Tutorial: Crie vários fluxos com parâmetros diferentes
Um pipeline pode conter vários fluxos que são quase idênticos, diferindo apenas em alguns parâmetros. Definir esses fluxos explicitamente é propenso a erros, redundante e difícil de manter. Metaprogramação com funções internas do Python gera fluxos repetitivos dinamicamente, com cada invocação fornecendo um conjunto diferente de parâmetros.
Metaprogramação: visão geral
A metaprogramação em LakeFlow Pipelines usa funções internas do Python. Como essas funções são avaliadas de forma preguiçosa pelo runtime do pipeline, é possível agrupar os decoradores @dp.table dentro de uma função de fábrica e chamar essa fábrica várias vezes com argumentos diferentes. Cada chamada registra um novo fluxo sem duplicar o código.
Para detalhes sobre o uso de for loops com LakeFlow Pipelines, consulte Criar tabelas em um loop for.
Exemplo: tempos de resposta do corpo de bombeiros
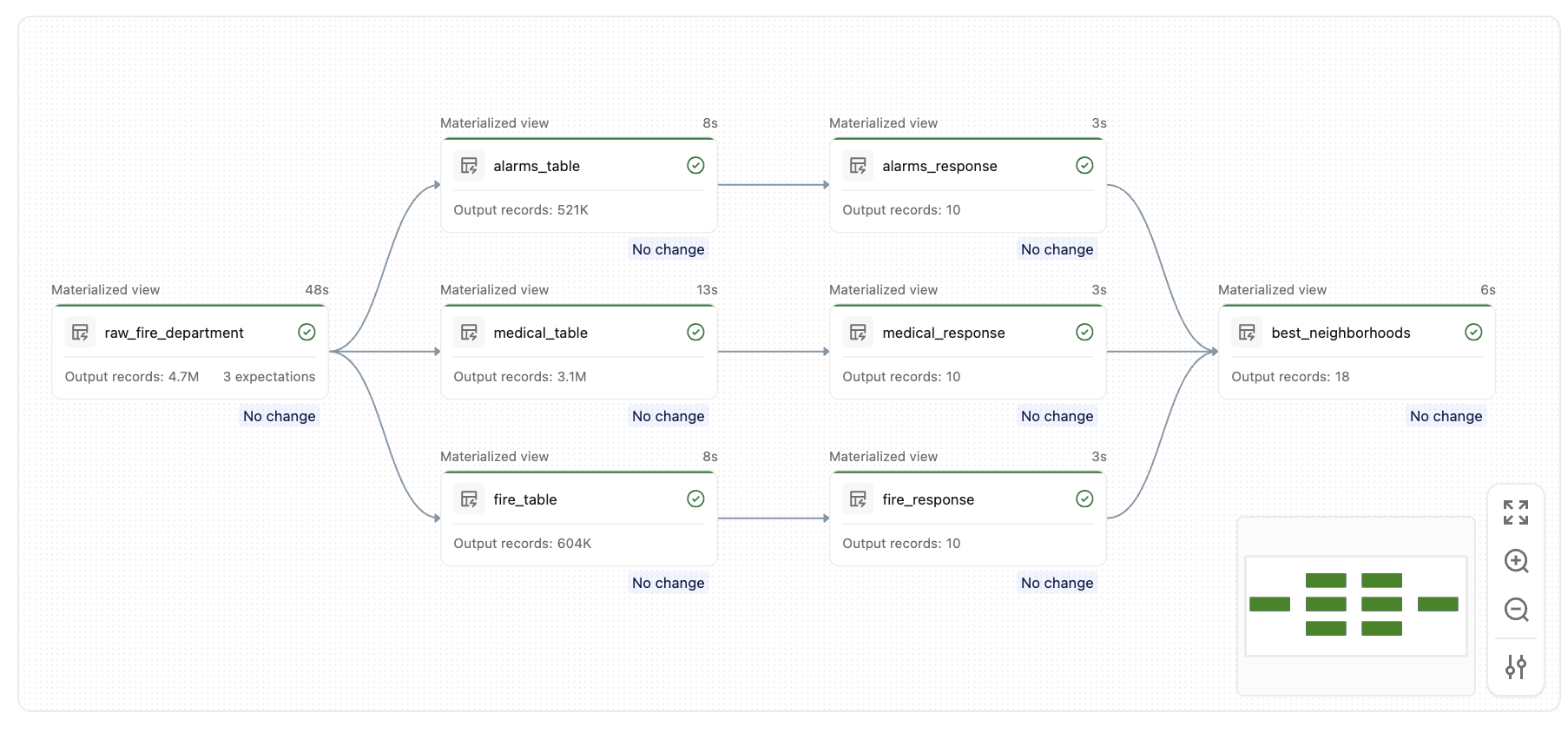
O exemplo a seguir utiliza o dataset integrados do corpo de bombeiros para encontrar os bairros com os tempos de resposta de emergência mais rápidos para cada tipo de chamada. Sem metaprogramação, você precisa escrever definições de tabela quase idênticas para cada tipo de chamada (Alarmes, Incêndio Estrutural, Incidente Médico). Com a metaprogramação, uma única função de fábrica gera todas elas.
o passo 1: Defina a tabela de ingestão bruta
import functools
from pyspark import pipelines as dp
from pyspark.sql.functions import *
@dp.table(
name="raw_fire_department",
comment="raw table for fire department response"
)
@dp.expect_or_drop("valid_received", "received IS NOT NULL")
@dp.expect_or_drop("valid_response", "responded IS NOT NULL")
@dp.expect_or_drop("valid_neighborhood", "neighborhood != 'None'")
def get_raw_fire_department():
return (
spark.read.format('csv')
.option('header', 'true')
.option('multiline', 'true')
.load('/databricks-datasets/timeseries/Fires/Fire_Department_Calls_for_Service.csv')
.withColumnRenamed('Call Type', 'call_type')
.withColumnRenamed('Received DtTm', 'received')
.withColumnRenamed('Response DtTm', 'responded')
.withColumnRenamed('Neighborhooods - Analysis Boundaries', 'neighborhood')
.select('call_type', 'received', 'responded', 'neighborhood')
)
o passo 2: Defina a função da fábrica de fluxo
A função de fábrica generate_tables registra duas tabelas para cada tipo de chamada: uma tabela de chamadas filtradas e uma tabela de tempo de resposta classificada. Ambas são criadas como funções internas decoradas com @dp.table.
all_tables = []
def generate_tables(call_table, response_table, filter):
@dp.table(
name=call_table,
comment="top level tables by call type"
)
def create_call_table():
return spark.sql("""
SELECT
unix_timestamp(received,'M/d/yyyy h:m:s a') as ts_received,
unix_timestamp(responded,'M/d/yyyy h:m:s a') as ts_responded,
neighborhood
FROM raw_fire_department
WHERE call_type = '{filter}'
""".format(filter=filter))
@dp.table(
name=response_table,
comment="top 10 neighborhoods with fastest response time"
)
def create_response_table():
return spark.sql("""
SELECT
neighborhood,
AVG((ts_received - ts_responded)) as response_time
FROM {call_table}
GROUP BY 1
ORDER BY response_time
LIMIT 10
""".format(call_table=call_table))
all_tables.append(response_table)
Passo 3: Invoque a fábrica e defina a tabela de resumo.
Chame a fábrica uma vez para cada tipo de chamada e, em seguida, defina uma tabela de resumo que una os resultados para encontrar os bairros que aparecem com mais frequência em todas as categorias.
generate_tables("alarms_table", "alarms_response", "Alarms")
generate_tables("fire_table", "fire_response", "Structure Fire")
generate_tables("medical_table", "medical_response", "Medical Incident")
@dp.table(
name="best_neighborhoods",
comment="which neighbor appears in the best response time list the most"
)
def summary():
target_tables = [dp.read(t) for t in all_tables]
unioned = functools.reduce(lambda x, y: x.union(y), target_tables)
return (
unioned.groupBy(col("neighborhood"))
.agg(count("*").alias("score"))
.orderBy(desc("score"))
)
Depois que você executar este pipeline, você cria um conjunto de tabelas semelhantes, como este gráfico:
conceitos-chave
- As funções internas são registradas preguiçosamente : o decorador
@dp.tablenão executa a função imediatamente. Ele registra a função com o ambiente de execução pipeline , que resolve o diagrama completo do fluxo de dados antes do início da execução. - Closures capturam parâmetros : Cada função interna fecha sobre os parâmetros passados para a fábrica (
call_table,response_table,filter), então cada fluxo registrado usa seu próprio conjunto isolado de valores. - Listas de tabelas dinâmicas : Usar uma lista como
all_tablespara rastrear nomes de tabelas gerados programaticamente torna fácil referenciá-los posteriormente (por exemplo, em uma união ou join).