de alterações (CDC) com suporte para SCD Tipo 1 e SCD Tipo 2. Ela elimina a necessidade de código manual para lidar com eventos fora de ordem e não requer conhecimento de semântica de transmissão ou conceitos como marcas d'água.
- Processamento incremental : O SDP fornece um mecanismo de processamento incremental para visões materializadas. Para utilizá-lo, você escreve sua lógica de transformações com semântica de lotes, e o mecanismo processará apenas novos dados e alterações na fonte de dados sempre que possível. O processamento incremental reduz o reprocessamento ineficiente quando novos dados ou alterações ocorrem nas fontes e elimina a necessidade de código manual para lidar com o processamento incremental.
Conceitos-chave
O diagrama abaixo ilustra os conceitos mais importantes do pipeline declarativo LakeFlow Spark .
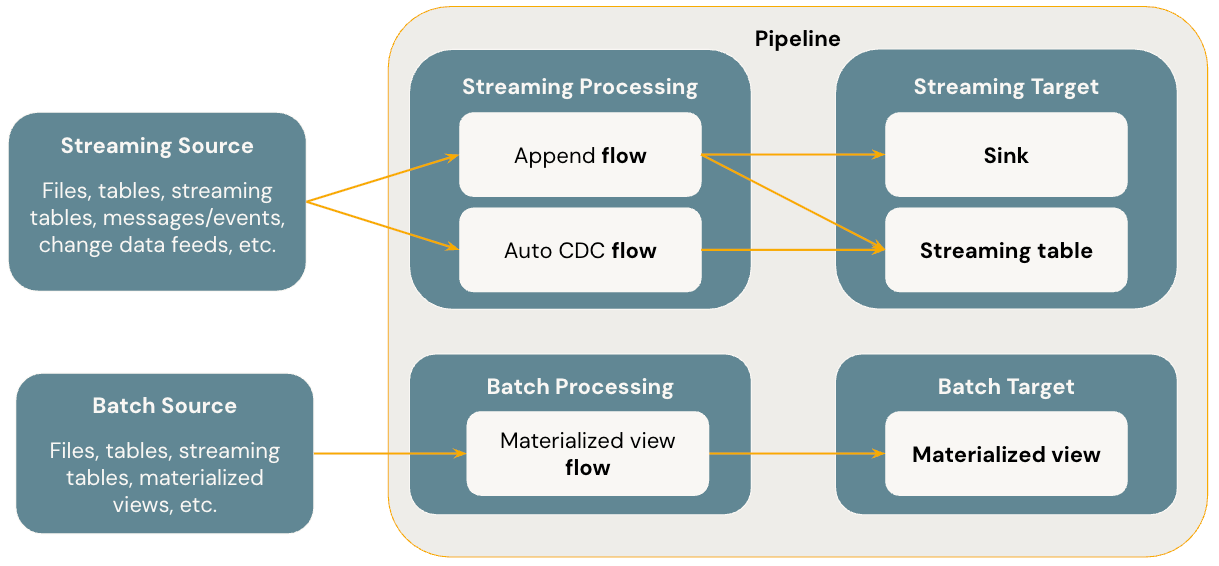
Fluxos
Um fluxo é o conceito fundamental de processamento de dados no SDP que suporta as semânticas de transmissão e de lotes. Um fluxo lê dados de uma fonte, aplica a lógica de processamento definida pelo usuário e grava o resultado em um destino. SDP partilha o mesmo tipo de fluxo de transmissão ( Anexar , Atualizar , Concluir ) que a transmissão estruturada do Spark. (Atualmente, somente os fluxos de Acréscimo e Atualizar estão expostos.) Para mais detalhes, consulte modos de saída em Transmissão Estructurada.
O pipeline declarativo LakeFlow Spark também oferece tipos de fluxo adicionais:
- O Auto CDC é um fluxo de transmissão exclusivo no LakeFlow SDP que lida com eventos CDC fora de ordem e oferece suporte aos tipos SCD 1 e 2. SCD Auto CDC não está disponível no pipeline declarativo Apache Spark .
- viewmaterializada é um fluxo de lotes no SDP que processa apenas novos dados e alterações nas tabelas de origem sempre que possível.
Para mais detalhes, consulte:
tabelas de transmissão
Uma tabela de transmissão é uma forma de tabela de gerenciamento Unity Catalog que também é um alvo de transmissão para LakeFlow SDP. Uma tabela de transmissão pode ter um ou mais fluxos de transmissão ( Append , AUTO CDC ) gravados nela. AUTO CDC é um fluxo de transmissão exclusivo que está disponível apenas para tabelas de transmissão em Databricks. Você pode definir fluxos de transmissão explicitamente e separadamente de sua tabela de transmissão de destino. Você também pode definir fluxos de transmissão implicitamente como parte de uma definição de tabela de transmissão.
Para mais detalhes, consulte:
Visão materializada
Uma viewmaterializada também é uma forma de tabela de gerenciamento Unity Catalog e é um alvo de lotes. Uma view materializada pode ter um ou mais fluxos de view materializada gravados nela. A visualização materializada difere das tabelas de transmissão porque você sempre define os fluxos implicitamente como parte da definição da view materializada.
Para mais detalhes, consulte:
Pias
Um destino é um destino de transmissão para um pipeline e suporta tabelas Delta, tópicos Apache Kafka, tópicos Azure EventHubs e fontes de dados Python personalizadas. Um coletor pode ter um ou mais fluxos de transmissão ( Acréscimo , Atualização ) gravados nele.
Para mais detalhes, consulte:
gasoduto
Um pipeline é a unidade de desenvolvimento e execução em um pipeline declarativo LakeFlow Spark . Um pipeline pode conter um ou mais fluxos, tabelas de transmissão, visões materializadas e destinos. Você utiliza o SDP definindo fluxos, tabelas de transmissão, visões materializadas e destinos no código-fonte do seu pipeline e, em seguida, executando o pipeline. Durante a execução do seu pipeline , ele analisa as dependências dos fluxos definidos, tabelas de transmissão, visualizações materializadas e destinos, e orquestra automaticamente a ordem de execução e paralelização deles.
Para mais detalhes, consulte:
PipelineDatabricks SQL
Tabelas de transmissão e visões materializadas são duas funcionalidades fundamentais do Databricks SQL. Você pode usar SQL padrão para criar e refresh tabelas de transmissão e visualizações materializadas no Databricks SQL. As tabelas de transmissão e as visualizações materializadas no Databricks SQL na mesma infraestrutura Databricks e têm a mesma semântica de processamento que no pipeline declarativo LakeFlow Spark . Ao usar tabelas de transmissão e visualizações materializadas no Databricks SQL, os fluxos são definidos implicitamente como parte da definição das tabelas de transmissão e das visualizações materializadas.
Para mais detalhes, consulte: