O que são Lakeflow Pipelines?
LakeFlow Pipelines fornecem uma estrutura declarativa para criar pipelines de dados em lotes e transmissão em SQL e Python. Seus conceitos centrais são pipelines, fluxos, tabelas de transmissão, visualizações materializadas e coletores, que trabalham juntos para processar dados com orquestração automática e atualizações incrementais.
Lakeflow Pipelines estendem o Apache Spark™ Declarative Pipelines (SDP). Para saber mais sobre SDP e como ele se compara aos LakeFlow Pipelines, consulte Apache Spark Declarative Pipelines.
Quais são os benefícios dos pipelines?
Em contraste com o desenvolvimento de processos de engenharia de dados com as APIs Apache Spark e Spark Structured Streaming no Databricks Runtime usando orquestração manual via Lakeflow Jobs, a natureza declarativa dos pipelines oferece os seguintes benefícios:
- orquestração automática : os pipelines executam os passos de processamento (chamados "flows") na ordem correta com paralelismo máximo e tentam novamente falhas transitórias de forma progressiva — da tarefa do Spark ao flow, até o pipeline inteiro.
- Processamento declarativo : Funções declarativas reduzem centenas de linhas de código manual do Spark e do Structured Streaming para poucas. A API AUTO CDC lida com eventos de Captura de Dados de Alterações (CDC) — incluindo SCD Tipo 1 e Tipo 2 — sem código manual para eventos fora de ordem ou conceitos de transmissão como marcas d'água.
- Processamento incremental : Um mecanismo de processamento incremental mantém as view materializadas atualizadas: escreve-se a lógica de transformação com semântica de lotes, e o mecanismo reprocessa apenas dados de origem novos ou alterados quando possível.
Conceitos fundamentais
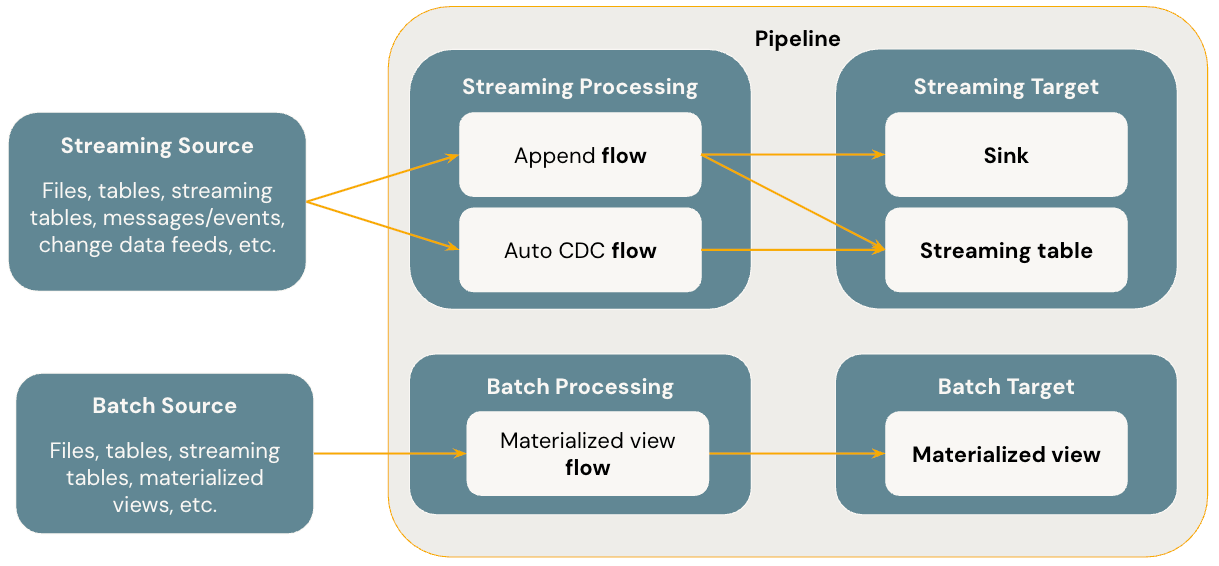
O diagrama abaixo ilustra os conceitos mais importantes de pipelines.
dataset
Um pipeline produz três tipos de conjuntos de dados, cada um com semântica de processamento diferente:
Tipo de dataset | Como os registros são processados |
|---|---|
Tabela de transmissão | Cada registro é processado exatamente uma vez, pressupondo uma origem somente de acréscimo. As tabelas de transmissão são adequadas para a ingestão e o processamento incremental de dados em crescimento contínuo. |
Visualização materializada | Os resultados são recalculados conforme necessário para refletir o estado atual dos dados. As visualizações materializadas são adequadas para transformações, agregações ou pré-computação de resultados consumidos por múltiplos conjuntos de dados subsequentes. |
View | Avaliado sob demanda, não persistido. Utilize modos de exibição para transformações intermediárias e verificações que não precisam ser publicadas em um catálogo. |
Uma tabela de streaming é um tipo de tabela gerenciada pelo Unity Catalog que também funciona como um destino de streaming. Uma tabela de transmissão pode ter um ou mais fluxos de transmissão ( Append , AUTO CDC ) gravados nela. É possível definir fluxos de transmissão explicitamente e separadamente de sua tabela de transmissão de destino, ou implicitamente como parte de uma definição de tabela de transmissão.
Uma materialized view é também uma forma de tabela gerenciada do Unity Catalog e é um destino em lote. Uma visualização materializada pode ter um ou mais fluxos de visualização materializada escritos nela. Materialized views diferem das tabelas de transmissão porque os fluxos são sempre definidos implicitamente como parte da definição da materialized view.
Para detalhes, consulte Tabelas de transmissão e views materializadas.
Quando usar visualizações, visualizações materializadas e tabelas de transmissão em fluxo
Ao implementar consultas em pipeline, escolha o tipo de dataset que melhor se adapta ao seu caso de uso.
Considere usar uma view para:
- Dividir uma query grande ou complexa em queries mais fáceis de gerenciar.
- Validar resultados intermediários usando expectativas.
- Reduzir custos de armazenamento e compute para resultados que não precisam ser persistidos. Como as tabelas são materializadas, elas exigem recursos adicionais de computação e armazenamento.
Considere usar uma visualização materializada quando:
- Várias consultas downstream consomem a tabela. Como uma view materializada armazena seus resultados em cache, consultas subsequentes leem os resultados pré-computados em vez de recalcular a consulta a cada acesso.
- Outros pipelines, Jobs ou consultas consomem a tabela. Como uma view materializada é materializada em uma tabela do Unity Catalog, consumidores fora do pipeline que a define podem consultá-la. As visualizações não são materializadas, portanto, elas só podem ser usadas no mesmo pipeline.
- É desejável inspecionar os resultados de uma query durante o desenvolvimento. Como uma view materializada é materializada e pode ser consultada fora do pipeline, é possível validar a correção dos cálculos durante o desenvolvimento. Após validar, converta queries que não exigem materialização em views.
- Sua consulta realiza agregações ou join, ou os dados de origem podem mudar devido a atualizações e exclusões em vez de apenas crescer. Uma view materializada mantém seus resultados consistentes com o estado atual dos dados de origem, enquanto uma tabela de transmissão é projetada para fontes somente de anexação e processa cada registro uma única vez.
Considere usar uma tabela de transmissão quando:
- Uma consulta é definida em uma fonte de dados que está crescendo contínua ou incrementalmente.
- Resultados de query devem ser computados de forma incremental.
- O pipeline precisa de alta taxa de transferência e baixa latência.
Tabelas de transmissão são sempre definidas contra fontes de transmissão. É possível usar fontes de transmissão com AUTO CDC ... INTO para aplicar atualizações de feeds CDC. Consulte As APIs AUTO de CDC: Simplifique a captura de dados de alterações (CDC) com pipelines.
Fluxos
Um fluxo é o conceito fundamental de processamento de dados em pipelines, e suporta semântica de transmissão e de lotes. Um fluxo lê dados de uma origem, aplica lógica de processamento definida pelo usuário e grava o resultado em um destino. Pipelines compartilham o mesmo tipo de fluxo de transmissão ( Append , Update , Complete ) que o Spark Structured Streaming. (Atualmente, apenas os fluxos Append e Update são expostos.) Para mais detalhes, consulte modos de saída em Structured Streaming.
Pipelines também fornecem tipos de fluxo adicionais:
- O AUTO CDC é um fluxo de transmissão exclusivo em LakeFlow Pipelines que lida com eventos CDC fora de ordem e oferece suporte a SCD Tipo 1 e SCD Tipo 2. O Auto CDC não está disponível no SDP.
- A *Materialized view* é um fluxo em lotes em pipelines que processa apenas novos dados e alterações nas tabelas de origem sempre que possível.
Para obter detalhes, consulte Carregue e processe dados incrementalmente com LakeFlow Pipelines.
Pias
Um *destino* é um alvo de transmissão para um pipeline e oferece suporte a tabelas Delta, tópicos do Apache Kafka, tópicos do Azure EventHubs e fontes de dados Python personalizadas. Um coletor pode ter um ou mais fluxos de transmissão (Acréscimo, Atualização) gravadosnele.
Para obter detalhes, consulte Sinks em LakeFlow Pipelines.
pipeline
Um pipeline é a unidade de desenvolvimento e execução, e é o contêiner para os fluxos, tabelas de transmissão, visualizações materializadas e coletores que você define. Você cria um pipeline definindo esses objetos no código-fonte do seu pipeline e depois executando o pipeline. Enquanto seu pipeline é executado, ele analisa as dependências dos objetos definidos e orquestra automaticamente a ordem de execução e paralelização.
Para obter detalhes, consulte O que são pipelines?.
Você também pode definir views materializadas e tabelas de transmissão independentes fora de um Lakeflow pipeline, onde o Databricks gerencia o pipeline para você. Para comparar as duas abordagens, consulte Pipelines independentes vs. Lakeflow pipelines.
ingestão de dados
Os pipelines suportam todas as fontes de dados disponíveis no Databricks. O Databricks recomenda o uso de tabelas de transmissão para a maioria dos casos de uso de ingestão. Para arquivos que chegam ao armazenamento de objetos na nuvem, o Auto Loader oferece carregamento incremental e idempotente. Para dados de transmissão, pipelines podem ingerir diretamente de barramentos de mensagens, como Apache Kafka, Azure Event Hubs, Amazon Kinesis e Google Pub/Sub. Consulte Carregar dados em pipelines.
Qualidade dos dados
Expectativas são cláusulas opcionais em datasets que validam dados à medida que fluem pelo pipeline. Você define uma expectativa como uma restrição Boolean SQL e especifica o que acontece quando um registro falha: avisar, descartar o registro ou falhar a atualização. Consulte Gerenciar a Qualidade dos Dados com Expectativas de Pipeline.
Integração do Delta
Todas as tabelas criadas e gerenciadas por pipelines são tabelas Delta. Eles possuem as mesmas garantias que o Delta Lake, incluindo transações ACID, viagem do tempo e imposição de esquema. Pipelines adicionam propriedades de tabela adicionais e realizam manutenção automática usando otimização preditiva, incluindo OPTIMIZE e VACUUM operações. Consulte O que é o Delta Lake no Databricks?.