Materialização para visão de Métis
Experimental
Este recurso é experimental.
Este artigo explica como usar a materialização para visualização de métricas para acelerar o desempenho da consulta.
A materialização para visões métricas acelera as consultas usando visões materializadas. O pipeline declarativo LakeFlow Spark orquestra uma visão materializada definida pelo usuário para uma determinada view de métricas. No momento da consulta, o otimizador de consultas encaminha de forma inteligente as consultas do usuário na view de métricas para a melhor view materializada, utilizando correspondência automática de consultas com reconhecimento de agregação, também conhecida como reescrita de consultas.
Essa abordagem oferece os benefícios do pré-cálculo e das atualizações incrementais automáticas, de modo que você não precisa determinar qual tabela de agregação ou view materializada consultar para diferentes objetivos de desempenho, e elimina a necessidade de gerenciar um pipeline de produção separado.
Visão geral
O diagrama a seguir ilustra como as métricas visualizam a definição e a execução de consultas:
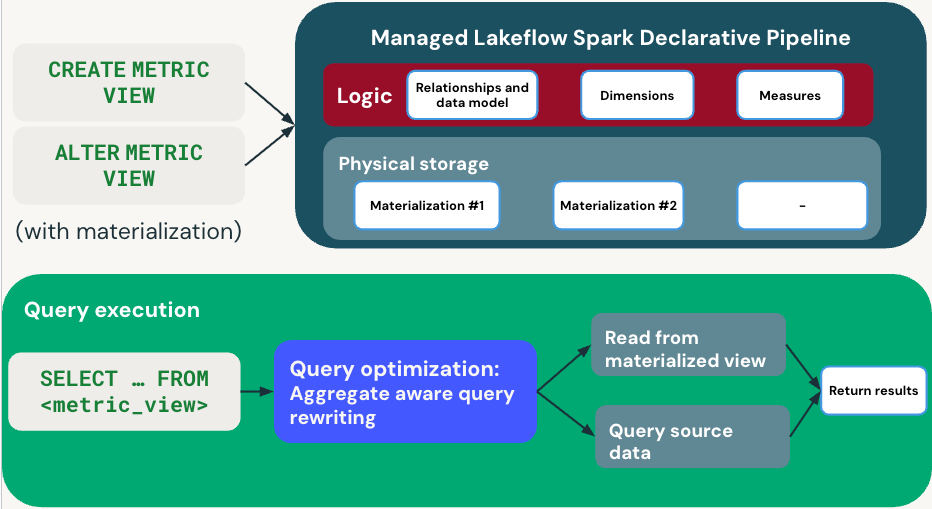
Fase de definição
Ao definir uma view de métricas com materialização, CREATE METRIC VIEW ou ALTER METRIC VIEW especifica suas dimensões, medidas e programa refresh . Databricks cria um pipelinede gerenciamento que mantém a visão materializada.
Execução de consulta
Quando você executa SELECT ... FROM <metric_view>, o otimizador de consultas usa a reescrita de consultas com reconhecimento de agregação para otimizar o desempenho:
- Caminho rápido : Lê da visualização materializada pré-computada quando aplicável.
- Caminho alternativo : Lê diretamente dos dados de origem quando as materializações não estão disponíveis.
O otimizador de consultas equilibra automaticamente o desempenho e a atualização dos dados, escolhendo entre dados materializados e dados de origem. Você recebe os resultados de forma transparente, independentemente do caminho utilizado.
Requisitos
Para usar a materialização na visualização de métricas:
- Seu workspace deve ter compute serverless habilitada. Isso é necessário para a execução do pipeline declarativo LakeFlow Spark .
- Databricks Runtime 17.2 ou acima.
Referência de configuração
Todas as informações relacionadas à materialização são definidas em um campo de nível superior chamado materialization na definição YAML da view métricas.
O campo materialization contém os seguintes campos obrigatórios:
- programar : Suporta a mesma sintaxe que a cláusula programar na visão materializada.
