Implantação de modelos legados de provisionamento de taxa de transferência
O fluxo de trabalho descrito nesta página está obsoleto. Em vez disso, consulte provisionamento Taxa de transferência Foundation Model APIs.
modelos registrados usando o sabor MLflow transformers
Para habilitar o provisionamento Taxa de transferência para endpoint do seu modelo, você deve log seu modelo usando o flavor MLflow transformers e especificar o argumento task com "llm/v1/embeddings".
Este argumento especifica a assinatura API usada para o endpoint do modelo de serviço. Consulte a documentação do MLflow para obter mais detalhes sobre a tarefa llm/v1/embeddings e seus respectivos esquemas de entrada e saída.
Segue um exemplo de como log o modelo Alibaba-NLP/gte-large-en-v1.5 para que ele possa ser disponibilizado com provisionamento Taxa de transferência:
model = AutoModel.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
task="llm/v1/embeddings",
registered_model_name=registered_model_name,
# model_type is required for logging a fine-tuned BGE models.
metadata={
"model_type": "gte-large"
}
)
Depois que seu modelo estiver logado no Unity Catalog, continue em Criar seu endpoint de provisionamento Taxa de transferência usando a UI para criar um endpoint de modelo de instalação com provisionamento Taxa de transferência.
faixas de tokens por segundo no provisionamento Taxa de transferência
Os tópicos descritos nesta seção aplicam-se ao provisionamento Taxa de transferência workloads that serve models that provisionamento inference capacity based on tokens per second . Os seguintes modelos se aplicam:
- Meta Llama 3.3
- Meta Llama 3.2 3B
- Meta Llama 3.2 1B
- Meta Llama 3.1
- GTE v1.5 (Inglês)
- BGE v1.5 (inglês)
- DeepSeek R1 (não disponível no Unity Catalog)
- Meta Llama 3
- Meta Llama 2
- DBRX
- Mistral
- Mixtral
- MPT
Consulte Unidades de modelo em provisionamento Taxa de transferência para modelos suportados que usam unidades de modelo (não tokens por segundo) para provisionamento de capacidade de inferência.
Esta seção descreve como e por que Databricks mede tokens por segundo para cargas de trabalho de provisionamento Taxa de transferência para APIsdo Foundation Model.
O desempenho de grandes modelos de linguagem (LLMs) é frequentemente medido em termos de tokens por segundo. Ao configurar o endpoint do modelo de serviço de produção, é importante considerar o número de solicitações que seu aplicativo envia para o endpoint. Isso ajuda você a entender se seu endpoint precisa ser configurado para escalonamento automático, de forma a não impactar a latência.
Ao configurar os intervalos de escalonamento para o endpoint implantado com provisionamento Taxa de transferência, Databricks descobriu que era mais fácil entender as entradas que chegam ao seu sistema usando tokens.
O que são tokens?
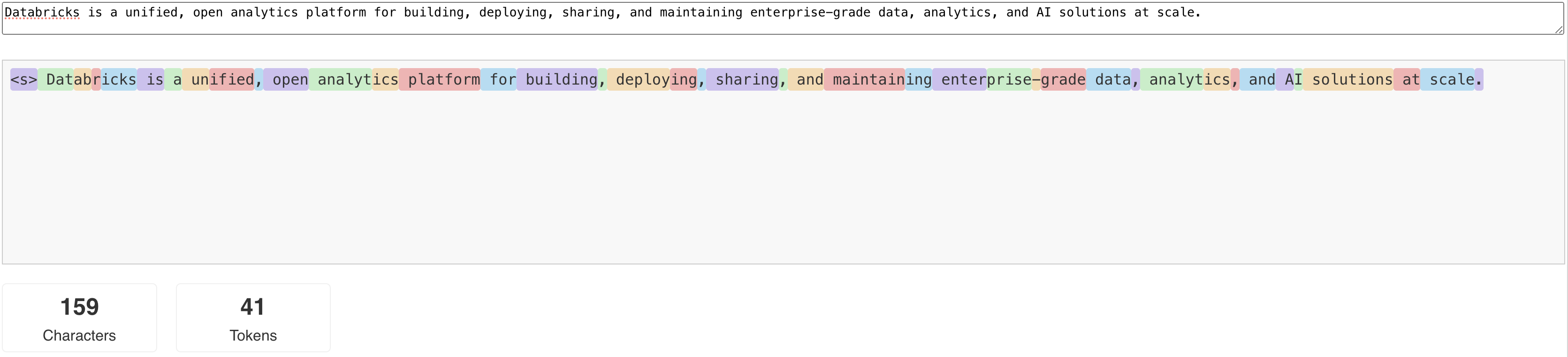
Os LLMs leem e geram texto em termos do que é chamado de tokens . Os tokens podem ser palavras ou subpalavras, e as regras exatas para dividir o texto em tokens variam de modelo para modelo. Por exemplo, você pode usar ferramentas online para ver como o tokenizador do Llama converte palavras em tokens.
O diagrama a seguir mostra um exemplo de como o analisador léxico Llama divide o texto:
Por que medir o desempenho do LLM em termos de tokens por segundo?
Tradicionalmente, os endpoints de serviço são configurados com base no número de solicitações concorrentes por segundo (RPS). No entanto, o tempo de uma solicitação de inferência LLM varia dependendo da quantidade de tokens passados e da quantidade gerada, o que pode resultar em desequilíbrio entre as solicitações. Portanto, decidir o quanto de escalonamento seu endpoint precisa realmente requer medir o escalonamento endpoint em termos do conteúdo da sua solicitação - tokens.
Diferentes casos de uso, recursos, diferentes proporções de tokens de entrada e saída:
- Comprimentos variáveis dos contextos de entrada : Enquanto algumas solicitações podem envolver apenas alguns tokens de entrada, como por exemplo, uma pergunta curta, outras podem envolver centenas ou até milhares de tokens, como um documento longo para sumarização. Essa variabilidade torna desafiador configurar um endpoint de serviço baseado apenas em RPS, uma vez que não leva em account as diferentes demandas de processamento das solicitações.
- Comprimentos de saída variáveis dependendo do caso de uso : Diferentes casos de uso para LLMs podem levar a comprimentos de tokens de saída muito diferentes. A geração de tokens de saída é a parte mais demorada da inferência LLM , portanto, isso pode impactar drasticamente a taxa de transferência. Por exemplo, o resumo envolve respostas mais curtas e concisas, mas a geração de texto, como a escrita de artigos ou descrições de produtos, pode gerar respostas muito mais longas.
Como faço para selecionar o intervalo de tokens por segundo para meu endpoint?
O provisionamento Taxa de transferência serving endpoint é configurado em termos de um intervalo de tokens por segundo que você pode enviar para o endpoint. O endpoint escala automaticamente para cima e para baixo, de forma a lidar com a carga da sua aplicação de produção. A cobrança é feita por hora, com base na quantidade de tokens por segundo que seu endpoint atinge.
A melhor maneira de saber qual intervalo tokens por segundo no seu endpoint de provisionamento Taxa de transferência funciona para o seu caso de uso é realizar um teste de carga com um dataset representativo. Consulte Realize sua própria avaliação comparativa endpoint LLM.
Há dois fatores importantes a considerar:
- Como a Databricks mede o desempenho do LLM em tokens por segundo.
- Como funciona o dimensionamento automático.
Como a Databricks mede o desempenho de tokens por segundo do LLM
Databricks avalia o desempenho do endpoint em relação a uma carga de trabalho que representa tarefas de sumarização comuns em casos de uso de geração aumentada por recuperação de dados. Especificamente, a carga de trabalho consiste em:
- 2048 tokens de entrada
- 256 tokens de saída
Os intervalos de tokens exibidos combinam tokens de entrada e saída (Taxa de transferência) e, por default, otimizam o balanceamento de Taxa de transferência e latência.
Databricks realiza testes de desempenho que mostram que os usuários podem enviar essa quantidade tokens por segundo simultaneamente para o endpoint , com um tamanho de lote de 1 por solicitação. Isso simula várias solicitações atingindo o endpoint ao mesmo tempo, o que representa com mais precisão como você realmente usaria o endpoint em produção.
- Por exemplo, se um endpoint de provisionamento Taxa de transferência tiver uma taxa definida de 2304 tokens por segundo (2048 + 256), então uma única solicitação com uma entrada de 2048 tokens e uma saída esperada de 256 tokens deverá levar cerca de um segundo para ser executada.
- Da mesma forma, se a taxa for definida como 5600, você pode esperar que uma única solicitação, com as contagens de tokens de entrada e saída acima, leve cerca de 0,5 segundos para ser executada – ou seja, o endpoint pode processar duas solicitações semelhantes em cerca de um segundo.
Se a sua carga de trabalho for diferente da acima mencionada, pode esperar que a latência varie em relação à taxa de provisionamento Taxa de transferência indicada. Conforme mencionado anteriormente, gerar mais tokens de saída demanda mais tempo do que incluir mais tokens de entrada. Se você estiver realizando inferência de lotes e quiser estimar o tempo necessário para concluí-la, poderá calcular o número médio de tokens de entrada e saída e comparar com a carga de trabalho de referência Databricks acima.
- Por exemplo, se você tiver 1000 linhas, com uma média de 3000 tokens de entrada e 500 tokens de saída, e uma taxa de transferência de 3500 tokens por segundo, o processo pode demorar mais de 1000 segundos no total (um segundo por linha), devido à sua média de tokens ser maior que o benchmark Databricks .
- Da mesma forma, se você tiver 1000 linhas, uma entrada média de 1500 tokens, uma saída média de 100 tokens e uma taxa de transferência de 1600 tokens por segundo, o processo poderá levar menos de 1000 segundos no total (um segundo por linha), devido à sua contagem média de tokens ser inferior ao benchmark do Databricks .
Como funciona o dimensionamento automático
servindo modelo recurso um sistema de escalonamento automático rápido que aumenta a compute subjacente para atender à demanda de tokens por segundo da sua aplicação. Databricks aumentam o provisionamento Taxa de transferência em pedaços de tokens por segundo, portanto, você será cobrado por unidades adicionais de provisionamento Taxa de transferência somente quando estiver usando-os.
O gráfico de Taxa de transferência-latência a seguir mostra um endpoint de provisionamento de Taxa de transferência testado com um número crescente de solicitações paralelas. O primeiro ponto representa 1 requisição, o segundo, 2 requisições paralelas, o terceiro, 4 requisições paralelas, e assim por diante. Com o aumento do número de solicitações e, consequentemente, da demanda por tokens por segundo, observa-se também um aumento na taxa de transferência (Provisionamento Taxa de transfer). Esse aumento indica que o dimensionamento automático aumenta a compute disponível. No entanto, você poderá começar a perceber que a taxa de transferência começa a estabilizar, atingindo um limite de aproximadamente 8.000 tokens por segundo à medida que mais solicitações paralelas são feitas. A latência total aumenta à medida que mais solicitações precisam esperar na fila antes de serem processadas, porque o compute alocado está sendo usado simultaneamente.
Você pode manter a Taxa de transferência consistente desativando a escala para zero e configurando uma Taxa de transferência mínima no endpoint de serviço. Fazendo isso, evita-se a necessidade de esperar que o endpoint seja escalado.

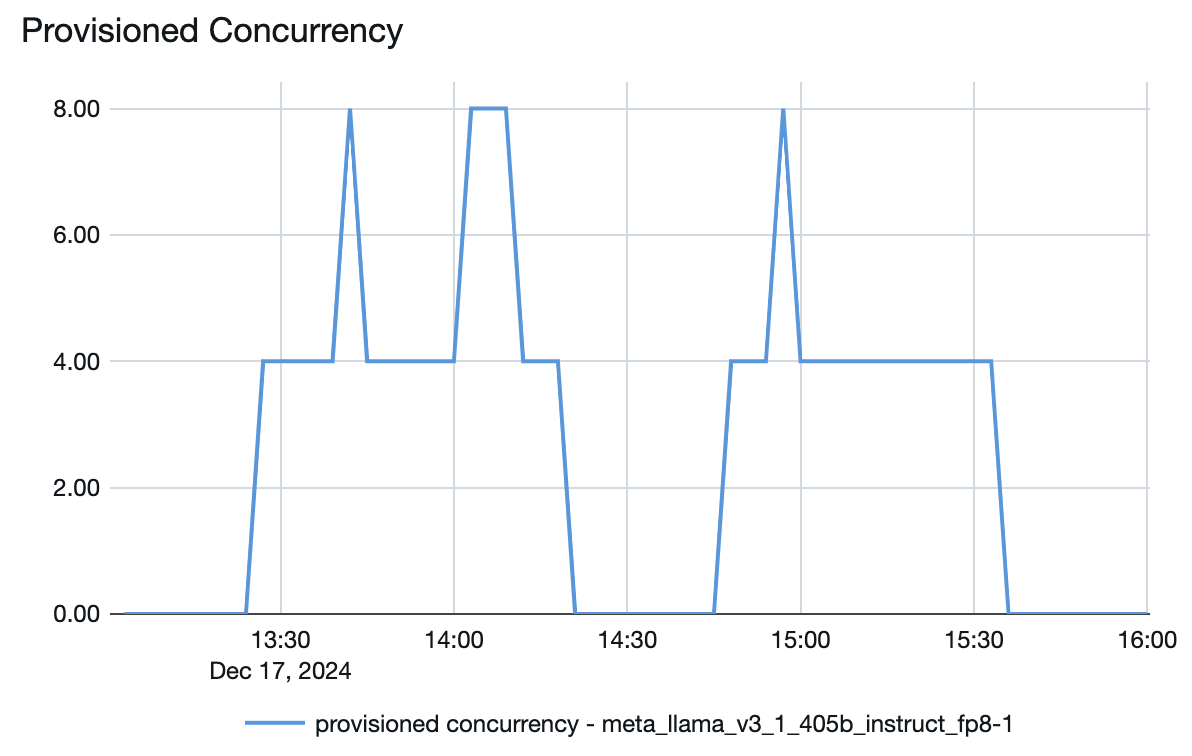
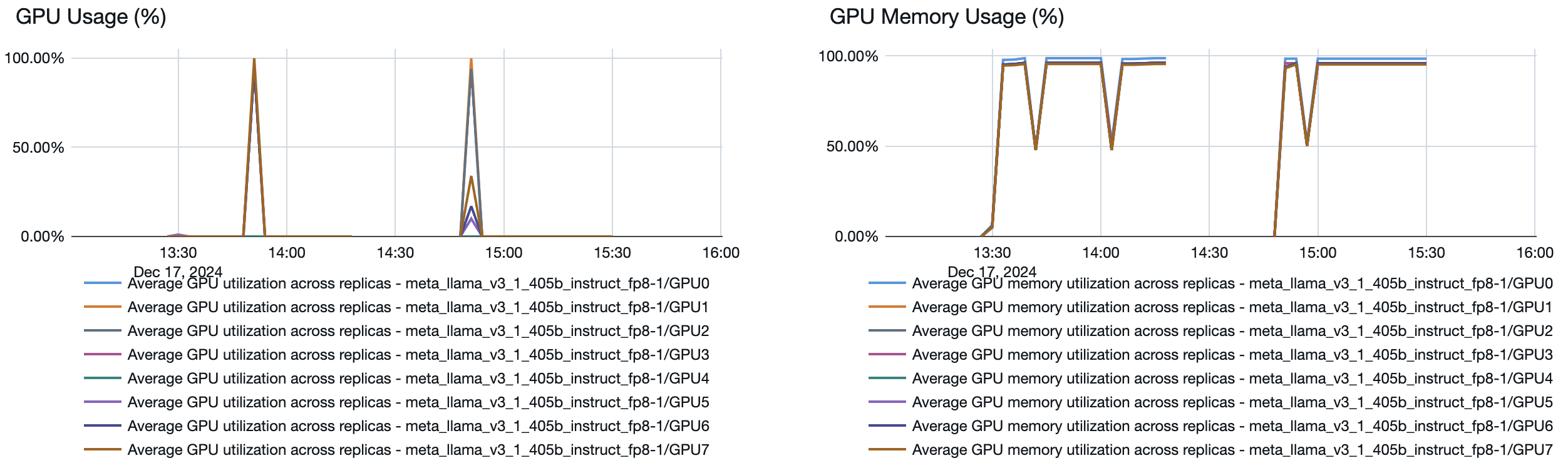
Você também pode ver no endpoint do modelo de serviço como os recursos são ativados ou desativados dependendo da demanda:
Solução de problemas
Se o seu endpoint de provisionamento Taxa de transferência estiver executando a uma taxa de menos tokens por segundo do que o especificado, verifique o quanto o endpoint realmente escalou, analisando o seguinte:
- O provisionamento de simultaneidade gráfico nas métricas do endpoint .
- O tamanho mínimo da banda endpoint de provisionamento Taxa de transferência.
- Acesse os detalhes da entidade servida para o endpoint e verifique o valor mínimo tokens por segundo na dropdown "Até" .
Em seguida, você pode calcular o quanto o endpoint realmente escalou usando a seguinte fórmula:
- simultaneidade de provisionamento * tamanho mínimo de banda / 4
Por exemplo, o gráfico de simultaneidade de provisionamento para o modelo Llama 3.1 405B acima tem uma simultaneidade de provisionamento máxima de 8. Ao configurar um endpoint para isso, o tamanho mínimo da banda era de 850 tokens por segundo. Neste exemplo, o endpoint foi dimensionado até um máximo de:
- 8 (concorrência de provisionamento) * 850 (tamanho mínimo da banda) / 4 = 1700 tokens por segundo