Acompanhe e compare modelos usando MLflow modelos logados
MLflow Os modelos registrados ajudam o senhor a acompanhar o progresso de um modelo durante todo o seu ciclo de vida. Quando o senhor treinar um modelo, use o site mlflow.<model-flavor>.log_model() para criar um LoggedModel que reúna todas as suas informações críticas usando um ID exclusivo. Para aproveitar o poder do LoggedModels, comece a usar o MLflow 3.
Para aplicativos GenAI, o site LoggedModels pode ser criado para capturar o commit do git ou conjuntos de parâmetros como objetos dedicados que podem ser vinculados a traços e métricas. Na aprendizagem profunda e na clássica ML, LoggedModels são produzidos a partir de MLflow execução, que são conceitos existentes em MLflow e podem ser considerados como trabalhos que executam o código do modelo. A execução do treinamento produz modelos como resultados, e a execução da avaliação usa modelos existentes como entrada para produzir métricas e outras informações que o senhor pode usar para avaliar o desempenho de um modelo.
O objeto LoggedModel persiste durante todo o ciclo de vida do modelo, em diferentes ambientes, e contém links para artefatos como metadados, métricas, parâmetros e o código usado para gerar o modelo. O acompanhamento registrado de modelos permite que o senhor compare modelos entre si, encontre o modelo de melhor desempenho e rastreie informações durante a depuração.
Os modelos registrados também podem ser cadastrados no Unity Catalog registro de modelo, disponibilizando informações sobre o modelo de todos os experimentos e espaços de trabalho do MLflow em um único local. Para obter mais detalhes, consulte Model Registry improvements with MLflow 3.
![]()
Acompanhamento aprimorado para os modelos gen AI e aprendizagem profunda
O Generative AI e a aprendizagem profunda fluxo de trabalho se beneficiam especialmente do acompanhamento granular que os modelos logados oferecem.
Gen AI - avaliação unificada e dados de rastreamento:
- Os modelos da geração AI geram métricas adicionais durante a avaliação e a implantação, como dados de feedback do revisor e rastreamentos.
- A entidade
LoggedModelpermite que o senhor consulte todas as informações geradas por um modelo usando uma única interface.
aprendizagem profunda - gerenciamento eficiente de pontos de controle:
- O aprendizado profundo treinamento cria vários pontos de verificação, que são instantâneos do estado do modelo em um determinado ponto durante o treinamento.
- O MLflow cria um
LoggedModelseparado para cada ponto de verificação, contendo as métricas do modelo e os dados de desempenho. Isso permite que você compare e avalie pontos de verificação para identificar os modelos com melhor desempenho de forma eficiente.
Criar um modelo registrado
Para criar um modelo registrado, use o mesmo log_model() API que as cargas de trabalho existentes do MLflow. Os trechos de código a seguir mostram como criar um modelo registrado para o gen AI, aprendizagem profunda e o tradicional ML fluxo de trabalho.
Para obter exemplos completos e executáveis do Notebook, consulte Exemplo de Notebook.
- Gen AI
- Deep learning
- Traditional ML
O trecho de código a seguir mostra como log um agente LangChain. Use o método log_model() para seu sabor de agente.
# Log the chain with MLflow, specifying its parameters
# As a new feature, the LoggedModel entity is linked to its name and params
model_info = mlflow.langchain.log_model(
lc_model=chain,
name="basic_chain",
params={
"temperature": 0.1,
"max_tokens": 2000,
"prompt_template": str(prompt)
},
model_type="agent",
input_example={"messages": "What is MLflow?"},
)
# Inspect the LoggedModel and its properties
logged_model = mlflow.get_logged_model(model_info.model_id)
print(logged_model.model_id, logged_model.params)
Começar um trabalho de avaliação e vincular as métricas a um modelo registrado, fornecendo o model_id exclusivo para o LoggedModel:
# Start a run to represent the evaluation job
with mlflow.start_run() as evaluation_run:
eval_dataset: mlflow.entities.Dataset = mlflow.data.from_pandas(
df=eval_df,
name="eval_dataset",
)
# Run the agent evaluation
result = mlflow.evaluate(
model=f"models:/{logged_model.model_id}",
data=eval_dataset,
model_type="databricks-agent"
)
# Log evaluation metrics and associate with agent
mlflow.log_metrics(
metrics=result.metrics,
dataset=eval_dataset,
# Specify the ID of the agent logged above
model_id=logged_model.model_id
)
O trecho de código a seguir mostra como criar modelos registrados durante a aprendizagem profunda treinamento. Use o método log_model() para sua variante do modelo MLflow.
# Start a run to represent the training job
with mlflow.start_run():
# Load the training dataset with MLflow. We will link training metrics to this dataset.
train_dataset: Dataset = mlflow.data.from_pandas(train_df, name="train")
X_train, y_train = prepare_data(train_dataset.df)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(scripted_model.parameters(), lr=0.01)
for epoch in range(101):
X_train, y_train = X_train.to(device), y_train.to(device)
out = scripted_model(X_train)
loss = criterion(out, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Obtain input and output examples for MLflow Model signature creation
with torch.no_grad():
input_example = X_train[:1]
output_example = scripted_model(input_example)
# Log a checkpoint with metrics every 10 epochs
if epoch % 10 == 0:
# Each newly created LoggedModel checkpoint is linked with its
# name, params, and step
model_info = mlflow.pytorch.log_model(
pytorch_model=scripted_model,
name=f"torch-iris-{epoch}",
params={
"n_layers": 3,
"activation": "ReLU",
"criterion": "CrossEntropyLoss",
"optimizer": "Adam"
},
step=epoch,
signature=mlflow.models.infer_signature(
model_input=input_example.cpu().numpy(),
model_output=output_example.cpu().numpy(),
),
input_example=X_train.cpu().numpy(),
)
# Log metric on training dataset at step and link to LoggedModel
mlflow.log_metric(
key="accuracy",
value=compute_accuracy(scripted_model, X_train, y_train),
step=epoch,
model_id=model_info.model_id,
dataset=train_dataset
)
O trecho de código a seguir mostra como log um modelo sklearn e vincula métricas ao Logged Model. Use o método log_model() para sua variante do modelo MLflow.
## Log the model
model_info = mlflow.sklearn.log_model(
sk_model=lr,
name="elasticnet",
params={
"alpha": 0.5,
"l1_ratio": 0.5,
},
input_example = train_x
)
# Inspect the LoggedModel and its properties
logged_model = mlflow.get_logged_model(model_info.model_id)
print(logged_model.model_id, logged_model.params)
# Evaluate the model on the training dataset and log metrics
# These metrics are now linked to the LoggedModel entity
predictions = lr.predict(train_x)
(rmse, mae, r2) = compute_metrics(train_y, predictions)
mlflow.log_metrics(
metrics={
"rmse": rmse,
"r2": r2,
"mae": mae,
},
model_id=logged_model.model_id,
dataset=train_dataset
)
Exemplo de notebook
Para ver exemplos de Notebook que ilustram o uso do LoggedModels, consulte as páginas a seguir:
visualizar modelos e acompanhar o progresso
O senhor pode view seus modelos registrados na UI workspace:
- Acesse o site Experiments tab em seu workspace.
- Selecione um experimento. Em seguida, selecione Models (Modelos ) tab.
Esta página contém todos os modelos registrados associados ao experimento, juntamente com suas métricas, parâmetros e artefatos.
![]()
O senhor pode gerar gráficos para acompanhar as métricas em toda a execução.
