Recomendações de expectativas e padrões avançados
Padrões de expectativa avançados combinam expectativas em múltiplos datasets para impor a qualidade dos dados em escala. Esses padrões pressupõem que você entenda a sintaxe e a semântica de views materializadas, tabelas de transmissão e expectativas.
Para uma visão geral básica do comportamento e da sintaxe das expectativas, consulte gerenciar a qualidade dos dados com expectativas pipeline.
Expectativas portáteis e reutilizáveis
A Databricks recomenda as seguintes práticas recomendadas ao implementar expectativas para melhorar a portabilidade e reduzir os encargos de manutenção:
Recomendação | Impacto |
|---|---|
Armazene as definições de expectativa separadamente da lógica do pipeline. | Aplique facilmente expectativas a vários conjuntos de dados ou pipelines. Atualize, audite e mantenha expectativas sem modificar o código-fonte do pipeline. |
Adicione tags personalizadas para criar grupos de expectativas relacionadas. | Filtre expectativas com base em tags. |
Aplique expectativas de forma consistente em conjuntos de dados semelhantes. | Use as mesmas expectativas em vários conjuntos de dados e pipelines para avaliar lógica idêntica. |
Os exemplos a seguir demonstram o uso de uma tabela ou dicionário Delta para criar um repositório central de expectativas. As funções Python personalizadas então aplicam essas expectativas ao conjunto de dados em um pipeline de exemplo:
O carregamento dinâmico de expectativas de um arquivo não é compatível em SQL.
- Delta Table
- Python Module
O exemplo seguinte cria uma tabela denominada rules para manter as regras:
CREATE OR REPLACE TABLE
rules
AS SELECT
col1 AS name,
col2 AS constraint,
col3 AS tag
FROM (
VALUES
("website_not_null","Website IS NOT NULL","validity"),
("fresh_data","to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'","maintained"),
("social_media_access","NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)","maintained")
)
O exemplo Python a seguir define expectativas de qualidade de dados com base nas regras na tabela rules . A função get_rules() lê as regras da tabela rules e retorna um dicionário Python contendo regras correspondentes ao argumento tag passado para a função.
Neste exemplo, o dicionário é aplicado usando decoradores @dp.expect_all_or_drop() para impor restrições de qualidade de dados.
Por exemplo, todos os registros que falharem nas regras marcadas com validity serão retirados da raw_farmers_market tabela:
from pyspark import pipelines as dp
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
df = spark.read.table("rules").filter(col("tag") == tag).collect()
return {
row['name']: row['constraint']
for row in df
}
@dp.table
@dp.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dp.table
@dp.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
spark.read.table("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
O exemplo a seguir cria um módulo Python para manter regras. Para este exemplo, armazene este código em um arquivo chamado rules_module.py na mesma pasta do Notebook usado como código-fonte para o pipeline:
def get_rules_as_list_of_dict():
return [
{
"name": "website_not_null",
"constraint": "Website IS NOT NULL",
"tag": "validity"
},
{
"name": "fresh_data",
"constraint": "to_date(updateTime,'M/d/yyyy h:m:s a') > '2010-01-01'",
"tag": "maintained"
},
{
"name": "social_media_access",
"constraint": "NOT(Facebook IS NULL AND Twitter IS NULL AND Youtube IS NULL)",
"tag": "maintained"
}
]
O exemplo Python a seguir define expectativas de qualidade de dados com base nas regras definidas no arquivo rules_module.py . A função get_rules() retorna um dicionário Python contendo regras correspondentes ao argumento tag passado a ele.
Neste exemplo, o dicionário é aplicado usando decoradores @dp.expect_all_or_drop() para impor restrições de qualidade de dados.
Por exemplo, todos os registros que falharem nas regras marcadas com validity serão retirados da raw_farmers_market tabela:
from pyspark import pipelines as dp
from rules_module import *
from pyspark.sql.functions import expr, col
def get_rules(tag):
"""
loads data quality rules from a table
:param tag: tag to match
:return: dictionary of rules that matched the tag
"""
return {
row['name']: row['constraint']
for row in get_rules_as_list_of_dict()
if row['tag'] == tag
}
@dp.table
@dp.expect_all_or_drop(get_rules('validity'))
def raw_farmers_market():
return (
spark.read.format('csv').option("header", "true")
.load('/databricks-datasets/data.gov/farmers_markets_geographic_data/data-001/')
)
@dp.table
@dp.expect_all_or_drop(get_rules('maintained'))
def organic_farmers_market():
return (
spark.read.table("raw_farmers_market")
.filter(expr("Organic = 'Y'"))
)
Tabelas de validação e fluxo de controle de pipeline
Alguns padrões nesta seção, como validação de contagem de linhas e unicidade de chave primária, definem um dataset separado, uma tabela de validação , que verifica uma propriedade em outras tabelas e usa expect_or_fail para evidenciar problemas. Antes de confiar em uma tabela de validação para controlar um pipeline, entenda o que as expectativas podem e não podem controlar:
- As expectativas aplicam a qualidade dos dados, não a orquestração. Em um pipeline, as expectativas determinam quais registros alcançam um dataset de destino:
warnmantém registros inválidos e registra métricas,dropos remove efailinterrompe o fluxo ofensivo. O objetivo é garantir que apenas limpeza de dados flua, e não executar ou ignorar condicionalmente outras partes do pipeline. - O comportamento de
