captura de dados de alterações (CDC) e Snapshot
Engenheiros de dados frequentemente precisam replicar dados de fontes upstream do Databricks— como bancos de dados relacionais (Oracle, Postgres, SQL Server) — para Databricks para fins de análise, geração de relatórios e machine learning. À medida que os sistemas operacionais mudam, as tabelas analíticas devem permanecer sincronizadas com essas mudanças.
Algumas equipes precisam refletir o estado atual de seus bancos de dados operacionais para fins de geração de relatórios e análises. Outros precisam preservar um histórico completo das alterações para fins de auditoria, requisitos regulatórios ou análises de clientes.
captura de dados de alterações (CDC) (CDC) trata um banco de dados como um conjunto de alterações, e não como um banco de dados estático completo. O diagrama a seguir mostra que, quando uma linha em uma tabela de origem que contém dados de funcionários é atualizada, ela gera um novo conjunto de linhas em um feed CDC que contém apenas as alterações. Cada linha do feed CDC normalmente contém metadados adicionais, incluindo operações como UPDATE e uma coluna que pode ser usada para ordenar deterministicamente cada linha no feed CDC , para que você possa lidar com atualizações fora de ordem. Por exemplo, a coluna sequenceNum no diagrama a seguir determina a ordem das linhas no feed do CDC:
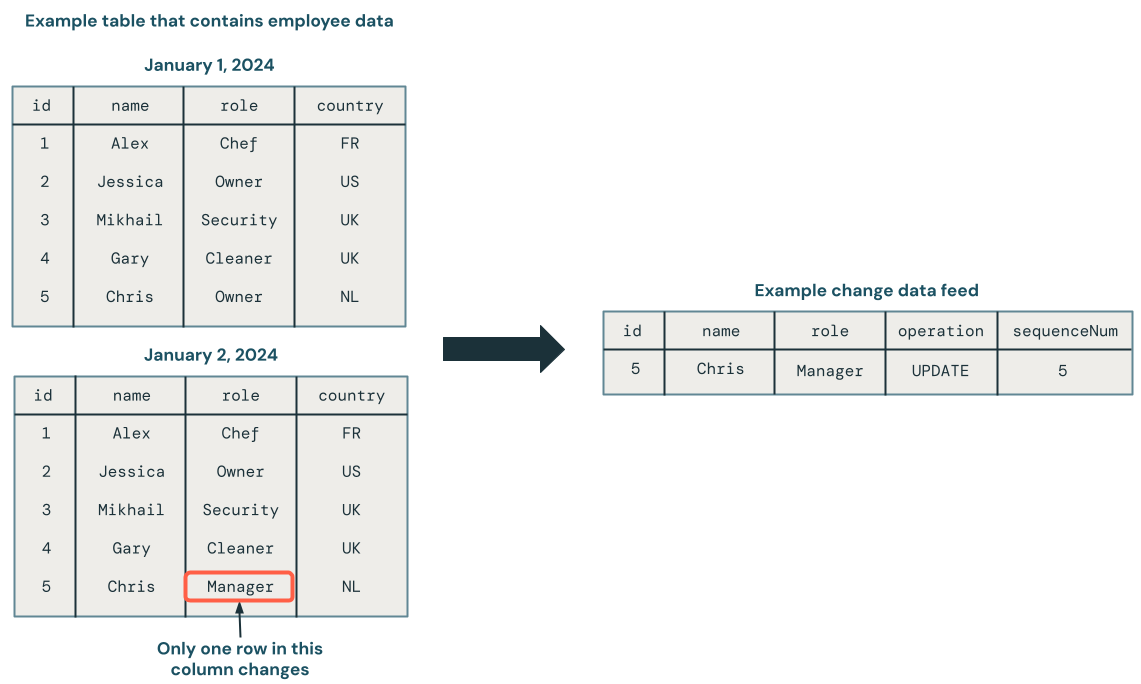
CDC permite view apenas as alterações nos dados para transações mais simples ao atualizar o banco de dados em um sistema subsequente. Também permite visualizar o histórico do banco de dados, caso seja necessário.
