Computação de recursos sob demanda
No Databricks, recursos sob demanda são computados no momento da inferência usando funções definidas pelo usuário (UDFs) escritas em Python, em vez de serem materializados antecipadamente.
Os recursos sob demanda são gerados a partir dos valores dos recursos e das entradas do modelo. Eles não são materializados e, em vez disso, são computados sob demanda durante o treinamento do modelo e durante a inferência. Um caso de uso típico é o pós-processamento de um recurso existente, por exemplo, para analisar um campo de uma cadeia de caracteres JSON. O senhor também pode usar o recurso on-demand para compute novos recursos com base em transformações de recursos existentes, como a normalização de valores em uma matriz.
No site Databricks, o usuário utiliza as funções definidas pelo usuário (UDFs) do sitePython para especificar como calcular o recurso on-demand. Essas funções são controladas pelo Unity Catalog e podem ser descobertas por meio do Catalog Explorer.
Para usar o recurso on-demand, seu workspace deve estar habilitado para Unity Catalog e o senhor deve usar Databricks Runtime 13.3 LTS ML ou acima.
fluxo de trabalho
Para compute recurso on-demand, o senhor especifica uma função definida pelo usuário Python (UDF) que descreve como calcular os valores do recurso.
- Durante o treinamento, o senhor fornece essa função e seus vínculos de entrada no parâmetro
feature_lookupsda APIcreate_training_set. - O senhor deve log o modelo treinado usando o método Recurso Store
log_model. Isso garante que o modelo avalie automaticamente o recurso on-demand quando for usado para inferência. - Para a pontuação de lotes, o
score_batchAPI calcula e retorna automaticamente todos os valores de recurso, inclusive o recurso on-demand.
Criar uma UDF Python
O senhor pode criar um Python UDF em um Notebook ou em Databricks SQL.
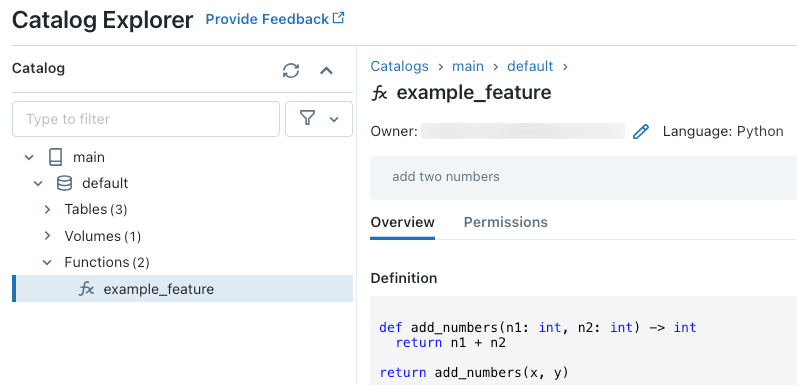
Por exemplo, a execução do código a seguir em uma célula do Notebook cria o site Python UDF example_feature no catálogo main e no esquema default.
%sql
CREATE FUNCTION main.default.example_feature(x INT, y INT)
RETURNS INT
LANGUAGE PYTHON
COMMENT 'add two numbers'
AS $$
def add_numbers(n1: int, n2: int) -> int:
return n1 + n2
return add_numbers(x, y)
$$
Depois de executar o código, o senhor pode navegar pelo namespace de três níveis no Catalog Explorer para view a definição da função:
Para obter mais detalhes sobre a criação de UDFs em Python, consulte o registro em Python UDF a Unity Catalog e o manual da linguagem SQL.
Treinar um modelo usando recurso on-demand
Para treinar o modelo, o senhor usa um FeatureFunction, que é passado para a API create_training_set no parâmetro feature_lookups.
O código de exemplo a seguir usa o Python UDF main.default.example_feature que foi definido na seção anterior.
# Install databricks-feature-engineering first with:
# %pip install databricks-feature-engineering
# dbutils.library.restartPython()
from databricks.feature_engineering import FeatureEngineeringClient
from databricks.feature_engineering import FeatureFunction, FeatureLookup
from sklearn import linear_model
fe = FeatureEngineeringClient()
features = [
# The feature 'on_demand_feature' is computed as the sum of the input value 'new_source_input'
# and the pre-materialized feature 'materialized_feature_value'.
# - 'new_source_input' must be included in base_df and also provided at inference time.
# - For batch inference, it must be included in the DataFrame passed to 'FeatureEngineeringClient.score_batch'.
# - For real-time inference, it must be included in the request.
# - 'materialized_feature_value' is looked up from a feature table.
FeatureFunction(
udf_name="main.default.example_feature", # UDF must be in Unity Catalog so uses a three-level namespace
input_bindings={
"x": "new_source_input",
"y": "materialized_feature_value"
},
output_name="on_demand_feature",
),
# retrieve the prematerialized feature
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id'
)
]
# base_df includes the columns 'id', 'new_source_input', and 'label'
training_set = fe.create_training_set(
df=base_df,
feature_lookups=features,
label='label',
exclude_columns=['id', 'new_source_input', 'materialized_feature_value'] # drop the columns not used for training
)
# The training set contains the columns 'on_demand_feature' and 'label'.
training_df = training_set.load_df().toPandas()
# training_df columns ['materialized_feature_value', 'label']
X_train = training_df.drop(['label'], axis=1)
y_train = training_df.label
model = linear_model.LinearRegression().fit(X_train, y_train)
registre o modelo e registre-o no Unity Catalog
Os modelos de pacote com metadados de recurso podem ser registrados em Unity Catalog. As tabelas de recurso usadas para criar o modelo devem ser armazenadas em Unity Catalog.
Para garantir que o modelo avalie automaticamente o recurso on-demand quando for usado para inferência, o senhor deve definir o URI do registro e, em seguida, log o modelo, como segue:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="main.default.model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model"
)
Se o Python UDF que define o recurso on-demand importar qualquer Python pacote, o senhor deverá especificar esse pacote usando o argumento extra_pip_requirements. Por exemplo:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model",
extra_pip_requirements=["scikit-learn==1.20.3"]
)
Exemplo de notebook
O Notebook a seguir mostra como treinar e pontuar um modelo que usa recurso on-demand.
Demonstração básica do recurso on-demand Notebook
Limitações
Para endpoints de Feature Serving, todos os tipos de dados compatíveis com Feature Store são compatíveis como tipos de saída de função de recurso, exceto ArrayType, MapType e StructType. StructType também não é compatível como um tipo de entrada de função de recurso.