expect_or_faildepende do modo de execução do pipeline. Em um pipeline com Trigger, uma expectativa com falha falha e reverte apenas a atualização desse fluxo; outros fluxos no mesmo pipeline continuam a ser atualizados independentemente. Em um pipeline contínuo, uma expectativa com falha interrompe o fluxo e todos os fluxos dependentes. Consulte Falha em registros inválidos. - Uma tabela de validação não restringe suas tabelas downstream. Ler uma tabela de validação de outro dataset não faz com que esse dataset aguarde o resultado da validação, portanto, uma validação com falha não impede que as tabelas downstream sejam atualizadas.
Para interromper o processamento downstream quando uma validação falha, divida a lógica de validação e o trabalho downstream em pipelines separados e orquestre-os com um Job, fazendo com que a tarefa do pipeline downstream dependa da tarefa do pipeline de validação. Como uma tarefa de pipeline falha quando sua atualização falha, a tarefa downstream não é executada a menos que o pipeline de validação seja bem-sucedido. De modo mais geral, quando você precisa de execução condicional ou dependências complexas, coordene múltiplos pipelines com um Job em vez de integrar a lógica em um único pipeline. Consulte Executar pipelines em um fluxo de trabalho.
Validação de contagem de linhas
O exemplo a seguir valida a igualdade da contagem de linhas entre table_a e table_b para verificar se nenhum dado é perdido durante as transformações:
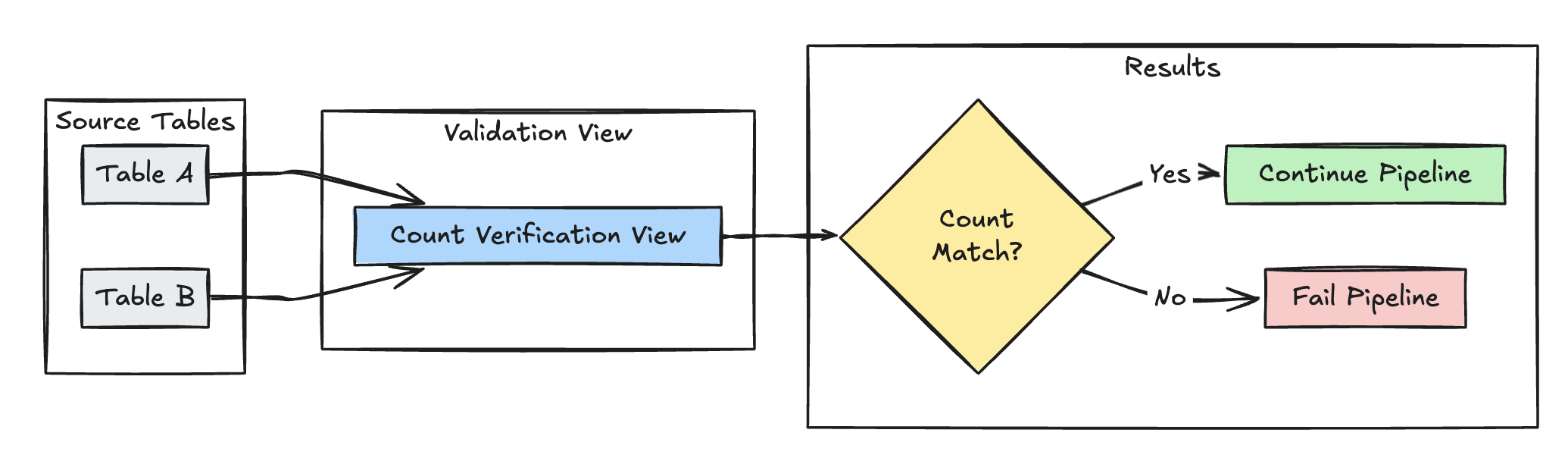
- Python
- SQL
@dp.materialized_view(
name="count_verification",
comment="Validates equal row counts between tables"
)
@dp.expect_or_fail("no_rows_dropped", "a_count == b_count")
def validate_row_counts():
return spark.sql("""
SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)""")
CREATE OR REFRESH MATERIALIZED VIEW count_verification(
CONSTRAINT no_rows_dropped EXPECT (a_count == b_count)
) AS SELECT * FROM
(SELECT COUNT(*) AS a_count FROM table_a),
(SELECT COUNT(*) AS b_count FROM table_b)
Detecção de registro ausente
O seguinte exemplo valida que todos os registros esperados estão presentes na tabela report:
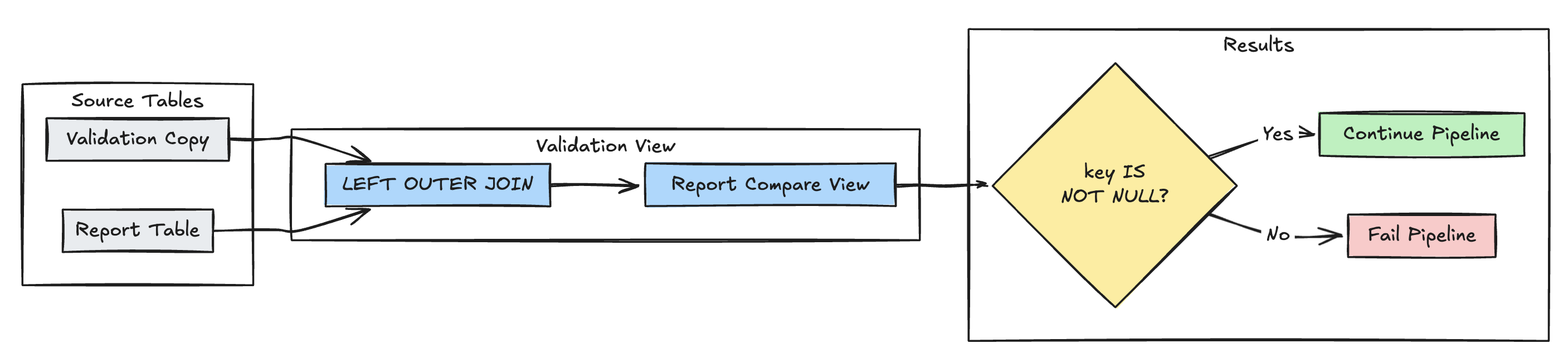
- Python
- SQL
@dp.materialized_view(
name="report_compare_tests",
comment="Validates no records are missing after joining"
)
@dp.expect_or_fail("no_missing_records", "r_key IS NOT NULL")
def validate_report_completeness():
return (
spark.read.table("validation_copy").alias("v")
.join(
spark.read.table("report").alias("r"),
on="key",
how="left_outer"
)
.select(
"v.*",
"r.key as r_key"
)
)
CREATE OR REFRESH MATERIALIZED VIEW report_compare_tests(
CONSTRAINT no_missing_records EXPECT (r_key IS NOT NULL)
)
AS SELECT v.*, r.key as r_key FROM validation_copy v
LEFT OUTER JOIN report r ON v.key = r.key
Unicidade key primária
O exemplo a seguir valida restrições key primária em todas as tabelas:
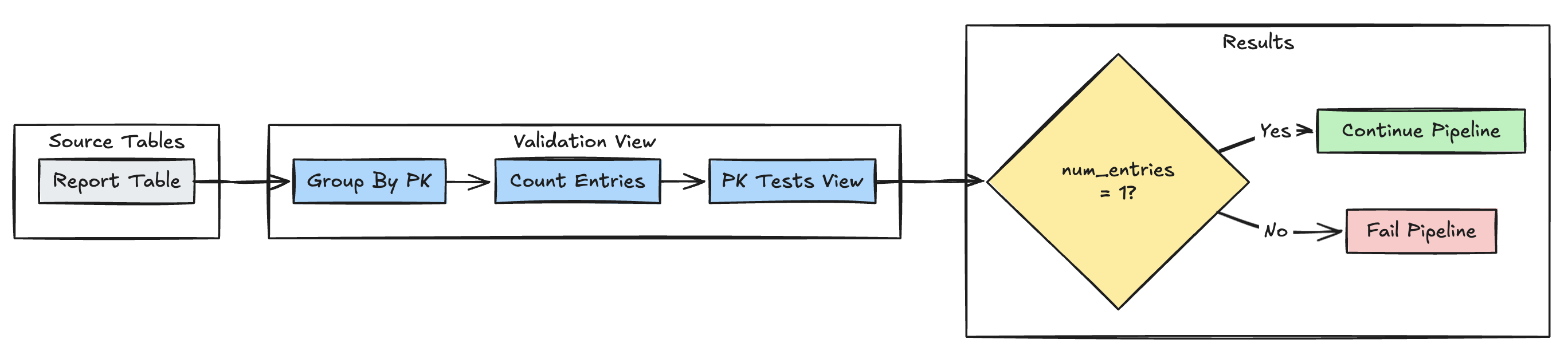
- Python
- SQL
@dp.materialized_view(
name="report_pk_tests",
comment="Validates primary key uniqueness"
)
@dp.expect_or_fail("unique_pk", "num_entries = 1")