O desafio reside no fato de que os sistemas de origem fornecem dados em formatos diferentes. Algumas emitem feeds de alterações que capturam mudanças individuais (inserções, atualizações, exclusões). Outros fornecem apenas instantâneos periódicos da tabela inteira. Cada formato exige abordagens de processamento diferentes para manter as tabelas subsequentes precisas e atualizadas.
Historicamente, as equipes têm se baseado em lógica personalizada MERGE INTO para aplicar essas alterações — seja por meio de feeds de alterações ou comparando Snapshots. Essa abordagem é complexa e propensa a erros, exigindo tabelas de preparação, funções de janela e suposições de sequenciamento que são difíceis de entender e manter à medida que o pipeline evolui.
Esta página descreve os dois formatos CDC (SCD Tipo 1 e Tipo 2), o que é CDC em detalhes e como aproveitar as vantagens do CDC, mesmo quando os dados de origem não o suportam, usando o recurso Snapshot.
Quais são os benefícios do CDC?
A captura de dados de alterações (CDC) oferece vários benefícios em suas cargas de trabalho.
- Os dados de alteração são normalmente menores do que o conjunto de dados completo, e as alterações podem ser processadas por consultas subsequentes como atualizações incrementais dos dados.
- Os dados de alteração podem ser armazenados de forma a permitir a reconstrução dos registros tal como estavam em um momento específico, fornecendo um histórico completo para auditoria, relatórios pontuais ou análise de tendências.
- A alteração de dados permite uma chave substituta estável ao longo do tempo.
Como as alterações são aplicadas: Estado atual ou panorama completo das alterações
As dimensões que mudam lentamente (SCD) definem como as mudanças a montante são aplicadas e modeladas depois de chegarem às tabelas analíticas. As organizações podem usar abordagens diferentes com base em suas necessidades de dados. SCD Tipo 1 permite salvar apenas o estado atual do dataset. SCD Tipo 2 salva o histórico completo das alterações no dataset. Esta seção descreve esses aspectos com mais detalhes.
SCD Tipo 1: Somente estado atual
O SCD Tipo 1 sobrescreve os dados antigos com os novos sempre que ocorrem alterações, mantendo apenas a versão mais recente de cada registro. A história não é preservada.
Utilize SCD Tipo 1 quando:
- Você só precisa do estado atual dos dados.
- Você deseja que a visualização materializada subsequente seja refresh incrementalmente, em vez de ser totalmente recalculada.
- Você precisa de uma chave substituta estável para ingressar.
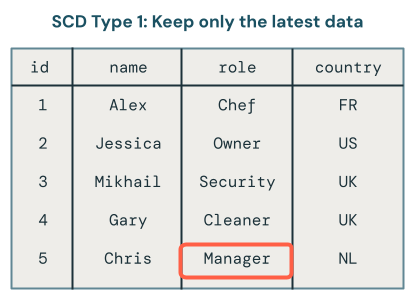
Apenas a versão mais recente dos dados está disponível no SCD1. É uma abordagem simples que você pode considerar como o armazenamento apenas da tabela final. Se um registro mudar de Owner para Manager, apenas Manager permanecerá na tabela:
SCD Tipo 2: Acompanhamento histórico
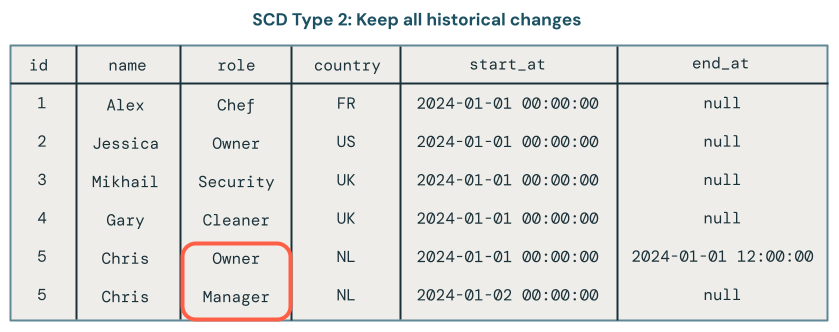
O SCD Tipo 2 mantém um registro histórico completo, criando múltiplas versões de dados ao longo do tempo, cada uma com data e hora registradas e metadados. As colunas __START_AT e __END_AT definem o período de validade para cada versão de um registro. Os registros ativos têm __END_AT = NULL. Você pode view o estado do dataset de dados em qualquer ponto no tempo.
Utilize o SCD Tipo 2 quando:
- A auditabilidade ou os requisitos regulamentares exigem acompanhamento histórico.
- A análise de clientes exige a compreensão de como as entidades evoluíram ao longo do tempo.
- A lógica de negócios exige relatórios pontuais.
- Você precisa analisar tendências ou comparar estados históricos.
O processamento SCD Tipo 2 mantém um registro histórico das alterações de dados. Por exemplo, se um registro atualmente tiver o campo de função definido como Manager, você também poderá ver que a função foi definida anteriormente como Owner. Na imagem a seguir, é exatamente isso que aconteceu com o registro para Chris. Você pode identificar o registro atual porque ele possui um valor null para o campo end_at :
O que é um feed do CDC?
captura de dados de alterações (CDC) (CDC) é um padrão de integração de dados que captura alterações feitas nos dados em um sistema de origem – inserções, atualizações e exclusões. Em vez de processar todo o conjunto de dados, CDC gera feeds contendo apenas os registros modificados.
Por exemplo, se você tiver uma tabela de funcionários no Oracle com 50 linhas e o cargo de um funcionário for alterado, o feed CDC conterá um único registro UPDATE para esse funcionário. Isso permite que o Databricks processe apenas os registros alterados, em vez de ler a tabela de origem inteira a cada execução.
Cada registro do CDC proveniente do banco de dados de origem inclui:
- O tipo de operações (
INSERT,UPDATE,DELETE) - Os valores dos dados para o registro
- Um número de sequência ou carimbo de data/hora para ordenação determinística.
O número de sequência garante que as chegadas atrasadas ou fora de ordem sejam processadas corretamente. Bancos de dados transacionais como SQL Server, MySQL e Oracle geram feeds CDC nativamente. As tabelas Delta também geram seu próprio feed CDC, conhecido como Change Data Feed (CDF), o que facilita o processamento de alterações provenientes de fontes Delta.
O que é um instantâneo?
Um instantâneo representa o estado completo de uma tabela em um ponto específico no tempo. Ao contrário dos feeds CDC , que capturam apenas as alterações, o Snapshot contém todas as linhas da tabela de origem.
As equipes nem sempre habilitam os feeds do CDC em bancos de dados operacionais por diversos motivos:
- Custo (o CDC pode aumentar a carga nos bancos de dados de produção)
- Problemas de desempenho no banco de dados de origem
- Sistemas legados que não são compatíveis com o CDC
- Restrições organizacionais (as equipes que gerenciam a ingestão não são proprietárias dos bancos de dados upstream)
Quando um feed de alterações não está disponível, a ingestão baseada em snapshots é a única opção. O instantâneo pode vir de:
- Exportações periódicas de bancos de dados relacionais (Oracle, Postgres, SQL Server)
- despejos de arquivos de armazenamento em nuvem de sistemas upstream
- Tabelas Delta (cada versão da tabela é efetivamente um Snapshot)
- Delta Sharing do locatário upstream
Como os Snapshots não capturam alterações em nível de registro, identificar o que mudou exige comparar registros entre Snapshots para inferir inserções, atualizações e exclusões.
Processar automaticamente os dados do CDC
Databricks simplifica o processamento CDC por meio da API AUTO CDC dentro do pipeline declarativo LakeFlow Spark . Esta API foi projetada para processar alterações provenientes de feeds CDC em bancos de dados de origem ou tabelas Delta com o recurso Change Data Feed ativado.
Use AUTO CDC quando qualquer uma destas condições for verdadeira:
- Seu sistema de origem gera um Feed de Dados de Alteração (CDF).
- Você está lendo dados de uma tabela Delta com o Feed de Dados de Alteração ativado.
- Você possui um feed do CDC proveniente de um banco de dados relacional (através de ferramentas como Debezium ou Oracle GoldenGate).
AUTO CDC Lida automaticamente com registros fora de sequência, processando os eventos na ordem definida pela coluna de sequenciamento. A coluna de sequenciamento deve ser uma representação monotonicamente crescente da ordem correta dos eventos, com uma atualização distinta por key em cada valor de sequenciamento. Os valores de sequenciamento NULL não são suportados. Para SCD Tipo 2, o pipeline LakeFlow Spark Declarative propaga os valores de sequenciamento para as colunas __START_AT e __END_AT da tabela de destino.
Hidratação inicial: Ao replicar uma tabela de banco de dados operacional existente no Databricks, primeiro é necessário carregar todo o histórico de dados antes de processar as alterações em andamento. AUTO CDC suporta isso através de fluxos únicos , um modo que processa todos os dados disponíveis uma vez e depois para. Após a conclusão da carga inicial, utilize um fluxo em modo acionado ou contínuo para o processamento CDC em andamento. Isso garante uma lógica consistente tanto para cargas em massa quanto para cargas incrementais.
Processar instantâneo automaticamente
Quando os feeds do CDC não estão disponíveis, o Databricks fornece a API AUTO CDC FROM SNAPSHOT . Esta API foi projetada para ingestão baseada em snapshots; ela compara snapshots consecutivos , gera um feed de alterações sintético e aplica a lógica SCD Tipo 1 ou Tipo 2 na tabela de destino. A tabela de destino pode fornecer um feed CDC (chamado de feed de dados de alteração (CDF) em tabelas Delta) do tipo SCD 1 ou do tipo 2 para consultas subsequentes.
AUTO CDC FROM SNAPSHOT É suportado apenas na interface de pipeline do Python. Os snapshots devem ser processados em ordem crescente de versão; se um snapshot fora de ordem for detectado, ele será ignorado. O processamento subsequente, como uma view materializada que consulta a saída de um dataset AUTO CDC FROM SNAPSHOT , obtém os benefícios do CDC, como a capacidade de incrementalização e chave substituta estável.
AUTO CDC FROM SNAPSHOT Não serve apenas para cargas iniciais. Ele foi projetado para processamento contínuo quando o formato de instantâneo é o único disponível. Cada vez que um novo Snapshot é gerado, a API o compara com o Snapshot anterior para identificar as alterações e gerar um feed de dados de mudanças.
Use AUTO CDC FROM SNAPSHOT quando:
- O CDC não está habilitado no banco de dados de origem.
- Você só tem acesso a snapshots periódicos (dumps completos da tabela).
- Você deseja os benefícios do CDC para processamento incremental ou ter um histórico completo das alterações?
AUTO CDC FROM SNAPSHOT Lida automaticamente com o seguinte:
- Compara snapshots consecutivos para identificar registros inseridos, atualizados e excluídos.
- Gera um feed de alterações sintético com base nas diferenças entre os Snapshots.
- Aplica a mesma lógica SCD que
AUTO CDCpara compute SCD Tipo 1 ou Tipo 2.
AUTO CDC FROM SNAPSHOT Só tem conhecimento das alterações de um Snapshot para o seguinte, e não das alterações interinas. Por exemplo, se você receber um Snapshot diário e um usuário alterar seu endereço duas vezes em um dia (de A para B e depois de B para C), seu feed de alterações poderá ir diretamente de A para C, porque você só recebeu o Snapshot para esses horários.
padrões de processamentoSnapshot
AUTO CDC FROM SNAPSHOT Suporta dois padrões para determinar versões de Snapshot.
Processamento Snapshot usando o tempo de ingestão pipeline
O Snapshot é lido no momento da execução do pipeline , e o horário de ingestão é usado como a versão do Snapshot. Um novo Snapshot é incorporado a cada atualização pipeline . Quando um pipeline é executado em modo contínuo, vários Snapshots são capturados com base no intervalo de disparo definido para o fluxo.
Use esse padrão quando os snapshots chegarem regularmente e em ordem, e você puder confiar no carimbo de data/hora de execução pipeline para o versionamento.
Processamento Snapshot usando funções de versão
Você fornece uma função que especifica qual versão do Snapshot deve ser processada no momento da execução do pipeline . A função retorna uma tupla: (DataFrame, version_number). A API processa os Snapshots na ordem definida pelos números de versão. Se for detectado um Snapshot fora de ordem, ele será ignorado.
Use este padrão quando:
- Vários instantâneos podem chegar ao mesmo tempo e precisam de processamento sequencial.
- O instantâneo pode chegar fora de ordem.
- Você precisa ter controle explícito sobre a ordem dos snapshots.
Capacidades adicionais do CDC
Alterar operações nos alvos do AUTO CDC
Ao contrário das tabelas de transmissão padrão, as tabelas Unity Catalog que são destinos AUTO CDC suportam instruções INSERT, UPDATE, DELETE e MERGE mesmo enquanto o pipeline está em execução. Para obter detalhes e limitações, consulte Adicionar, alterar ou excluir dados em uma tabela de transmissão de destino.
Leitura de feeds de dados de mudança de alvos do AUTO CDC
AUTO CDC As tabelas de transmissão de destino podem emitir seu próprio Change Data Feed (CDF), permitindo que o pipeline downstream consuma as alterações da saída AUTO CDC . Para obter detalhes, consulte Ler um feed de dados de alterações de uma tabela de destino AUTO CDC.
meth e
AUTO CDC Captura automaticamente as métricas num_upserted_rows e num_deleted_rows em cada execução do pipeline. Para obter detalhes, consulte os tópicos avançados do AUTO CDC.
Subconjuntos de colunas de acompanhamento para SCD Tipo 2
Por default, SCD Tipo 2 cria uma nova versão sempre que o valor de qualquer coluna é alterado. AUTO CDC permite especificar quais colunas rastrear para o histórico, de forma que as alterações em colunas não rastreadas atualizem a versão atual no local, em vez de criar um novo registro histórico. Isso reduz os custos de armazenamento e a complexidade das consultas, preservando o histórico de atributos críticos. Para um exemplo, consulte Rastrear um subconjunto de colunas com SCD Tipo 2.
Recomendações
Use captura de dados de alterações (CDC) (CDC) quando você quiser trabalhar apenas com as alterações em seus dados, por exemplo, para permitir que a visualização materializada subsequente seja atualizada incrementalmente. Utilize também CDC quando desejar manter um histórico das alterações em seus dados, por exemplo, para saber quem desempenhava qual função em um determinado momento.
Use as APIs AUTO CDC quando precisar replicar dados upstream no Databricks e mantê-los sincronizados com as alterações da fonte. A API correta depende de como o seu sistema de origem expõe as alterações:
- Use
AUTO CDCquando sua fonte emitir um feed de alterações — por exemplo, um banco de dados relacional com CDC habilitado (por meio de ferramentas como Debezium ou Oracle GoldenGate), uma tabela Delta com Change Data Feed habilitado ou qualquer fonte que produza uma transmissão de inserções, atualizações e exclusões com uma coluna de sequenciamento. - Use
AUTO CDC FROM SNAPSHOTquando sua fonte não suporta CDC e fornece apenas dumps completos de tabelas periodicamente. Essa API infere alterações comparando Snapshots consecutivos e gera um feed de alterações sintético, para que você obtenha os mesmos benefícios de processamento SCD mesmo sem um feed CDC nativo.
Em ambos os casos, escolha SCD Tipo 1 se precisar apenas do estado atual de cada registro, ou SCD Tipo 2 se precisar preservar um histórico completo de alterações para auditoria, relatórios pontuais ou análise de tendências.
Próximos passos
- As APIs AUTO CDC : Simplifique a captura de dados de alterações (CDC) com pipeline: Aprenda como implementar CDC com as APIs
AUTO CDCeAUTO CDC FROM SNAPSHOT. - Tópicos avançados do AUTO CDC: Aprenda sobre tópicos avançados CDC , como uso de operações DML, leitura de feeds de dados de alteração e monitoramento de métricas.