- modo : Deve ser definido como
relaxed. - materialized_views : Uma lista de visualizações materializadas a serem materializadas.
- Nome : O nome da materialização.
- dimensões : Uma lista de dimensões a serem materializadas. Somente referências diretas a nomes de dimensões são permitidas; expressões não são suportadas.
- Medidas : Uma lista de medidas a serem implementadas. Somente referências diretas a nomes de medidas são permitidas; expressões não são suportadas.
- tipo : Especifica se a view materializada é agregada ou não. Aceita dois valores possíveis:
aggregatedeunaggregated.- Se
typeéaggregated, deve haver pelo menos uma dimensão ou medida. - Se
typeforunaggregated, nenhuma dimensão ou medida deve ser definida.
- Se
A cláusulaTRIGGER ON UPDATE não é suportada para materialização para visualização de métricas.
Definição de exemplo
version: 1.1
source: prod.operations.orders_enriched_view
filter: revenue > 0
dimensions:
- name: category
expr: substring(category, 5)
- name: color
expr: color
measures:
- name: total_revenue
expr: SUM(revenue)
- name: number_of_suppliers
expr: COUNT(DISTINCT supplier_id)
materialization:
schedule: every 6 hours
mode: relaxed
materialized_views:
- name: baseline
type: unaggregated
- name: revenue_breakdown
type: aggregated
dimensions:
- category
- color
measures:
- total_revenue
- name: suppliers_by_category
type: aggregated
dimensions:
- category
measures:
- number_of_suppliers
Mode
No modo relaxed , a reescrita automática de consultas apenas verifica se a visão materializada candidata possui as dimensões e medidas necessárias para atender à consulta.
Isso significa que várias verificações são ignoradas:
- Não existem verificações para saber se a view materializada está atualizada.
- Não há verificações para saber se você tem configurações SQL correspondentes (por exemplo,
ANSI_MODEouTIMEZONE). - Não existem verificações para saber se a view materializada retorna resultados determinísticos.
Se a consulta incluir alguma das seguintes condições, a reescrita da consulta não ocorrerá e a consulta recorrerá às tabelas de origem:
- Segurança em nível de linha (RLS) ou mascaramento em nível de coluna (CLM) na visão materializada.
- Funções não determinísticas como
current_timestamp()na visão materializada. Esses elementos podem aparecer na definição view de métricas ou em uma tabela de origem usada pela view de métricas.
Durante o período de lançamento experimental, relaxed é o único modo suportado. Caso essas verificações falhem, a consulta recorrerá aos dados de origem.
Tipos de materializações para visão de métricas
As seções a seguir explicam os tipos de visão materializada disponíveis para a visão de métricas.
Tipo agregado
Este tipo pré-calcula agregações para combinações específicas de medidas e dimensões, visando uma cobertura direcionada.
Isso é útil para direcionar padrões ou widgets de consulta de agregação comuns específicos. Databricks recomenda incluir colunas de filtro potenciais como dimensões na configuração view materializada. As colunas de filtro potenciais são colunas usadas no momento da consulta na cláusula WHERE .
Tipo não agregado
Este tipo materializa todo o modelo de dados não agregado (por exemplo, os campos source, join e filter ) para uma cobertura mais ampla com menor aumento de desempenho em comparação com o tipo agregado.
Use este tipo quando as seguintes condições forem verdadeiras:
- A origem é uma view ou consulta SQL dispendiosa.
- As junções definidas na sua view de métricas são dispendiosas.
Se a sua fonte for uma referência direta a uma tabela sem a aplicação de um filtro seletivo, uma view materializada não agregada pode não trazer benefícios.
Ciclo de vida da materialização
Esta seção explica como as materializações são criadas, gerenciadas e atualizadas ao longo de seu ciclo de vida.
Criar e modificar
A criação ou modificação de uma view de métricas (usando CREATE, ALTER ou o Explorador de Catálogo) ocorre de forma síncrona. A visualização materializada especificada é materializada de forma assíncrona usando o pipeline declarativo LakeFlow Spark .
Ao criar uma view de métricas, Databricks cria um pipeline LakeFlow Spark Declarative e programa uma atualização inicial imediata se houver visualizações materializadas especificadas. A view de métricas permanece consultável sem materializações, recorrendo à consulta a partir dos dados de origem.
Ao modificar uma view de métricas, nenhuma nova atualização é agendada, a menos que você esteja habilitando a materialização pela primeira vez. As visões materializadas não são usadas para reescrita automática de consultas até que a próxima atualização agendada seja concluída.
Alterar o programador de materialização não aciona uma refresh.
Consulte a refreshmanual para obter um controle mais preciso sobre o comportamento refresh .
Inspecione pipelinesubjacente.
A materialização para a visualização de métricas é implementada usando o pipeline declarativo LakeFlow Spark . O link para o pipeline está presente na tab Visão Geral do Explorador de Catálogo. Para saber como acessar o Explorador de Catálogo, consulte O que é o Explorador de Catálogo?.
Você também pode acessar este pipeline executando DESCRIBE EXTENDED na view de métricas. A seção de atualização de informações contém um link para o pipeline.
DESCRIBE EXTENDED my_metric_view;
Exemplo de saída:
-- Returns additional metadata such as parent schema, owner, access time etc.
> DESCRIBE TABLE EXTENDED customer;
col_name data_type comment
------------------------------- ------------------------------ ----------
... ... ...
# Detailed Table Information
... ...
Language YAML
Table properties ...
# Refresh information
Latest Refresh status Succeeded
Latest Refresh https://...
Refresh Schedule EVERY 3 HOURS
refreshmanual
A partir do link para a página do pipeline declarativo LakeFlow Spark , você pode iniciar manualmente uma atualização pipeline para atualizar as materializações. Você também pode acionar uma refresh manual usando o seguinte comando SQL :
REFRESH MATERIALIZED VIEW <metric-view-name>
refreshincremental
A visão materializada utiliza refresh incremental sempre que possível e possui as mesmas limitações em relação à fonte de dados e à estrutura do plano.
Para obter detalhes sobre pré-requisitos e restrições, consulte refresh incremental para visualização materializada.
Reescrita automática de consultas
Consultas a uma view de métricas com materialização tentam usar suas materializações o máximo possível. Existem duas estratégias de reescrita de consultas: correspondência exata e correspondência não agregada.

Ao consultar uma view de métricas, o otimizador analisa a consulta e as materializações definidas pelo usuário disponíveis. A consulta é executada automaticamente na melhor materialização em vez das tabelas base usando este algoritmo:
- A primeira tentativa busca uma correspondência exata.
- Se existir uma materialização não agregada, tente uma correspondência não agregada.
- Se a reescrita da consulta falhar, a consulta lerá diretamente das tabelas de origem.
A materialização deve ser concluída antes que a reescrita da consulta entre em vigor.
Verifique se a consulta está usando uma visão materializada.
Para verificar se uma consulta está usando uma view materializada, execute EXPLAIN EXTENDED em sua consulta para ver o plano de consulta. Se a consulta estiver usando visão materializada, o nó folha inclui__materialization_mat___metric_view e o nome da materialização do arquivo YAML.
Alternativamente, o perfil de consulta mostra a mesma informação.
correspondência exata
Para ser elegível para a estratégia de correspondência exata, as expressões de agrupamento da consulta devem corresponder precisamente às dimensões de materialização. As expressões de agregação da consulta devem ser um subconjunto das medidas de materialização.
Partida não agregada
Caso haja uma materialização não agregada disponível, essa estratégia será sempre elegível.
Cobrança
A atualização da visualização materializada acarreta custos de utilização do pipeline declarativo LakeFlow Spark .
Restrições conhecidas
As seguintes restrições se aplicam à materialização para a visualização de redes:
- Uma view de métricas com materialização que se refere a outra view de métricas como fonte não pode ter uma materialização não agregada.