def validate_pk_uniqueness():
return (
spark.read.table("report")
.groupBy("pk")
.count()
.withColumnRenamed("count", "num_entries")
)
CREATE OR REFRESH MATERIALIZED VIEW report_pk_tests(
CONSTRAINT unique_pk EXPECT (num_entries = 1)
)
AS SELECT pk, count(*) as num_entries
FROM report
GROUP BY pk
Padrão de evolução do esquema
O exemplo a seguir mostra como lidar com a evolução do esquema para colunas adicionais. Use este padrão ao migrar fonte de dados ou manipular múltiplas versões de dados upstream, garantindo compatibilidade com versões anteriores e reforçando a qualidade dos dados:
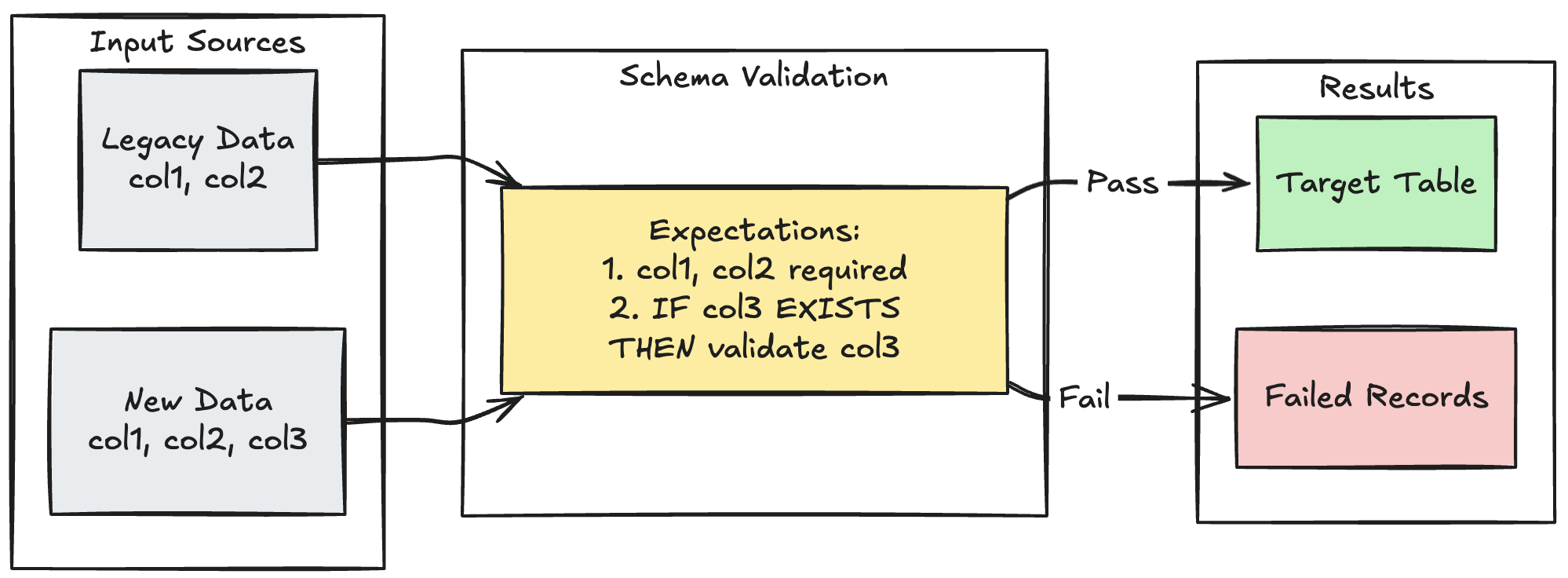
- Python
- SQL
@dp.table
@dp.expect_all_or_fail({
"required_columns": "col1 IS NOT NULL AND col2 IS NOT NULL",
"valid_col3": "CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END"
})
def evolving_table():
# Legacy data (V1 schema)
legacy_data = spark.read.table("legacy_source")
# New data (V2 schema)
new_data = spark.read.table("new_source")
# Combine both sources
return legacy_data.unionByName(new_data, allowMissingColumns=True)
CREATE OR REFRESH MATERIALIZED VIEW evolving_table(
-- Merging multiple constraints into one as expect_all is Python-specific API
CONSTRAINT valid_migrated_data EXPECT (
(col1 IS NOT NULL AND col2 IS NOT NULL) AND (CASE WHEN col3 IS NOT NULL THEN col3 > 0 ELSE TRUE END)
) ON VIOLATION FAIL UPDATE
) AS
SELECT * FROM new_source
UNION
SELECT *, NULL as col3 FROM legacy_source;
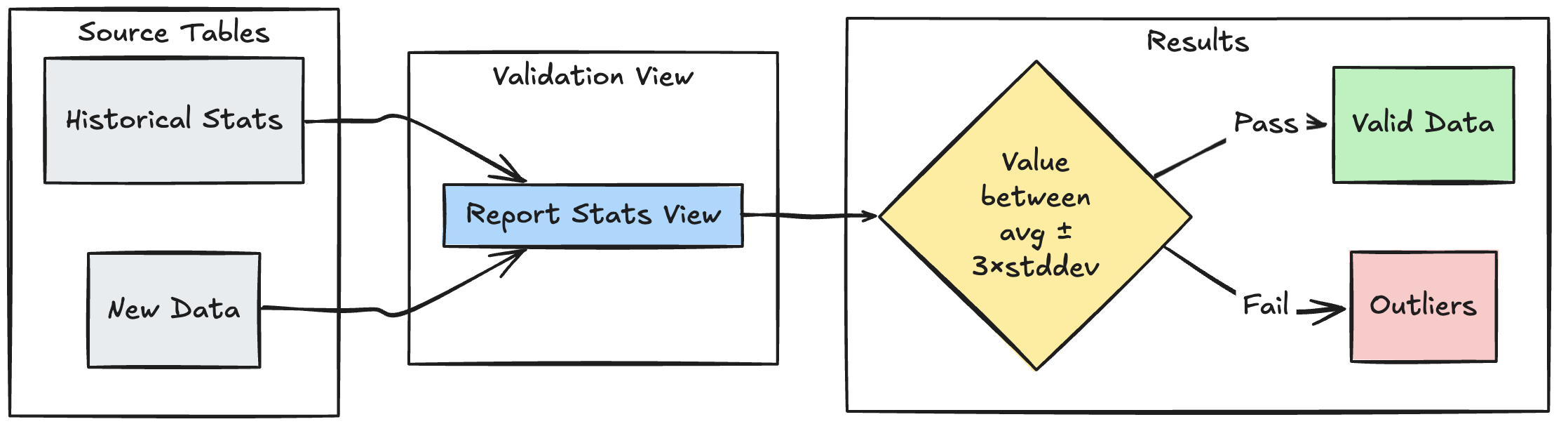
Padrão de validação baseado em intervalo
O exemplo a seguir demonstra como validar novos pontos de dados em relação a intervalos estatísticos históricos, ajudando a identificar discrepâncias e anomalias no seu fluxo de dados:
- Python
- SQL
@dp.view
def stats_validation_view():
# Calculate statistical bounds from historical data
bounds = spark.sql("""
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE
date >= CURRENT_DATE() - INTERVAL 30 DAYS
""")
# Join with new data and apply bounds
return spark.read.table("new_data").crossJoin(bounds)
@dp.table
@dp.expect_or_drop(
"within_statistical_range",
"amount BETWEEN lower_bound AND upper_bound"
)
def validated_amounts():
return spark.read.table("stats_validation_view")
CREATE OR REFRESH MATERIALIZED VIEW stats_validation_view AS
WITH bounds AS (
SELECT
avg(amount) - 3 * stddev(amount) as lower_bound,
avg(amount) + 3 * stddev(amount) as upper_bound
FROM historical_stats
WHERE date >= CURRENT_DATE() - INTERVAL 30 DAYS
)
SELECT
new_data.*,
bounds.*
FROM new_data
CROSS JOIN bounds;
CREATE OR REFRESH MATERIALIZED VIEW validated_amounts (
CONSTRAINT within_statistical_range EXPECT (amount BETWEEN lower_bound AND upper_bound)
)
AS SELECT * FROM stats_validation_view;
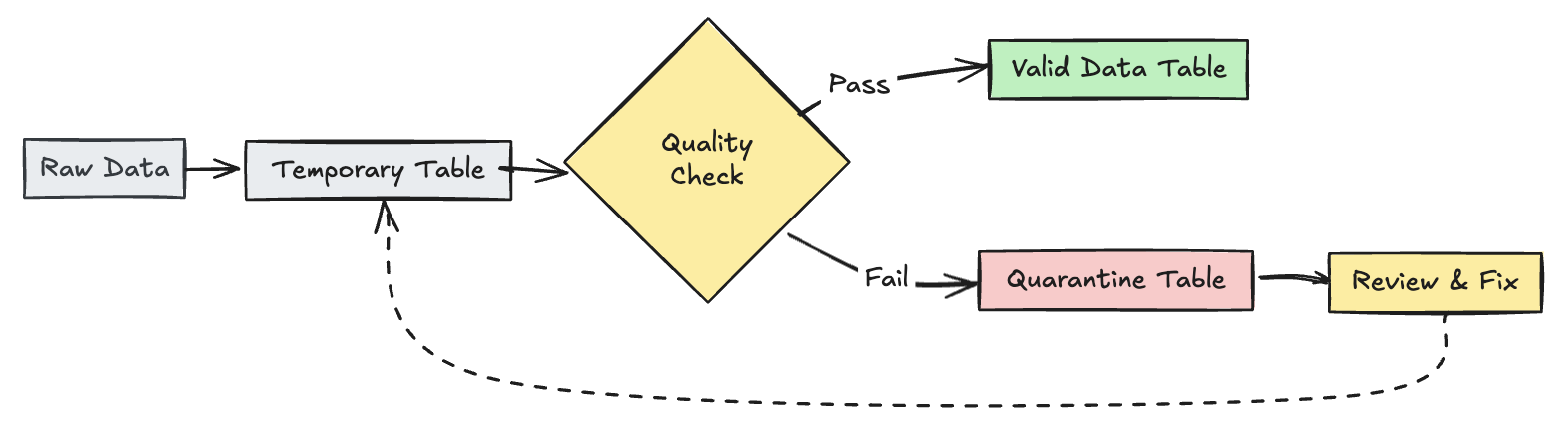
Colocar em quarentena registros inválidos
Esse padrão combina expectativas com tabelas temporárias e visualizações para rastrear métricas de qualidade de dados durante atualizações pipeline e permitir caminhos de processamento separados para registros válidos e inválidos em operações posteriores.
- Python
- SQL
from pyspark import pipelines as dp
from pyspark.sql.functions import expr
rules = {
"valid_pickup_zip": "(pickup_zip IS NOT NULL)",
"valid_dropoff_zip": "(dropoff_zip IS NOT NULL)",
}
quarantine_rules = "NOT({0})".format(" AND ".join(rules.values()))
@dp.view
def raw_trips_data():
return spark.readStream.table("samples.nyctaxi.trips")
@dp.table(
temporary=True,
partition_cols=["is_quarantined"],
)
@dp.expect_all(rules)
def trips_data_quarantine():
return (
spark.readStream.table("raw_trips_data").withColumn("is_quarantined", expr(quarantine_rules))
)
@dp.view
def valid_trips_data():
return spark.read.table("trips_data_quarantine").filter("is_quarantined=false")
@dp.view
def invalid_trips_data():
return spark.read.table("trips_data_quarantine").filter("is_quarantined=true")
CREATE TEMPORARY STREAMING LIVE VIEW raw_trips_data AS
SELECT * FROM STREAM(samples.nyctaxi.trips);
CREATE OR REFRESH TEMPORARY STREAMING TABLE trips_data_quarantine(
-- Option 1 - merge all expectations to have a single name in the pipeline event log
CONSTRAINT quarantined_row EXPECT (pickup_zip IS NOT NULL OR dropoff_zip IS NOT NULL),
-- Option 2 - Keep the expectations separate, resulting in multiple entries under different names
CONSTRAINT invalid_pickup_zip EXPECT (pickup_zip IS NOT NULL),
CONSTRAINT invalid_dropoff_zip EXPECT (dropoff_zip IS NOT NULL)
)
PARTITIONED BY (is_quarantined)
AS
SELECT
*,
NOT ((pickup_zip IS NOT NULL) and (dropoff_zip IS NOT NULL)) as is_quarantined
FROM STREAM(raw_trips_data);
CREATE TEMPORARY LIVE VIEW valid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=FALSE;
CREATE TEMPORARY LIVE VIEW invalid_trips_data AS
SELECT * FROM trips_data_quarantine WHERE is_quarantined=TRUE;