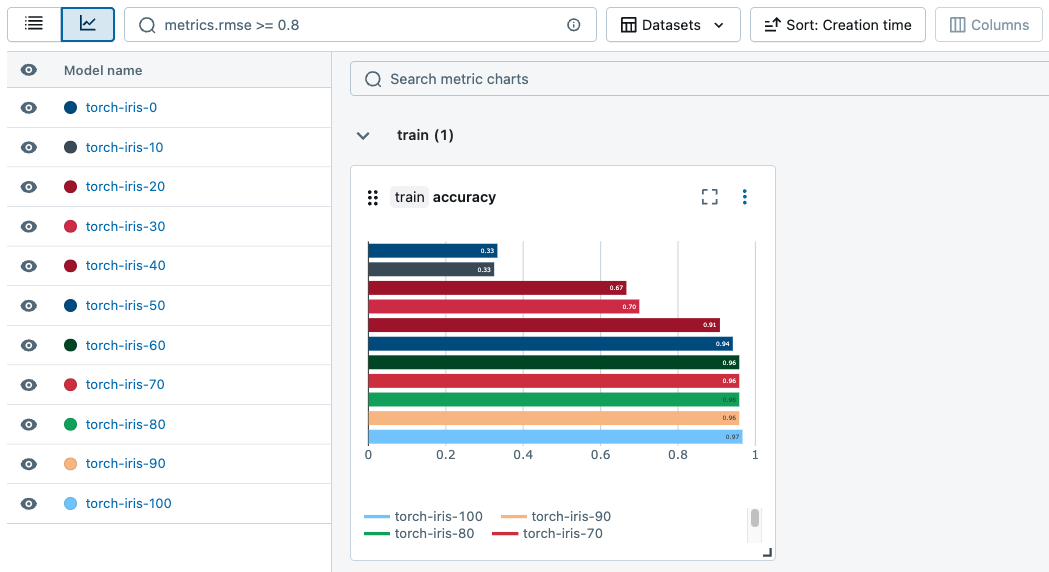
Pesquisar e filtrar modelos registrados
Em Models tab, o senhor pode pesquisar e filtrar modelos registrados com base em seus atributos, parâmetros, tags e métricas.
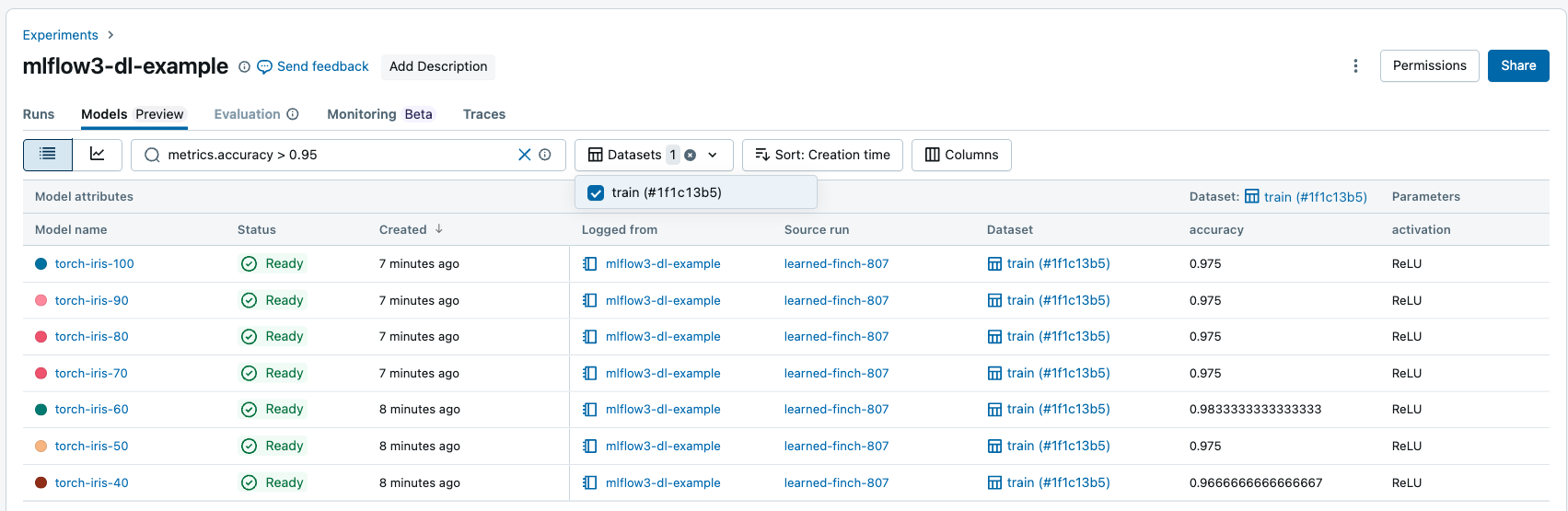
O senhor pode filtrar as métricas com base no desempenho específico do site dataset, e somente os modelos com valores de métricas correspondentes no conjunto de dados fornecido são retornados. Se os filtros dataset forem fornecidos sem nenhum filtro de métricas, os modelos com quaisquer métricas nesses conjuntos de dados serão retornados.
