Recuperar um pipeline de falha no ponto de verificação de transmissão
Recuperar um pipeline do LakeFlow quando um ponto de verificação de transmissão se torna inválido ou corrompido, usando um refresh completo, backup e preenchimento retroativo, ou um reset seletivo de ponto de verificação.
O que é um posto de controle de transmissão?
No Apache Spark transmissão estruturada, um checkpoint é um mecanismo usado para persistir o estado de uma consulta de transmissão. Este estado inclui:
- Informações de progresso : quais compensações da fonte foram processadas.
- Estado intermediário : dados que precisam ser mantidos em microlotes para operações com estado (por exemplo, agregações,
mapGroupsWithState). - Metadados : informação sobre a execução da consulta de transmissão.
Os pontos de verificação são essenciais para garantir tolerância a falhas e consistência de dados em aplicações de transmissão:
- Tolerância a falhas : se um aplicativo de transmissão falhar (por exemplo, devido a uma falha de nó, travamento do aplicativo), o ponto de verificação permite que o aplicativo reinicie a partir do último estado de ponto de verificação bem-sucedido, em vez de reprocessar todos os dados desde o início. Isso evita a perda de dados e garante o processamento incremental.
- Processamento exatamente uma vez : para muitas fontes de transmissão, os pontos de verificação, em conjunto com coletores idempotentes, permitem o processamento exatamente uma vez, o que garante que cada registro seja processado exatamente uma vez, mesmo diante de falhas, evitando duplicatas ou omissões.
- Gerenciamento de estado : para transformações com estado, os pontos de verificação persistem o estado interno dessas operações, permitindo que a consulta de transmissão continue processando corretamente novos dados com base no estado histórico acumulado.
pontos de verificação do oleoduto
Pipelines se baseiam na transmissão estructurada e abstraem grande parte do gerenciamento de pontos de verificação subjacente, oferecendo uma abordagem declarativa. Ao definir uma tabela de transmissão em seu pipeline, existe um estado de ponto de verificação para cada fluxo que grava na tabela de transmissão. Esses locais de ponto de verificação são internos ao pipeline e não são acessíveis aos usuários.
Normalmente, você não precisa gerenciar ou entender os pontos de verificação subjacentes às tabelas de transmissão, exceto nos seguintes casos:
- Retroceder e reproduzir : se você quiser reprocessar os dados de um ponto específico no tempo, preservando o estado atual da tabela, você deve redefinir o ponto de verificação da tabela de transmissão.
- Recuperando-se de uma falha ou corrupção de ponto de verificação : se uma consulta gravada na tabela de transmissão falhar devido a erros relacionados ao ponto de verificação, isso causará uma falha grave e a consulta não poderá prosseguir. Há três abordagens que você pode usar para se recuperar dessa classe de falha:
- refreshcompleta da tabela : isso redefine a tabela e apaga os dados existentes.
- refresh completa da tabela com backup e preenchimento : faça um backup da tabela antes de executar uma refresh completa da tabela e preencher os dados antigos, mas isso é muito caro e deve ser o último recurso.
- Reset ponto de verificação e continuar incrementalmente : se você não puder perder dados existentes, deverá executar uma redefinição seletiva de ponto de verificação para os fluxos de transmissão afetados.
Exemplo: Falha de pipeline devido a alteração de código
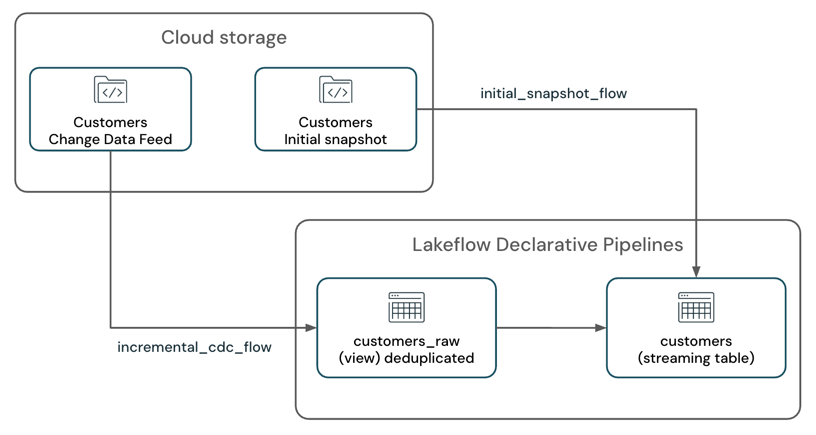
Considere um cenário em que você tem um pipeline que processa um fluxo de dados de alterações juntamente com o snapshot inicial da tabela a partir de um sistema de armazenamento cloud , como Amazon S3, e grava em uma tabela de transmissão SCD-1.
O pipeline possui dois fluxos de transmissão:
customers_incremental_flow: Lê incrementalmente o feed CDC da tabela de origemcustomer, filtra registros duplicados e os insere na tabela de destino.customers_snapshot_flow: Lê uma vez o Snapshot inicial da tabela de origemcustomerse insere os registros na tabela de destino.
@dp.temporary_view(name="customers_incremental_view")
def query():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.includeExistingFiles", "true")
.load(customers_incremental_path)
.dropDuplicates(["customer_id"])
)
@dp.temporary_view(name="customers_snapshot_view")
def full_orders_snapshot():
return (
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.includeExistingFiles", "true")
.option("cloudFiles.inferColumnTypes", "true")
.load(customers_snapshot_path)
.select("*")
)
dp.create_streaming_table("customers")
dp.create_auto_cdc_flow(
flow_name = "customers_incremental_flow",
target = "customers",
source = "customers_incremental_view",
keys = ["customer_id"],
sequence_by = col("sequenceNum"),
apply_as_deletes = expr("operation = 'DELETE'"),
apply_as_truncates = expr("operation = 'TRUNCATE'"),
except_column_list = ["operation", "sequenceNum"],
stored_as_scd_type = 1
)
dp.create_auto_cdc_flow(
flow_name = "customers_snapshot_flow",
target = "customers",
source = "customers_snapshot_view",
keys = ["customer_id"],
sequence_by = lit(0),
stored_as_scd_type = 1,
once = True
)
Após a implantação deste pipeline, ele foi executado com sucesso e começou a processar o feed de dados alterados e o Snapshot inicial.
Mais tarde, você percebe que a lógica de desduplicação na consulta customers_incremental_view é redundante e causa um gargalo de desempenho. Você remove o dropDuplicates() para melhorar o desempenho:
@dp.temporary_view(name="customers_raw_view")
def query():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.includeExistingFiles", "true")
.load()
# .dropDuplicates()
)
Após remover a API dropDuplicates() e reimplantar o pipeline, a atualização falha com o seguinte erro:
Streaming stateful operator name does not match with the operator in state metadata.
This is likely to happen when a user adds/removes/changes stateful operators of existing streaming query.
Stateful operators in the metadata: [(OperatorId: 0 -> OperatorName: dedupe)];
Stateful operators in current batch: []. SQLSTATE: 42K03 SQLSTATE: XXKST
Este erro indica que a alteração não é permitida devido a uma incompatibilidade entre o estado do ponto de verificação e a definição da consulta atual, impedindo que o pipeline avance.
Falhas relacionadas ao ponto de verificação podem ocorrer por vários motivos além da simples remoção da API dropDuplicates . Cenários comuns incluem:
- Adicionar ou remover operadores com estado (por exemplo, introduzir ou remover
dropDuplicates()ou agregações) em uma consulta de transmissão existente. - Adicionar, remover ou combinar fontes de transmissão em uma consulta previamente verificada (por exemplo, unir uma consulta de transmissão existente com uma nova ou adicionar/remover fontes de uma consulta de união existente).
- Modificar o esquema de estado das operações de transmissão com estado (como alterar as colunas usadas para desduplicação ou agregação).
Para obter uma lista abrangente de alterações suportadas e não suportadas, consulte o guiaSpark transmissão estructurada e Tipos de alterações em consultas de transmissão estructurada.
Opções de recuperação
Existem três estratégias de recuperação, dependendo dos seus requisitos de durabilidade de dados e restrições de recurso:
Métodos | Complexidade | Custo | Perda potencial de dados | Possível duplicação de dados | Requer Snapshot inicial | Redefinição de tabela completa |
|---|---|---|---|---|---|---|
Baixa | Médio | Sim (se nenhum Snapshot inicial estiver disponível ou se os arquivos raw tiverem sido excluídos na origem.) | Não (Para aplicar alterações na tabela de destino.) | Sim | Sim | |
Médio | Alta | Não | Não (Para dissipadores idempotentes. Por exemplo, CDC automático.) | Não | Não | |
Médio-alto (Médio para fontes somente de acréscimo que fornecem deslocamentos imutáveis). | Baixa | Não (requer consideração cuidadosa.) | Não (Para escritores idempotentes. Por exemplo, CDC automático somente para a tabela de destino.) | Não | Não |
A complexidade média-alta depende do tipo de fonte de transmissão e da complexidade da consulta.
Recomendações
- Use um refresh completo da tabela se você não quiser lidar com a complexidade de um reset de checkpoint, e você pode recalcular a tabela inteira. Um refresh completo também oferece a opção de fazer alterações no código.
- Use refresh completa da tabela com backup e preenchimento retroativo se não quiser lidar com a complexidade da redefinição do ponto de verificação e estiver de acordo com o custo adicional de fazer um backup e preencher o histórico de dados.
- Use o ponto de verificação Redefinir tabela se você precisar preservar os dados existentes na tabela e continuar processando novos dados incrementalmente. No entanto, essa abordagem requer um tratamento cuidadoso do ponto de verificação Reset para verificar se os dados existentes na tabela não foram perdidos e se o pipeline pode continuar processando novos dados.
Reset o ponto de verificação e continuar incrementalmente
Para redefinir o ponto de verificação e continuar o processamento incrementalmente, siga estes passos:
-
Pare o pipeline: certifique-se de que não haja atualizações ativas em execução no pipeline.
-
Determine a posição inicial para o novo ponto de verificação: identifique o último deslocamento ou registro de data e hora bem-sucedido a partir do qual você deseja continuar o processamento. Normalmente, esse é o último deslocamento processado com sucesso antes da falha ocorrer.
Como você está lendo os arquivos JSON usando o Auto Loader no exemplo anterior, você pode usar a opção
modifiedAfterpara definir um carimbo de data/hora para quando o Auto Loader começar a processar novos arquivos.Para fontes Kafka , você pode usar a opção
startingOffsetspara especificar os deslocamentos a partir dos quais a consulta de transmissão deve começar a processar novos dados.Para fontes Delta Lake , você pode usar a opção
startingVersionpara especificar a versão a partir da qual a consulta de transmissão deve começar a processar novos dados. -
Faça alterações no código: Você pode modificar a consulta de transmissão para remover a API
dropDuplicates()ou fazer outras alterações. Verifique também se você adicionou a opçãomodifiedAfterao caminho de leitura do Auto Loader.Python@dp.temporary_view(name="customers_incremental_view")
def query():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.includeExistingFiles", "true")
.option("modifiedAfter", "2025-04-09T06:15:00")
.load(customers_incremental_path)
# .dropDuplicates(["customer_id"])
)
Fornecer um registro de data e hora modifiedAfter incorreto pode levar à perda ou duplicação de dados. Verifique se o registro de data e hora está definido corretamente para evitar o processamento de dados antigos novamente ou a perda de novos dados.
Se sua consulta tiver join transmissão-transmissão ou união transmissão-transmissão, você deverá aplicar a estratégia acima para todas as fontes de transmissão participantes. Por exemplo:
cdc_1 = spark.readStream.format("cloudFiles")...
cdc_2 = spark.readStream.format("cloudFiles")...
cdc_source = cdc_1..union(cdc_2)
-
Identificar os nomes dos fluxos associados à tabela de transmissão para a qual se deseja Reset o ponto de verificação. É preciso passar cada nome de fluxo em um formato
catalog.schema.flow_nametotalmente qualificado. No exemplo, o nome do fluxo totalmente qualificado émy_catalog.my_schema.customers_incremental_flow. O fluxo usa um parâmetro explícitoflow_namedecustomers_incremental_flow. Caso não seja definido um nome de fluxo explícito, o nome de fluxo padrão será o nome de tabela de destino totalmente qualificado no formatocatalog.schema.table(por exemplo,my_catalog.my_schema.customers). É possível encontrar nomes de fluxo no código do pipeline, na interface de usuário do pipeline ou nos logs de eventos do pipeline. -
Reset o ponto de verificação: crie um Python Notebook e anexe-o a um cluster Databricks .
Você precisará das seguintes informações para poder redefinir o ponto de verificação:
- URL workspace Databricks
- ID do pipeline
- Nome(s) do(s) fluxo(s) para o(s) qual(is) você está Redefinindo o ponto de verificação
Pythonimport requests
import json
# Define your Databricks instance and pipeline ID
databricks_instance = "<DATABRICKS_URL>"
token = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get()
pipeline_id = "<YOUR_PIPELINE_ID>"
flows_to_reset = ["<YOUR_FLOW_NAME>"]
# Set up the API endpoint
endpoint = f"{databricks_instance}/api/2.0/pipelines/{pipeline_id}/updates"
# Set up the request headers
headers = {
"Authorization": f"Bearer {token}",
"Content-Type": "application/json"
}
# Define the payload
payload = {
"reset_checkpoint_selection": flows_to_reset
}
# Make the POST request
response = requests.post(endpoint, headers=headers, data=json.dumps(payload))
# Check the response
if response.status_code == 200:
print("Pipeline update started successfully.")
else:
print(f"Error: {response.status_code}, {response.text}") -
execução do pipeline: O pipeline começa a processar novos dados da posição inicial especificada com um novo ponto de verificação, preservando os dados da tabela existente enquanto continua o processamento incremental.
Melhores práticas
- Evite usar recurso de visualização privada em produção.
- Teste suas alterações antes de fazer alterações no seu ambiente de produção.
- Crie um pipeline de teste, idealmente em um ambiente inferior. Se isso não for possível, tente usar um catálogo e esquema diferentes para seu teste.
- Reproduza o erro.
- Aplique as alterações.
- Valide os resultados e tome uma decisão sobre prosseguir ou não.
- Implemente as alterações no seu pipeline de produção.