Crie um pipeline controlado por origem
No Databricks, você pode controlar a origem de um pipeline e todo o código associado a ele. Ao controlar a origem de todos os arquivos associados ao seu pipeline, as alterações no código de transformações, no código de exploração e na configuração pipeline são todas versionadas no Git e podem ser testadas no desenvolvimento e transferidas com segurança para a produção.
Um pipeline controlado por fonte oferece as seguintes vantagens:
- Rastreabilidade : capture todas as alterações no histórico Git .
- Teste : valide as alterações pipeline em um workspace de desenvolvimento antes de promover para um workspace de produção compartilhado. Cada desenvolvedor tem seu próprio pipeline de desenvolvimento em seu próprio branch de código em uma pasta Git e em seu próprio esquema.
- Colaboração : quando o desenvolvimento e os testes individuais são concluídos, as alterações no código são enviadas para o pipeline de produção principal.
- Governança : alinhe-se com os padrões de CI/CD e implantação da empresa.
Databricks permite que o pipeline e seus arquivos de origem sejam controlados em conjunto por meio de Pacotes de Automação Declarativa. Com os bundles, a configuração do pipeline é controlada por versão na forma de arquivos de configuração YAML, juntamente com os arquivos de origem Python ou SQL de um pipeline. Um pacote pode conter um ou mais pipelines, bem como outros tipos de recursos, como Jobs.
Esta página mostra como configurar um pipeline com controle de versão usando Declarative Automation Bundles (anteriormente conhecidos como Databricks ativo Bundles). Para obter mais informações sobre pacotes, consulte O que são pacotes de automação declarativa?.
Requisitos
Para criar um pipeline controlado por origem, você já deve ter:
- Uma pasta Git criada e configurada em seu workspace . Uma pasta Git permite que usuários individuais criem e testem alterações antes de confirmá-las em um repositório Git . Consulte as pastas Git do Databricks.
- O Editor LakeFlow Pipelines . Consulte Desenvolver e depurar pipelines ETL com o Editor LakeFlow Pipelines para obter mais informações.
- Para o conjunto completo de privilégios necessários para criar, executar, refresh e view pipelines e sua saída, consulte Gerenciar identidades, permissões e privilégios para pipelines.
Crie um novo pipeline em um pacote
Databricks recomenda a criação de um pipeline com controle de origem desde o início. Como alternativa, você pode adicionar um pipeline existente a um pacote que já tenha controle de origem. Consulte Migrar recurso existente para um pacote.
Para criar um novo pipeline controlado por origem:
-
Na parte superior da barra lateral, clique em
 Novo e, em seguida, selecione
Novo e, em seguida, selecione  pipelineETL .
pipelineETL . -
Faça as alterações que desejar no nome ou no esquema do pipeline. Consulte Criar um novo pipeline ETL.
-
Clique no
 menu (à direita do
menu (à direita do  Use o botão de código de exemplo ) e selecione
Use o botão de código de exemplo ) e selecione  Configurar como controlado por versão .
Configurar como controlado por versão . -
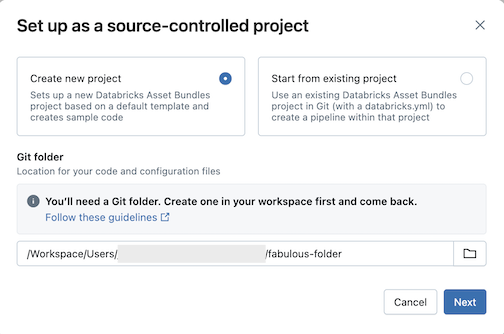
Clique em Criar novo projeto e selecione uma pasta Git onde você deseja colocar seu código e configuração:
-
Clique em Avançar .
-
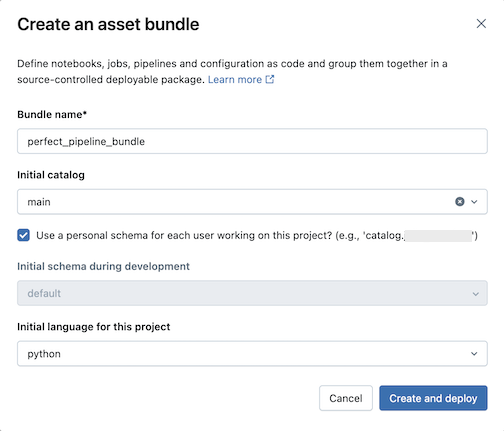
Digite o seguinte na caixa de diálogo Criar um pacote ativo :
- Nome do pacote : O nome do pacote.
- Catálogo inicial : O nome do catálogo que contém o esquema a ser usado.
- Usar um esquema pessoal : deixe esta caixa marcada se quiser isolar edições em um esquema pessoal, para que quando os usuários da sua organização colaborarem no mesmo projeto, vocês não substituam as alterações uns dos outros no dev.
- Linguagem inicial : a linguagem inicial a ser usada para os arquivos de pipeline de amostra do projeto, Python ou SQL.
-
Clique em Criar e instalado . Um pacote com um pipeline é criado na pasta Git.
Explore o pacote de pipeline
Em seguida, explore o pacote de pipeline que foi criado.
O pacote, que está na pasta Git , contém arquivos de sistema do pacote e o arquivo databricks.yml , que define variáveis, URLs workspace de destino e permissões, e outras configurações para o pacote. Como databricks.yml reside na raiz do pacote (o pai da raiz do pipeline ), mude para a tab Todos os arquivos no navegador ativo pipeline para vê-lo. A pasta resources de um pacote é onde as definições para recursos como pipeline e Job são contidas.
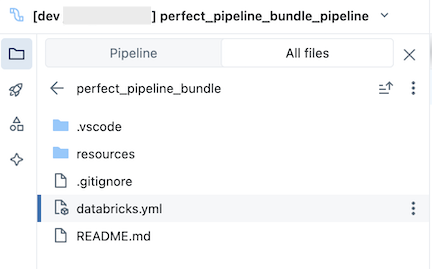
Abra a pasta resources e clique no botão do editor de pipeline para view o pipeline controlado pela origem:
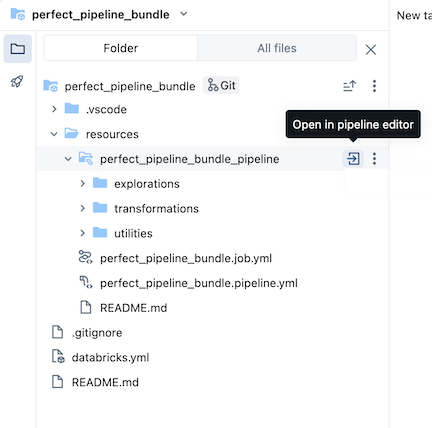
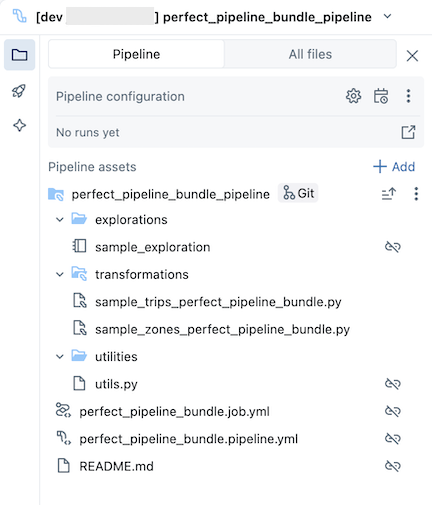
O pacote de pipeline de amostra inclui os seguintes arquivos:
-
Um exemplo de caderno de exploração
-
Dois arquivos de código de exemplo que fazem transformações em tabelas
-
Um arquivo de código de exemplo que contém uma função utilidades
-
Um arquivo YAML de configuração de trabalho que define o trabalho no pacote que executa o pipeline
-
Um arquivo YAML de configuração de pipeline que define o pipeline
Você deve editar este arquivo para persistir permanentemente quaisquer alterações de configuração no pipeline, incluindo alterações feitas por meio da interface do usuário. Caso contrário, as alterações da interface do usuário serão substituídas quando o pacote for reimplantado. Por exemplo, para definir um catálogo default diferente para o pipeline, edite o campo catalog neste arquivo de configuração.
- Um arquivo README com detalhes adicionais sobre o pacote pipeline de amostra e instruções sobre como executar o pipeline
Para informações sobre arquivos pipeline , consulte navegador pipeline ativo.
Para obter mais informações sobre criação e alterações implantadas no pacote pipeline , consulte Criar pacotes no workspace e pacotes implantados e fluxo de trabalho de execução a partir do workspace.
execução do pipeline
Você pode executar transformações individuais ou todo o pipeline controlado pela fonte:
- Para executar e visualizar uma única transformação no pipeline, selecione o arquivo de transformações na árvore do navegador workspace para abri-lo no editor de arquivos. Na parte superior do arquivo no editor, clique no botão de execução do arquivo .
- Para executar todas as transformações no pipeline, clique no botão pipelinede execução no canto superior direito do workspace Databricks .
Para obter mais informações sobre a execução do pipeline, consulte código pipeline de execução.
Atualizar o pipeline
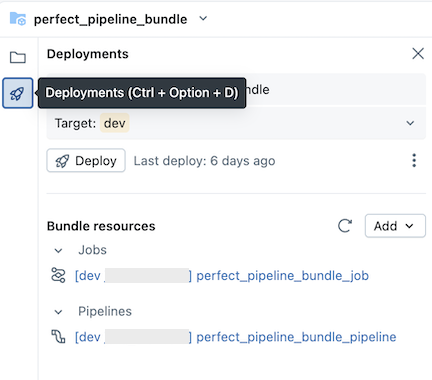
Você pode atualizar artefatos em seu pipeline ou adicionar explorações e transformações adicionais, mas depois precisará enviar essas alterações para o GitHub. Clique no ![]() Ícone do Git associado ao pacote do pipeline ou clique no ícone de três linhas horizontais (kebab) da pasta e, em seguida, em Git... para selecionar quais alterações enviar. Veja as alterações de commit e push.
Ícone do Git associado ao pacote do pipeline ou clique no ícone de três linhas horizontais (kebab) da pasta e, em seguida, em Git... para selecionar quais alterações enviar. Veja as alterações de commit e push.
Além disso, quando você atualiza os arquivos de configuração pipeline ou adiciona ou remove arquivos do pacote, essas alterações não são propagadas para o workspace de destino até que você implante explicitamente o pacote. Veja bundles implantados e fluxo de trabalho de execução a partir do workspace.
Databricks recomenda que você mantenha a configuração default para pipeline controlado por origem. A configuração default é definida para que você não precise editar a configuração YAML do pacote pipeline quando arquivos adicionais são adicionados por meio da interface do usuário.
Adicionar um pipeline existente a um pacote
Para adicionar um pipeline existente a um pacote, primeiro crie um pacote no workspace e, em seguida, adicione a definição YAML pipeline ao pacote, conforme descrito nas páginas a seguir:
Para obter informações sobre como migrar o recurso para um pacote usando o Databricks CLI, consulte Migrar recurso existente para um pacote.
Recurso adicional
Para tutoriais adicionais e material de referência para pipelines, consulte Spark Declarative Pipelines.