Você pode filtrar com base nos seguintes atributos:
model_idmodel_namestatusartifact_uricreation_time(numérico)last_updated_time(numérico)
Use os seguintes operadores para pesquisar e filtrar cadeias de caracteres - como atributos, parâmetros e tags:
=,!=,IN,NOT IN
Use os seguintes operadores de comparação para pesquisar e filtrar atributos numéricos e métricas:
=,!=,>,<,>=,<=
Pesquisar modelos registrados programaticamente
O senhor pode pesquisar os modelos registrados usando o site MLflow API:
## Get a Logged Model using a model_id
mlflow.get_logged_model(model_id = <my-model-id>)
## Get all Logged Models that you have access to
mlflow.search_logged_models()
## Get all Logged Models with a specific name
mlflow.search_logged_models(
filter_string = "model_name = <my-model-name>"
)
## Get all Logged Models created within a certain time range
mlflow.search_logged_models(
filter_string = "creation_time >= <creation_time_start> AND creation_time <= <creation_time_end>"
)
## Get all Logged Models with a specific param value
mlflow.search_logged_models(
filter_string = "params.<param_name> = <param_value_1>"
)
## Get all Logged Models with specific tag values
mlflow.search_logged_models(
filter_string = "tags.<tag_name> IN (<tag_value_1>, <tag_value_2>)"
)
## Get all Logged Models greater than a specific metric value on a dataset, then order by that metric value
mlflow.search_logged_models(
filter_string = "metrics.<metric_name> >= <metric_value>",
datasets = [
{"dataset_name": <dataset_name>, "dataset_digest": <dataset_digest>}
],
order_by = [
{"field_name": metrics.<metric_name>, "dataset_name": <dataset_name>,"dataset_digest": <dataset_digest>}
]
)
Para obter mais informações e parâmetros de pesquisa adicionais, consulte a documentaçãoMLflow 3 API.
Pesquisar execução por entradas e saídas do modelo
O senhor pode pesquisar a execução por ID de modelo para retornar todas as execuções que tenham os modelos registrados como entrada ou saída. Para obter mais informações sobre a sintaxe das cadeias de filtro, consulte filtragem para execução.
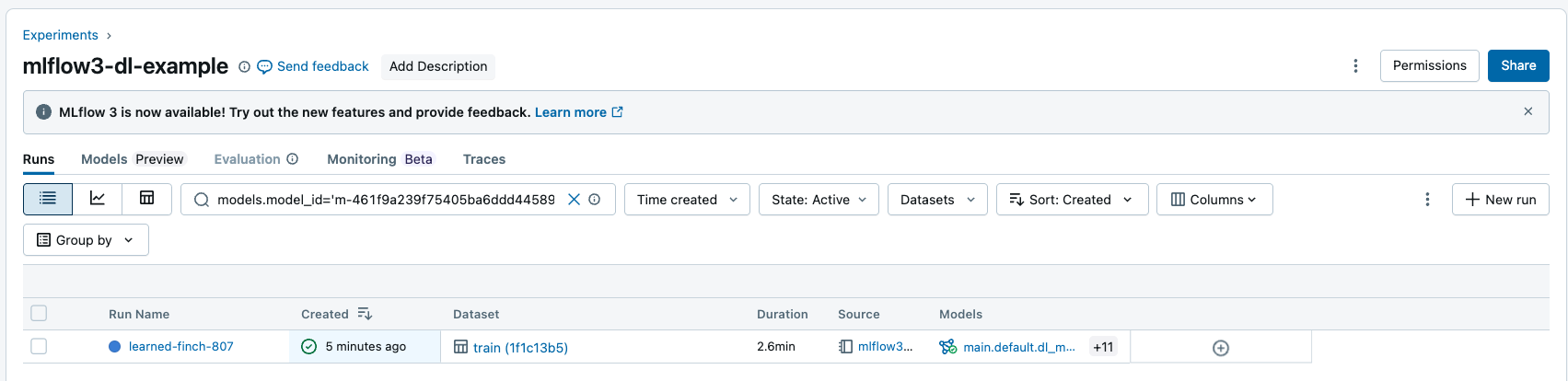
O senhor pode pesquisar por execução usando o site MLflow API:
## Get all Runs with a particular model as an input or output by model id
mlflow.search_runs(filter_string = "models.model_id = <my-model-id>")
Recursos adicionais
Para saber mais sobre outros novos recursos do site MLflow 3, consulte os artigos a seguir: